







第一章《introduction》,一开始先介绍了一些模式识别与机器学习的背景知识,模式识别的起源,定义。接下来又讲到了hand-written digits的例子,说到了手动编写代码的方式在这样的问题上是很难得到好的结果的。而通过机器学习的方法,让我们创建的模型自己去认识大量的数据,认识数据背后的规律则会有很好的效果。然后讲到了特征的基本概念,讲到了机器学习算法的基本分类等等,比较易于理解,就不赘述了。而为了解决机器学习所要解决的问题,我们需要理解概率论,决策论和信息论。下面的从1.1到1.2的内容,作者首先介绍了一个多项式曲线的例子,从这个例子又引出概率论,最后又回到曲线的例子。而后来决策论和信息论的内容,放在下一部分叙述。
1.1 Example:Polynomial Curve Fitting
问题:拟合的目标是sin(2πx),并根据高斯分布加入了一点随机噪声。利用以上方式产生了10个点作为我们的样本集。(书中也顺带提到了噪声的来源:1,样本本身的一些偶然因素,例如放射衰变。2一些未捕获到的特征)
使用模型: 多项式模型
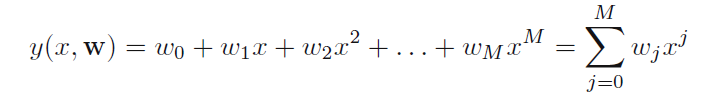
cost function:
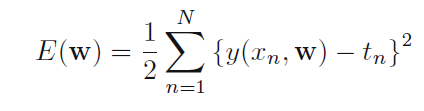
接下来作者比较了多项式的模型M分别为0,1,3,9时,用相同的包含10个样本点的数据集训练模型所得出的拟合情况。
其中M=0,1的模型明显存在欠拟合,而M=9时则存在过拟合,M=3时,效果是最好的。同时,作者提出了一个问题,从幂级数的角度来讲,函数sin(2πx)是包含了所有指数从0---无穷的所有项数的,那么按道理说,M越大,拟合效果应该越好,那么为什么M=9的效果会比较差呢?
因为越大的M也越容易拟合目标变量上的噪声,再加之此时参数个数与样本数的比是1:1,所以M=9的效果就会很差。那么如果数据严格以sin(2πx)产生,而没有随机噪声,用M=9的模型去拟合,效果是不是会很好?
接下来,作者说到,过拟合的原因有参数个数和样本数的比例不好导致(通常样本数应该是参数个数的5--10倍),而过拟合的另一个原因是最大似然函数的天生瑕疵(后面会具体讲,这里问题的来源即cost function)。当从贝叶斯的角度来看时,有效参数的个数会自适应于样本数,即加入正则化。
加入正则化后的cost function:
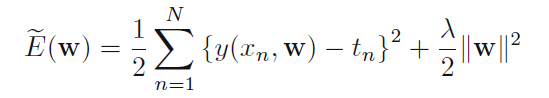
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









