







问题背景:
最近公司有个需求,要爬取某个网站列表数据,使用开源工具spiderFlow,关于该工具,本人不再赘述,该工具git地址:https://gitee.com/ssssssss-team/spider-flow;帮助文档:https://www.spiderflow.org/。使用该工具爬取数据的过程中遇到的问题,我将在此做个总结,仅供参考。
问题整理:
1、数据库查到的数据,及其被分割后的数据均为object
2、服务器操作系统时区和springboot配置的时区不一致,导致界面查询时间比数据多8小时,同时导致定时任务直接失效;
3、大量频繁的请求导致返回503,爬取结果resp为null;
1、数据库查到的数据为object类型,而且无法对其进行类型转换及subString操作。
项目中需要查看当天的日期,一开始的想法是从数据库查询now(),然后跟目标日期对比。

实际执行对比之后发现,equals方法执行后的结果均为null,定位后发现数据库查到的数据为object。而且也无法对其进行类型转换及subString操作。
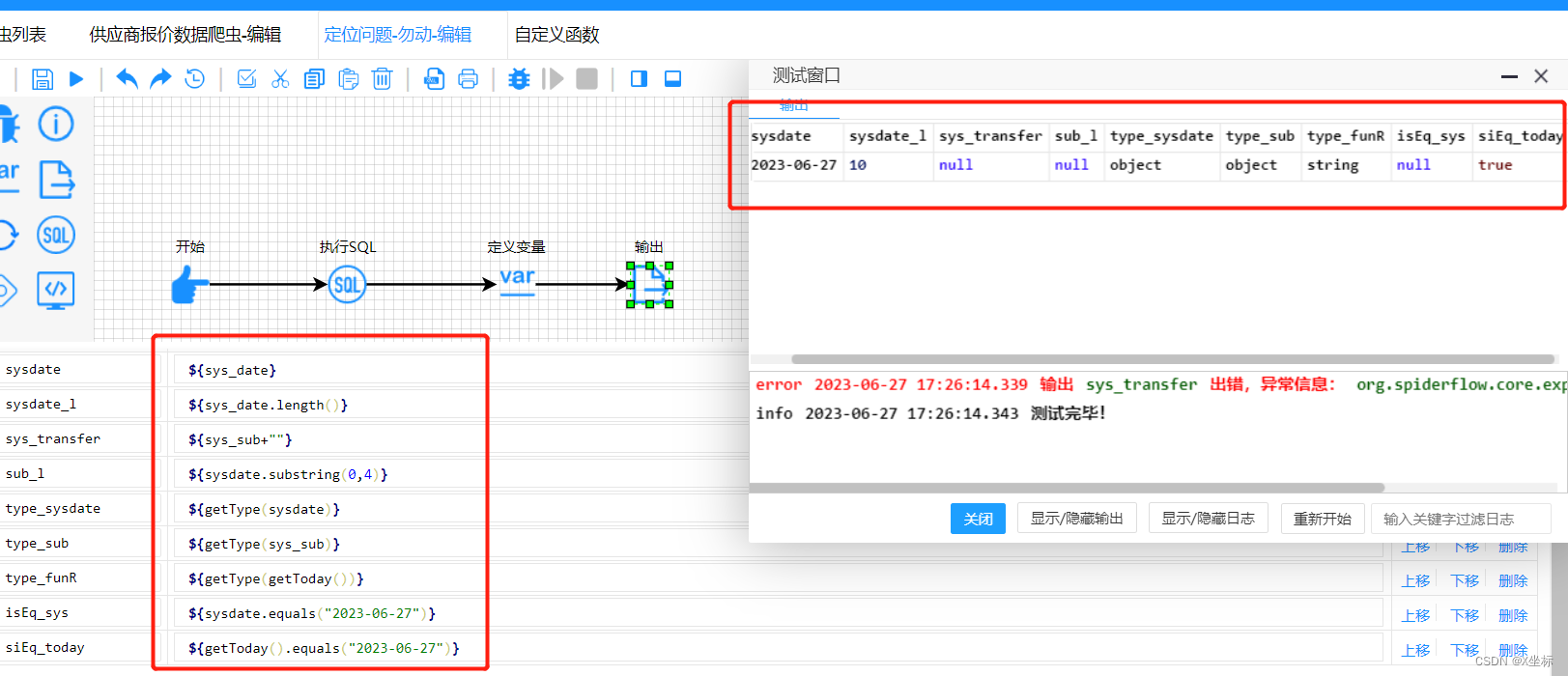
