







题型分布
- 填空题 5*2’=10’
- 计算题 2*10’=20’
- 简答题 2*10’=20’
- 实证分析4*10’=40’ 建模步骤和代码实现(简洁函数)
- 证明题1*10’=10’
PART Ⅰ R软件与金融数据
1 金融数据分析中的R软件介绍
不同的时间序列的区别与生成
生成等间隔时间序列/生成非等间隔时间序列/给一段代码说明用法
ts类型
ts是基本R软件的stats包中支持的规则时间序列类型, 具有start和frequency两个属性, 对于年度数据,frequency=1, 对于月度数据,frequency=12
但是日数据最好不时间标签为具体日历时间的ts类型, 因为金融数据的日数据在周末和节假日一般无数据, 而ts类型要求时间是每一天都相连的, 不能周五直接跳到周一。
年度时间序列
yd <- ts(
c(4, 8, 7, 7, 3, 1, 8, 9, 8, 6, 3, 5,
5, 8, 2, 5, 9, 2, 5, 2, 3, 2, 2, 4),
frequency=1, start=2001); yd
## Time Series:
## Start = 2001
## End = 2024
## Frequency = 1
## [1] 4 8 7 7 3 1 8 9 8 6 3 5 5 8 2 5 9 2 5 2 3 2 2 4
月度时间序列
ym <- ts(
c(9, 6, 3, 5, 4, 8, 2, 5, 8, 4, 6, 3,
2, 2, 6, 4, 1, 4, 2, 1, 8, 9, 4, 6),
frequency=12, start=c(2001,1)); ym
## Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
## 2001 9 6 3 5 4 8 2 5 8 4 6 3
## 2002 2 2 6 4 1 4 2 1 8 9 4 6
zoo类型
R的zoo扩展包提供了比基本R中ts时间序列类型更灵活的时间序列类型, 其时间标签(time stamp)可以使用R中任何的日期和时间类型, 序列不需要是等时间间隔的,支持多元时间序列。
如果序列符合ts类型的要求, 则与ts类型兼容并可以互相转换。
set.seed(1)
z.1 <- zoo(sample(3:6, size=12, replace=TRUE),
make_date(2018, 1, 1) + ddays(0:11)); z.1
## 2018-01-01 2018-01-02 2018-01-03 2018-01-04 2018-01-05 2018-01-06 2018-01-07
## 3 6 5 3 4 3 5
## 2018-01-08 2018-01-09 2018-01-10 2018-01-11 2018-01-12
## 5 4 4 5 5
set.seed(2)
z.2 <- zoo(cbind(x=sample(5:10, size=12, replace=TRUE),
y=sample(8:13, size=12, replace=TRUE)),
make_date(2018, 1, 1) + ddays(0:11)); z.2
## x y
## 2018-01-01 9 10
## 2018-01-02 10 13
## 2018-01-03 10 9
## 2018-01-04 5 10
## 2018-01-05 9 8
## 2018-01-06 5 13
## 2018-01-07 8 8
## 2018-01-08 9 11
## 2018-01-09 5 10
## 2018-01-10 6 13
## 2018-01-11 7 8
## 2018-01-12 5 13
时间不必是连续的,如
set.seed(1)
z.3 <- zoo(101:112,
make_date(2018, 1, 1) +
ddays(sample(0:30, 12, replace=FALSE))); z.3
## 2018-01-01 2018-01-02 2018-01-04 2018-01-07 2018-01-10 2018-01-11 2018-01-14
## 104 105 102 103 112 107 108
## 2018-01-18 2018-01-19 2018-01-23 2018-01-25 2018-01-28
## 109 110 106 101 111
注意输入的随机生成的日期次序是乱序的, 但生成zoo时间序列后一定会按照正常时间序列排好次序。
xts类型
library(xts, quietly = TRUE) #世界安静了
xts.1 <- xts(
c(5, 5, 4, 6, 4, 3, 3, 3, 4, 5, 5, 4),
make_date(2018, 1, 1) + ddays(0:11)); xts.1
## [,1]
## 2018-01-01 5
## 2018-01-02 5
## 2018-01-03 4
## 2018-01-04 6
## 2018-01-05 4
## 2018-01-06 3
## 2018-01-07 3
## 2018-01-08 3
## 2018-01-09 4
## 2018-01-10 5
## 2018-01-11 5
## 2018-01-12 4
xts包的设计目标是使得以xts为输入的函数可以兼容其它时间序列类型的输入, 并可以很方便地增加属性
xts类型与zoo类型的差别如下:
-
xts类型必须使用正式的时间类型作为时间下标, zoo类型的时间下标更普遍。 xts目前仅允许使用Date, POSIXct, chron, yearmon, yearqtr, timeDate作为时间下标。
-
xts包含一些独有的内部属性, 包括.CLASS, .ROWNAMES等。 这是为了能够无损地与其他时间序列类型互相转换而保存的其它时间序列类型的部分额外信息。
-
xts具有用户添加属性。 这使得xts类型是用户可定制的数据类型, 用户可以随意添加或者删除自定义属性, 不会影响到数据的显示和计算。 与其他时间序列类型互相转换所需的部分额外信息也保存为用户添加属性。
如何读取桌面上的文件
txt/csv文件
如何从网站上获取财经类的数据
(1) quantmod
quantmod包提供了一个getSymbols()函数, 可以从多个公开数据源下载金融和经济数据并转换为R格式(主要是xts格式), 数据源包括(有些在国内可能无法访问):
例如,从雅虎金融下载微软公司的日数据, 股票代码MSFT:
MSFT <- getSymbols("MSFT", src="yahoo", auto.assign = FALSE)
head(MSFT)
## MSFT.Open MSFT.High MSFT.Low MSFT.Close MSFT.Volume MSFT.Adjusted
## 2007-01-03 29.91 30.25 29.40 29.86 76935100 22.96563
## 2007-01-04 29.70 29.97 29.44 29.81 45774500 22.92717
## 2007-01-05 29.63 29.75 29.45 29.64 44607200 22.79642
## 2007-01-08 29.65 30.10 29.53 29.93 50220200 23.01947
## 2007-01-09 30.00 30.18 29.73 29.96 44636600 23.04254
## 2007-01-10 29.80 29.89 29.43 29.66 55017400 22.81180
从雅虎金融获取美国10年债日数据:
TNX <- getSymbols("^TNX", auto.assign = FALSE) # CBOE 10年国债日数据
head(TNX)
## TNX.Open TNX.High TNX.Low TNX.Close TNX.Volume TNX.Adjusted
## 2007-01-03 4.658 4.692 4.636 4.664 0 4.664
## 2007-01-04 4.656 4.662 4.602 4.618 0 4.618
## 2007-01-05 4.587 4.700 4.583 4.646 0 4.646
## 2007-01-08 4.668 4.678 4.654 4.660 0 4.660
## 2007-01-09 4.660 4.670 4.644 4.656 0 4.656
## 2007-01-10 4.666 4.700 4.660 4.682 0 4.682
(2)用BatchGetSymbols包下载金融数据
library(BatchGetSymbols)
first.date <- Sys.Date() - 60
last.date <- Sys.Date()
freq.data <- "daily"
# set tickers
tickers <- c(
"S&P500" = c,
"Facebook" = "FB",
"上证综指" = "000001.SS",
"兴业银行" = "601166.SS",
"中兴通讯" = "000063.SZ"
)
l.out <- BatchGetSymbols(
tickers = tickers,
first.date = first.date,
last.date = last.date,
freq.data = freq.data,
cache.folder = file.path(
tempdir(), 'BGS_Cache') ) # cache in tempdir()
## Running BatchGetSymbols for:
## tickers =.Primitive("c"), FB, 000001.SS, 601166.SS, 000063.SZ
## Downloading data for benchmark ticker
## ^GSPC | yahoo (1|1) | Found cache file
## .Primitive("c") | yahoo (1|5) | Not Cached - Error in download..
## FB | yahoo (2|5) | Found cache file - Got 100% of valid prices | OK!
## 000001.SS | yahoo (3|5) | Found cache file - Got 86% of valid prices | Good stuff!
## 601166.SS | yahoo (4|5) | Found cache file - Got 86% of valid prices | Got it!
## 000063.SZ | yahoo (5|5) | Not Cached | Saving cache - Got 86% of valid prices | You got it!
常用的软件包是用来做什么的?
library(tidyverse) # Wickham的数据整理的整套工具
library(lubridate) # 日期和日期时间数据处理
library(quantmod) # 金融数据的整理与作图功能
MTS:MTSplot(cbind(ts2,ts2)) # 画出两个并列的时序图
ccm(cbind(ts1,ts2))
fBasics::basicStats(x)
fBasics::basicStats(x)["Kurtosis", 1]
fBasics::basicStats(x)["Skewness", 1]
fBasics::normalTest(x, method="jb") #正态性检验 p<0.05 拒绝原假设 不是正态分布
library(xts) # 时间序列数据的常见格式 用来做格式转换的
tseries包中的get.hist.quote()函数可以从网上获取各主要股票的日交易数据。
fracdiff库的fracdiff可以拟合分数ARIMA模型。
tseries包中的garch可以拟合GARCH和ARCH模型。 经常用GARCH(1,1)拟合收益数据。 rugarch包有更强大的GARCH功能,比如使用t分布残差。
fSeries包中的garchFit可以拟合较复杂的包含GARCH的模型。
car包中的durbin.watson函数可以对lm对象进行Durbin-Watson自相关检验。 ts包中的Box.test可以进行Box-Pierce或Ljung-Box白噪声检验。 tseries包中的adf.test可以进行Dickey-Fuller单位根检验。
2 金融数据及其特征
各个之间的关系
1
+
R
t
=
P
t
P
t
−
1
1+R_t=\frac{P_t}{P_{t-1}}
1+Rt=Pt−1Pt
对数收益率
r
t
r_t
rt和简单收益率
R
t
R_t
Rt的近似关系
r
t
=
ln
(
1
+
R
t
)
r_t=\ln(1+R_t)
rt=ln(1+Rt)
股票价格
P
t
P_t
Pt和对数收益率
r
t
r_t
rt和的关系
r
t
=
ln
P
t
−
ln
P
t
−
1
r_t=\ln{P_t}-\ln{P_{t-1}}
rt=lnPt−lnPt−1
收益率的分布(重尾分布)
如何判断它是重尾分布?怎么检验它的正态分布?
