







遗传算法的基础
历史背景
19世纪的世界四大学说之一:达尔文的自然选择学说。
它的主要内容有四点:过度繁殖,生存斗争(也叫生存竞争),遗传和变异,适者生存。
达尔文认为:一切生物都有产生变异的特性。引起变异的根本原因是环境条件的改变。然后,在生物产生的各种变异中,有的可以遗传,有的不能够遗传。
在生存斗争里面,如果有「有利变异」的基因,那它就容易在生存斗争中获胜。相反的,有不利变异的个体,就容易在生存斗争中失败,然后死亡。
它的主要思想就是:但凡是生存下来的生物,都是适应环境的。而被淘汰的生物,都是对环境不适应的,这就是适者生存。
达尔文就把这个过程叫做自然选择。自然选择的过程是一个长期的、缓慢的、连续的过程。
因为,生存斗争是不断地进行,所以,自然选择也是不断地进行的,这样一代一代下来,可以说物种也因此得到优化了。

遗传算法的起源与发展
遗传算法:就是根据自然界这个“物竞天择,适者生存”现象而提出来的一种随机搜索算法。
大概在60 年代左右,美国密歇根大学(心理学和计算机科学与工程)的Holland (荷兰)教授,和他的学生们,创造出了一种基于生物遗传和进化机制的遗传算法。


1967年,Holland的学生J.D.Bagley(巴格利),在博士论文中,首次提出“遗传算法(Genetic Algorithms)”这个词语。
之后,Holland也指导了学生完成了很多篇有关遗传算法研究的论文。
1971年,R.B.Hollstien(霍尔斯汀),在他的博士论文中,首次把遗传算法用于函数优化。
1975年,是遗传算法历史上十分重要的一年。因为,这一年Holland出版了他的著名专著《自然系统和人工系统的自适应》(Adaptation in Natural and Artificial Systems)。这本书系统地论述了遗传算法,所以,也有人把1975年作为遗传算法的诞生年。

进入八十年代,遗传算法迎来了兴盛发展时期。
1985年,在美国召开了第一届遗传算法国际会议(International Conference on Genetic Algorithms ,ICGA),并且成立国际遗传算法学会(International Society of Genetic Algorithms ,ISGA),以后每两年举行一次。

这之后,有很多关于遗传算法的学术论文,也不断的被发表在《Artificial Intelligence》、《Machine Learning》、《Information science》、《Parallel Computing》、《Genetic Programming and Evaluable Machine(遗传编程和可评估机器)》等杂志上。
概念
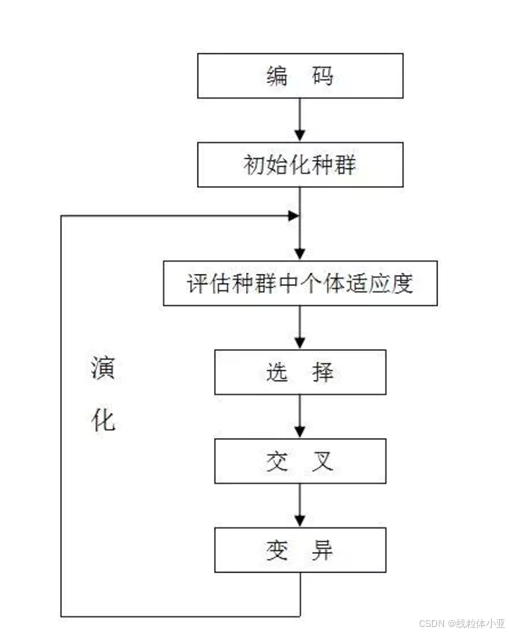
遗传算法的大概步骤:
- 首先,对问题进行描述;
- 把「潜在解」进行编码;
- 然后,用「随机数」初始化一个种群,种群中的每个个体,都对应一个编码;
- 最后,通过适应度函数,来度量个体的适应性。然后根据,适应度来选择算法。比如:淘汰适应度较低的个体,让优良的个体的基因,交叉复制和变异,产生新的子代。
和遗传算法相关的概念有:
(1) 选择算子
就是计算个体的适应值,然后根据大小,进行淘汰。就是:低适应值的个体会被淘汰,高适应值的个体会被保留。
(2) 交叉算子
在种群中,「随机」选择「两个」个体,交换它们的染色体部分编码,然后,产生两个新的子个体。
子个体和父个体不同,但又包含父个体的大部分遗传信息。
(3) 变异算子
按照一个极小概率,随机改变染色体上的某个基因,增加群体的多样性。
基因重组与基因突变
交叉运算(crossover)
可以分为5种情况:(基因交叉,相当于基因重组或者杂交)
- 单点交叉
- 两点交叉和多点交叉
- 均匀交叉
- 算术交叉
- 基因突变
1. 单点交叉
单点交叉:就是一种比较简单的交叉方式。
做法:就是随机指定一个交叉点,然后交换部分染色体,生成两个新的个体。
例子:
- |:表示交叉点。
- 左边是双亲的编码(x1,x2)
- 右边是后代的编码(x1*,x2*)
- 他们交换了后半部分的编码

