






Spide-Flow功能文档
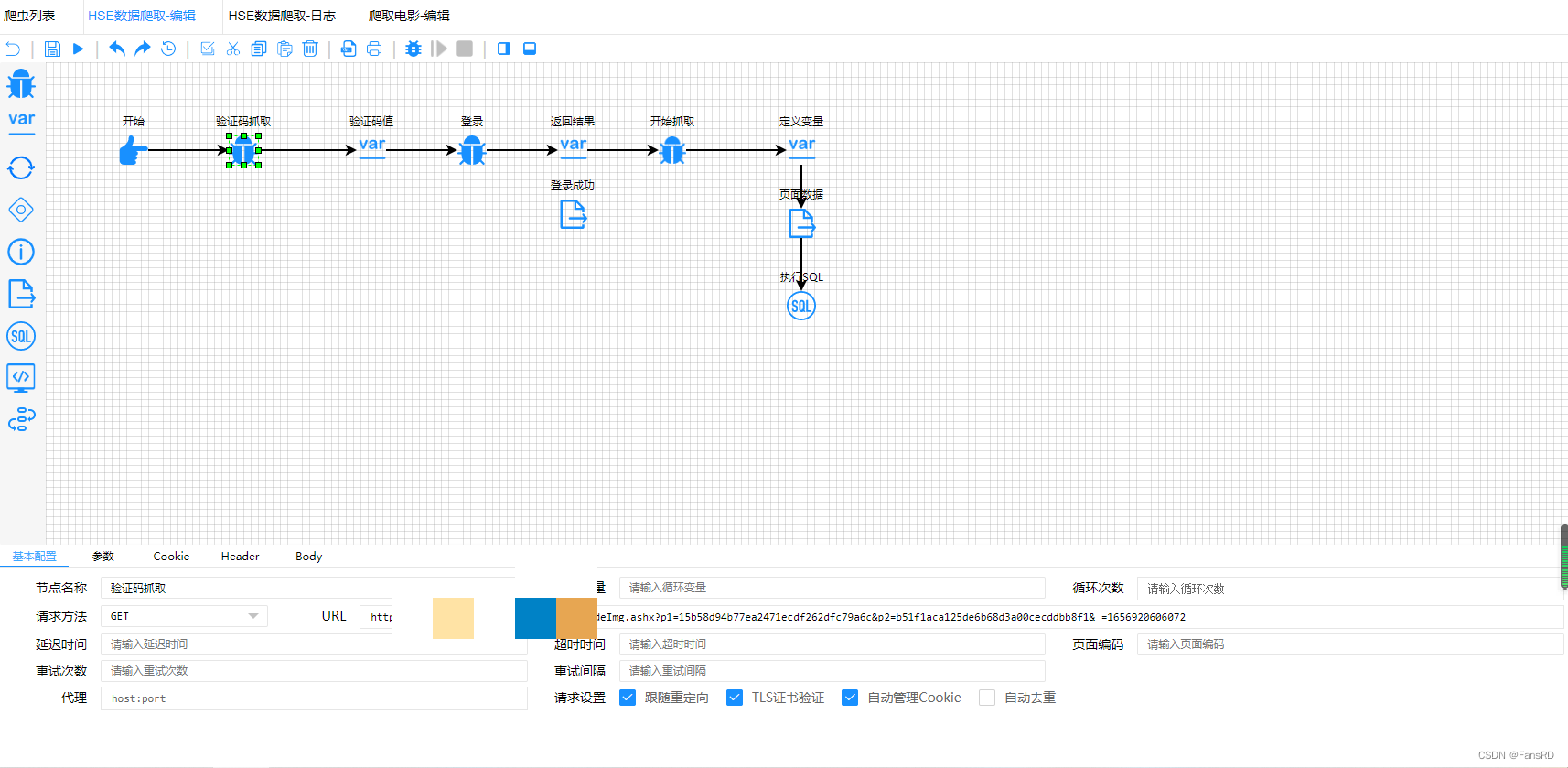
- 首先找到登录的网站

2.打开F12开发者工具,输入账号密码,验证码故意出错,会出现生成验证码的接口,接口为GET请求,那么就在软件里设置为GET请求,之后打开接口就会出现正确验证码


1.将这个页面的数据进行爬取,每次登录就会爬取正确的验证码,将爬取的验证码保存,变量名为validCode.