基本统计量(超额峰度)
对于所有正态分布来说峰度等于3,许多统计软件会给出超额峰度(excess kurtosis),也就是峰度减去3之后的值。一个正态分布或者其他中峰分布的超额峰度为0, 一个尖峰分布(尖峰==厚尾)的超额峰度大于0,一个低峰分布的超额峰度小于0。
fBasics::basicStats(x)
## Skewness -0.323171<0
## Kurtosis 5.486581>0
这里的Kurtosis是超额峰度。 有左偏,重尾。
直方图,作核密度估计图并叠加正态密度估计
hist(x, nclass=30, main="Apple Log Returns")

作核密度估计图并叠加正态密度估计:
tmp.1 <- density(x, na.rm=TRUE)
tmp.x <- seq(min(x, na.rm=TRUE), max(x, na.rm=TRUE),
length.out=100)
tmp.y <- dnorm(tmp.x, mean(x, na.rm=TRUE),
sd(x, na.rm=TRUE))
tmp.ra <- range(c(tmp.1$y, tmp.y), na.rm=TRUE)
plot(tmp.1, main="Apple Log Return",
ylim=tmp.ra)
lines(tmp.x, tmp.y, lwd=2, col="red")
legend("topleft", lwd=c(1,2),
col=c("black", "red"),
legend=c("Kernel density Est.",
"Parametric normal density est."))
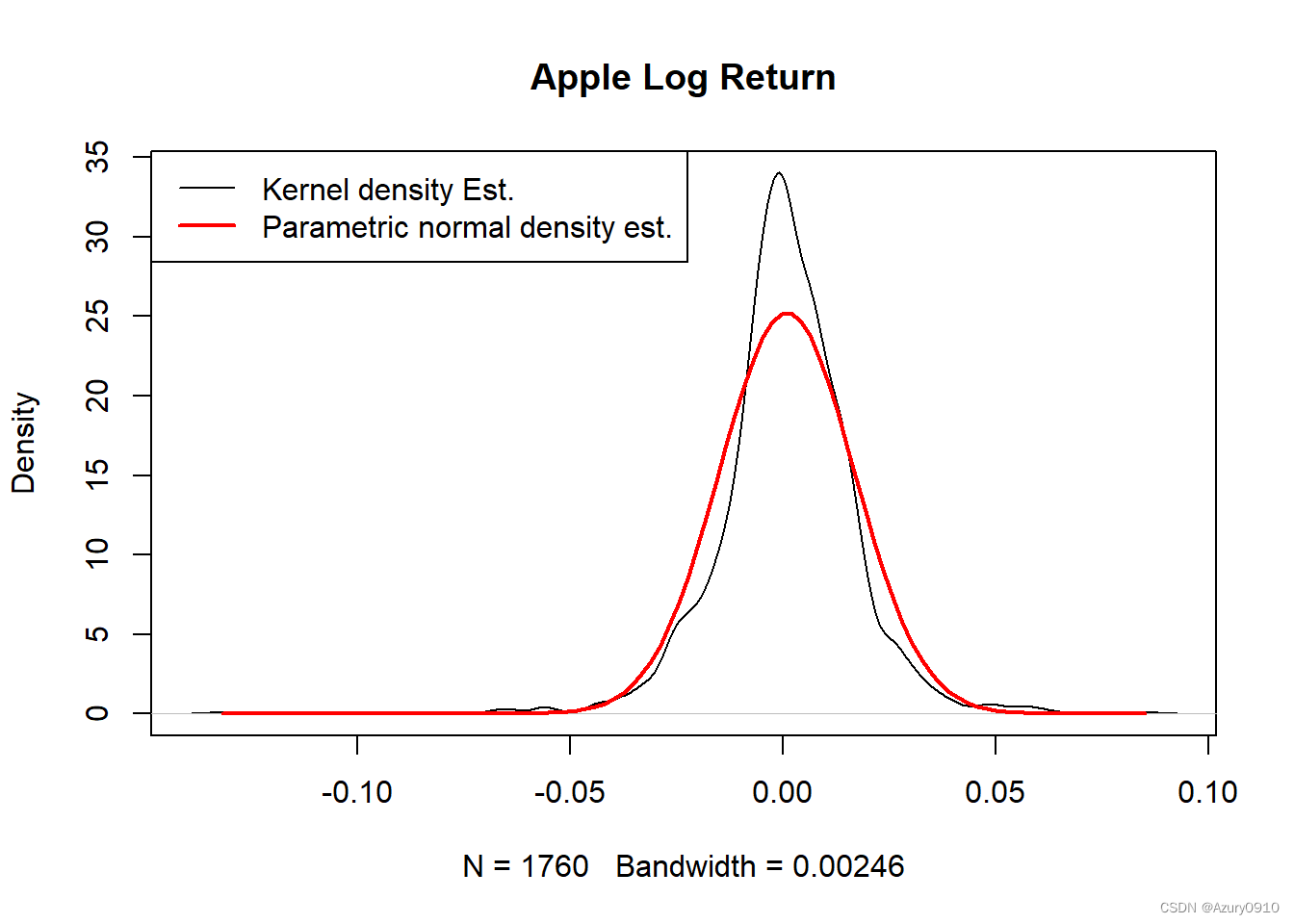
比正态密度明显重尾, 且左尾比右尾长。
均值为零的检验
均值为零的检验
t.test(x)
##
## One Sample t-test
##
## data: x
## t = 2.0935, df = 1759, p-value = 0.03644
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## 0.0000498348 0.0015282461
## sample estimates:
## mean of x
## 0.0007890405
检验 p p p值为0.036,在0.05水平下显著, 可认为均值不为零,显著地大于零。
偏度及其标准化
单独计算偏度,及其标准化:
tmp <- fBasics::basicStats(x)["Skewness", 1]; tmp
标准化
tmp/sqrt(6/length(x))
标准化值的绝对值超过1.96, 在0.05水平下拒绝偏度等于零的假设。
超额峰度及其标准化
单独计算超额峰度,及其标准化:
tmp <- fBasics::basicStats(x)["Kurtosis", 1]; tmp
tmp/sqrt(24/length(x))
标准化值的绝对值超过1.96, 在0.05水平下拒绝峰度等于零的假设。
正态性JB检验
fBasics::normalTest(x, method="jb")
##
## Title:
## Jarque - Bera Normalality Test
##
## Test Results:
## STATISTIC:
## X-squared: 2245.9834
## P VALUE:
## Asymptotic p Value: < 2.2e-16
##
## Description:
## Tue Feb 22 10:38:12 2022 by user: Lenovo
p值为小于万分之一的值, 在0.05水平下显著,拒绝原假设,则该分布不满足正态性假设
PART Ⅱ 一元线性时间序列模型
3 线性时间序列模型
平稳时间序列的定义
设有随机变量序列 { x t , t = … , − 2 , − 1 , 0 , 1 , 2 } \{x_t,t=…,-2,-1,0,1,2\} {xt,t=…,−2,−1,0,1,2}, 称其为一个时间序列。
弱平稳序列(宽平稳序列,weakly stationary time series): 如果时间序列 { X t } \{X_t\} {Xt}存在有限的二阶矩且满足:
- E X t = μ EX_t=\mu EXt=μ与 t t t无关
- V a r ( X t ) = γ 0 Var(X_t)=\gamma_0 Var(Xt)=γ0与 t t t无关
- γ k = C o v ( X t − k , X t ) , k = 1 , 2 , . . . \gamma_k=Cov(X_{t-k},X_t),k=1,2,... γk=Cov(Xt−k,Xt),k=1,2,...与 t t t无关
则称 { X t } \{X_t\} {Xt}为弱平稳序列。
严平稳序列
对时间序列
{
X
t
}
\{X_t\}
{Xt}, 如果对任意的
t
∈
Z
t\in\mathbb{Z}
t∈Z和正整数
t
t
t,
k
k
k,
(
X
t
,
…
,
X
t
+
n
−
1
)
(X_t,\dots,X_{t+n-1})
(Xt,…,Xt+n−1)总是与
(
X
t
+
k
,
…
,
X
t
+
n
−
1
+
k
)
(X_{t+k},\dots,X_{t+n-1+k})
(Xt+k,…,Xt+n−1+k)同分布, 则称
{
X
t
}
\{X_t\}
{Xt}为严平稳时间序列。
时间序列是特殊的随机过程
随机过程的定义
依赖于时间t的**一族(无限多个)**随机变量,记为{X(t),t∈T} ,t也可以为次序、间隔等。
白噪声检验
如果弱平稳序列 { X t } \{X_t\} {Xt}满足 ρ k = 0 \rho_k=0 ρk=0, k = 1 , 2 , … k=1,2,\dots k=1,2,…,称 { X t } \{X_t\} {Xt}为白噪声序列。
H 0 : ρ 1 = ⋯ = ρ m = 0 ⟷ H a : 不全为零 H_0: \rho_1 = \dots = \rho_m = 0 \longleftrightarrow H_a: \text{不全为零} H0:ρ1=⋯=ρm=0⟷Ha:不全为零
原假设是序列为白噪声过程
在R软件中, Box.test(x, type="Ljung-Box")执行Ljung-Box白噪声检验。 Box.test(x, type="Box-Pierce")执行Box-Pierce混成检验。 用fitdf=指定要减去的自由度个数。
示例:
读入数据:
d <- read_table(
"m-ibmsp-2611.txt", col_types=cols(
.default=col_double(),
date=col_date(format="%Y%m%d")))
ibm <- ts(d[["ibm"]], start=c(1926,1), frequency=12)
读入的是简单收益率的月度数据。 作ACF图:
forecast::Acf(ibm) #acf(ibm)

从ACF来看月度简单收益率是白噪声。
作Ljung-Box白噪声检验, 分别取 m = 12 m=12 m=12和 m = 24 m=24 m=24:
Box.test(ibm, lag=12, type="Ljung-Box")
##
## Box-Ljung test
##
## data: ibm
## X-squared = 13.098, df = 12, p-value = 0.362
p = 0.362 > 0.05 p= 0.362>0.05 p=0.362>0.05
Box.test(ibm, lag=24, type="Ljung-Box")
##
## Box-Ljung test
##
## data: ibm
## X-squared = 35.384, df = 24, p-value = 0.0629
p = 0.0629 > 0.05 p= 0.0629>0.05 p=0.0629>0.05
在0.05水平下均不拒绝原假设, 支持IBM月度简单收益率是白噪声的原假设。
Box-Pierce检验和Ljung-Box检验受到取值 m m m的影响, 建议采用 m = ln T m=\ln{T} m=lnT, 且序列为季度、月度这样的周期序列时, m m m应取为周期的整数倍。
ARMA模型的建模过程
期中考之前的流程图
1 读取数据
导入数据
格式转化 xts/ts
2 plot作时序图
平稳性/周期性
3 若平稳 定阶
若不平稳 单位根检验
a)固定趋势 linear model 带时间序列误差的回归模型
b)随机趋势 做(季节)差分 转化为平稳模型
4 模型参数估计
最小二乘估计/最大似然估计/Yule-walker方程
5 模型优化
变量选择/调整阶数/换新模型
6 模型检验+模型选择
白噪声检验/残差是否重尾/正态分布
7 模型选择 样本内外比较
8 预测
模拟生成ARMA模型/平稳序列【代码】
生成单位根过程
set.seed(2)
y = arima.sim(model=list(order=c(0,1,0)), n=500, sd=0.2)
plot(y,main = "单位根过程")
随机趋势:时间序列非平稳,过去时间点的数据对当前的影响不会衰减
表现为ACF衰减缓慢
模拟一个平稳的ARMA(1,2)模型,并对模拟的数据进行
建模分析,检验结果是否与初始参数吻合
set.seed(2)
y = arima.sim(model=list(order=c(1,0,2),ar=c(0.8),ma=c(0.7, 0.6)), n=500, sd=0.2)#生成系数
为1和-0.1的AR(2)模型
# plot(y)
eacf(y)
eacf最左上角的圆圈建议选择ARMA(1,2) 与模拟数据吻合,下边进行参数估计
res <- arima(y, order=c(1,0,2), include.mean=TRUE);
