






问题出现
在周五晚上,突然收到公司系统告警信息,提示一个内部使用的在线文件浏览服务不可用了。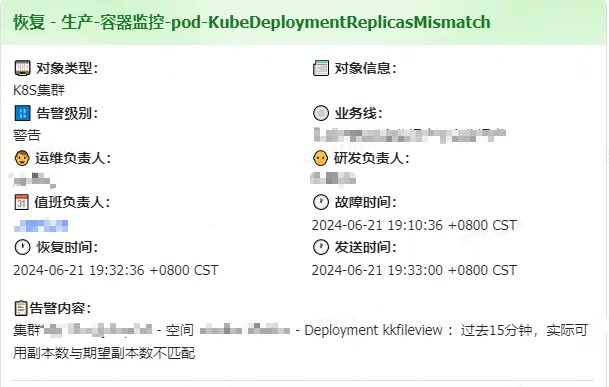
收到这个消息之后,就先马上滚动重启了Pod,然后服务也可用了。
问题定位
周一的早上,秉承着不能放过任何一次排查BUG的机会水文章的机会。回到公司后,到日志平台中查看那个时间段的日志,发现故障时间远比通知中的时间要早。并且在日志中也发现了本次的问题根因:OOM!
问题分析
在看到OOM时我是非常诧异的,都2024年了,在这个内存这么充足的年代而且这个服务的访问量并不是太大的情况下,还能出现OOM。
这个服务是内部OA系统的文件预览服务,使用开源的KKFileView
于是乎我去公司内部的K8S治理平台上查看这个服务的部署YAML配置,发现在系统内存这块,Pod最少需要512M,最多需要4G,讲道理,应该不会出现OOM的情况。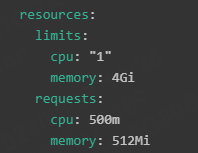
然后我又去监控平台上查看出现故障时间段中,Pod的内存使用量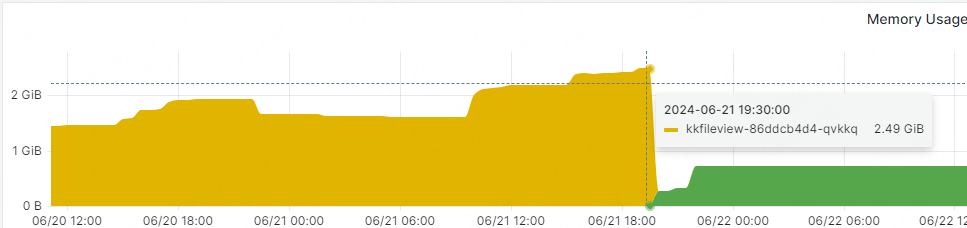
黄色的是之前出现OOM的Pod内存使用数据,绿色的是新启动的内存使用量。
可以看到,在最高点的内存占用也才2.49G,距离Pod最大内存上限4G还有1.5个G的空间,不应该会出现OOM啊。
监控没到上限,然后又OOM,那只能去看JVM的启动参数了,看启动程序时JVM的最大堆配置了多少。
于是跑到正在运行的Pod中执行以下命令查看JVM的内存参数
jmap -heap 1
得到以下结果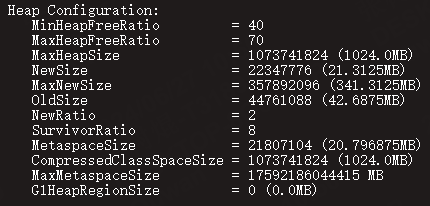
才发现怎么最大堆才1个G啊,我Pod启动配置的明明是4个G。然后我又去构建Docker镜像的DockerFile中看有没有配置启动参数,发现也是没有配置的。
那就只能得出一个结论了,JVM启动的时候,默认将最大堆设置成了1G。
为什么只有1G呢,我从官网中找到了计算最大堆的计算方法:The Parallel Collector
官网中说到,如果没有在启动时指定了初始和最大堆大小,那么就会根据机器上的内存大小进行计算。
- 32 位 JVM:
- 如果物理内存小于 2GB,最大堆大小为物理内存的 1/4。
- 如果物理内存大于或等于 2GB,最大堆大小为 512MB。
- 64 位 JVM:
- 如果物理内存小于 2GB,最大堆大小为物理内存的 1/4。
- 如果物理内存大于或等于 2GB,最大堆大小为物理内存的 1/4,但最多不超过 32GB。
这个计算规则跟Pod上的也一致,那就是这个原因导致的了。没有指定启动时的JVM参数,导致程序在运行中OOM了。
问题修复
定位到了问题,并且了得知了问题出现的原因,这个就好解决了。啪,直接一顿操作下来,将JVM的最大堆参数设置成2个G。
题外话
我一开始在想这个OOM究竟是怎么引起的时候,还以为是kkFileView哪里内存泄漏了,没想到是JVM的堆大小居然会这么小。直到一步步的排查,才知道JVM的动态获取堆最大值的计算方式。
解决了OOM之后,又会有一个新的问题。为什么这个kkFileView在1G的情况下会出现OOM呢?
这个问题展开又够写水一篇文章的了,那么就下篇文章再见了😉。















 883
883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