随后则自定义函数,通过js脚本获取了当前时间,此时,获取到的时间是String类型(如上图),而且和目标字段equals比较结果也正常。
2、服务器操作系统时区和springboot配置的时区不一致,导致界面查询时间比数据多8小时,同时导致定时任务直接失效;

网上找答案说是在springboot的配置文件里配置如下即可解决
spring.jackson.time-zone=GMT+8
分析发现,该项目本身就已经包含该配置,然后注释掉该配置之后,查询时间则正常。经过了解,我发现spring.jackson.time-zone配置是springboot在json反序列化的时候对于时间参数的时区做的校正处理,然后我分别查询数据库、操作系统的时区,发现数据库及操作系统服务的时区均为东八区
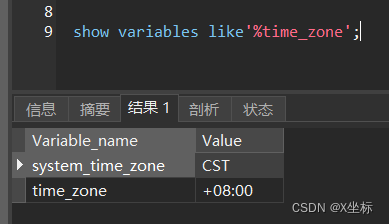
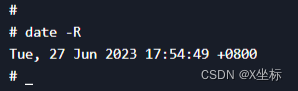
服务器操作系统、数据库和springboot配置的时区均为东八区,按道理不应该出现时间不一致的问题!然后我想到服务是部署在docker容器当中的,我试着请求了一个当前应用并不存在的url,然后看应用返回的时间
