







基本架构
服务器介绍
分布式文件系统就是把数据放在一个服务器集群上。由集群中的服务器一起合作,提供整个文件系统的服务。
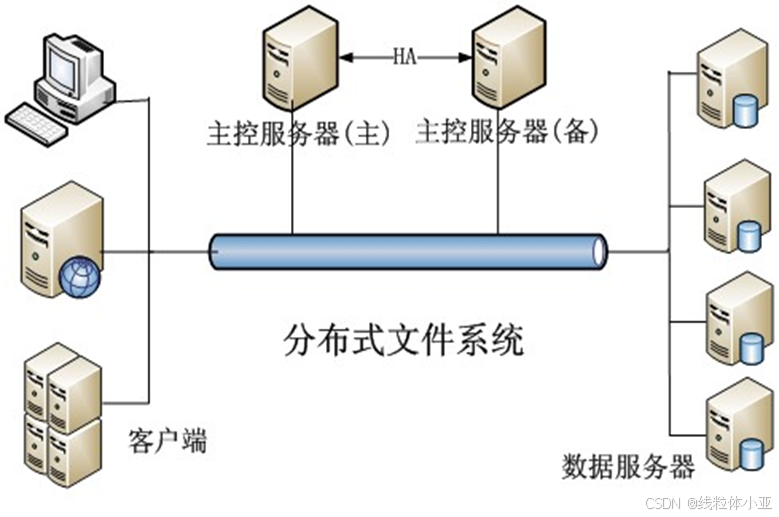
上图:分布式文件系统的典型架构。
其中,重要的服务器:包括,
- 主控服务器 (Master/Name node)
- 数据服务器 (Chunk Server/Data node)
- 客户端
HDFS和GFS都是按照这个架构模式搭建的。
1. 主控服务器
存储目录结构的主控服务器。
在GFS中叫Master;在HDFS中叫Name node。
叫法不一样,但是道理一样:
Master:是对数据服务器的。它就像数据服务器的领导一样,管理各个数据服务器,收集它们的信息,然后给它们分配任务;
NameNode:是针对客户端的。对于客户端来说,主控服务器上放着所有的文件目录信息。如果,要找一个文件,必须问问NameNode。
主控服务器在整个集群里面,同时提供服务的只有一个。
主控服务器主要有4个功能
1) 命名空间的维护
补充:命名空间 (Namespace)
Namespace目的:在不同的命名空间中,如果使用同一个变量名,不会产生冲突。
例如,小明是X公司的员工,工号为123,小红是Y公司的员工,工号也是123。因为两人在不同的公司工作,可以使用相同的工号,不会造成混乱。
这里每个公司就表示一个独立的名字空间。但是,如果两人在同一家公司工作,那么工号就不能相同了,否则,在支付工资时会发生混乱。
Linux系统就引入了命名空间,作用是类似的。操作系统虚拟化之后,不同容器就有不同的命名空间。
主控服务器就负责维护整个文件系统的命名空间。
2) 数据服务器管理
就是集中管理数据服务器。
有2种方式:
- 通过轮询数据服务器
- 数据服务器报告心跳的方式
步骤:
收到客户端的「写」请求时,主控服务器要看各个数据服务器的「负载」等信息,选择一组数据服务器进行服务;
当主控服务器发现,有数据服务器宕机时,就要进行复制;
服务器的负载过高时,主控服务器也要进行迁移。
3) 服务调度
主控服务器的最终目的:服务好客户端的请求。
主控服务器通常的服务模型:包括:
1. 单线程:
主控服务器只能「顺序」地请求服务。所以,效率低。
