







第一章 绪论
(一)课程内容
1 大数据安全
- 如何在满足可用性的前提下实现大数据机密性
安全与效率之间的平衡一直信息安全领域关注的重要问题。在大数据场景下,数据的高速流动特性以及操作多样性使得数据的安全与效率之间的矛盾更加突出。 - 如何实现大数据的安全共享
在大数据访问控制中,用户难以信赖服务商正确实施访问控制策略,且在大数据应用中实现用户角色与权限划分更为困难。 - 如何实现大数据真实性验证与可信溯源
当一定数量的虚假信息混杂在真实信息之中时,往往容易导致人们误判。(例如:点评网站上的虚假评论)最终影响数据分析结果的准确性。需要基于数据的来源真实性、传播途径、加工处理过程等,了解各项数据可信度,防止分析得出无意义或者错误的结果。
2 大数据隐私保护
- 由于去匿名化技术的发展,实现身份匿名越来越困难
仅数据发布时做简单的去标识处理已经无法保证用户隐私安全,通过链接不同数据源的信息,攻击者可能发起身份重识别攻击,逆向分析出匿名用户的真实身份,导致用户的身份隐私泄露。 - 基于大数据对人们状态和行为的预测带来隐私泄露威胁
随着深度学习等人工智能技术快速发展,通过对用户行为建模与分析,个人行为规律可以被更为准确的预测与识别,刻意隐藏的敏感属性可以被推测出来。
3 区别与联系@
- 大数据安全需求更为广泛,关注的目标不仅包括数据机密性,还包括数据完整性、真实性、不可否认性,以及平台安全、数据权属判定等。
而隐私保护需求一般仅聚焦于匿名性。 - 虽然隐私保护中的数据匿名需求与安全需求之一的机密性需求看上去比较类似,但后者显然严格得多。
- 匿名性仅防止攻击者将已公布的信息与现实中的用户联系起来,
- 而机密性则要求数据对于非授权用户完全不可访问。
- 在大数据安全问题下,一般来说数据对象是有明确定义。
而在涉及隐私保护需求时,所指的用户“隐私”则较为笼统,可能具有多种数据形态存在。
| 大数据安全 | 隐私保护 |
|---|---|
| 数据机密性、数据完整性、真实性、不可否认性,以及平台安全,数据权属判定 | 匿名性 |
| 安全需求的机密性:要求数据对于非授权用户完全不可访问 | 数据匿名需求:防止攻击者将已公布的信息与现实中的用户联系起来 |
| 数据对象是有明确定义 | 所指的用户“隐私”则较为笼统,可能具有多种数据形态存在 |
(二)基本知识:基本密码学
1 安全需求
- 机密性(Confidentiality):信息不泄露给非授权的用户
例:访问系统的BLP模型、泄密 - 完整性(Integrity):信息不被非法修改
例:访问系统的Biba模型、修改内容 - 可用性(Availability):信息系统能正确和及时地为合法用户提供服务的能力
例:dos/ddos攻击、流量分析 - 可鉴别性(Authentication):接收者能鉴别和识别信息的来源
例:破坏数据包收到的先后顺序、冒名顶替 - 抗抵赖性(Non-repudiation):生产信息的人不能事后否认该生产
例:不承认发送过某个文件
2 加密技术
(1) 相关定义
