







业务需求的升级和数据量的增长推动着技术的升级变革和创新。当下会员标签数据也正在从最初的Mysql关系型数据库迁移到ES。以满足更高数据量下业务方对查询性能和数据分析的要求。目前来看,ES能完美解决当下数量级的查询及分析聚合要求,但是ES的数据量上到十亿级别,性能还是有所退化,查询速度就显得捉襟见肘。用户是最不喜欢等待的,超过1秒的等待都是不太好的用户体验。我在以往的工作中,有过使用Hadoop全家桶+SparkStreaming来分析聚合网络流量数据的经历。后期替换为CH,它们性能差距接近10倍。相比之下,CH使用的CPU和内存还少的多。
未来用户量也会不断增长,根据业务需要肯定会衍生出更多维度的用户标签。在海量数据下,能存储用户个性化标签,并且为实时精细化营销提供分析服务的,非CH莫属,在 '快' 这一点上,它独领风骚。1亿数据集体量下,官方基准测试43项SQL查询,平均相应速度是Mysql的429倍。若一个磁盘允许以400MB/s的速度读取数据,并且数据压缩率是3,查询一个10字节的列,那么它的处理速度大约是1-2亿行每秒。将一份数据写入到MergeTree表中时,写入速度大约为50到200MB/s。如果写入的数据每行为1Kb,那么写入的速度为50,000到200,000行每秒。
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
OLTP(联机事务处理):主要用来记录业务事件的发生,如用户上了一节课,当行为产生后,系统会记录是谁在何时上了一节什么课,这样的一行(或多行)数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功,像公司常见的业务系统如ERP,CRM,OA等系统都属于OLTP。
OLAP(联机分析处理):当用户上的课多了,我们可以对用户上课的时间,偏好,习惯做一个总结分析时,就需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取我们想要的信息,为运营做决策提供支持,这就是OLAP。
核心特性一:一个完整的DBMS(数据库管理系统)
CH作为一个DBMS,支持DBMS的基本特性:
- DDL:可以动态创建、修改或删除数据库、表和视图,而无需重启服务
- DML:可以动态查询、插入、修改和删除数据
- 权限控制:支持按照用户粒度设置数据库或表的操作权限
- 数据备份和恢复:提供了数据备份导出和导入恢复机制
- 分布式管理:提供集群模式
核心特性二:列式存储和数据压缩-为什么快的原因之一
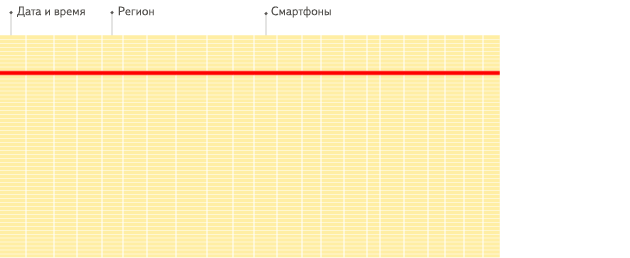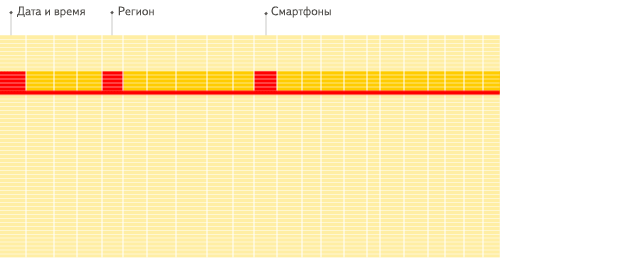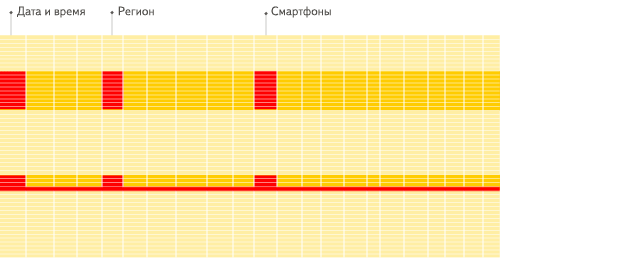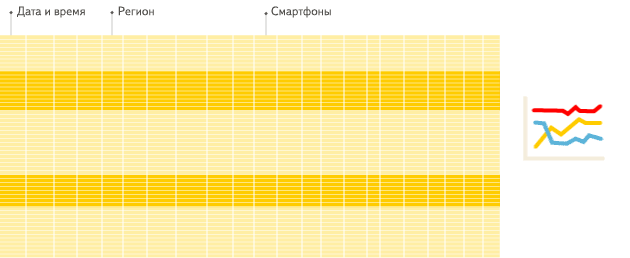
首先看下列式和行式在数据聚合分析的区别
行式数据库:



列式数据库:
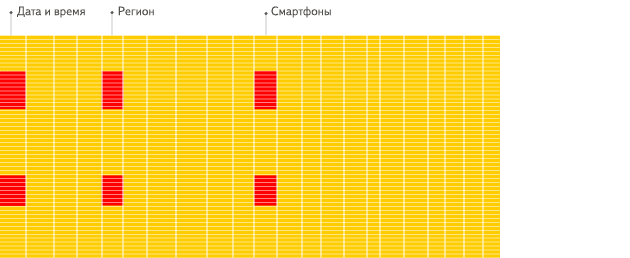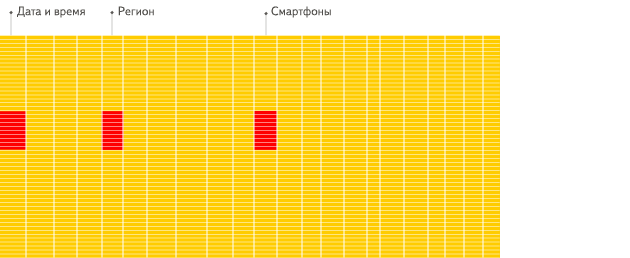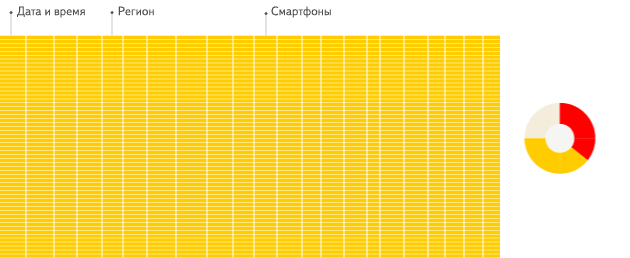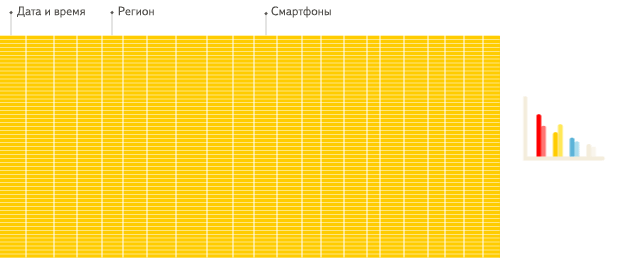
提升查询速度,最简单有效的方法就是减少数据扫描范围和数据传输时的大小,列式存储和数据压缩就可以实现这两点。如果需要对一个50个字段的表中的5个字段做查询分析,行式数据库需要扫描每一行,然后获取到其中的5列数据。列式数据库只需要直接扫描这5列数据就可以了。避免扫描多余的数据。
按列存储相比于按行存储的另一个优势就是对数据压缩的天然友好。举个栗子说明压缩的本质:
假设有2个用户标签-活动来源,'新世界项目,双11赠送'和'新世界项目',现在对它们进行压缩,如下所示
压缩前:新世界项目,双11赠送_新世界项目
压缩后:新世界项目,双11赠送_(11,5)
压缩的本质是按照一定的步长对数据进行扫描匹配,当发现重复部分的时候就进行编码转换。(11,5)表示从'_'开始往前数11位,可以匹配到5个字节长度的重复项。真实的压缩算法肯定比这个更复杂。数据中的重复项越多->则压缩率越高->则数据量体量越小->数据在网络中的传输越快->对网络带宽和磁盘IO的压力约小。同一列的数据天然的重复项最多,天生适合压缩。
CH主要的MergeTree引擎下,列与列会由不同的文件分别保存,来自不同列的值被单独存储,来自同一列的数据被存储在一起。数据默认使用LZ4压缩算法,Yandex.Metrica的生产环境下压缩比可以达到8:1。
核心特性三:向量化执行引擎-为什么快的原因之一
都知道开多线程利用CPU多核心提高处理速度。类似的,向量化执行是CPU寄存器级别的并行操作。为了实现向量化执行,需要利用CPU的SIMD指令,即用单条指令操作多条数据。在CPU寄存器层面实现数据的并行操作。
SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。
一般流程:每次从内存加载一个数据寄存器进行运算
SIMD:一次加载多个数据到专用寄存器,则一条指令就能进行多个数据的加乘运算
以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。
CH正是利用向量化执行的特性,提升了自身性能。
核心特性四:关系模型与完善的SQL查询支持
CH使用关系模型描述数据并提供了传统数据库的相关概念(数据库,表,视图和函数等等)。CH完全使用SQL作为查询语言(支持GROUP BY、ORDER BY、JOIN、IN等大部分标准SQL)。非常容易理解上手。现实经验来看,前期用户量,数据量小,大量数据分析建模工作都是基于关系型数据库开始的。CH使用关系模型,所以将传统关系型数据库迁移到CH成本非常低。
核心特性五:多线程与分布式
向量化执行是通过数据级并行的方式提升了性能,那么多线程处理就是通过线程级并行的方式实现了性能的提升。一台服务器性能不够,那么就利用多台服务器的资源协同处理。CH能充分利用每一台廉价的机器。Hadoop全家桶中的YARN就是这种思想的成熟运用者。根据不同的任务动态的从集群中申请资源(CPU核心,内存),分而治之,共同完成数据分析聚合的目标(参考MapReduce原理)。比如本批次需要分析的数据2000w行,分布在5台服务器上分别存储,只需要在5台服务器上都运行相同的计算任务,每台服务器分析400w行上下的数据,然后把结果汇总,就得到了最后的分析结果。当然,前提是数据是分布式存储的。学习大数据入门的第一句话一定是:“移动计算比移动数据更划算”。CH的思想也是一模一样的。CH既支持分区(纵向扩展,利用多线程原理),也支持分片(横向扩展,利用分布式原理),可以说将多线程和分布式技术运用到了极致。
核心特性六:多主架构
HDFS,HBase和ES这类分布式系统,都采用了Master-Slave主从架构,由一个管控节点作为Leader统筹集群。而CH不一样,它是Multi-Master架构,集群中每个节点角色对等,不区分数据节点和计算节点,客户端访问任意一个节点都能得到相同的结果,集群中所有节点功能相同。所以它天然避免了单点故障问题!
CH的一些其他特点:
- 数据分片,本地表和分布式表概念
- 支持批量更新(小数据量反而不适合它)
- 不依赖臃肿的Hadoop全家桶,开箱即用
CH的一些缺点特性(事实上其他同类型OLAP数据库同样不擅长这些,为了极致查询性能所做的权衡):
- 不支持事务
- 不擅长根据主键按行粒度进行查询(虽然本身支持)
- 不擅长按行删除数据(虽然本身支持)















 5249
5249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