2. 请求线程
每请求一线程的方式:可以并发的处理请求。
但是,因为系统资源的限制,所以,也会限制创建线程的数量。
3. 线程池(通常配合任务队列)
目前使用较多,通常由单独的线程接受请求,然后加入到任务队列中。
4) 主备容灾
因为主控服务器非常重要,任务也很多。
所以,为了避免主控服务器的单点问题,通常会有备用服务器。
通常的实现方式:通过HA(High Available),UCARP(自动 IP 故障转移)等软件:就是为主控服务器提供一个虚拟IP,然后来提供服务。
当备用服务器检测到主控服务器宕机时,会接管主控服务器的资源 & 服务。
2. 数据服务器
每一个文件的具体数据,会被分成很多的数据块,「冗余」地存放在数据服务器中。
数据服务器的主要工作模式:
定期向主控服务器汇报它的状况,然后就是等待,处理命令,存放数据。
数据服务器主要有3个功能
1) 数据本地存储
最简单的方式是:把客户的每个文件数据,分配到一个单独的数据服务器上,作为一个本地文件存储。
⚠️:但是,这种方式不能很好地利用分布式文件系统的特性,很多文件系统都使用「固定大小」的块来存储数据,典型的块的大小为64MB。
所以,对于「小」文件的存储:可以把多个文件的数据存在一个块里面,然后,为块内的文件建立索引,这样就可以提高存储空间的利用率。
例子:
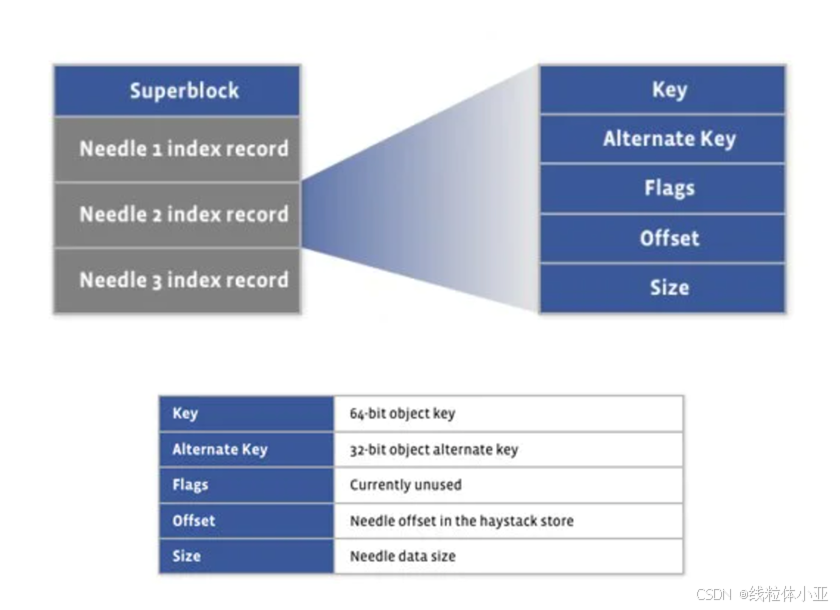
HayStack:它是Facebook 用来存储照片的系统。
它的本地存储方式:把多个图片,存储在一个大文件中,然后,为每个文件的存储位置建立索引。
新创建的图片,会被放到大文件的末尾,然后更新索引。
在删除文件时,就会设置文件头的删除标记,系统在空闲时,会把超过一定时限的文件,进行回收。
对于「大」文件的存储:就是把文件存储到多个块上,多个块所在的数据服务器可以「并行」服务。

2) 状态维护
就是需要维护一些状态。
首先,它要把自己的状态,用心跳包的方式,周期性地报告给主控服务器。让主控服务器知道自己是不是在正常工作。
通常,心跳包中还会包含数据服务器当前的负载状况(比如,CPU、内存、磁盘I/O、磁盘存储空间、网络I/O、等)。这些信息可以帮助主控服务器制定「负载均衡」策略。