传统加密技术的主要目标是保护数据的机密性。
一个加密算法被定义为一对数据变换,其中一个变换应用于数据的起源项,称为明文;所产生的相应数据项称为密文。这个变换称为加密变换。而另一个变换应用于密文,恢复出明文,称为解密变换。
- 加密变换;密文=加密变换(明文,加密密钥)
- 解密变换;明文=解密变换(密文,解密密钥)
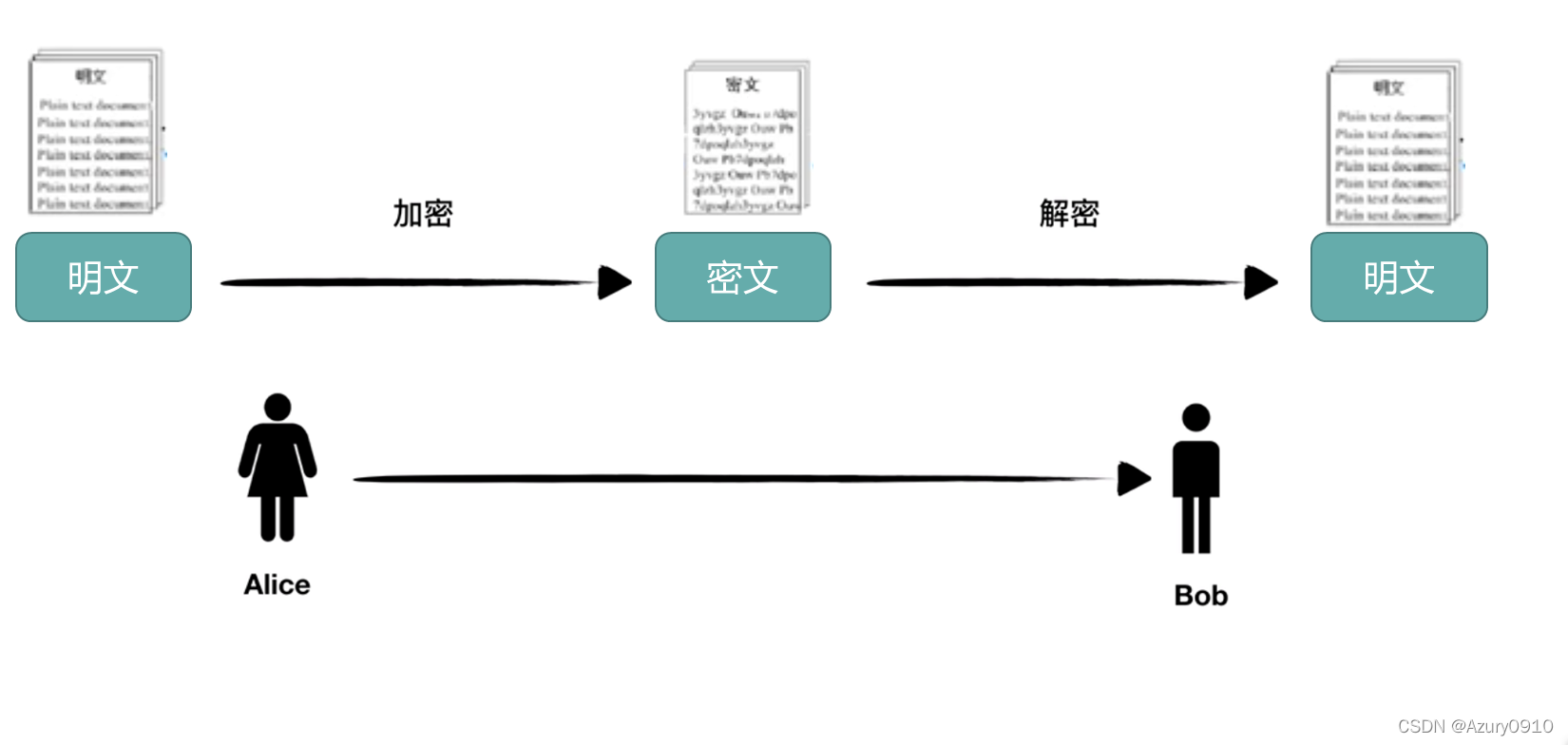
明文和密钥通常都可以用比特串的形式存储;但密文较长,密钥较短。
(2) 对称加密技术
加密和解密密钥相同,或可以互相推导。就像需要用钥匙才能锁上的门锁。
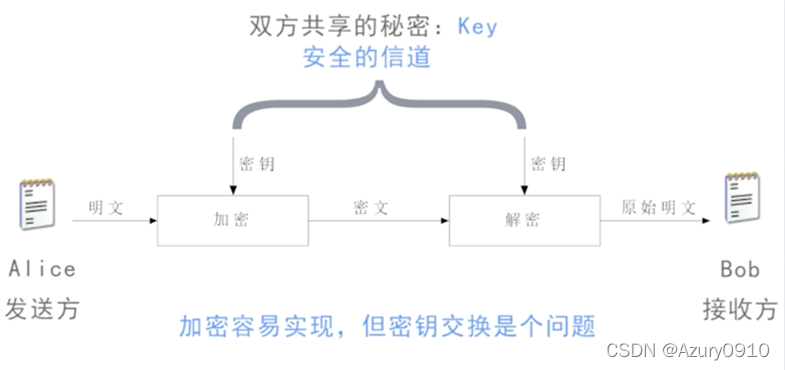
具备机密性、可鉴别性、完整性;不保证抗抵赖性。
机密性:
可鉴别性:

完整性:
抗抵赖性:
由于数字世界中,复制件和原件是无法区分的,因此加密者和解密者对密文有相同的生产能力。
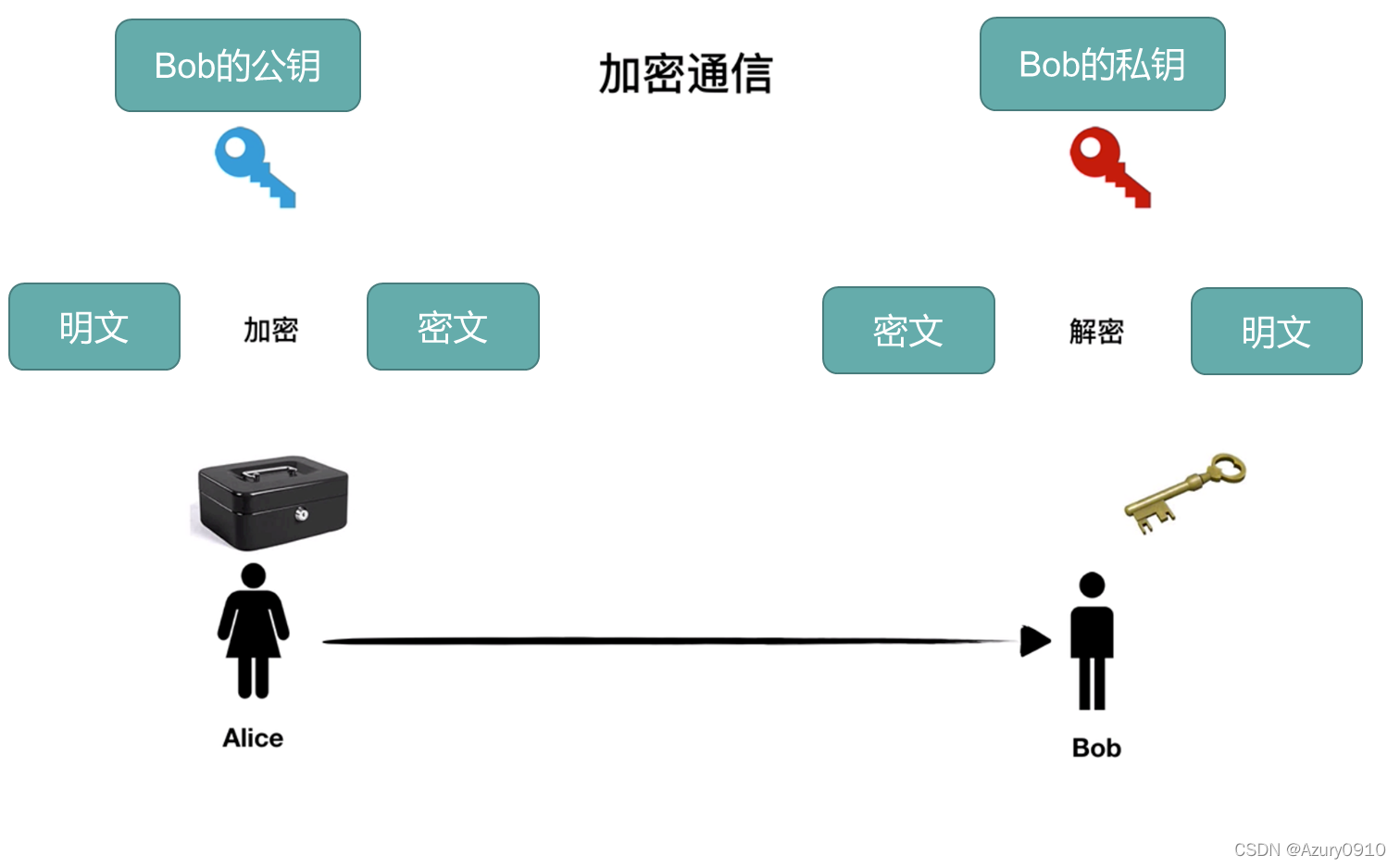
(3) 非对称加密技术(公钥加密)
采用两个不同的密钥将加密和解密功能分开。
- 一个密钥称为私钥,像对称密码中一样,该密钥被秘密保存。
- 另一个密钥称为公钥,不需要保密。
公钥密码必须具有如下重要特性:给定公钥,要确定出私钥在计算上是不可行的。就像常见的门,锁门很容易,但开门需要钥匙。
非对称加密技术的六要素:
- 明文
- 密文
- 公开密钥(记作PU或KU)Public Key
- 私有密钥(记作PR或KR)Private Key
- 加密算法
- 解密算法
Tip:
- 接收方B容易通过计算产生一对密钥(公开密钥 K U b KU_b KUb,私有密钥 K R b KR_b KRb)
- 发送方A容易计算产生密文 C = E K U b ( M ) C=E_{KU_b} (M) C=EKUb(M)
- 接收方B容易通过计算解密密文 M = D K R b ( C ) = D K R b [ E K U b ( M ) ] M=D_{KR_b}(C)=D_{KR_b}[E_{KU_b}(M)] M=DKRb(C)=DKRb[EKUb(M)]
- 敌对方即使知道公开密钥
K
U
b
{KU}_b
KUb,要确定私有密钥
K
R
b
{KR}_b
KRb在计算上不可行
敌对方即使知道公开密钥 K U b KU_b KUb和密文 C C C,要计算明文 M M M在计算上不可行 - 密钥对互相之间可交换使用
M = D K R b [ E K U b ( M ) ] = D K U b [ E K R b ( M ) ] M=D_{KR_b}[E_{KU_b}(M)]=D_{KU_b} [E_{KR_b}(M)] M=DKRb[EKUb(M)]=DKUb[EKRb(M)]
对比
| 项目 | 对称加密技术 | 非对称加密技术 |
|---|---|---|
| 特征 | 双方信息对等 | 双方信息不对等,根据公钥计算私钥是困难的 |
| 条件 | 实现密钥交换 | 不需要密钥交换 |