怎么判断时间序列是平稳的
plot看图
acf pacf看衰减速度
模型定阶方法【代码】
AR(p)
MA(q)
ARMA(p,q) 不止一种
| AR(p) | MA(q) | ARMA(p,q) |
|---|---|---|
pacf() | acf() | EAIC, autoarima, arimasubset |
ARMA模型的系数估计方法【代码】
4 自回归模型
AR(1)模型的性质【计算】
X
t
=
ϕ
0
+
ϕ
1
X
t
−
1
+
ε
t
X_t=\phi_0+\phi_1X_{t-1}+\varepsilon_t
Xt=ϕ0+ϕ1Xt−1+εt
(
1
−
ϕ
1
B
)
X
t
=
ϕ
0
+
ε
t
(1-\phi_1B)X_t=\phi_0+\varepsilon_t
(1−ϕ1B)Xt=ϕ0+εt
期望
μ = E ( X t ) = ϕ 0 1 − ϕ 1 \mu=E(X_t)=\frac{\phi_0}{1-\phi_1} μ=E(Xt)=1−ϕ1ϕ0
方差
σ X = V a r ( X t ) = σ 2 1 − ϕ 1 2 \sigma_{X}=Var(X_t)=\frac{\sigma^2}{1-\phi_1^2} σX=Var(Xt)=1−ϕ12σ2
自协方差函数
X
t
−
μ
=
ϕ
1
(
X
t
−
1
−
μ
)
+
ε
t
X_t-\mu=\phi_1(X_{t-1}-\mu)+\varepsilon_t
Xt−μ=ϕ1(Xt−1−μ)+εt
γ
0
=
E
[
(
X
t
−
μ
)
(
X
t
−
μ
)
]
=
ϕ
1
γ
1
+
σ
2
\gamma_0=E[(X_t-\mu)(X_{t}-\mu)]=\phi_1\gamma_1+\sigma^2
γ0=E[(Xt−μ)(Xt−μ)]=ϕ1γ1+σ2
γ
j
=
E
[
(
X
t
−
μ
)
(
X
t
−
j
−
μ
)
]
=
ϕ
1
γ
j
−
1
\gamma_j=E[(X_t-\mu)(X_{t-j}-\mu)]=\phi_1\gamma_{j-1}
γj=E[(Xt−μ)(Xt−j−μ)]=ϕ1γj−1
自相关函数
ρ j = γ j γ 0 = ϕ 1 j \rho_j=\frac{\gamma_j}{\gamma_0}=\phi_1^j ρj=γ0γj=ϕ1j
转化为MA(∞)
AR(2)模型的性质
X
t
=
ϕ
0
+
ϕ
1
X
t
−
1
+
ϕ
2
X
t
−
2
+
ε
t
X_t=\phi_0+\phi_1X_{t-1}+\phi_2X_{t-2} +\varepsilon_t
Xt=ϕ0+ϕ1Xt−1+ϕ2Xt−2+εt
(
1
−
ϕ
1
B
−
ϕ
2
B
2
)
X
t
=
ϕ
0
+
ε
t
(1-\phi_1B-\phi_2B^2)X_t=\phi_0+\varepsilon_t
(1−ϕ1B−ϕ2B2)Xt=ϕ0+εt
期望
μ = E ( X t ) = ϕ 0 1 − ϕ 1 − ϕ 2 \mu=E(X_t)=\frac{\phi_0}{1-\phi_1-\phi_2} μ=E(Xt)=1−ϕ1−ϕ2ϕ0
方差
σ X = V a r ( X t ) = σ 2 1 − ϕ 1 2 − ϕ 2 2 \sigma_{X}=Var(X_t)=\frac{\sigma^2}{1-\phi_1^2-\phi_2^2} σX=Var(Xt)=1−ϕ12−ϕ22σ2
自协方差函数
X t − μ = ϕ 1 ( X t − 1 − μ ) + ϕ 2 ( X t − 2 − μ ) + ε t X_t-\mu=\phi_1(X_{t-1}-\mu)+\phi_2(X_{t-2}-\mu)+\varepsilon_t Xt−μ=ϕ1(Xt−1−μ)+ϕ2(Xt−2−μ)+εt
γ j = E [ ( X t − μ ) ( X t − j − μ ) ] = ϕ 1 γ j − 1 + ϕ 2 γ j − 2 \gamma_j=E[(X_t-\mu)(X_{t-j}-\mu)]=\phi_1\gamma_{j-1}+\phi_2\gamma_{j-2} γj=E[(Xt−μ)(Xt−j−μ)]=ϕ1γj−1+ϕ2γj−2
自相关函数
ρ j = γ j γ 0 = ϕ 1 ρ 1 + ϕ 2 ρ 2 \rho_j=\frac{\gamma_j}{\gamma_0}=\phi_1\rho_1+\phi_2\rho_2 ρj=γ0γj=ϕ1ρ1+ϕ2ρ2
偏自相关系数的定义及区别
设
X
1
,
…
,
X
n
,
Y
X_1, \dots, X_n, Y
X1,…,Xn,Y为随机变量,
L
(
Y
∣
X
1
,
…
,
X
n
)
=
argmin
Y
^
=
b
0
+
b
1
X
1
+
⋯
+
b
n
X
n
E
(
Y
−
Y
^
)
2
L(Y|X_1, \dots, X_n) = \mathop{\text{argmin}}_{\hat Y = b_0 + b_1 X_1 + \dots + b_n X_n} E(Y - \hat Y)^2
L(Y∣X1,…,Xn)=argminY^=b0+b1X1+⋯+bnXnE(Y−Y^)2
称为用
X
1
,
…
,
X
n
X_1, \dots, X_n
X1,…,Xn对
Y
Y
Y的最优线性预测。
Y
−
L
(
Y
∣
X
1
,
…
,
X
n
)
Y - L(Y|X_1, \dots, X_n)
Y−L(Y∣X1,…,Xn)与
Z
−
L
(
Z
∣
X
1
,
…
,
X
n
)
Z - L(Z|X_1,\dots, X_n)
Z−L(Z∣X1,…,Xn)的相关系数称为Y和Z在扣除
X
1
,
…
,
X
n
X_1, \dots, X_n
X1,…,Xn影响后的偏相关系数。
对平稳线性时间序列, 对
n
=
1
,
2
,
…
n=1,2,\dots
n=1,2,…, 有
L
(
X
t
∣
X
t
−
1
,
…
,
X
t
−
n
)
=
ϕ
n
0
+
ϕ
n
1
X
t
−
1
+
⋯
+
ϕ
n
n
X
t
−
n
L(X_t|X_{t-1}, \dots, X_{t-n}) = \phi_{n0} + \phi_{n1} X_{t-1} + \dots + \phi_{nn} X_{t-n}
L(Xt∣Xt−1,…,Xt−n)=ϕn0+ϕn1Xt−1+⋯+ϕnnXt−n
其中
ϕ
n
j
,
j
=
0
,
1
,
…
,
n
\phi_{nj}, j=0,1,\dots,n
ϕnj,j=0,1,…,n与
t
t
t无关。 称
ϕ
n
n
\phi_{nn}
ϕnn为时间序列
{
X
t
}
\{X_t \}
{Xt}的偏自相关系数,
{
ϕ
n
n
}
\{ \phi_{nn} \}
{ϕnn}序列称为时间序列
{
X
t
}
\{X_t \}
{Xt}的偏自相关函数(PACF)。
ϕ n n \phi_{nn} ϕnn实际是 X t X_t Xt与 X t − n X_{t-n} Xt−n在扣除 X t − 2 , … , X t − n + 1 X_{t-2}, \dots, X_{t-n+1} Xt−2,…,Xt−n+1的影响后的偏相关系数。 ϕ 11 \phi_{11} ϕ11就是 ρ 1 \rho_1 ρ1。
AR模型参数估计方法
- 最小二乘法估计
- 最大似然估计
- Yule-Walker方程
- Burg递推计算
5 移动平均模型
移动平均模型的性质【计算】
X t = θ 0 + ε t + θ 1 ε t − 1 X_t = \theta_0 + \varepsilon_t + \theta_1 \varepsilon_{t-1} Xt=θ0+εt+θ1εt−1
期望
E X t = θ 0 , ∀ t E X_t = \theta_0, \ \forall t \quad EXt=θ0, ∀t
方差
Var ( X t ) = σ 2 ( 1 + θ 1 2 ) \text{Var}(X_t) = \sigma^2(1 + \theta_1^2) Var(Xt)=σ2(1+θ12)
协方差
γ 1 = E [ ( X t − θ 0 ) ( X t − 1 − θ 0 ) ] = E [ ( ε t + θ 1 ε t − 1 ) ( ε t − 1 + θ 1 ε t − 2 ) ] = θ 1 E ε t − 1 2 = σ 2 θ 1 \gamma_1 = E[(X_t - \theta_0)(X_{t-1}-\theta_0)] = E[(\varepsilon_t + \theta_1 \varepsilon_{t-1})(\varepsilon_{t-1} + \theta_1 \varepsilon_{t-2})] = \theta_1 E \varepsilon_{t-1}^2 = \sigma^2 \theta_1 γ1=E[(Xt−θ0)(Xt−1−θ0)]=E[(εt+θ1εt−1)(εt−1+θ1εt−2)]=θ1Eεt−12=σ2θ1
γ k = E [ ( ε t + θ 1 ε t − 1 ) ( ε t − k + θ 1 ε t − k − 1 ) ] = 0 ( k > 1 ) \gamma_k = E[(\varepsilon_t + \theta_1 \varepsilon_{t-1})(\varepsilon_{t-k} + \theta_1 \varepsilon_{t-k-1})] = 0 \ (k>1) γk=E[(εt+θ1εt−1)(εt−k+θ1εt−k−1)]=0 (k>1)
γ k = { σ 2 ( 1 + θ 1 2 ) , k = 0 σ 2 θ 1 , k = 1 , 0 , k > 1 \gamma_k = \begin{cases} \sigma^2(1 + \theta_1^2), & k=0 \\ \sigma^2 \theta_1, & k=1, \\ 0, & k>1 \end{cases} γk=⎩⎪⎨⎪⎧σ2(1+θ12),σ2θ1,0,k=0k=1,k>1