2. 两点交叉和多点交叉
两点交叉:随机设置两个交叉点,然后,交换两个交叉点之间的染色体。
1|10|10和 1|01|01
两点交叉后,得到:1|01|10 和 1|10|01。
多点交叉:随机设置多个交叉点,然后,交换部分编码串。
在实际的遗传算法实践中,一般不会使用多点交叉方法。因为,它可能会破坏最优解。
其实,随着交叉点的增加,编码结构被破坏的可能性也会增加。
3. 均匀交叉
均匀交叉:是多点交叉的一种特殊形式。
均匀交叉:指基因编码串中,每个基因位都用相同的概率进行交换。
4. 算术交叉
算术交叉:通过线性组合,产生两个新的子代个体。
算术交叉通常是用在:浮点数编码的染色体上(不是常见的二进制)。
5. 基因突变
基因突变(Mutation):就是染色体编码的某一位上的基因,改变了。
(1) 二进制编码
在二进制编码里面,就会按照一定的概率,把基因串上的0、1数字取反。
例子:是一个二进制编码的基因突变。
(2) 浮点型编码
浮点型编码的基因突变:就是对编码数值的增减。
例子:
2.3,5.6,6.2,8.0,6.3
经过基因变异后,可能得到的浮点数串:
2.4,5.5,6.1,7.8,6.5
遗传算法的一般步骤
① 随机构成一个初始种群,然后,计算个体的「适应度」;
② 判断算法:是否满足某一指标(比如:收敛)。如果满足,就停止,然后输出结果;
③ 根据适应值大小进行一个排序,然后根据某一方式进行选择;
④ 按交叉概率,进行交叉操作;
⑤ 按变异概率,进行变异操作;
⑥ 返回步骤 ② ,循环执行。
遗传算法的实现技术:
1. 编码
编码是为了建立个体特征和基因之间的映射关系.
编码:是遗传算法要解决的首要问题,也是设计遗传算法时的一个关键步骤。
编码方法会影响到后续的交叉算子、变异算子等的运算,也会很大程度上决定了遗传进化的效率。
目前,已经提出了许多种不同的编码方法。
总的来说,这些编码方法可以分为三大类:二进制编码法、浮点编码法、符号编码法。
(1) 二进制编码
二进制编码:是遗传算法中最常用的编码方式。
方法:就像人类的基因有AGCT,4种碱基序列一样。在这里我们只用了0和1两种碱基,然后,把他们串成一条链,形成染色体。一个位能表示出2种状态的信息量。所以,足够长的二进制染色体就能够表示出所有的特征。
优点:
- 编码、解码操作,较为简单易懂
- 它相对应的交叉,变异等操作,也比较容易实现。
缺点:
- 当个体特征比较复杂的时候,对应的编码会很复杂,所以,相应的解码过程也会过分繁复。
- 因为这种编码有随机性,所以它的局部搜索能力较差。
为降低算法的复杂性、提高运算效率,可以用浮点数编码的方式。
(2) 格雷码方法
格雷码编码:是二进制编码的一种变形。
区别就是:连续两个整数,所对应的编码值之间,只有一个码位是不同的。
这个区别就解决了二进制编码的缺点(相临数字的距离较远的问题),增强了遗传算法的局部搜索能力。
(3) 浮点编码法
二进制编码虽然简单,但是也存在很多问题,比如:当个体长度较短时,可能达不到精度要求;然后,当个体编码长度较长时,虽然能提高精度,但增加了解码的难度。
浮点数编码方式:用了浮点数来表示个体的每个基因值。
这个浮点数用的就是:某一范围内的一个浮点数。
这种方法,要保证基因值是在给定的区间内;还要保证产生的新个体的基因值,也在这个区间范围内。
优点:
- 浮点数编码可表示的数值范围较大,并且精度较高;
- 可以用于较大空间的遗传搜索;
- 改善了遗传算法的计算复杂性;
- 也可以用于设计针对问题的专门的知识型遗传算子。
(4) 符号编码法
符号编码法:指基因值,可能涉及符号集(如{A,B,C…})。
优点:可以编码有意义的基因值。
2. 群体(= 种群)的规模