| 效果 | 保证机密性、可鉴别性、完整性;不保证抗抵赖性 | 保证机密性;不保证可鉴别性、抗抵赖性、完整性 |
| 缺点 | / | 解密加密效率低 |
| 密钥个数 | n个人两两秘密通信需要 n(n-1)/2个密钥 | n个人两两秘密通信需要n对密钥 |
(4) 混合加密技术@
为克服非对称加密技术的缺点——解密加密效率低
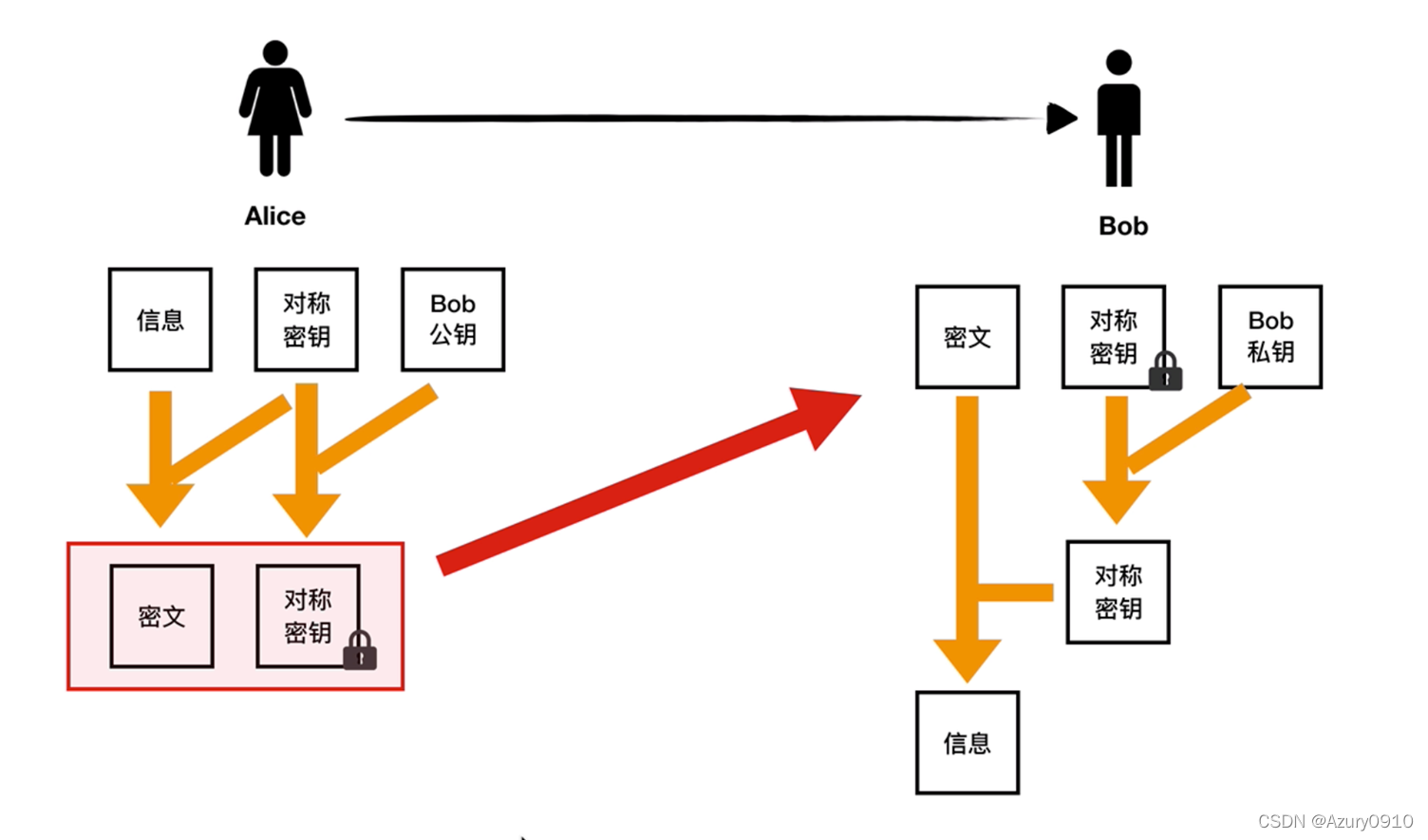
发送者A用对称密钥加密明文,用公钥加密对称密钥,接受者B用私钥解密对称密钥,用对称密钥解密密文得到信息。
- B将公钥传递给A;
- A用对称密钥对待传递的消息加密,并使用B的公钥加密该对称密钥;
- A将对称加密后的消息和公钥加密后的对称密钥传给B;
- B用自己的私钥对加密后的对称密钥解密,得到对称密钥;
- B用解密得到的对称密钥对加密后的消息解密,得到A传递来的消息。
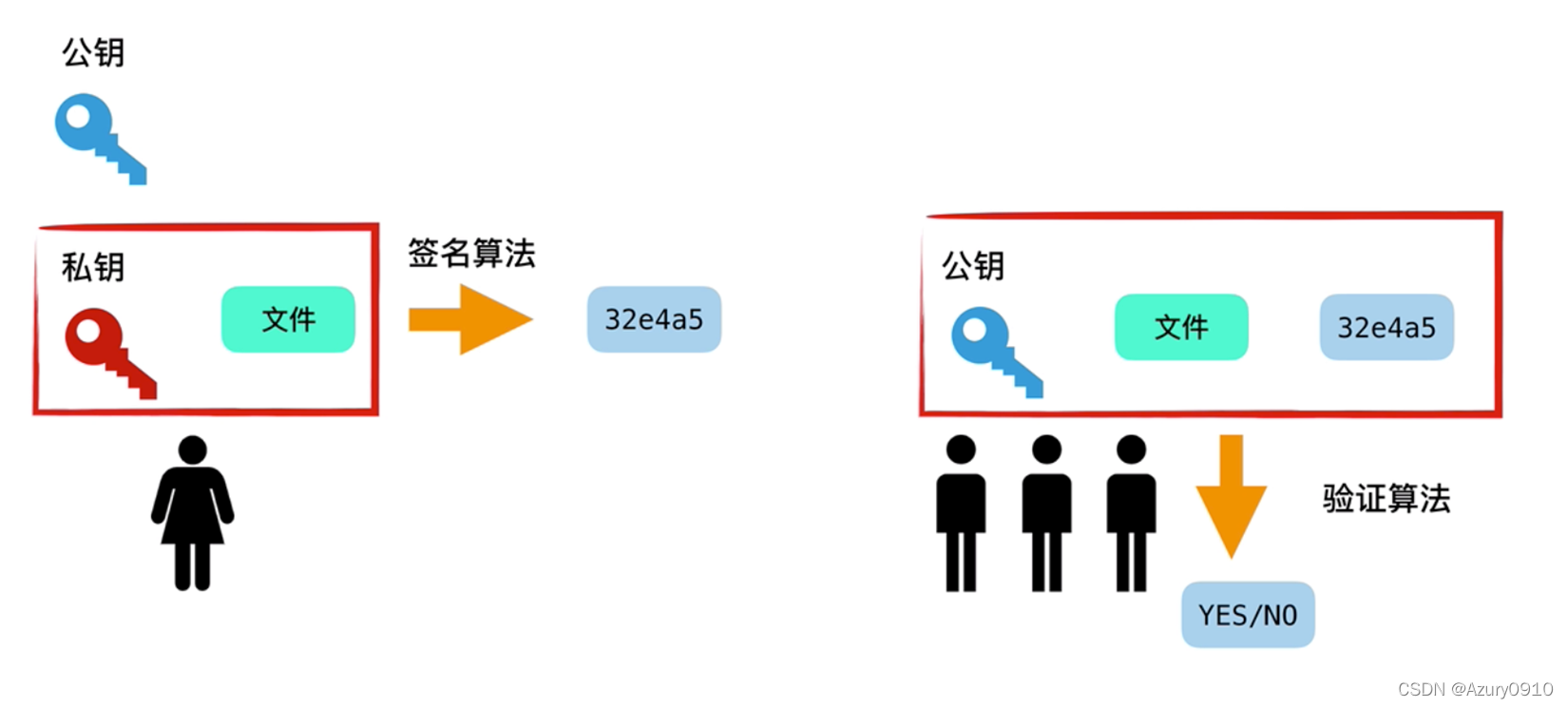
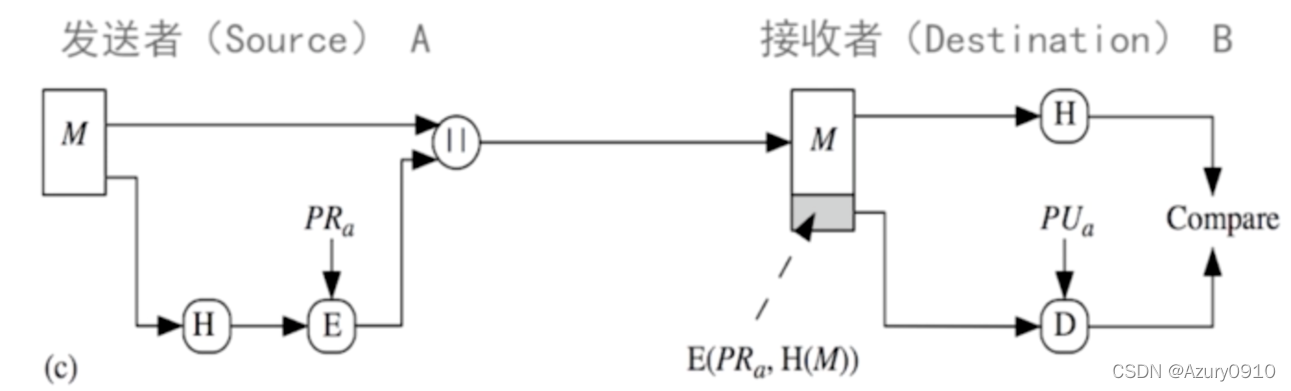
3 数字签名技术
数字签名的目的是证明文件归签名者所有
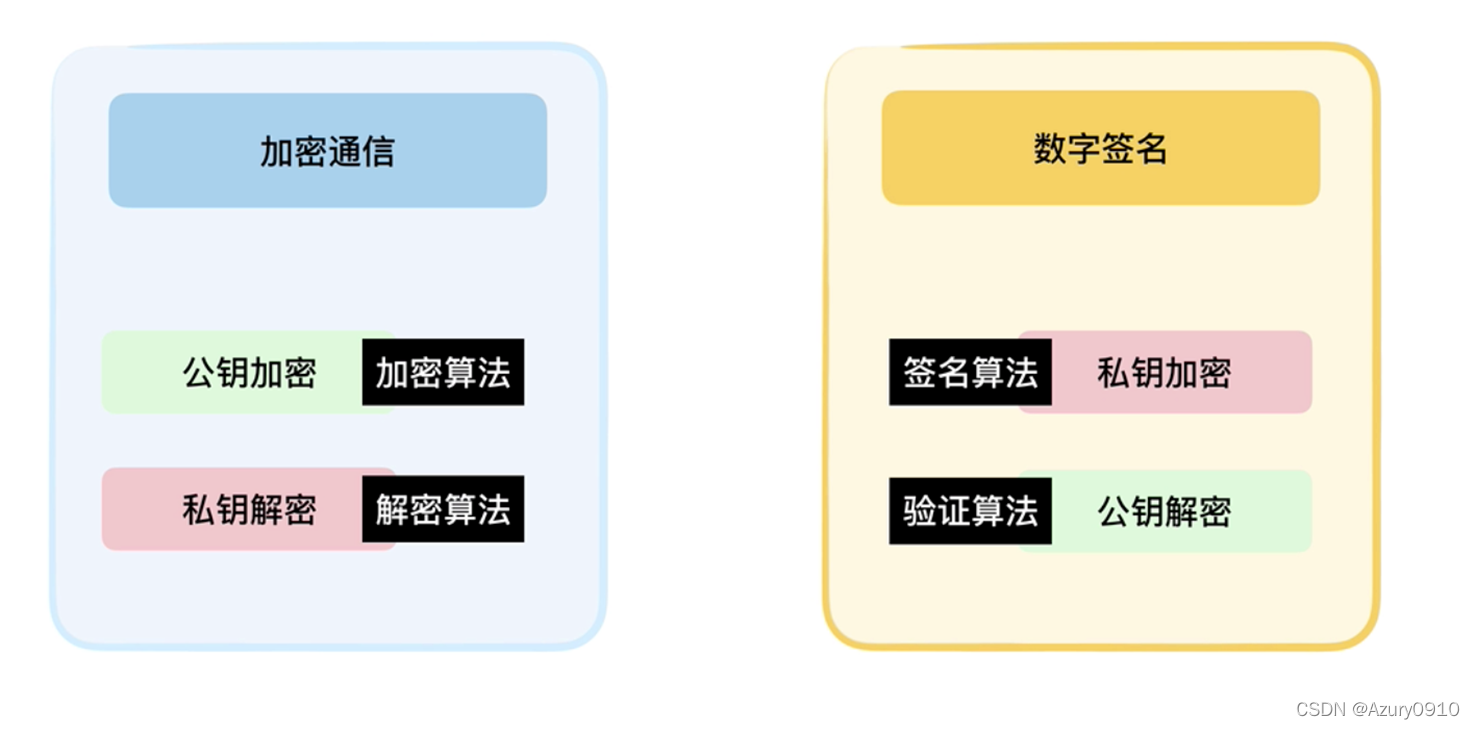
- 可鉴别性
在不知道签名者私钥的情况下,任何其他人都不能伪造签名。因此前面可用于鉴别签名者。 - 抗抵赖性
签名者无法否认自己对消息对签名。 - 完整性
任何消息的更改都将导致签名无法通过验证。
非对称加密技术保证信息的机密性,数字签名保证可鉴别性、抗抵赖性、完整性。
是否存在一种方法,同时满足四条性质?
答:先私钥后公钥
4 Hash和MAC技术
(1)Hash函数
Hash函数(也称哈希函数)可将任意长的消息压缩为固定长度的Hash值,Hash函数需满足如下性质:
- 单向性:从Hash值得到原消息是计算上不可行的
- 抗碰撞性:找到两个不同的报文Hash值相同,是计算上不可行的。
可用于文件完整性检验,密码保存,软件下载等场景。
不使用密码,任何人都可以计算,因此不能避免恶意篡改。比如在流氓软件的场景中,可以通过同时修改软件和Hash的方式实现恶意篡改。
Hash通常和非对称密码技术配合实现数字签名,避免用私钥加密明文而导致的效率低下。保证完整性、可鉴别性、抗抵赖性。
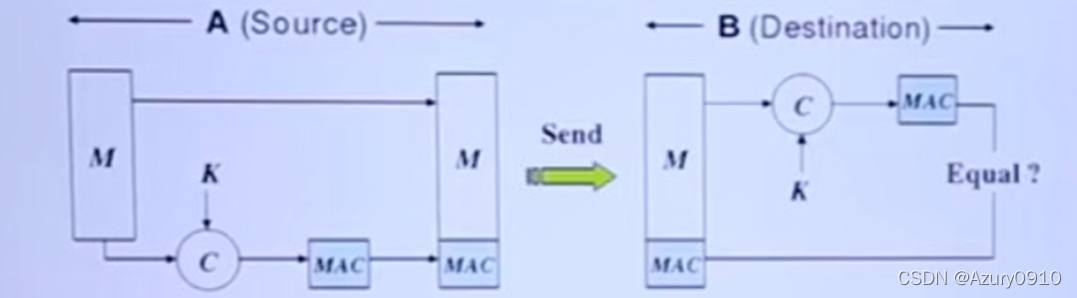
(2) MAC
MAC(Message Authentication Code,消息认证码/报文鉴别码)基于一个大尺寸数据生产一个小尺寸数据,在性能上也需要避免碰撞,但MAC算法有对称密钥参与,计算结果类似于一个加密的Hash值。
保证可鉴别性和完整性,不能抗抵赖(因为使用了对称密钥)。
| 加密技术 | 机密性 | 可鉴别性 | 完整性 | 抗抵赖性 |
|---|---|---|---|---|
| 对称加密技术 | √ | √ | √ | × |
| 非对称加密技术 | √ | × | × | × |
| Hash+非对称密码技术 | - | √ | √ | √ |