自相关函数
ρ
k
=
{
1
,
k
=
0
θ
1
1
+
θ
1
2
,
k
=
1
,
0
,
k
>
1
\rho_k = \begin{cases} 1, & k=0 \\ \frac{\theta_1}{1 + \theta_1^2}, & k=1, \\ 0, & k>1 \end{cases}
ρk=⎩⎪⎨⎪⎧1,1+θ12θ1,0,k=0k=1,k>1
这就验证了MA(1)序列是弱平稳列
可逆性
对MA(1)模型,当|\theta_1|<1
ε
t
=
−
ϕ
0
+
X
t
+
∑
j
=
1
∞
(
−
θ
1
)
j
X
t
−
j
\varepsilon_t = -\phi_0 + X_t + \sum_{j=1}^\infty (-\theta_1)^j X_{t-j}
εt=−ϕ0+Xt+j=1∑∞(−θ1)jXt−j
移动平均模型定阶
ACF q阶截尾
AIC定阶
移动平均模型的估计
- 矩估计法,利用 { γ k } \{\gamma_k\} {γk}与 { θ k } \{\theta_k\} {θk}、 σ 2 \sigma^2 σ2的关系求非线性方程组解;
- 逆相关函数法,将MA模型转换为长阶自回归模型,用估计自回归模型的方法估计,能 保证可逆性;
- 新息估计法;
- 条件最大似然估计法;
- 精确最大似然估计法。
6 ARMA模型
一般ARAM模型为
X t = ϕ 0 + ϕ 1 X t − 1 + ⋯ + ϕ p X t − p + ε t + θ 1 ε t − 1 + ⋯ + θ q ε t − q X_t = \phi_0 + \phi_1 X_{t-1} + \dots + \phi_p X_{t-p} + \varepsilon_t + \theta_1 \varepsilon_{t-1} + \dots + \theta_q \varepsilon_{t-q} Xt=ϕ0+ϕ1Xt−1+⋯+ϕpXt−p+εt+θ1εt−1+⋯+θqεt−q
平稳解的均值为
E
X
t
=
ϕ
0
1
−
ϕ
1
−
⋯
−
ϕ
p
EX_t = \frac{\phi_0}{1 - \phi_1 - \dots - \phi_p}
EXt=1−ϕ1−⋯−ϕpϕ0
ARMA模型辨识
R的forecast包提供了一个auto.arima()函数, 可以自动进行模型选择。 TSA包提供了一个armasubsets()函数用于模型选择。
Tsay和Tiao(1984)提出了一个对ARMA定阶的辅助工具EACF, 其结果可以用与
(
p
,
q
)
(p,q)
(p,q)有关的二维表格表示, 结果包含由字母“O”组成的三角形, 锐角顶点在
(
p
,
q
)
(p,q)
(p,q)位置。如

TSA::eacf(ts.3m, 6, 12)
## AR/MA
## 0 1 2 3 4 5 6 7 8 9 10 11 12
## 0 o o x o o x o o o x o x o
## 1 x o x o o x o o o o o x o
## 2 x x x o o x o o o o o o o
## 3 x x x o o o o o o o o o o
## 4 x o x o o o o o o o o o o
## 5 x x x o x o o o o o o o o
## 6 x x x x x o o o o o o o o
从上面的结果不易选择ARMA阶。 函数的默认检验系数非零的检验水平是0.05水平。 如果用0.01水平, 则选择 p = q = 0 p=q=0 p=q=0。
resr <- TSA::armasubsets(ts.3m, nar = 6, nma = 12)
plot(resr)
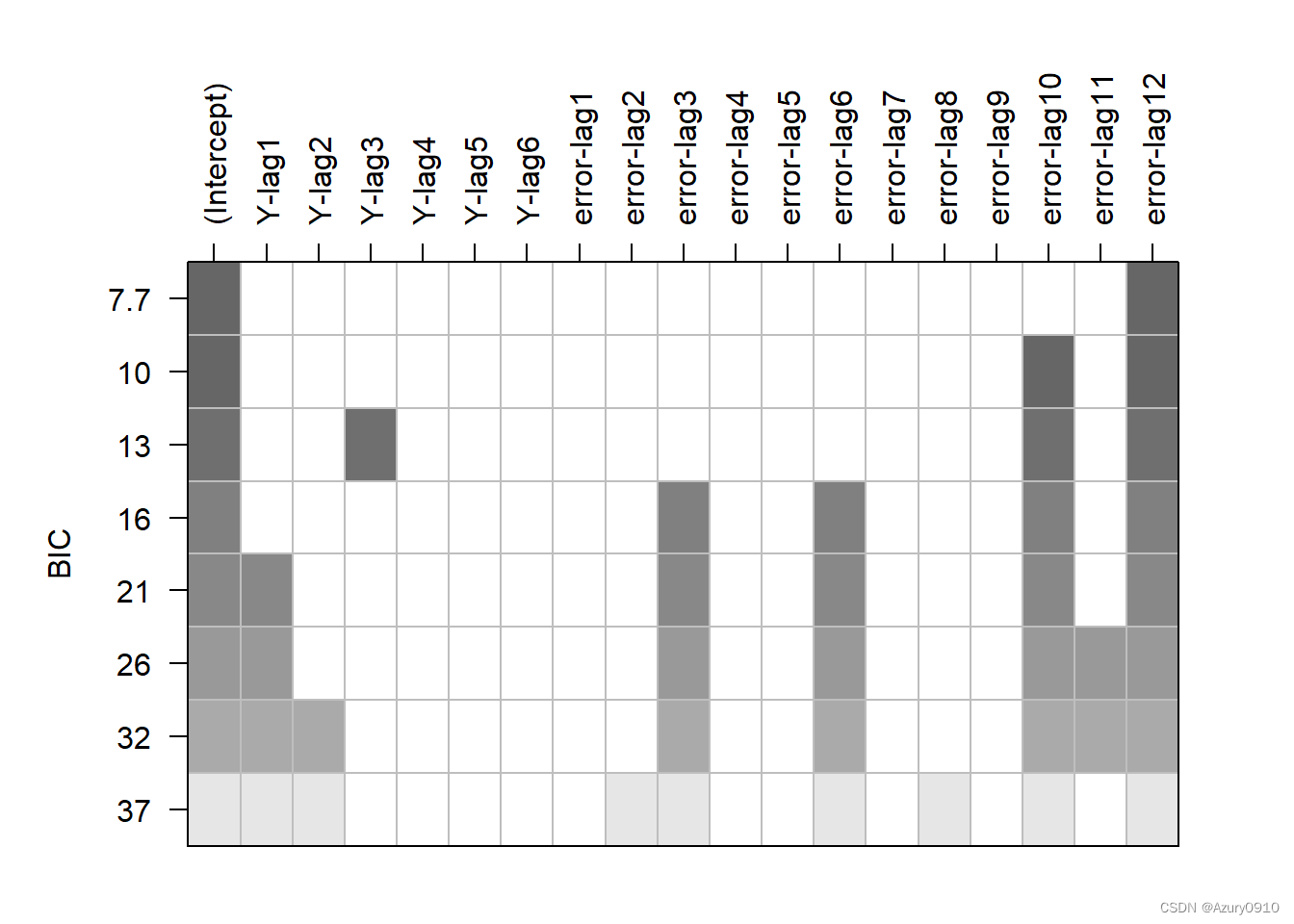
用forecasts包的auto.arima()函数定阶:
forecast::auto.arima(ts.3m, max.p = 6, max.q = 6, max.P = 1, max.Q = 1)
## Series: ts.3m
## ARIMA(3,0,1)(1,0,1)[12] with non-zero mean
##
## Coefficients:
## ar1 ar2 ar3 ma1 sar1 sma1 mean
## 0.0453 -0.0285 -0.0837 -0.1124 0.5319 -0.4435 0.0103
## s.e. 0.3146 0.0417 0.0387 0.3147 0.2885 0.3049 0.0023
##
## sigma^2 = 0.003998: log likelihood = 1016.63
## AIC=-2017.25 AICc=-2017.06 BIC=-1980.24
ARMA模型的三种表示
设ARMA( p , q p,q p,q)模型的系数满足平稳性条件与可逆性条件。
(0) ARMA模型的一般表示
( 1 − ϕ 1 B − ⋯ − ϕ p B p ) X t = ϕ 0 + ( 1 + θ 1 B + ⋯ + θ q B q ) ε t (1 - \phi_1 B - \dots - \phi_p B^p) X_t = \phi_0 + (1 + \theta_1 B + \dots + \theta_q B^q) \varepsilon_t (1−ϕ1B−⋯−ϕpBp)Xt=ϕ0+(1+θ1B+⋯+θqBq)εt
(1) ARMA模型的MA表示
用滞后算子的性质, 令
P
(
z
)
=
1
−
∑
j
=
1
p
ϕ
p
z
j
P(z) = 1 - \sum_{j=1}^p \phi_p z^j
P(z)=1−∑j=1pϕpzj,
Q
(
z
)
=
1
+
∑
j
=
1
q
θ
q
z
j
Q(z) = 1 + \sum_{j=1}^q \theta_q z^j
Q(z)=1+∑j=1qθqzj, 则
P
(
B
)
X
t
=
ϕ
0
+
Q
(
B
)
ε
t
P(B)X_t=\phi_0+Q(B)\varepsilon_t
P(B)Xt=ϕ0+Q(B)εt
两边同除以
P
(
B
)
P(B)
P(B),得
X
t
=
ϕ
0
P
(
B
)
+
Q
(
B
)
P
(
B
)
ε
t
X_t=\frac{\phi_0}{P(B)}+\frac{Q(B)}{P(B)}\varepsilon_t
Xt=P(B)ϕ0+P(B)Q(B)εt
再令
Ψ
(
z
)
=
Q
(
z
)
P
(
z
)
=
∑
j
=
0
∞
ψ
j
z
j
,
\Psi(z) = \frac{Q(z)}{P(z)} = \sum_{j=0}^\infty \psi_j z^j,
Ψ(z)=P(z)Q(z)=j=0∑∞ψjzj,其中
{
ψ
j
}
绝
\{ \psi_j \}绝
{ψj}绝对可和(实际上,
j
→
∞
j\to\infty
j→∞时
c
j
c_j
cj以负指数速度衰减)。 所以
X
t
=
μ
+
Ψ
(
B
)
ε
t
=
μ
+
∑
j
=
0
∞
ψ
j
ε
t
−
j
,
t
∈
Z
X_t = \mu + \Psi(B) \varepsilon_t = \mu + \sum_{j=0}^\infty \psi_j \varepsilon_{t-j}, \ t \in \mathbb Z
Xt=μ+Ψ(B)εt=μ+j=0∑∞ψjεt−j, t∈Z
这称为ARMA模型的MA表示或者Wold表示。
μ
=
E
X
t
=
ϕ
0
/
P
(
1
)
=
ϕ
0
/
(
1
−
ϕ
1
−
⋯
−
ϕ
p
)
\mu=EX_t = \phi_0/P(1) = \phi_0 / (1 - \phi_1 - \dots - \phi_p)
μ=EXt=ϕ0/P(1)=ϕ0/(1−ϕ1−⋯−ϕp)。
ψ
0
=
1
\psi_0=1
ψ0=1。
(2) ARMA模型的AR表示
P
(
B
)
X
t
=
ϕ
0
+
Q
(
B
)
ε
t
P(B)X_t=\phi_0+Q(B)\varepsilon_t
P(B)Xt=ϕ0+Q(B)εt
两边同除以
Q
(
B
)
Q(B)
Q(B),得
P
(
B
)
Q
(
B
)
X
t
=
ϕ
0
Q
(
B
)
+
ε
t
\frac{P(B)}{Q(B)}X_t=\frac{\phi_0}{Q(B)}+\varepsilon_t
Q(B)P(B)Xt=Q(B)ϕ0+εt
令
π
(
z
)
=
P
(
z
)
Q
(
z
)
\pi(z) = \frac{P(z)}{Q(z)}
π(z)=Q(z)P(z)
则
π
(
z
)
=
∑
j
=
0
∞
π
j
z
j
\pi(z) = \sum_{j=0}^\infty \pi_j z^j
π(z)=∑j=0∞πjzj,
{
π
j
}
\{ \pi_j \}
{πj}绝对可和, 当
j
→
∞
j\to\infty
j→∞时
π
j
\pi_j
πj以负指数速度收敛到0。
π
0
=
1
\pi_0=1
π0=1。 于是ARMA模型有如下的AR表示
π
(
B
)
X
t
=
ϕ
0
Q
(
1
)
+
ε
t
\pi(B) X_t = \frac{\phi_0}{Q(1)} + \varepsilon_t
π(B)Xt=Q(1)ϕ0+εt
或
X
t
=
ϕ
~
0
−
π
1
X
t
−
1
−
π
2
X
t
−
2
−
⋯
+
ε
t
X_t = \tilde\phi_0 - \pi_1 X_{t-1} - \pi_2 X_{t-2} - \dots + \varepsilon_t
Xt=ϕ~0−π1Xt−1−π2Xt−2−⋯+εt
其中
ϕ
~
0
=
ϕ
0
/
Q
(
1
)
=
ϕ
0
/
(
1
+
θ
1
+
⋯
+
θ
q
)
\tilde\phi_0 = \phi_0/Q(1) = \phi_0 / (1 + \theta_1 + \dots + \theta_q)