种群(population):就是个体的集合,这个集合里面,个体数称为种群。
规模较大的群体:一般个体多样性较高。这样可以避免算法陷入「局部最优解」。
⚠️:增大群体的话,同时也会增加计算的复杂度,降低整体的效率。
群体的规模:一般选在编码长度的倍数值。然后,群体的规模是可变的,可以根据算法的结果进行一些调整。
在实际应用里面,编码长度越长,所需要的群体规模就要越大。
初始群体的选取:一般用随机的方法产生。也可以用启发式的方法,来选取更加优良的群体。
3. 选择策略
选择策略的目的:通过选择函数,从群体中选择优胜的个体,然后,淘汰不满足条件的个体。
所以,选择合适的淘汰策略,也是遗传算法的关键。
常见的策略有:
(1) 基于适应值比例的策略
用适应值作为选择依据。值越低,越容易被淘汰。
代表算法:轮盘赌选择(Roulette Wheel Selection),和它的改进算法。
轮盘赌选择:是一种回放式的随机采样方法。每个个体进入下一代的概率,就等于它的适应度,与整个种群中个体适应度值和的比例。但是,这种方法选择误差比较大。
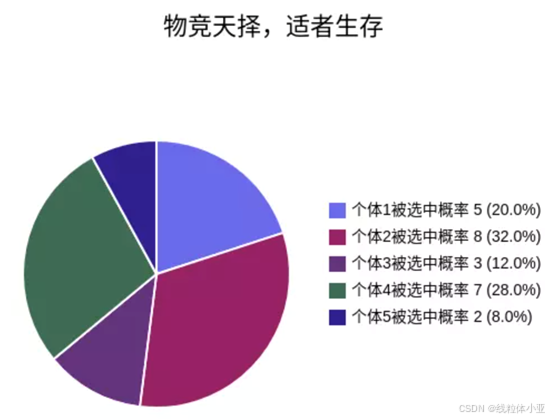
例子:轮盘赌选择:
假如有5条染色体,他们的适应度分别为5、8、3、7、2。
那么总的适应度为:F = 5 + 8 + 3 + 7 + 2 = 25。
那么各个个体的被选中的概率为:
α1 = ( 5 / 25 ) * 100% = 20%
α2 = ( 8 / 25 ) * 100% = 32%
α3 = ( 3 / 25 ) * 100% = 12%
α4 = ( 7 / 25 ) * 100% = 28%
α5 = ( 2 / 25 ) * 100% = 8%
当指针在这个转盘上转动,停止下来时,指向的个体就是被选择的个体。
可以看出,适应性越高的个体被选中的概率就越大。
(2) 基于排名的策略
根据个体的适应度在群体中的排名,来确定被选择的概率。
(3) 基于局部竞争机制的策略
在群体中,随机选择k个个体进行比较,然后选择适应度最好的。
代表算法:局部选择法、联赛选择法等。
4. 适应度 (fitness function) 及选择函数
适应度函数
也叫评价函数。就是计算群体中每个个体,是否满足选择条件。
适应度函数总是非负的,但是,目标函数可能有正有负。所以,需要在目标函数和适应度函数之间进行一些变换。
评价个体适应度的一般过程:
- 对个体编码串,进行「解码」处理后,可以得到个体的表现型。
- 由个体的表现型,可以计算出对应个体的目标函数值。
- 根据最优化问题的类型,由目标函数值,按一定的转换规则,最后求出个体的适应度。
选择函数
常用的选择方法前面讲过了一些,比如,轮盘赌选择法,随机遍历抽样法(轮盘赌选择法的改进),局部选择法,最佳个体保存方法(也叫做复制),排序选择法(根据个体适应值的大小进行排序,然后选择),联赛选择方法(每次选取几个适应度最高的个体,然后遗传到下一代群体中)等。
5. 变异算子
变异算子:就是按一定的概率,发生变异,产生新的遗传基因。
目的:增加种群多样性,提高全局最优搜索能力,保持群体差异,防止过早出现收敛。
常用的变异算法,比如:
- 基本位变异(Simple Mutation):随机对某一位的值做变异运算;
- 均匀变异(Uniform Mutation;
- 非均匀变异;
- 等等。
遗传算法的优越性:
① 可以普遍适用于数值求解问题。而且对目标函数要求低。
② 在求解很多组合优化问题时,不需要对问题有非常深入的理解。而且,计算过程是比较快速简单的。
③ 可以和其他的启发式算法进行兼容。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