| MAC+对称加密技术 | √ | √ | √ | × |
5 密钥交换技术
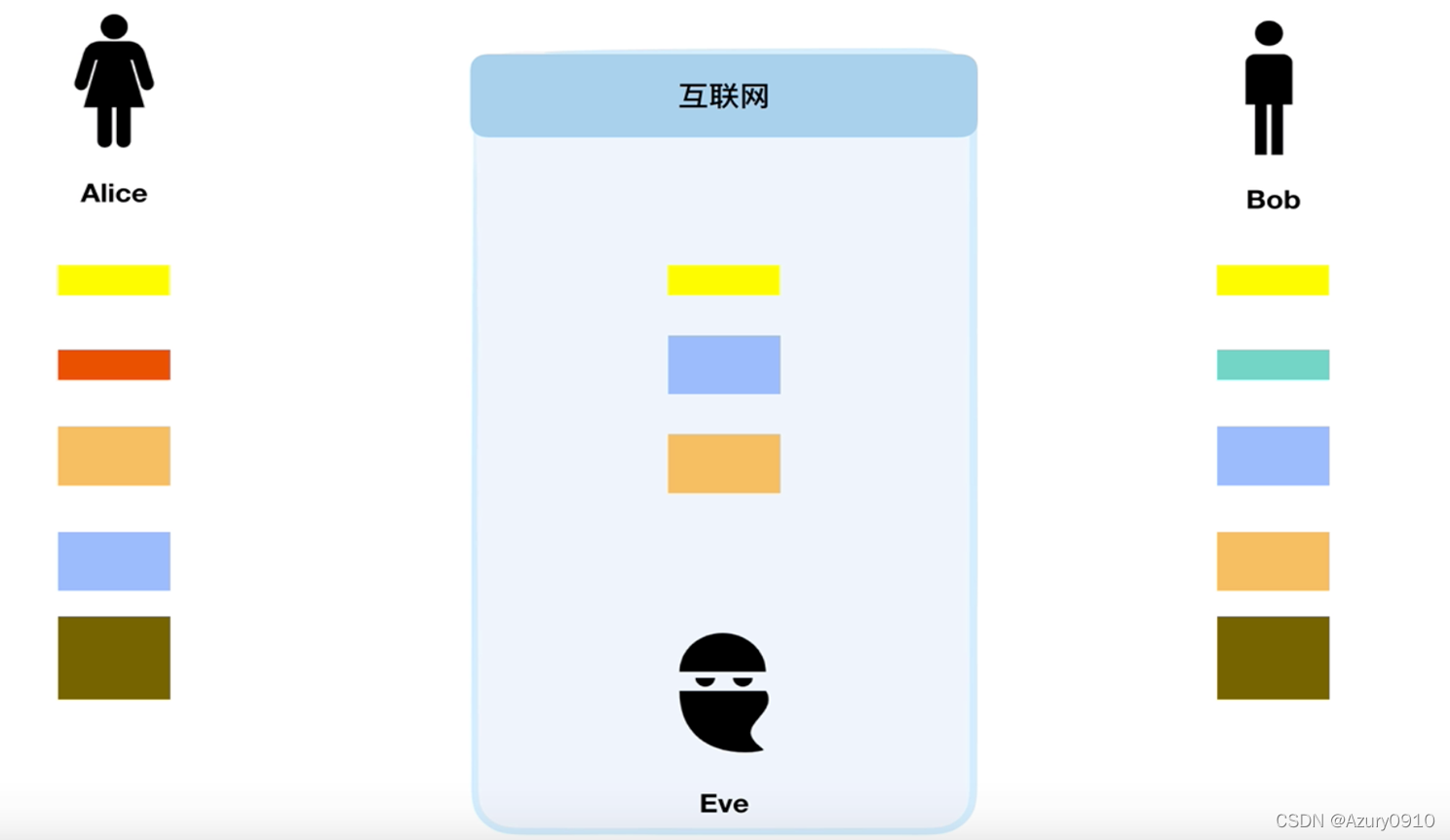
首先假设双方分别是Alice和Bob,他们就一个随机的初始的颜色达成了一致。这个颜色不需要被保密,但是每一次要不一样。在这个例子中,这个初始的颜色是黄色。然后他们两个人每一个人选择一个秘密的颜色,Alice只知道Alice的颜色,其他任何人都不知道Alice选的是什么颜色,Bob同理。在这个例子中,Alice选择的是红色,Bob选择的是蓝绿色。这个过程的关键部分是Alice和Bob每个人将他们自己的秘密颜色和他们对方彼此共享的颜色(初始的颜色即黄色)混合在一起,导致了分别是orang-tan色,和浅蓝色。他们公开的将混合之后的颜色进行交换。最终,他们每一个人将他们从对方收到的颜色和他们自己的private color进行混合。这个结果就是最终的混合颜色。在这个例子中是黄褐色。这个颜色和对方的颜色是一致的。
如果某个第三方听到了这个交换,他就会知道公共的颜色(黄色)和第一个混合的颜色(orange-tan和浅蓝色),但是对这个第三方来说,确定最终的秘密颜色(黄褐色)在计算上是很困难的。事实上,当在使用大的数字而不是颜色时,这个行为需要大量的计算。这个行为即使是现代超极计算机都是不可能在一个合理的时间内完成的。

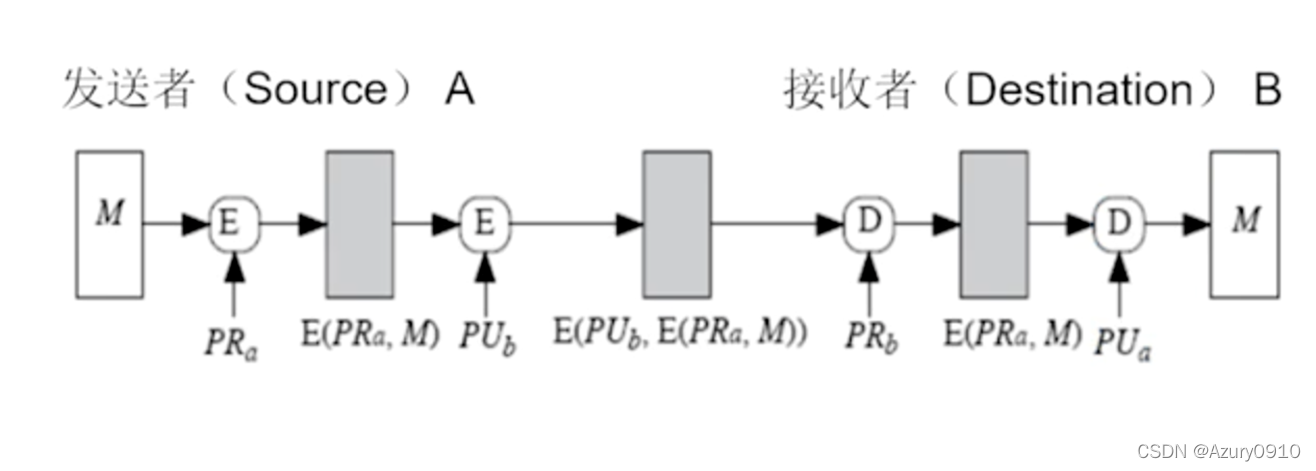
6 数字签名技术和非对称加密技术的混合使用 @
记Alice的公私钥对为 ( P U a , P R a ) (PU_a,PR_a) (PUa,PRa),Bob的公私钥对为 ( P U b , P R b ) (PU_b,PR_b) (PUb,PRb)
- Alice用自己的私钥对明文 M M M加密得到 E ( P R a , M ) E(PR_a,M) E(PRa,M),对明文进行签名;
- Alice再用Bob的公钥对签名后的消息加密,得到 E ( P U b , E ( P R a , M ) ) E(PU_b,E(PR_a,M)) E(PUb,E(PRa,M));
- Alice将 E ( P U b , E ( P R a , M ) ) E(PU_b,E(PR_a,M)) E(PUb,E(PRa,M))发送给Bob;
- Bob接收后,先用自己的私钥解密,得到 D ( P R b , E ( P U b , E ( P R a , M ) ) ) = E ( P R a , M ) D(PR_b,E(PU_b,E(PR_a,M)))=E(PR_a,M) D(PRb,E(PUb,E(PRa,M)))=E(PRa,M);
- 最后,Bob用Alice的公钥对解密后的消息 E ( P R a , M ) E(PR_a,M) E(PRa,M)进行解密运算,得到 D ( P U a , E ( P R a , M ) ) = M D(PU_a, E(PR_a,M))=M D(PUa,E(PRa,M))=M,以获取明文 M M M并验证签名。