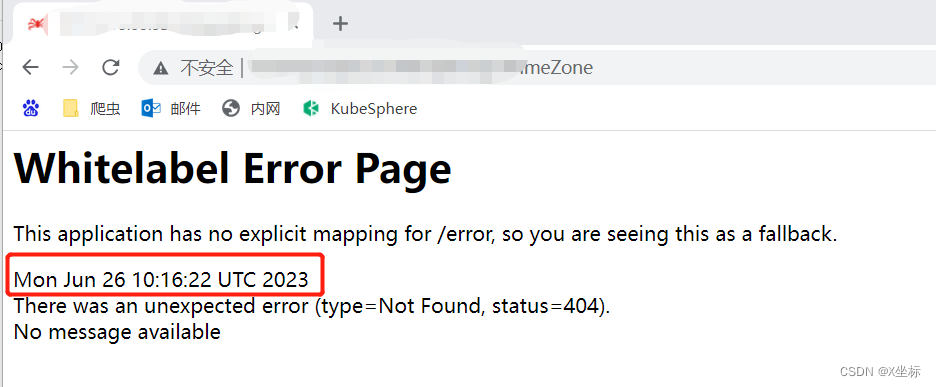
发现服务返回的时间果然是UTC时间,和东八区差8个小时!然后我查看该宿主机其他服务获取的系统时间,则是正常的,所以得出结论,该服务的宿主机与应用容器之间的时区不一致, 通过dockerfile的配置,可以设置服务的时区,配置时区之后,问题解决。配置如下(不同类型的Linux宿主机操作系统配置可能不同,具体自行百度):
ENV TIME_ZONE Asia/Shanghai
RUN ln -snf /usr/share/zoneinfo/$TIME_ZONE /etc/localtime
其中Asia/Shanghai为东八区的时区代号。
3、大量频繁的请求导致返回503,爬取结果resp为null;
我所负责的本次爬虫共有41个页面,每个页面爬3页数据,每页40条数据(第三页为末页的除外)。我的爬取逻辑是三个循环嵌套,最多总共爬取41×3×40=4920次。且每次请求之间没有延时,导致爬取一段时间后,经常会出现爬取结果为null的情况
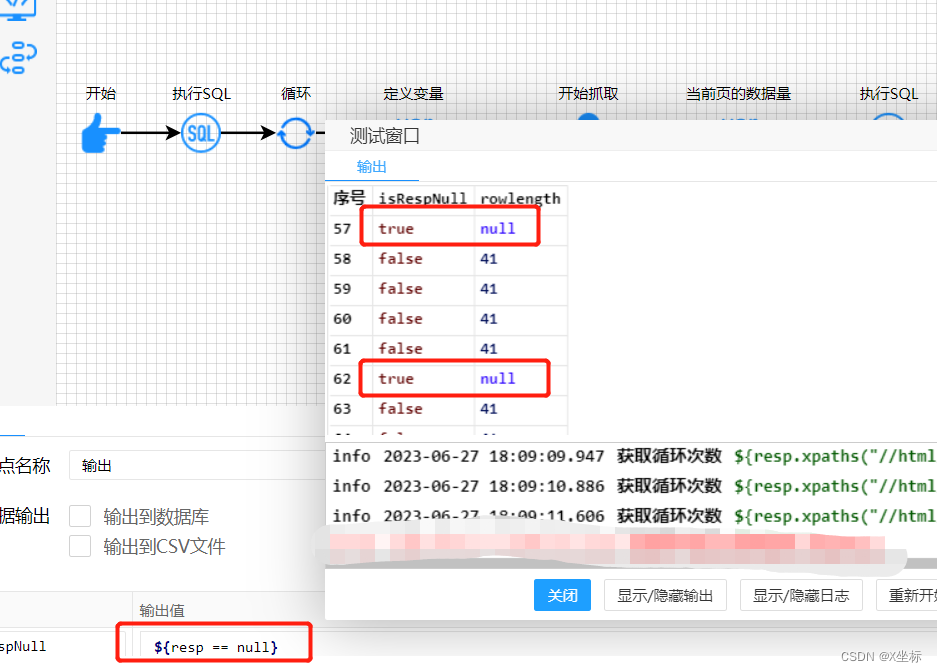