ϕ~0=ϕ0/Q(1)=ϕ0/(1+θ1+⋯+θq)。 这称为ARMA的AR表示或者长阶自回归形式。 这说明平稳可逆ARMA序列可以用自回归模型近似表示。
π
j
\pi_j
πj称为ARMA模型的\pi权重。
7 单位根过程
单位根检验(原假设/方法/代码)
许多经济和金融序列并不能仅用随机游动来描述, 可能需要用ARIMA。 因为ARMA模型可以看成长阶自回归, 所以检验是否ARIMA模型, 可以用q=0的ARIMA作为基础模型。 对序列 { x t } \{ x_t \} {xt}为了检验其是否有单位根, 考虑如下的基础模型:
X t = c t + β X t − 1 + ∑ j = 1 p − 1 ϕ j Δ X t − j + e t \begin{aligned} X_t = c_t + \beta X_{t-1} + \sum_{j=1}^{p-1} \phi_j \Delta X_{t-j} + e_t\end{aligned} Xt=ct+βXt−1+j=1∑p−1ϕjΔXt−j+et
当
β
=
1
\beta=1
β=1时, 就是
Δ
X
t
\Delta X_t
ΔXt的
A
R
(
p
−
1
)
AR(p-1)
AR(p−1)模型; 当
β
<
1
\beta<1
β<1时, 是
X
t
的
A
R
(
p
)
X_t的AR(p)
Xt的AR(p)模型。
c
t
c_t
ct是非随机的趋势部分, 可以取
0
0
0,或常数,或
a
+
b
t
a + bt
a+bt这样的非随机线性趋势。
检验假设
H
0
:
β
=
1
⟷
H
a
:
β
<
1
H_0: \beta = 1 \longleftrightarrow H_a: \beta < 1
H0:β=1⟷Ha:β<1
如果拒绝
H
0
H_0
H0, 就说明没有单位根。 使用统计量
ADF
=
β
^
−
1
SE
(
β
^
)
\text{ADF} = \frac{\hat\beta - 1}{\text{SE}(\hat\beta)}
ADF=SE(β^)β^−1
当ADF统计量足够小的时候拒绝
H
0
H_0
H0。
基础模型(7.5)也可以改写成
Δ
X
t
=
c
t
+
β
c
X
t
−
1
+
∑
j
=
1
p
−
1
ϕ
j
Δ
X
t
−
j
+
e
t
\Delta X_t = c_t + \beta_c X_{t-1} + \sum_{j=1}^{p-1} \phi_j \Delta X_{t-j} + e_t
ΔXt=ct+βcXt−1+j=1∑p−1ϕjΔXt−j+et
其中
β
c
=
β
−
1
\beta_c = \beta-1
βc=β−1, 检验
H
0
:
β
c
=
0
⟷
H
a
:
β
c
<
0
H_0: \beta_c = 0 \longleftrightarrow H_a: \beta_c < 0
H0:βc=0⟷Ha:βc<0
这个检验称为ADF检验(Augmented Dicky-Fuller Test)。
fUnitRoots包的adfTest()函数可以执行单位根ADF检验。 urca包的ur.df()函数, tseries包的adf.test()函数也可以执行单位根ADF检验。
注意,单位根DF检验和ADF检验都是在拒绝 H 0 H_0 H0(显著)时否认有单位根, 不显著时承认有单位根。
怎么区分固定趋势和随机趋势
10 带时间序列误差的回归模型【实证分析】
时序分析与回归分析的区别与联系
在统计学的数据分析中, 线性回归分析是最常用的分析工具之一。 线性回归以一元线性回归为例,模型如下
Y t = β 0 + β 1 X t + e t , t = 1 , 2 , … , T \begin{aligned} Y_t =& \beta_0 + \beta_1 X_t + e_t, \ t=1,2,\dots,T \end{aligned} Yt=β0+β1Xt+et, t=1,2,…,T
其中自变量 { X t } \{ X_t \} {Xt}为常数列, β 0 \beta_0 β0, β 1 \beta_1 β1为未知的系数, { e t } \{ e_t \} {et}为零均值独立同分布随机误差序列, 方差为 σ e 2 \sigma_e^2 σe2, 因变量 { Y t } \{ Y_t \} {Yt}为随机变量列。 参数 β 0 \beta_0 β0, β 1 \beta_1 β1, σ e 2 \sigma_e^2 σe2可以用最小二乘法估计, 估计量无偏、相合, 系数的估计渐近正态分布。 为了对估计结果做假设检验或者用模型结果做预测, 一般还假设 { e t } \{ e_t \} {et}为零均值独立同正态分布序列。
在金融研究中, { X t } \{ X_t \} {Xt}和 { Y t } \{ Y_t \} {Yt}一般都是时间序列, 而且 { e t } \{ e_t \} {et}也是时间序列,有序列相关性。 这时, 最小二乘估计不是最有效的估计甚至于可能不相合, 基于 { e t } \{ e_t \} {et}独立同正态分布所做的标准误差估计、假设检验和预测都不再成立。
建模步骤
- 拟合一个线性回归模型,并检验残差的序列相关性
- 如果残差序列是单位根非平稳的,则对因变量和自变量都做一阶差分。 然后对差分后的序列再进行第一步。 如果残差序列是平稳的, 则对残差序列识别一个ARMA模型, 并相应地修改线性回归模型。
- 用最大似然估计法对回归模型与ARMA模型进行联合估计, 并对模型进行检验, 看是否需要改进。 主要可以使用Ljung-Box对残差进行白噪声检验。
11 长记忆模型【简答】
有一些平稳时间序列的ACF虽然也随滞后
k
→
∞
k\to\infty
k→∞趋于零, 但是收敛到零的速度比较慢, 只有负幂次
k
−
α
k^{-\alpha}
k−α这样的速度。 这代表着序列的自相关性随着距离变远而减小得比较慢, 称这样的序列是长记忆时间序列。
注意, 长记忆时间序列仍是弱平稳的, 单位根非平稳列虽然远距离的自相关性很强但不称为长记忆。
长记忆时间序列的典型模型是分数差分弱平稳列,模型为
( 1 − B ) d X t = ξ t , − 0.5 < d < 0.5 \begin{aligned} (1-B)^d X_t = \xi_t, \ -0.5 < d < 0.5 \end{aligned} (1−B)dXt=ξt, −0.5<d<0.5
其中 { ξ t } \{ \xi_t \} {ξt}是零均值独立同分布白噪声。
fracdiff::fdGPH(vw)
## $d
## [1] 0.372226
##
## $sd.as
## [1] 0.0698385
##
## $sd.reg
## [1] 0.06868857
估计的差分阶为。
用fracdiff::fracdiff()函数进行ARFIMA模型估计:
mres <- fracdiff::fracdiff(vw, nar=1, nma=1)
summary(mres)
##
## Call:
## fracdiff::fracdiff(x = vw, nar = 1, nma = 1)
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## d 0.490938 0.007997 61.39 <2e-16 ***
## ar 0.113389 0.005988 18.94 <2e-16 ***
## ma 0.575895 0.005946 96.85 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## sigma[eps] = 0.0065619
## [d.tol = 0.0001221, M = 100, h = 0.0003742]
## Log likelihood: 3.551e+04 ==> AIC = -71021.02 [4 deg.freedom]
其中选项nar和nma用来指定AR阶和MA阶。 模型为
估计结果中差分阶已经接近非平稳的边缘0.5了。
注意:fracdiff::fracdiff()的输出与arima()输出有差别, 其MA系数的输出是格式的。
Ⅲ 资产波动率模型
16 资产波动率模型特征
波动率的定义和特征
波动率(volatility)指的是资产价格的波动强弱程度, 类似于概率论中随机变量标准差的概念。
波动率不能直接观测, 可以从资产收益率中看出波动率的一些特征。
- 存在波动率聚集(volatility clustering)
- 波动率随时间连续变化,一般不出现波动率的跳跃式变动
- 波动率一般在固定的范围内变化,意味着动态的波动率是平稳的
- 在资产价格大幅上扬和大幅下跌两种情形下, 波动率的反映不同, 大幅下跌时波动率一般也更大, 这种现象称为杠杆效应(leverage effect)非对称震荡
波动率的估计方法【简答题】
波动率模型的建立
对资产收益率序列建立波动率模型需要如下四个步骤:
- 通过检验序列的自相关性建立均值的方程, 必要时还可以引入适当的解释变量;
- ARMA模型/常数均值 求 μ t = E ( r t ∣ F t − 1 ) \mu_t=E(r_t|F_{t-1}) μt=E(rt∣Ft−1) linear
- 解释变量可以是Xt Yt
- 对均值方程的残差作白噪声检验, 通过后,对残差检验ARCH效应;
- 对 a t a_t at做白噪声检验 r t − μ t = a t r_t-\mu_t=a_t rt−μt=at (检验线性关系)
- 对 a t a_t at做ARCH检验 a t 2 a_t^2 at2之间有关联(检验非线性关系)
- 如果ARCH效应检验结果显著, 则指定一个波动率模型, 对均值方程和波动率方程进行联合估计;
- 联合估计: r t = μ t + a t r_t=\mu_t+a_t rt=μt+at
- 对得到的模型进行验证, 需要时做改进。
ARCH效应的检验【代码】
什么是ARCH效应?