第二章 安全存储与访问控制技术
背景:Unix系统的权限管理
Unix是一个多用户操作系统,需要保证许多用户同时访问操作系统服务,这就要求系统具有高度安全性和隐私性。
Unix对每个用户分配唯一的用户号(UID),多个用户组成用户组,每个组分配一个组号(GID)。
系统管理员可以将用户分到组中,用户也可以属于多个组,Unix中的每个进程具有拥有者的UID和GID。
文件的权限有三种,读(r)、写(w)和执行(x)。下面为Unix文件权限的示例:
| 符号表示 | 含义 |
|---|---|
| rwx------ | 仅拥有者可以读、写、执行 |
| rwxr-xr-x | 拥有者可以读、写、执行;其他用户可以读和执行 |
| r-x—r-x | 拥有者和其他用户可以读和执行,同组其他用户没有权限 |
| rw-r----- | 拥有者可以读写,同组其他用户可读 |
字符每组依次为所有者、同组其他用户、其他用户
(一)早期访问控制技术
1 几个基本概念@引用监控机、主体、客体、操作、访问权限
早期的访问控制技术都是建立在可信引用监控机基础上的。引用监控机是在1972年由Anderson首次提出的抽象概念,它能够对系统中的主体和客体之间的授权访问关系进行监控。当数据存储系统中存在一个所有用户都信任的引用监控机时,就可以由它来执行各种访问控制策略,以实现客体资源的受控共享。
访问控制策略是对系统中用户访问资源行为的安全约束需求的具体描述。
引用监控机(Reference Monitor,RM):指系统中监控主体和客体之间授权访问关系的部件。
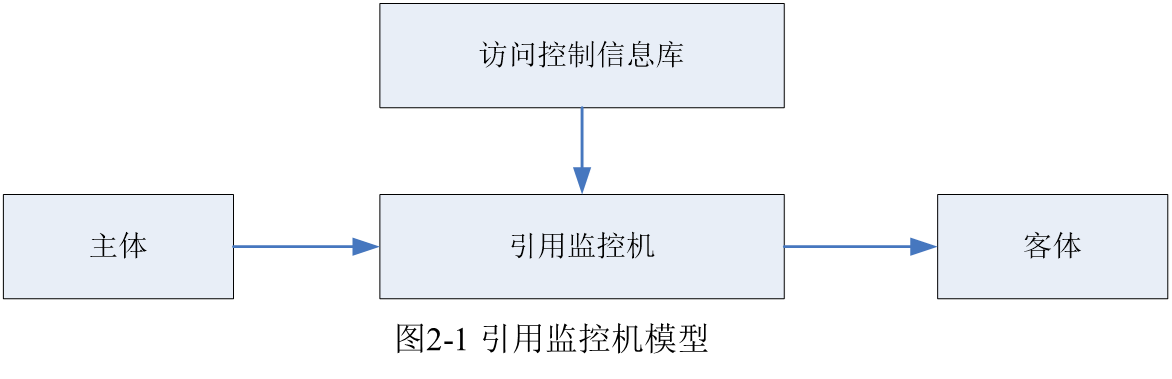
一般来说,这类访问控制技术都涉及如下的概念:
- 主体:能够发起对资源的访问请求的主动实体,通常为系统的用户或进程。
- 客体:能够被操作的实体,通常是各类系统和数据资源。
- 操作:主体对客体的读、写等动作行为。
- 访问权限:客体及对其的操作形成的二元组
<操作,客体>。
2 访问控制模型
访问控制模型的发展历史
在20世纪70年代,大型资源共享系统出现在政府和企业中。为了应对系统中的资源安全共享需求,访问控制矩阵等①自主访问控制模型和BLP、Biba等②强制访问控制模型被提出,并得到了广泛应用。
在20世纪80年代末到90年代初,人们发现在商业系统按照工作或职位来进行访问权限的管理更加方便。因此,③基于角色的访问控制模型被提出,并发展成为迄今为止在企业或组织中应用最为广泛的访问控制模型之一。
在21世纪初期,互联网技术使得用户对资源的访问处于开放环境。开放环境往往无法预先获得主客体身份的全集,且存在身份隐藏的需求。因此,④基于属性的访问控制被提出,它通过安全属性来管理授权,而不需要预先指导访问者身份。
(1)自主访问控制模型
客体的属主决定主体对客体的访问权限。可以被表述为
(
S
,
O
,
A
)
(S,O,A)
(S,O,A)三元组。其中,
S
S
S表示主体(subject)集合,
O
O