- 登录的时候输入账号和密码还有验证码,只有输错账号或者密码,输正确验证码,才会暴露账号密码的接口.
- 可以先输错密码获取正确加密后的账号


- 再次登录输错账号就可以获取正确的密码


2.将之前获取到正确的验证码在登录界面进行替换


- 登录成功后会返回一个OK的信号.
- 如果账号有误或者密码有误会返回一个账号或者密码错误的信息.

1.进去后选择要抓取的页面,之后打开F12开发者工具,选择要爬取的数据接口

- 打开页面接口就会出现所需要的数据

2.之后将JSON数据解析


- ${resp.html}解析当前页面
- ${json.parse(jsonSt)}将页面解析为JSON数据类型
- ${extract.jsonpath(jsonobj,'rows')根据jsonpath抽取Jsonobj根节点下’rows’的属性,封装为datas

1.获取到数据组将需要的数据进行爬取,比如温度,PH,氨氮,化学需氧量

1.首先对本地数据库进行配置,测试连接状态

2 .连接成功后,将需要存入数据库的数据,通过SQL语句进行存入
INSERT INTO table (对应字段) VALUES(对应值)

- 配置定时任务可以配置每分钟,每小时等执行一次,根据开发所要的需求进行配置.
- 验证码

将账号密码输入正确,故意将拖动滑块错误会暴露验证码接口,爬取验证码,这个拖动滑块验证码爬取正确率为100%,返回信息为正确的验证码.

账号密码

打开接口会会接受到一个信息,用户名不存在,将页面信息存入数据库可以清楚知道登录是那一步出现的问题.

密码输错同样会出现一个接口

打开接口会出现一个错误密码提示

页面数据

页面数据如果出现问题,数据库同样会导入空值数据,或者数据没有进行存入进去,表明在拉取数据这一步出现了问题.
- 需要到百度进行注册一个OCR账号

2.注册之后在应用列表中创建一个应用

3.根据创建后生成的AppID,API Key,Secret Key到Spide-Flow进行OCR配置,
配置完成后就可以进行爬取时调用OCR插件.
4.OCR插件需要从Spide-Flow文档中获取地址进行源码下载.

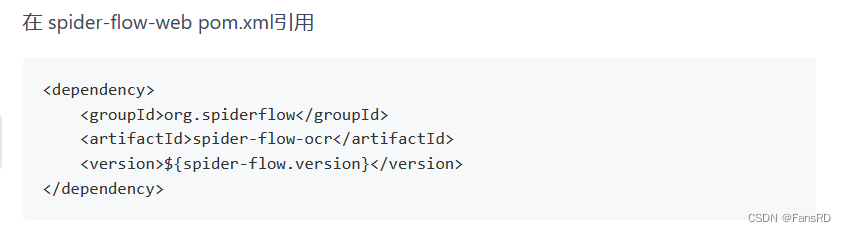
5.下载完成后在 spider-flow-web pom.xml引用
6.基于百度OCR技术实现每人每月免费次数一千次,无论失败和成功都算作一次.
普通识别和高精度识别的收费标准不同,会记录每日的调取量和成功量.
普通识别收费为:0.005/次
精准识别收费为:0.03/次


随机生成的正确验证码存入数据库 与 OCR识别的验证码存入数据库进行对比计算成功率.
- 大小写字母加数字类型 测试100次 成功率为6%
- 文字类型 测试100次 成功率为7%
成功率和测试的图片也有一定的关系.
1.从生成正确的验证码数据库中和OCR识别生成的验证码的数据库中拿出来对比进行返回页面正确或者错误信息.
2.暂时模拟返回页面错误信息