于是我怀疑是网站服务对单位时间同一目标发送的请求数量有限制(可能是反爬机制,也有可能是缓存队列已满),于是我用postman批量发送了一下请求,
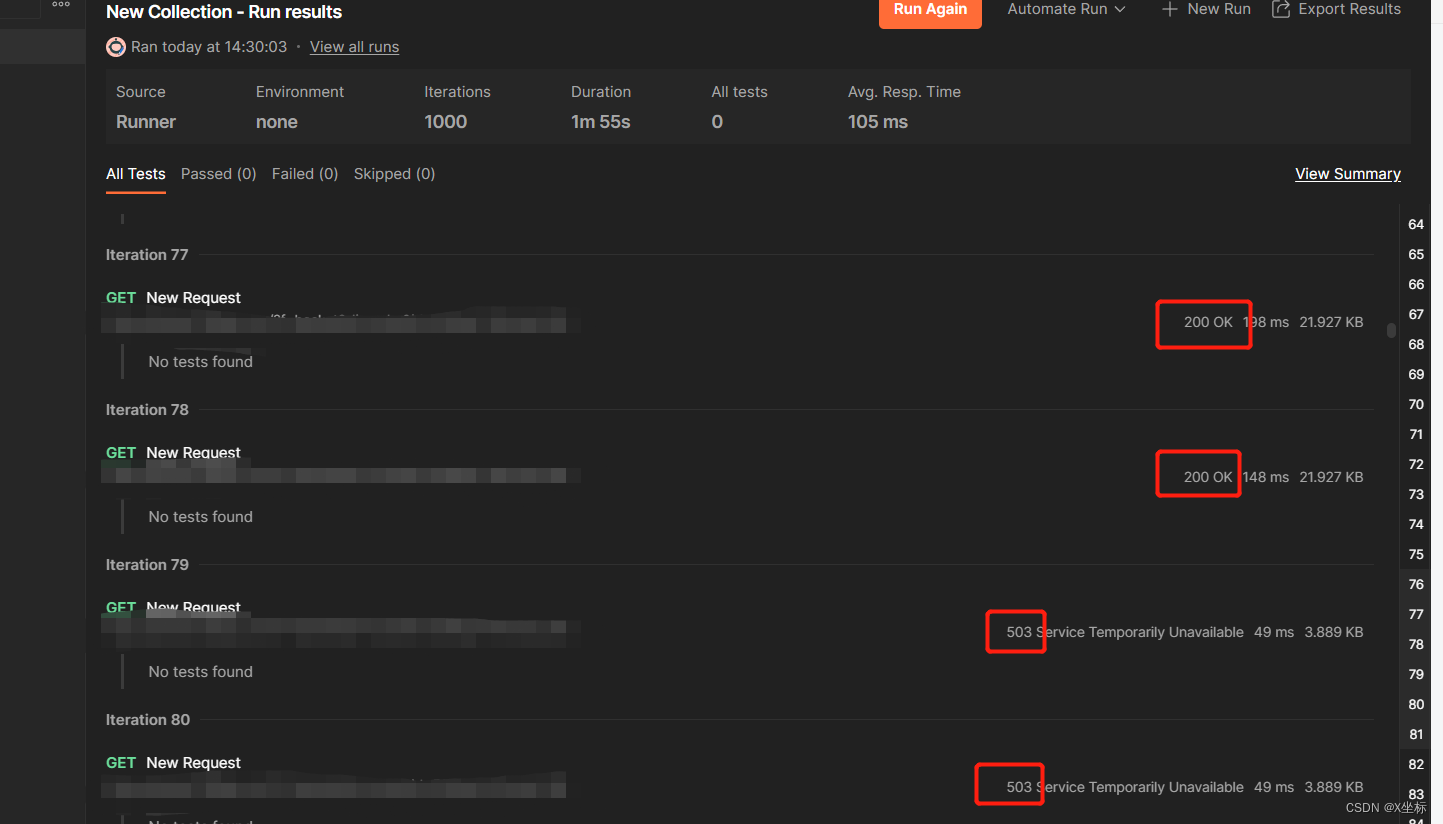
发现从第79次请求之后,请求返回都是503,这一结果也印证了上述猜想。
于是我将爬虫的请求添加了1秒的延时

重新测试后,所有请求均正常返回
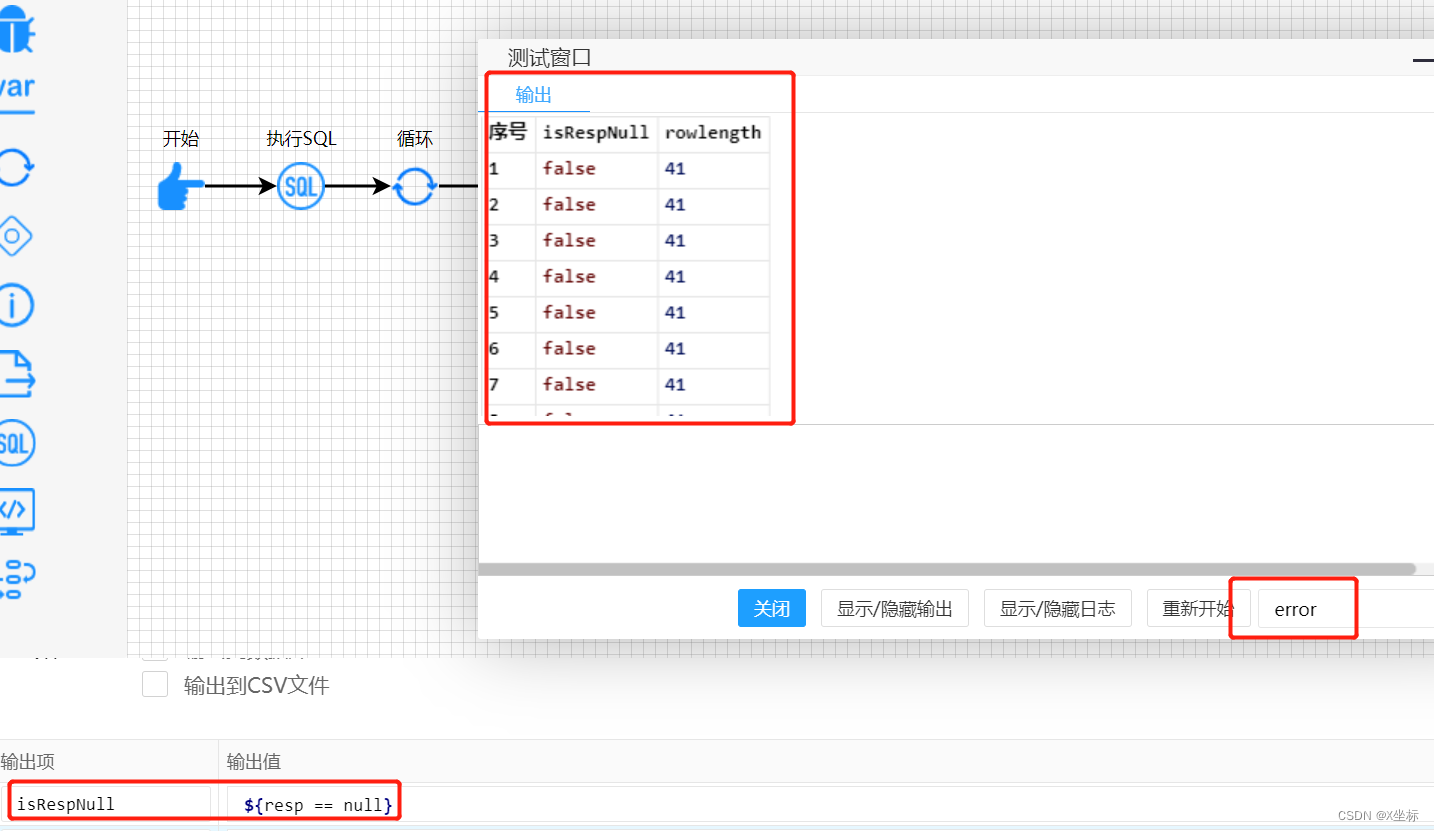
使用postman延时请求结果也均正常返回。
总结:
1、需要使用到的系统变量,例如时间,尽量从js脚本中获取;
2、服务正常使用(不止是爬虫服务)需要保证数据库时区、springboot配置时区、服务器操作系统时区(如果是docker容易部署,则是宿主机和容器时区)均要保持一致;
3、要根据爬虫的请求量决定是否需要请求延时,需要延时多少(少量请求不需要延时也可以正常爬取)。















 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