O表示客体(object)集合,且
S
⊂
O
S⊂O
S⊂O。
A
A
A表示访问(Access)矩阵,
A
(
s
i
,
o
j
)
A(s_i,o_j)
A(si,oj)则表示主体
s
i
s_i
si能够对客体
o
j
o_j
oj执行的操作权限。
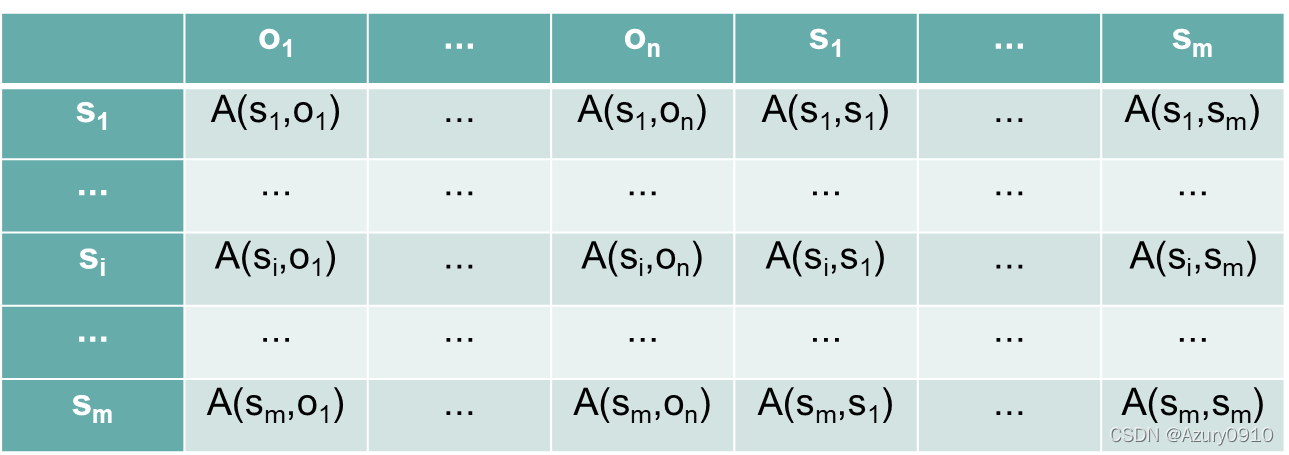
访问矩阵中的一行,代表某个主体对系统中所有客体的访问权限信息,一列代表所有主体对某个客体的访问权限信息。
自主访问控制模型的实施由RM根据访问矩阵A进行判定,而数据的所有者对权限的管理通过修改访问矩阵A来实现。
访问矩阵A在实际系统中主要有两种实现方式:
- 指定主体的能力表(Capabilities List,CL)
该表记录了每一个主体与一个权限集合的对应关系。权限集合中每个权限被表示为一个客体以及其上允许的操作集合的二元组。 - 指定客体的访问控制列表(Access Control List,ACL)
该表记录了每一个客体与一个权限集合的对应关系。权限集合中的每个权限被表示为一个主体以及其能够进行的操作集合的二元组。
(2)强制访问控制模型
(a)BLP模型:机密性、下读上写
BLP(Bell-lapadula)模型被用于保护系统的机密性,防止信息的未授权泄漏。
- 安全级别Level:公开(UC)、秘密(S)、机密(C)、绝密(TS)。它们之间的关系为UC≤S≤C≤TS。
- 范畴Category:为一个类别信息构成的集合,例如{中国,军事,科技}。具有该范畴的主体能够访问那些以该范畴子集为范畴的客体。
- 安全标记Label:由安全级别和范畴构成的二元组<Level,Category>,例如<C,{中国,科技>。
- 支配关系dom:安全标记A dom B,当且仅当Level_A≥Level_B,Category_A⊇Category_B。
BLP模型中在为系统中每个保护范围内的主客体都分配了安全标记后,主体对客体的访问行为应满足如下两条安全属性:
- 简单安全属性:主体S可以读客体O,当且仅当LabelS dom LabelO,且S对O有自主型读访问权限。
- 安全属性:主体S可以写客体O,当且仅当LabelO dom LabelS,且S对O具有自主型写权限。
从信息流角度看,上述两条读/写操作所应遵循的安全属性阻止了信息从高安全级别流入低安全级别,且使得信息“仅被需要知悉的人所知悉”,因此,能够有效地确保数据的机密性。
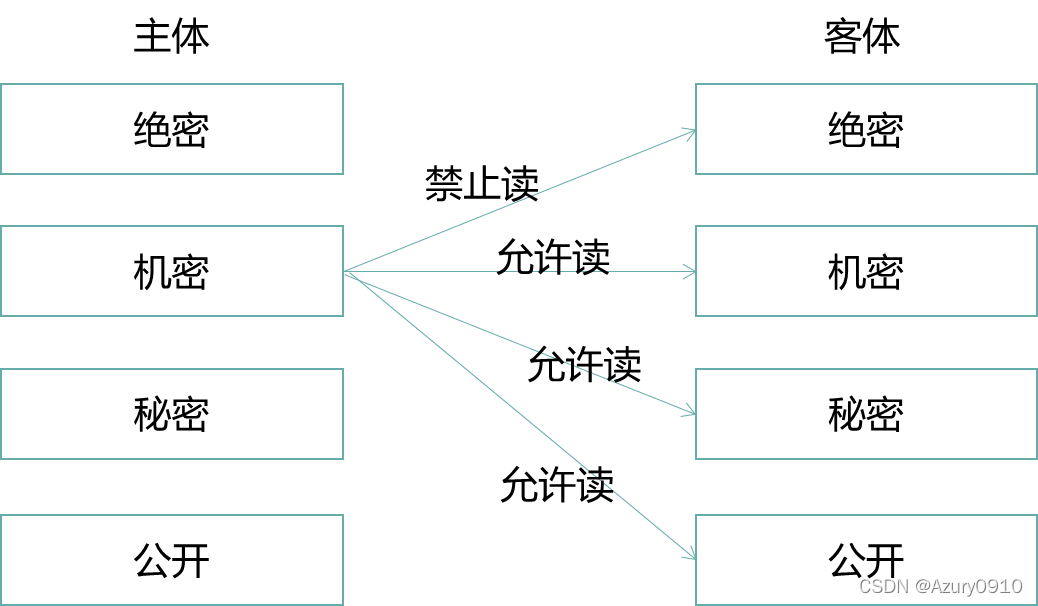
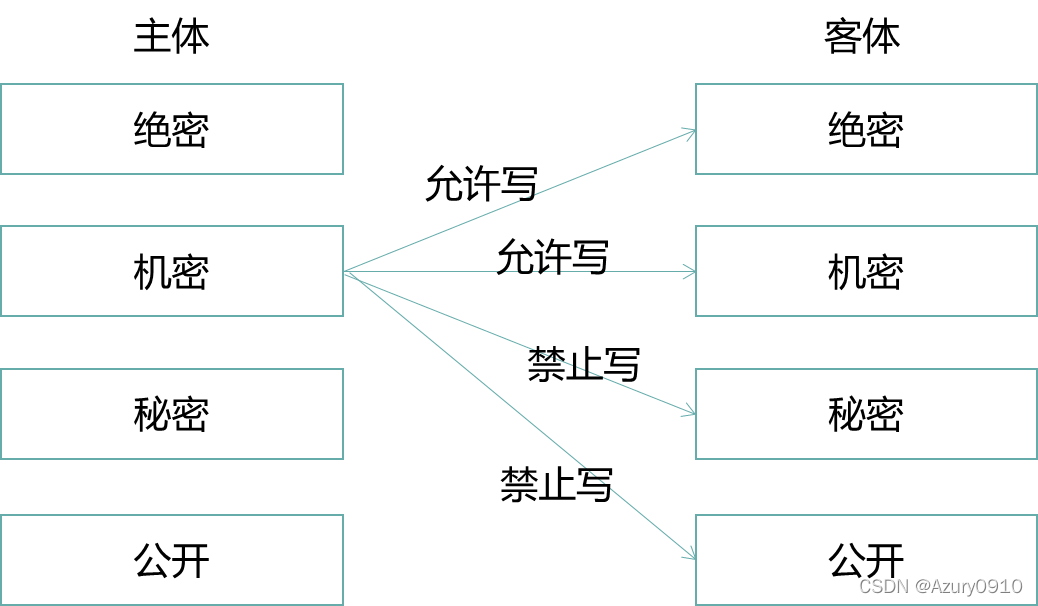
但是BLP模型这种“下读上写”的规则忽略了完整性的重要安全指标。
(b)Biba模型:完整性、上读下写
Biba模型是第一个关注完整性的访问控制模型,用于防止用户或应用程序等主体未授权地修改重要的数据或程序等客体。该模型可以看作是BLP模型的对偶。
- 完整性级别Level:代表了主/客体的可信度。完整性级别高的主体比完整性级别低的主体在行为上具有更高的可靠性;完整性级别高的客体比完整性级别低的客体所承载的信息更加精确和可靠 。