1.模拟多任务同时爬取数据

2 .设定HSE2验证码错误,HSE账号错误

①数据库可以看到项目的名称和错误的信息.
②如果验证码错误同时会显示密码错误.
③如果验证码正确账号错误,会出现正确的验证码同时报错账号错误信息,登录错误的时间.
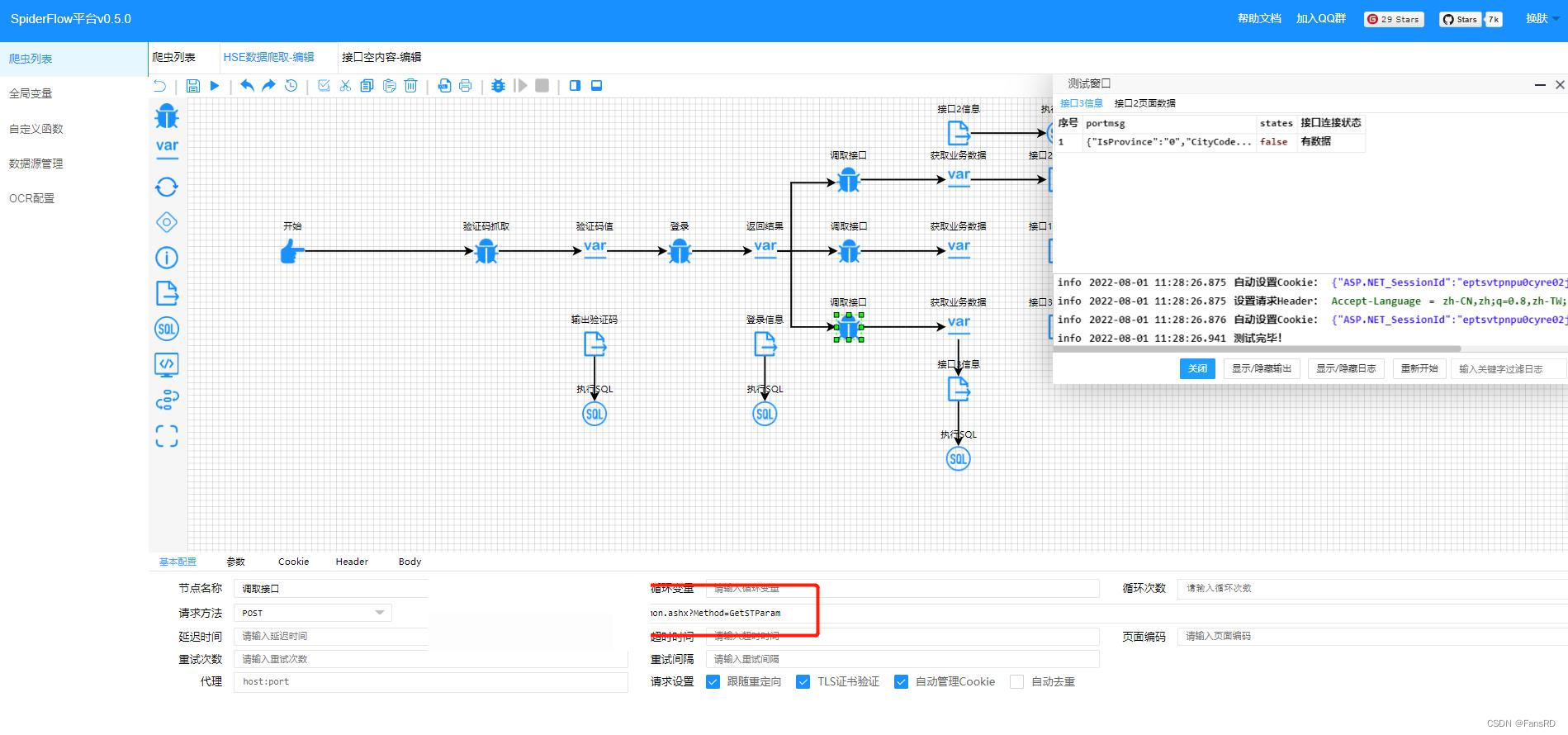
- 模拟多接口任务爬取
①爬取的接口实际为一张图片并无数据,接口返回的信息为ok

②在获取业务数据离进行页面的对比 如果为’ok’则返回true

③在返回日志中用三元运算符进行返回日志,如果为true则无数据

④反之爬取的接口为实际所需数据则返回有数据














 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