{ r t } \{r_t\} {rt}前后之间不相关,但不独立的。 { ∣ r t ∣ } \{|r_t|\} {∣rt∣}和 { r t 2 } \{r_t^2\} {rt2}存在相关性
ARCH效应怎么检验?
为了检验ARCH效应, 先建立均值模型, 拟合 μ t \mu_t μt, 计算残差 a t = r t − μ t a_t=r_t-\mu_t at=rt−μt。 用残差序列的平方 { a t 2 } \{a^2_t\} {at2}作ARCH效应检验。
检验方法一: { a t 2 } \{a^2_t\} {at2}白噪声检验
一种是对 { a t 2 } \{a^2_t\} {at2}作Ljung-Box白噪声检验, 检验不显著时没有ARCH效应, 检验显著时有ARCH效应。
检验方法二:Engle的拉格朗日乘子法检验
a
t
2
=
α
0
+
α
1
a
t
−
1
2
+
⋯
+
α
m
a
t
−
m
2
+
e
t
,
t
=
m
+
1
,
…
,
T
a_t^2 = \alpha_0 + \alpha_1 a_{t-1}^2 + \dots + \alpha_m a_{t-m}^2 + e_t, \ t=m+1, \dots, T
at2=α0+α1at−12+⋯+αmat−m2+et, t=m+1,…,T
其中
T
T
T为样本量,
m
m
m是适当的AR阶数,
e
t
e_t
et为回归残差。 零假设为
H
0
:
α
1
=
⋯
=
α
m
=
0
H_0: \ \alpha_1 = \dots = \alpha_m = 0
H0: α1=⋯=αm=0
拒绝
H
0
H_0
H0时有ARCH效应。
执行Engle的ARCH效应检验的函数定义如下:
"archTest" <- function(x, m=10){
# Perform Lagrange Multiplier Test for ARCH effect of a time series
# x: time series, residual of mean equation
# m: selected AR order
y <- (x - mean(x))^2
T <- length(x)
atsq <- y[(m+1):T]
xmat <- matrix(0, T-m, m)
for (j in 1:m){
xmat[,j] <- y[(m+1-j):(T-j)]
}
lmres <- lm(atsq ~ xmat)
summary(lmres)
}
17 ARCH模型
ARCH(
m
m
m)模型为
a
t
=
σ
t
ε
t
,
σ
t
2
=
α
0
+
α
1
a
t
−
1
2
+
⋯
+
α
m
a
t
−
m
2
.
\begin{aligned} a_t =& \sigma_t \varepsilon_t , \\ \sigma_t^2 =& \alpha_0 + \alpha_1 a_{t-1}^2 + \dots + \alpha_m a_{t-m}^2 . \end{aligned}
at=σt2=σtεt,α0+α1at−12+⋯+αmat−m2.
ARCH模型系数有哪些约束条件,为什么要有?
{
ε
t
}
\{\varepsilon_t\}
{εt}是零均值单位方差的独立同分布白噪声
α
0
>
0
\alpha_0>0
α0>0保证方差
σ
t
2
>
0
\sigma_t^2>0
σt2>0,
α
j
≥
0
,
j
=
1
,
2
,
…
,
m
\alpha_j \ge0,j=1,2,\dots,m
αj≥0,j=1,2,…,m
前后正相关,波动聚集效果正相叠加。
σ
t
2
=
V
a
r
(
a
t
2
∣
F
t
−
1
)
=
E
(
a
t
2
∣
F
t
−
1
)
\sigma_t^2=Var(a_t^2|F_{t-1})=E(a_t^2|F_{t-1})
σt2=Var(at2∣Ft−1)=E(at2∣Ft−1)
ARCH(1,1)模型的性质【证明】
以最简单的ARCH(1)为例讨论模型的性质。 模型为
a
t
=
σ
t
ε
t
,
σ
t
2
=
α
0
+
α
1
a
t
−
1
2
a_t = \sigma_t \varepsilon_t, \ \sigma_t^2 = \alpha_0 + \alpha_1 a_{t-1}^2
at=σtεt, σt2=α0+α1at−12
其中
α
0
>
0
\alpha_0>0
α0>0,
0
<
α
1
<
1
0<\alpha_1<1
0<α1<1 。
α
1
>
0
\alpha_1>0
α1>0是因为如果等于零就不能算ARCH(1),
α
1
<
1
\alpha_1<1
α1<1是为了方差有限。
(1) 无条件期望
E ( a t ) = E [ E ( a t ∣ F t − 1 ) ] = E [ E ( σ t ε t ∣ F t − 1 ) ] = E [ σ t E ( ε t ∣ F t − 1 ) ] = 0 E(a_t)=E[E(a_t|F_{t-1})]=E[E(\sigma_t \varepsilon_t|F_{t-1})]=E[\sigma_t E(\varepsilon_t|F_{t-1})]=0 E(at)=E[E(at∣Ft−1)]=E[E(σtεt∣Ft−1)]=E[σtE(εt∣Ft−1)]=0
(2) 无条件方差
V a r ( a t ) = E ( a t 2 ) = E [ E ( a t 2 ∣ F t − 1 ) ] = E [ E ( σ t 2 ε t 2 ∣ F t − 1 ) ] = E [ σ t 2 E ( ε t 2 ∣ F t − 1 ) ] = E ( σ t 2 ) = α 0 + α 1 E ( a t − 1 2 ) Var(a_t)=E(a_t^2)=E[E(a_t^2|F_{t-1})]=E[E(\sigma_t^2 \varepsilon_t^2|F_{t-1})]=E[\sigma_t^2 E(\varepsilon_t^2|F_{t-1})]=E(\sigma_t^2)=\alpha_0+\alpha_1E(a_{t-1}^2) Var(at)=E(at2)=E[E(at2∣Ft−1)]=E[E(σt2εt2∣Ft−1)]=E[σt2E(εt2∣Ft−1)]=E(σt2)=α0+α1E(at−12)
V a r ( a t ) = E ( a t 2 ) = α 0 1 − α 1 Var(a_t)=E(a_t^2)=\frac{\alpha_0}{1-\alpha_1} Var(at)=E(at2)=1−α1α0
(3) 高阶矩(峰度)
判断 { a t } \{a_t\} {at}是否为厚尾分布
{ ε t } \{\varepsilon_t\} {εt}服从标准正态分布, 则其有任意阶矩, 这时条件四阶矩
E ( a t 4 ∣ F t − 1 ) = E ( σ t 4 ε t 4 ∣ F t − 1 ) = σ t 4 E ( ε t 4 ∣ F t − 1 ) = 3 σ t 4 = 3 ( α 0 + α 1 a t − 1 2 ) 2 , \begin{aligned} E(a_t^4 | F_{t-1}) =& E(\sigma_t^4 \varepsilon_t^4 | F_{t-1}) = \sigma_t^4 E(\varepsilon_t^4 | F_{t-1})\\ =& 3 \sigma_t^4 = 3(\alpha_0 + \alpha_1 a_{t-1}^2)^2 , \end{aligned} E(at4∣Ft−1)==E(σt4εt4∣Ft−1)=σt4E(εt4∣Ft−1)3σt4=3(α0+α1at−12)2,
(标准正态分布的四阶原点矩=3)
从而无条件的四阶矩为
(重期望公式)
E
(
a
t
4
)
=
E
[
E
(
a
t
4
∣
F
t
−
1
)
]
=
3
E
[
(
α
0
+
α
1
a
t
−
1
2
)
2
]
=
3
[
α
0
2
+
2
α
0
α
1
E
(
a
t
−
1
2
)
+
α
1
2
E
(
a
t
−
1
4
)
]
.
\begin{aligned} E(a_t^4) =& E[ E(a_t^4|F_{t-1})] = 3 E [ (\alpha_0 + \alpha_1 a_{t-1}^2)^2 ] \\ =& 3 \left[ \alpha_0^2 + 2\alpha_0 \alpha_1 E(a_{t-1}^2) + \alpha_1^2 E(a_{t-1}^4) \right] . \end{aligned}
E(at4)==E[E(at4∣Ft−1)]=3E[(α0+α1at−12)2]3[α02+2α0α1E(at−12)+α12E(at−14)].