3) 副本管理
为了保证数据的安全性,分布式文件系统中的文件,会存储多个副本到数据服务器上。
写多个副本的方式,主要分为3种:
第一种方式(最简单的方式):客户端「分别」向多个数据服务器,写同一份数据。例如,DNFS采用的就是这种方式;
第二种方式:客户端向主控服务器写数据,然后,主控服务器向其他数据服务器「转发」数据。例如,TFS采用的就是这种方式;
第三种方式:用流水复制的方式。客户端向某个数据服务器写数据,这个数据服务器向副本链中的下一个数据服务器转发数据,以此类推。例如,HDFS,GFS用的就是这种方式。
当有节点宕机或节点间负载极不均匀时,主控服务器会制定一些副本复制或迁移计划。
数据服务器:是「实际」执行这些计划的。
3. 客户端
客户端:是以一个类库(包)的模式存在,为用户提供文件读/写,目录操作等。
客户端主要有两个功能:
1) 接口
用户,最终通过文件系统提供的接口来存取数据。
在Linux环境下,提供POSIX(Portable Operating System Interface,可移植操作系统接口)接口。
补充:POSIX就是一系列API标准的总称。
有了POSIX接口的支持,很多的应用(各种语言的都可以)能可以不用修改的,把本地文件转换成分布式文件存储。

2) 缓存
为了加速文件存取的过程,同时,减小主控服务器的负担,可以把元信息进行缓存。
数据可以根据业务特性,缓存在本地或磁盘上,也可缓存在远端的Cache系统上。
维护缓存需要考虑2个问题:
1. 如何解决一致性问题。
一致性的维护:可以由客户端完成,也可以由服务器完成。
- 客户端:周期性地使Cache失效,或者检查Cache的有效性;
- 服务器:在元数据更新后,通知客户端,使Cache失效。
2. 缓存替换算法。
使用比较多的替换算法有:LRU(Least Recently Used,近期最少使用算法),随机替换等。
总结
总结了典型的分布式文件系统的架构(包括:主控服务器,数据服务器,客户端)。
大概介绍了:分布式文件系统的基本原理,它们要解决的问题,和解决问题的基本方法。
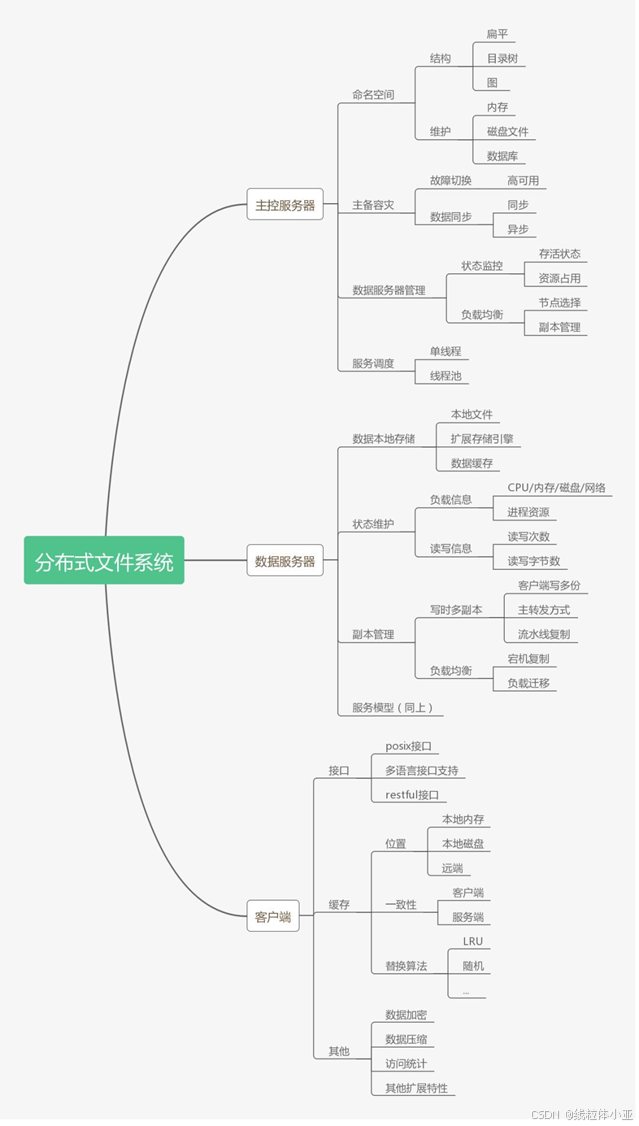
数据分布
在一个文件系统中,最重要的数据:就是整个文件系统的目录结构 & 具体每个文件上的数据。