- 范畴Category:是基于类别信息对方问行为的进一步约束。若范畴Category_A⊇Category_B,则A能写入B;否则,A不能写入B
- 完整性标记Label:由完整性级别和范畴构成的二元组<Level,Category>。
- 支配关系dom:完整性标记A dom B,当且仅当Level_A≥Level_B,Category_A⊇Category_B。
Biba模型的严格完整性策略是BLP模型的对偶,也是不特别指明情况下所谓的Biba模型。它应满足如下安全属性:
- 完整性特性:主体S能够写入客体O,当且仅当LabelS dom LabelO。
- 调用特性:主体S1能够调用主体S2,当且仅当LabelS1 dom LabelS2。
- 简单完整性条件:主体S能够读取客体O,当且仅当LabelO dom LabelS。
基于上述三条安全属性,信息只能从高完整性级别的主客体流向低完整性级别的主客体,从而有效避免了低完整性级别的主客体对高安全级别主客体的完整性的“污染”。
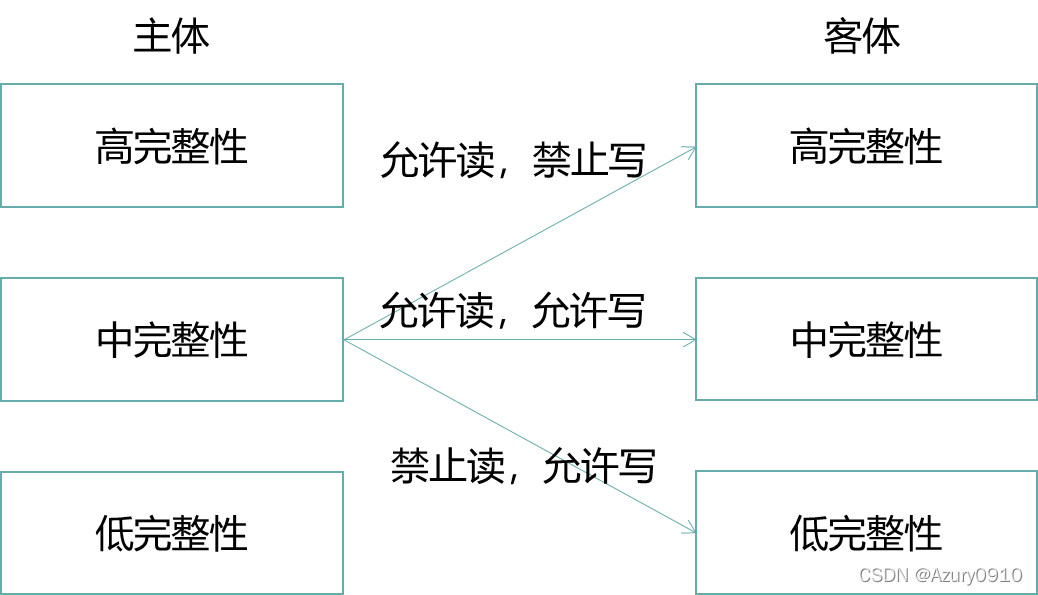
从上述BLP模型和Biba模型可以看出,强制访问控制是基于主客体标记之间的支配关系来实现的。在大数据场景下,由安全管理员来进行强制访问控制的授权管理是具有挑战性的。
- 随着主客体规模的急剧增长,安全标记的定义和管理将变得非常繁琐;
- 来自多个应用的用户主体和数据客体也将使得安全标记难以统一。
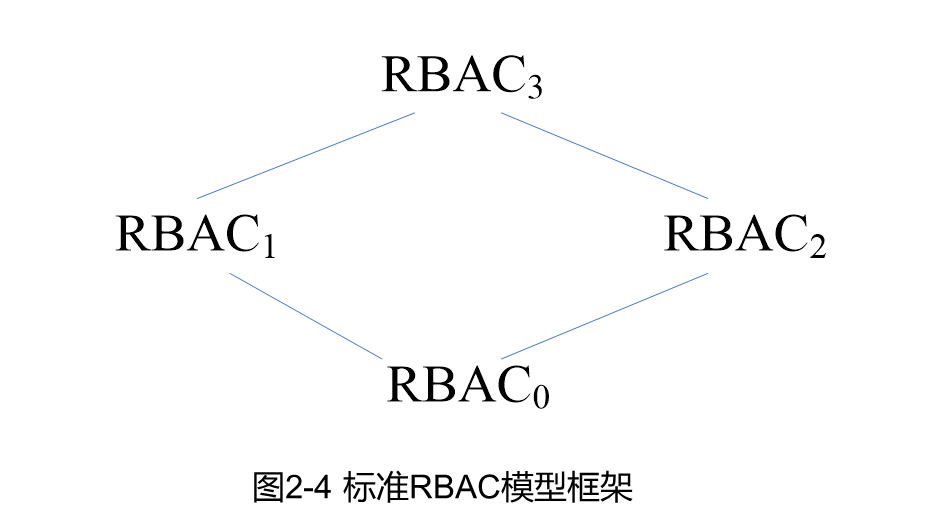
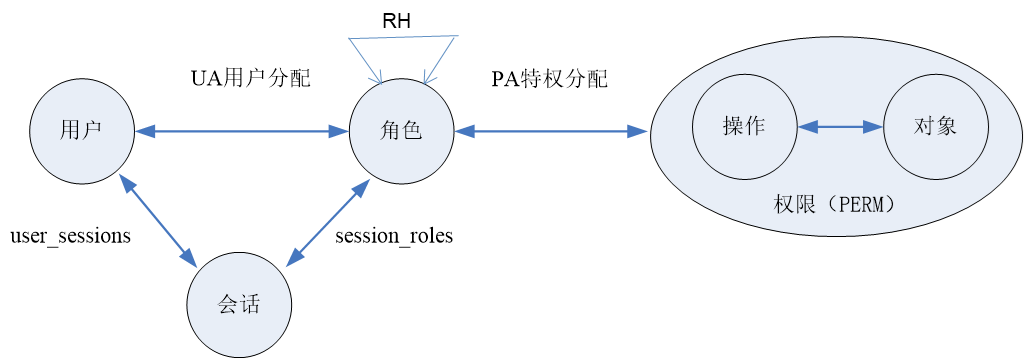
(3)基于角色的访问控制模型:RBAC0~3四个模型及其相互关系
RBAC0是最基本的模型,定义了用户、角色、会话和访问权限等要素。RBAC1在RBAC0的基础上引入了角色继承的概念。RBAC2增加了角色之间的约束条件,例如互斥角色等。RBAC3是RBAC1和RBAC2的综合,探讨了角色继承和约束之间的关系。
标准RBAC模型包括了RBAC0~3四个模型。
- RBAC0(Core RBAC),定义了用户、角色、会话和访问权限等要素,并形式化地描述了访问权限与角色的关系。
- RBAC1(Hierarchal RBAC)在RBAC0的基础上引入了角色继承的概念,简化了权限管理的复杂度。
- RBAC2(Constraint RBAC)增加了角色之间的约束条件,例如互斥角色、最小权限等。
- RBAC3(Combines RBAC)是RBAC1和RBAC2的综合,探讨了角色继承和约束之间的关系。
(a)Core RBAC
Core RBAC定义了基于角色访问控制的5个元素——用户、角色、对象、操作、权限以及一个动态的概念——会话。
角色访问控制的基本元素
- 用户是访问控制的主体,可以发起访问操作请求。
- 对象是访问控制的客体,指系统中受访问控制机制保护的资源.
