






Probability distribution->discrete variable
Probability density->continuous variable
何为先验概率(Prior probability)、后验(Posterior probability)? 是以事件(Event)发生的先后顺序为依据的。
- 1.2.1 Probability density
概率密度是相对于连续函数来说的,离散数据的概率分布可以认为是概率密度在离散点在邻域范围内的积分值。
概率密度同样满足sum rule和product rule。
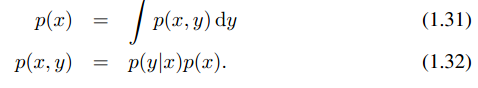
如果x=g(y)是一个非线性变换,那么随机变量x和y的概率密度极值点是不同的。如果是线性变换,那么两者的极值点是相同的,因为x对y的导数为一常量。存在如下关系。
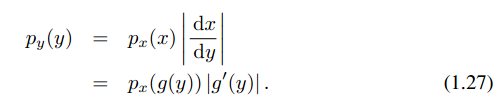
- 1.2.2 Expectation and Covariance
均值的定义:

多变量的均值:

- 1.2.3 Bayesian probability
频率学派和贝叶斯学派的区别:
频率学派仅仅通过观察到的数据来得到问题的解,且是一个固定(deterministic)的值;而贝叶斯学派并不认为问题的解是固定不变的,而是在一定的变化范围内(即取得问题的解符合一定的概率),这主要是因为由于加入了先验知识后,对频率学派中的固定的值产生了影响。


因此,贝叶斯的方法更具有容错性,同时,容错性带来的问题是:对于置信度比较高的数据,采用较高容错度的贝叶斯方法取得的精度并没有频数派的方法高。因此,两种方法大战了几十年,双方各有利弊。

- 1.2.4 The Gaussian distribution
The issue of bias in maximum likelihood estimation 由于对方差的欠估计(under-estimated),会使得最大似然估计在样本较少的情况下,对高斯分布参数的估计并不准确,如(1.57)(1.58)所示,ML的均值是Gaussian均值的无偏估计,而ML的方差估计偏小,这正也是产生overfitting的原因。但是,随着样本数目的增多,而ML的方差估计会趋于Gaussian的方差,bias的现象会减弱。
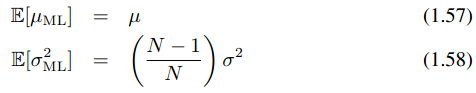

- 1.2.5 Curve fitting re-visited
Curve fitting的最大似然和贝叶斯最大后验估计的解决方法。两者的区别和联系及两者的最终的目标函数与curve fitting的目标函数和加约束的curve fitting的目标函数之间的联系。
最大似然的目标函数:
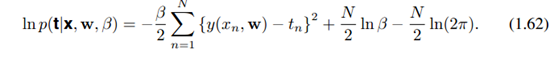
最大后验概率的目标函数:

- 1.2.6 Bayesian curve fitting
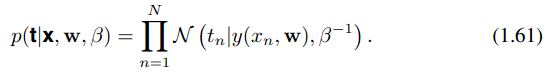
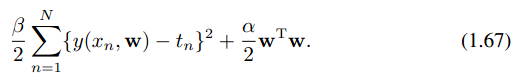
通过最大似然估计(1.6.1)和最大后验概率估计(1.6.7)得到的w,虽然估计的方法不同,但两者得到的仍是w的点估计,并没有体现出频数派和贝叶斯学派的本质区别。


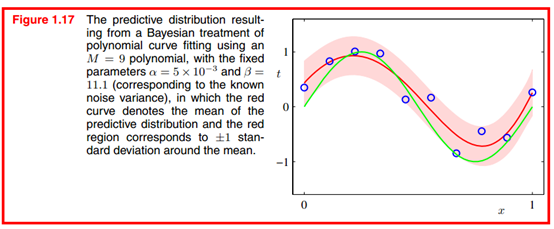















 1491
1491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