具体的文件数据被切分成「数据块」,存放在数据服务器上。
每一个文件数据块,在数据服务器上都表示为「一对」文件(这是普通的Linux文件):
一对里面:
- 一个是数据文件;
- 另一个是附加信息的元文件,就是:数据块文件。
数据块文件:放在数据目录下。它有一个名为 current的根目录,然后,里面有很多的数据块文件和子目录(dir0 ~ dir63,最多64个子目录)。
这个是磁盘上的物理结构,和它对应的是内存中的数据结构。
就是:
Block类,用于表示数据块。
FSDataset类:就是数据服务器,管理文件块的数据结构。
其中,
FSDataset.FSDir:对应着数据块的文件和目录;
FSDataset.FSVolume:对应着一个数据目录;
FSDataset.FSVolumeSet:是FSVolume的集合,每一个FSDataset有一个FSVolumeSet。
前面写的是:数据服务器里的数据。
相比来说,主控服务器的数据量不大,但逻辑更复杂。
主控服务器主要有3类数据:
- 文件系统的目录结构数据;
- 各个文件的分块信息;
- 数据块的位置信息:就数据块放置在哪些数据服务器上。
在 GFS和HDFS的架构里面,只有文件的目录结构 & 分块信息:会被持久化到本地磁盘上。
而数据块的位置信息:是动态地汇总过来的,仅存活在内存数据结构里面。
服务器间协议
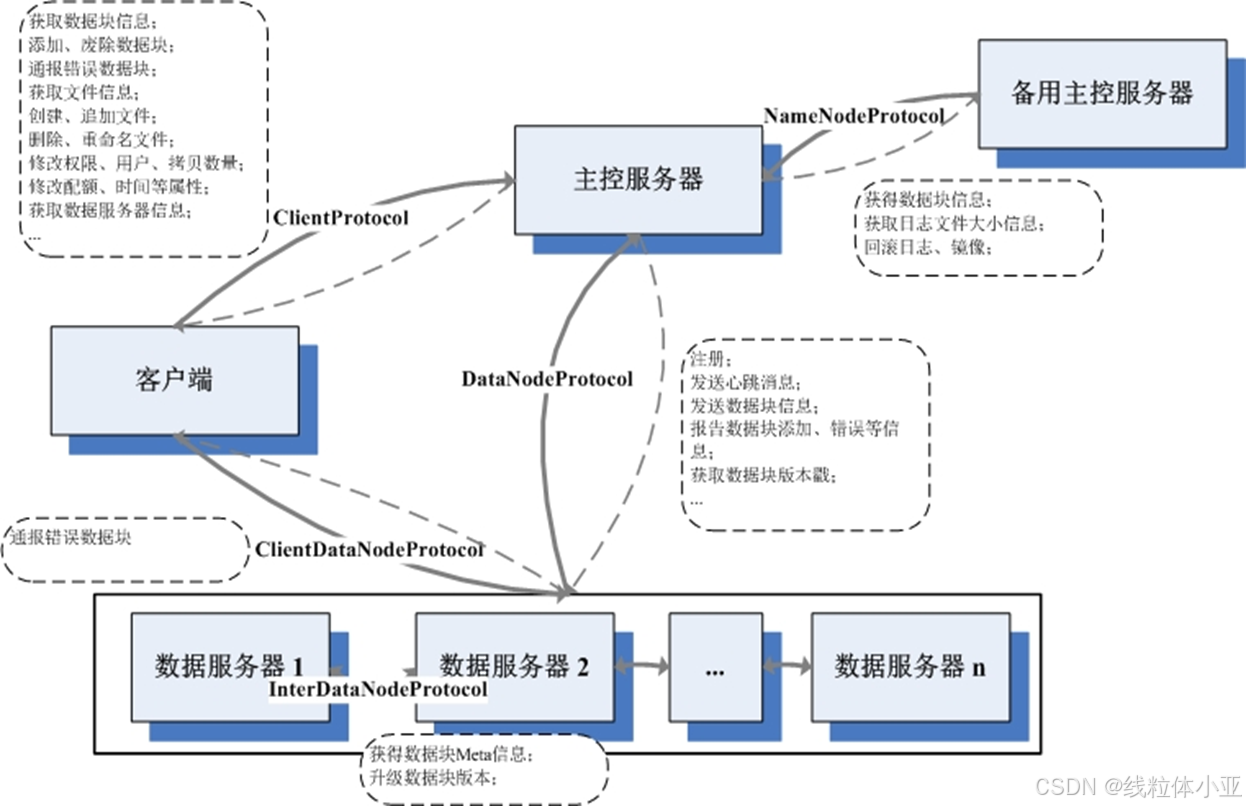
客户端,主控服务器,数据服务器之间,遵循的协议。
例如,
客户端 & 主控服务器之间的ClientProtocol;
主控服务器 & 数据服务器之间的 DataNodeProtocol等。
在Hadoop里面,部署了一套RPC机制(Remote Procedure Call Protocol,远程过程调用协议)。
目的:实现各服务器间的通信协议。
基于RPC的通信模式,是一个消息拉取的流程:就是RPC服务器等待RPC客户端的调用,但是,是不会主动把相关信息推送到RPC客户端的。

















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