( 1 − 3 α 1 2 ) E a t 4 = 3 ( α 0 2 + 2 α 0 α 1 α 0 1 − α 1 ) (1 - 3 \alpha_1^2) Ea_t^4 = 3\left( \alpha_0^2 + 2\alpha_0 \alpha_1 \frac{\alpha_0}{1 - \alpha_1} \right) (1−3α12)Eat4=3(α02+2α0α11−α1α0)
这要求
1
−
3
α
1
2
>
0
1 - 3\alpha_1^2>0
1−3α12>0,即
0
<
α
1
<
3
3
0<\alpha_1 < \frac{\sqrt{3}}{3}
0<α1<33。 这时
E
a
t
4
=
3
α
0
2
(
1
+
α
1
)
(
1
−
α
1
)
(
1
−
3
α
1
2
)
.
Ea_t^4 = \frac{3\alpha_0^2(1+\alpha_1)}{(1-\alpha_1)(1-3\alpha_1^2)} .
Eat4=(1−α1)(1−3α12)3α02(1+α1).
由此可以计算
a
t
a_t
at的峰度为
E
a
t
4
[
Var
(
a
t
)
]
2
=
3
1
−
α
1
2
1
−
3
α
1
2
>
3.
\frac{Ea_t^4}{[\text{Var}(a_t)]^2} = 3 \frac{1-\alpha_1^2}{1 - 3\alpha_1^2} > 3 .
[Var(at)]2Eat4=31−3α121−α12>3.
a
t
a_t
at的超额峰度为
E
a
t
4
[
Var
(
a
t
)
]
2
−
3
=
6
α
1
2
1
−
3
α
1
2
>
0.
\frac{Ea_t^4}{[\text{Var}(a_t)]^2} - 3 = \frac{6\alpha_1^2}{1 - 3\alpha_1^2} > 0 .
[Var(at)]2Eat4−3=1−3α126α12>0.
这说明 { a t } \{a_t \} {at}序列是厚尾(重尾)分布, 其样本比均值和方差相同的正态序列有更多的离群值(outliers)。 这与实证分析中对资产收益率的分布观察结果一致。
ARCH模型的优缺点
优点:
- 可以产生波动率聚集;
- 扰动 a t a_t at具有厚尾分布。
缺点:
- 因为假定 a t − j a_{t-j} at−j通过 a t − j 2 a_{t-j}^2 at−j2影响波动率, 所以正的扰动和负的扰动对波动率影响相同, 但是实际的资产收益率中正负扰动对波动率影响不同, 较大的负扰动比正扰动引起的波动更大。(杠杆效应)
- ARCH模型对模型参数有较严格的约束条件, 即使是ARCH(1), 为了能计算峰度,也需要 α 1 ∈ ( 0 , 3 3 ) \alpha_1\in (0, \frac{\sqrt{3}}{3}) α1∈(0,33), 高阶的ARCH( m m m)的约束条件更为复杂。 这对带高斯新息的ARCH模型通过超额峰度表达厚尾性是一个限制。
- 只能描述条件方差的变化, 但是不能解释变化的原因。(模型本身缺陷)
- 由模型做的波动率预测会偏高。
ARCH模型的建模步骤
(1) 定阶 m = ? m=? m=?
首先, 模型为
σ
t
2
=
α
0
+
α
1
a
t
−
1
2
+
⋯
+
α
m
a
t
−
m
2
\sigma_t^2 = \alpha_0 + \alpha_1 a_{t-1}^2 + \dots + \alpha_m a_{t-m}^2
σt2=α0+α1at−12+⋯+αmat−m2
因为
E
(
a
t
2
∣
F
t
−
1
)
=
σ
t
2
E(a_t^2 | F_{t-1}) = \sigma_t^2
E(at2∣Ft−1)=σt2, 所以认为近似有
a
t
2
≈
α
0
+
α
1
a
t
−
1
2
+
⋯
+
α
m
a
t
−
m
2
a_t^2 \approx \alpha_0 + \alpha_1 a_{t-1}^2 + \dots + \alpha_m a_{t-m}^2
at2≈α0+α1at−12+⋯+αmat−m2
这样可以用
{
a
t
2
}
\{ a_t^2 \}
{at2}序列的PACF的截尾性来估计ARCH阶
m
m
m。
另一方面, 令
η
t
=
a
t
2
−
σ
t
2
\eta_t = a_t^2 - \sigma_t^2
ηt=at2−σt2, 可以证明
{
η
t
}
\{\eta_t \}
{ηt}为零均值不相关白噪声列, 则
a
t
2
a_t^2
at2有模型
a
t
2
=
α
0
+
α
1
a
t
−
1
2
+
⋯
+
α
m
a
t
−
m
2
+
η
t
a_t^2 = \alpha_0 + \alpha_1 a_{t-1}^2 + \dots + \alpha_m a_{t-m}^2 + \eta_t
at2=α0+α1at−12+⋯+αmat−m2+ηt
(2) 模型估计(系数) α m ^ \hat{\alpha_m} αm^ 最大似然估计
对ARCH( m m m)模型,考虑最大似然估计或条件最大似然估计。 扰动 a t = ε t σ t , σ t 2 = α 0 + α 1 a t − 1 2 + ⋯ + α m a t − m 2 a_t = \varepsilon_t \sigma_t, \sigma^2_t = \alpha_0 + \alpha_1 a_{t-1}^2 + \dots + \alpha_m a_{t-m}^2 at=εtσt,σt2=α0+α1at−12+⋯+αmat−m2, 记模型参数 α = ( α 0 , α 1 , … , α m ) T \boldsymbol\alpha = (\alpha_0, \alpha_1, \dots, \alpha_m)^T α=(α0,α1,…,αm)T。 模型的似然函数与假定的 ε t \varepsilon_t εt的分布有关, 存在多种似然函数形式。
- 正态假设
- t分布假设(厚尾)
- 有偏t分布假设
- 广义误差分布假设
(3) 模型验证
a ~ t = ε t = a t σ t = r t − μ t σ t \tilde a_t =\varepsilon_t=\frac{a_t}{\sigma_t}=\frac{r_t-\mu_t}{\sigma_t} a~t=εt=σtat=σtrt−μt
对 { a ~ t } \{\tilde a_t \} {a~t}作Ljung-Box白噪声检验, 可以考察均值方程的充分性。
{ a ~ t } \{\tilde a_t \} {a~t}的偏度、峰度、QQ图可以用来与 ε t \varepsilon_t εt的假定分布比较, 以检验模型假定的正确性。
(4) 预测
GARCH tGARCH APARCH区别 估计代码
18 GARCH模型
对于一个对数收益率序列
r
t
r_t
rt, 令
a
t
=
r
t
−
μ
t
=
r
t
−
E
(
r
t
∣
F
t
−
1
)
a_t = r_t - \mu_t = r_t - E(r_t | F_{t-1})
at=rt−μt=rt−E(rt∣Ft−1)为其新息序列, 称
{
a
t
}
\{ a_t \}
{at}服从GARCH(
m
m
m,
s
s
s)模型, 如果
a
t
a_t
at满足
a
t
=
σ
t
ε
t
,
σ
t
2
=
α
0
+
∑
i
=
1
m
α
i
a
t
−
i
2
+
∑
j
=
1
s
β
j
σ
t
−
j
2
\begin{aligned} a_t = \sigma_t \varepsilon_t, \quad \sigma_t^2 = \alpha_0 + \sum_{i=1}^m \alpha_i a_{t-i}^2 + \sum_{j=1}^s \beta_j \sigma_{t-j}^2\end{aligned}
at=σtεt,σt2=α0+i=1∑mαiat−i2+j=1∑sβjσt−j2
其中
{
ε
t
}
\{ \varepsilon_t \}
{εt}为零均值单位方差的独立同分布白噪声列,
系数要求:
α
0
>
0
\alpha_0>0
α0>0,
α
i
≥
0
\alpha_i \geq 0
αi≥0,
β
j
≥
0
\beta_j \geq 0
βj≥0,确保方差必须是正的。
0
<
∑
i
=
1
m
α
i
+
∑
j
=
1
s
β
j
<
1
0 < \sum_{i=1}^m \alpha_i + \sum_{j=1}^s \beta_j < 1
0<∑i=1mαi+∑j=1sβj<1, 这最后一个条件用来保证满足模型的
a
t
a_t
at 的无条件方差有限且不变, 而条件方差
σ
t
2
\sigma_t^2
σt2可以随时间
t
t
t而变。
与ARMA模型比较
GARCH(1,1)转为ARMA(1,1)
tips:构造白噪声 η t = a t 2 − σ t 2 \eta_t=a_t^2-\sigma_t^2 ηt=at2−σt2
a
t
2
=
α
0
+
∑
i
=
1
max
(
m
,
s
)
(
α
i
+
β
i
)
a
t
−
i
2
+
η
t
−
∑
j
=
1
s
β
j
η
t
−
j
.
\begin{aligned} a_t^2 = \alpha_0 + \sum_{i=1}^{\max(m,s)} (\alpha_i + \beta_i) a_{t-i}^2 + \eta_t - \sum_{j=1}^s \beta_j \eta_{t-j} . \end{aligned}
at2=α0+i=1∑max(m,s)(αi+βi)at−i2+ηt−j=1∑sβjηt−j.
这就是关于
{
a
t
2
}
\{a_t^2\}
{at2}的ARMA(
max
(
m
,
s
)
,
s
\max(m,s), s
max(m,s),s)模型, 由ARMA模型的无条件期望的公式得
E
a
t
2
=
α
0
1
−
∑
i
=
1
max
(
m
,
s
)
(
α
i
+
β
i
)
=
α
0
1
−
∑
i
=
1
m
α
i
−
∑
j
=
1
s
β
j
.
E a_t^2 = \frac{\alpha_0}{1 - \sum_{i=1}^{\max(m,s)} (\alpha_i + \beta_i)} = \frac{\alpha_0}{1 - \sum_{i=1}^m \alpha_i - \sum_{j=1}^s \beta_j} .
Eat2=1−∑i=1max(m,s)(αi+βi)α0=1−∑i=1mαi−∑j=1sβjα0.
这要求分母为正,即要求
∑
i
=
1
m
α
i
+
∑
j
=
1
s
β
j
<
1
\sum_{i=1}^m \alpha_i + \sum_{j=1}^s \beta_j < 1
∑i=1mαi+∑j=1sβj<1。 这时
a
t
a_t
at的无条件方差
Var
(
a
t
)
\text{Var}(a_t)
Var(at)也等于上式。
GARCH模型的性质【证明】
a t = σ t ε t , ε t i.i.d. WN ( 0 , 1 ) , σ t 2 = α 0 + α 1 a t − 1 2 + β 1 σ t − 1 2 . \begin{aligned} a_t =& \sigma_t \varepsilon_t, \quad \varepsilon_t \text{ i.i.d. WN} (0,1) , \\ \sigma_t^2 =& \alpha_0 + \alpha_1 a_{t-1}^2 + \beta_1 \sigma_{t-1}^2 . \end{aligned} at=σt2=σtεt,εt i.i.d. WN(0,1),α0+α1at−12+β1σt−12.
(1) 期望
为了计算无条件均值
E
a
t
Ea_t
Eat,先计算条件期望
E
(
a
t
∣
F
t
−
1
)
=
E
(
σ
t
ε
t
∣
F
t
−
1
)
=
σ
t
E
(
ε
t
∣
F
t
−
1
)
=
0.
E(a_t | F_{t-1}) = E(\sigma_t \varepsilon_t | F_{t-1}) = \sigma_t E(\varepsilon_t | F_{t-1}) = 0 .
E(at∣Ft−1)=E(σtεt∣Ft−1)=σtE(εt∣Ft−1)=0.
这里用了
σ
t
∈
F
t
−
1
而
ε
t
\sigma_t \in F_{t-1}而\varepsilon_t
σt∈Ft−1而εt与
F
t
−
1
F_{t-1}
Ft−1独立。 于是
E
a
t
=
E
[
E
(
a
t
∣
F
t
−
1
)
]
=
0.
E a_t = E[ E(a_t | F_{t-1})] = 0 .
Eat=E[E(at∣Ft−1)]=0.
即GARCH模型的新息
a
t
a_t
at的无条件期望为零。
(2) 方差
来计算
a
t
a_t
at的无条件方差。 设模型的
{
a
t
}
\{ a_t \}
{at}序列存在严平稳解,则
Var
(
a
t
)
=
E
(
a
t
2
)
=
E
[
E
(
a
t
2
∣
F
t
−
1
)
]
=
E
[
E
(
σ
t
2
ε
t
2
∣
F
t
−
1
)
]
=
E
[
σ
t
2
E
(
ε
t
2
∣
F
t
−
1
)
]
=
E
[
σ
t
2
E
(
ε
t
2
)
]
=
E
[
σ
t
2
]
=
E
[
α
0
+
α
1
a
t
−
1
2
+
β
1
σ
t
−
1
2
]
=
α
0
+
α
1
E
(
a
t
−
1
2
)
+
β
1
E
[
E
(
a
t
−
1
2
∣
F
t
−
2
)
]
=
α
0
+
(
α
1
+
β
1
)
E
(
a
t
−
1
2
)
.
\begin{aligned} \text{Var}(a_t) =& E(a_t^2) = E[ E(a_t^2 | F_{t-1})] = E[ E(\sigma_t^2 \varepsilon_t^2 | F_{t-1})]\\ =& E[\sigma_t^2 E(\varepsilon_t^2 | F_{t-1})] = E[\sigma_t^2 E(\varepsilon_t^2)] \\ =& E[\sigma_t^2] = E[\alpha_0 + \alpha_1 a_{t-1}^2 + \beta_1 \sigma_{t-1}^2] \\ =& \alpha_0 + \alpha_1 E(a_{t-1}^2) + \beta_1 E[E(a_{t-1}^2|F_{t-2})]\\ =& \alpha_0 + (\alpha_1 + \beta_1) E(a_{t-1}^2) . \end{aligned}
Var(at)=====E(at2)=E[E(at2∣Ft−1)]=E[E(σt2εt2∣Ft−1)]E[σt2E(εt2∣Ft−1)]=E[σt2E(εt2)]E[σt2]=E[α0+α1at−12+β1σt−12]α0+α1E(at−12)+β1E[E(at−12∣Ft−2)]α0+(α1+β1)E(at−12).
令
E
a
t
2
=
E
a
t
−
1
2
E a_t^2 = E a_{t-1}^2
Eat2=Eat−12, 解得
Var
(
a
t
)
=
E
a
t
2
=
α
0
1
−
α
1
−
β
1
.
\text{Var}(a_t) = E a_t^2 = \frac{\alpha_0}{1 - \alpha_1 - \beta_1} .
Var(at)=Eat2=1−α1−β1α0.
GARCH(1,1)模型的性质:
第一,像ARCH模型一样, a t a_t at存在波动率聚集, 一个较大的 a t − 1 a_{t-1} at−1或 σ t − 1 \sigma_{t-1} σt−1使得1步以后的条件方差变大, 从而倾向于出现较大的对数收益率。
第二,当
ε
t
\varepsilon_t
εt为标准正态分布时, 在如下条件下
a
t
a_t
at有无条件四阶矩:
1
−
2
α
1
2
−
(
α
1
+
β
1
)
2
>
0.
1 - 2 \alpha_1^2 - (\alpha_1 + \beta_1)^2 > 0 .
1−2α12−(α1+β1)2>0.
这时超额峰度为
E
a
t
4
(
E
a
t
2
)
2
−
3
=
2
[
1
−
(
α
1
+
β
1
)
2
+
α
1
2
]
1
−
(
α
1
+
β
1
)
2
−
2
α
1
2
>
0.
\frac{E a_t^4}{(Ea_t^2)^2} - 3 = \frac{2\left[1 - (\alpha_1 + \beta_1)^2 + \alpha_1^2 \right]} {1 - (\alpha_1 + \beta_1)^2 - 2\alpha_1^2} > 0 .
(Eat2)2Eat4−3=1−(α1+β1)2−2α122[1−(α1+β1)2+α12]>0.
即
a
t
a_t
at分布厚尾。 但是, 对实际数据建模时即使使用条件t分布, 对数据的厚尾性的拟合仍可能不足。
第三,GARCH模型给出了一个比较简单的波动率模型。
第四,因为 σ t 2 对 a t − i \sigma_t^2对a_{t-i} σt2对at−i的依赖是通过 a t − i 2 a_{t-i}^2 at−i2, 所以一个取正值的扰动 a t − i a_{t-i} at−i和一个取负值的 a t − i a_{t-i} at−i, 只要绝对值相等, 对后续波动率的影响就是相等的, 不能体现杠杆效应。
GARCH模型相较于ARCH模型的优点
可以解决ARCH高阶的问题
GARCH、ARCH各自的优缺点
像ARCH模型一样,
a
t
a_t
at存在波动率聚集
对数据的厚尾性的拟合仍可能不足
GARCH模型给出了一个比较简单的波动率模型
只要绝对值相等, 对后续波动率的影响就是相等的, 不能体现杠杆效应
GARCH模型的建模步骤
ARCH模型的建模步骤也适用于GARCH模型的建模。 GARCH模型的定阶方法研究不多, 一般用试错法尝试较低阶的GARCH模型, 如GARCH(1,1), GARCH(2,1), GARCH(1,2)等。 许多情况下GARCH(1,1)就能解决问题。
为了估计参数, 可以假定初始的 σ t 2 \sigma_t^2 σt2已知, 递推计算后续的 σ t 2 \sigma_t^2 σt2并计算条件似然函数, 求条件似然函数的最大值点得到参数估计。 有时用 a t a_t at的样本方差作为初始的 σ t \sigma_t σt的值。
为了检验模型的充分性, 可以计算标准化残差
a
~
t
=
a
t
σ
t
,
\tilde a_t = \frac{a_t}{\sigma_t} ,
a~t=σtat,
通过对
a
~
t
\tilde a_t
a~t和
a
~
t
2
\tilde a_t^2
a~t2的白噪声检验确认模型可以接受, 还可以做
a
~
t
\tilde a_t
a~t相对于条件分布的QQ图以检验模型假设的条件分布的拟合优度。
GARCH模型白噪声检验工作what+how+why
19 改进的GARCH模型
RGARCH\TGARCH\APARCH相较于GARCH模型的优点/区别
RGARCH\TGARCH\ APARCH模型结构
APARCH模型的估计【代码】
EGARCH模型
指数GARCH(EGARCH)模型允许正负资产收益率对波动率有不对称的影响。
EGARCH(m,s)模型可以用滞后算子的形式写成
a
t
=
σ
t
ε
t
,
ln
σ
t
2
=
α
0
′
+
1
+
α
2
B
+
⋯
+
α
m
B
m
−
1
1
−
β
1
B
−
⋯
−
β
s
B
s
g
(
ε
t
−
1
)
\begin{aligned} a_t = \sigma_t \varepsilon_t, \quad \ln\sigma_t^2 = \alpha_0' + \frac{1 + \alpha_2 B + \dots + \alpha_m B^{m-1}}{ 1 - \beta_1 B - \dots - \beta_s B^s} g(\varepsilon_{t-1}) \end{aligned}
at=σtεt,lnσt2=α0′+1−β1B−⋯−βsBs1+α2B+⋯+αmBm−1g(εt−1)
α
0
′
\alpha_0'
α0′为常数, 其中
B
B
B是滞后算子, 多项式
1
+
α
2
z
+
⋯
+
α
m
z
m
−
1
1 + \alpha_2 z + \dots + \alpha_m z^{m-1}
1+α2z+⋯+αmzm−1和
1
−
β
1
z
−
⋯
−
β
m
z
m
1 - \beta_1 z - \dots - \beta_m z^m
1−β1z−⋯−βmzm的根都在单位圆外且两个多项式没有公因子。没有系数约束条件。
a
t
=
σ
t
ε
t
,
ln
σ
t
2
=
α
0
(
1
−
α
)
+
g
(
ε
t
−
1
)
+
α
ln
σ
t
−
1
2
.
\begin{aligned} a_t =& \sigma_t \varepsilon_t, \\ \ln \sigma_t^2 =& \alpha_0 (1-\alpha) + g(\varepsilon_{t-1})+ \alpha \ln\sigma_{t-1}^2 . \end{aligned}
at=lnσt2=σtεt,α0(1−α)+g(εt−1)+αlnσt−12.
EGARCH与GARCH模型的区别还有:
- 使用条件方差的对数建模, 因为对数值可正可负, 这就取消了GARCH模型对系数必须非负的限制。
- g ( ε t − j ) = g ( a t − j / σ t − j ) g(\varepsilon_{t-j})=g(a_{t-j}/\sigma_{t-j}) g(εt−j)=g(at−j/σt−j)的使用使得波动率对 a t − j a_{t-j} at−j的依赖关系与 a t − j a_{t-j} at−j的正负号有关, 可以用来描述正负收益率对波动率的不同的影响, 即杠杆效应。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