- 操作是指对象上能够被执行的一组访问操作。
- 权限是指对象及其上指定的一组操作,是可以进行权限管理的最小单元。
- 角色是权限分配的载体,是一组有意义的权限集合。
- 会话用于维护用户和角色之间的动态映射关系。
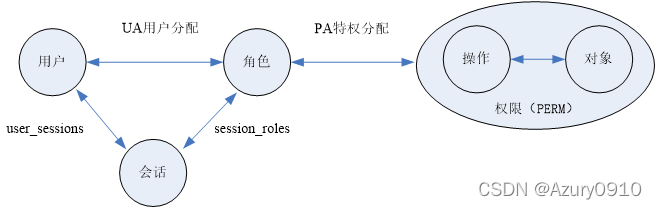
元素之间的关系: - UA用户分配:用户和角色之间是多对多的映射关系,记录了管理员为用户分配的所有角色。
- PA特权分配:角色与权限之间也是多对多的映射关系,记录了管理员为角色分配的所有权限
- user_sessions:用户与会话之间的一对多映射关系。即一个用户可通过登录操作开启一个或多个会话,而每个会话只对应一个用户。
- session_roles:会话与角色之间的多对多关系。即用户可以在一个会话中激活多个角色,而一个角色也可以在多个会话中被激活。
(b)Hierarchal RBAC
角色继承操作(Role Hierarchies,RH)即一个角色 r 1 r_1 r1继承了另一个角色 r 2 r_2 r2,那么 r 1 r_1 r1就拥有 r 2 r_2 r2的所有权限。角色继承分成两类:
- 多重继承:一个角色可以同时继承多个角色,且角色满足偏序关系
- 受限继承:在满足偏序关系的同时,一个角色只能继承一个角色,即继承关系为树结构
(c)Constraint RBAC
RBAC2在RBAC0的基础上引入了指责分离的概念,以调节角色之间的权限冲突,即如果两个角色拥有的某些权限是冲突的,那么就需要增加职责分离约束,使两个角色不能并存。根据约束生效的时期不同,这些约束可以被分为两类:
- 静态职责分离(Static Separation of Duty,SSD)
- 动态职责分离(Dynamic Separation of Duty,DSD)
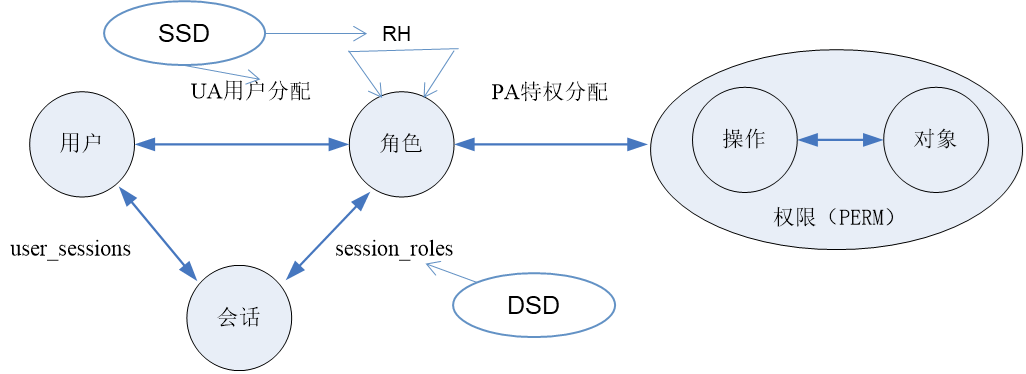
SSD主要作用于管理员为用户分配角色和定义角色继承关系阶段。若两个角色被设定了SSD约束,则不能被同时分配给一个用户,且不存在继承关系;
DSD主要作用于用户激活角色的阶段。若两个角色被设定了DSD约束,则不能在一个对话中被用户同时激活。
(d)Combines RBAC
Combines RBAC是在Core RBAC的基础上对Hierarchal RBAC的角色继承和Constraint RBAC的约束的综合。
(4)基于属性的访问控制模型:各组成部分的功能及流程
基于属性的访问控制模型是一种适用于开放环境下的访问控制技术。它通过安全属性来定义授权,并实施访问控制。由于安全属性可以由不同的属性权威分别定义和维护,所以具备较高的动态性和分散性,能够较好地适应开放式的环境。具体地,它包括如下几个重要概念:
- 实体entity:系统中存在的主体、客体,以及权限和环境。
- 环境environment:指访问控制发生时的系统环境。
- 属性attribute:用于描述上述实体的安全相关信息。它通常由属性名和属性值构成,又可分为以下几类:
- 主体属性:姓名、性别、年龄
- 客体属性:创建时间、大小
- 权限属性:业务操作读写性质的创建、读、写
- 环境属性:时间、日期、系统状态等。
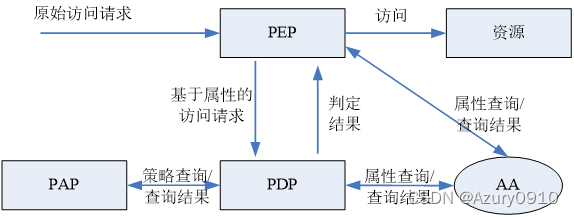
AA为属性权威 attribution authority,负责实体属性的创建和管理,并提供属性的查询。
PAP为策略管理点,负责访问控制策略的创建和管理,并提供策略的查询。
PEP为策略执行点,负责处理原始访问请求,查询AA中的属性信息生成基于属性的访问请求,并将其发送给PDP进行判定,然后根据PDP的判定结果实施访问控制。
PDP为策略判定点,负责根据PAP中的策略集对基于属性的访问请求进行判定,并将判定结果返回PEP。
较为适合大数据的开放式数据共享环境。然而属性的管理和标记对于安全管理员来说仍然是劳动密集型工作,且需要一定的专业领域知识。在大数据场景下,数据规模和应用复杂度使得这一问题更加严重。
3 局限性总结@
早期访问控制模型和技术在大数据应用场景下主要存在三方面问题:
- 安全管理员的授权管理难度更大
- 工作量大
- 领域知识匮乏
- 严格的访问控制策略难以适用
- 访问需求无法预知
- 访问需求动态变化
- 外包存储环境下无法使用
- 数据所有者不具备海量存储能力
- 数据所有者不具备构建可信引用监控机的能力
(二)基于数据分析的访问控制技术
1 角色挖掘技术
在基于角色的访问控制中,管理员需要解决两个问题:
- 创建哪些角色?
- 角色与用户、角色与权限如何关联?
大数据场景下角色的定义将是大工作量,且需要领域知识的任务。安全管理员已经难以自上而下地分析和归纳安全需求,并基于需求来定义角色了。为了解决该问题,自底向上定义角色的方法被提出,即采用数据挖掘技术从系统的访问控制信息等数据中获得角色的定义,也被称为角色挖掘(Role Mining)。目前经典的角色挖掘技术可以分为两类:
- 基于层次聚类的角色挖掘方法
- 生成式角色挖掘方法
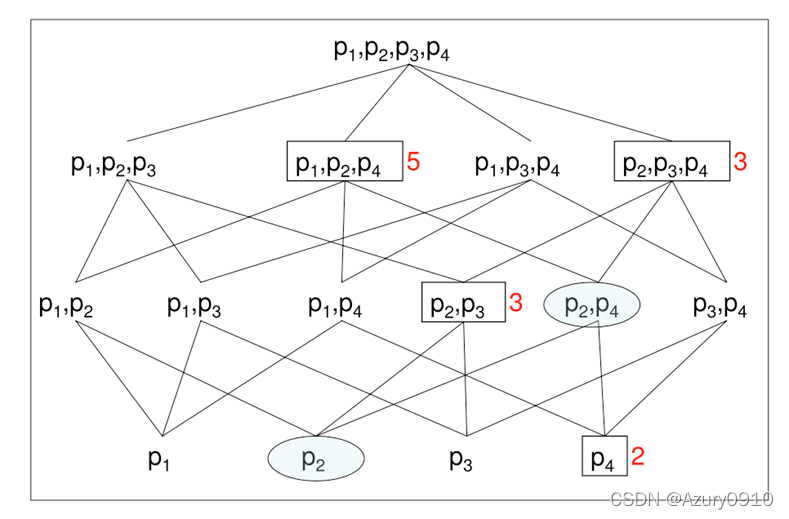
(1) 基于层次聚类的角色挖掘方法
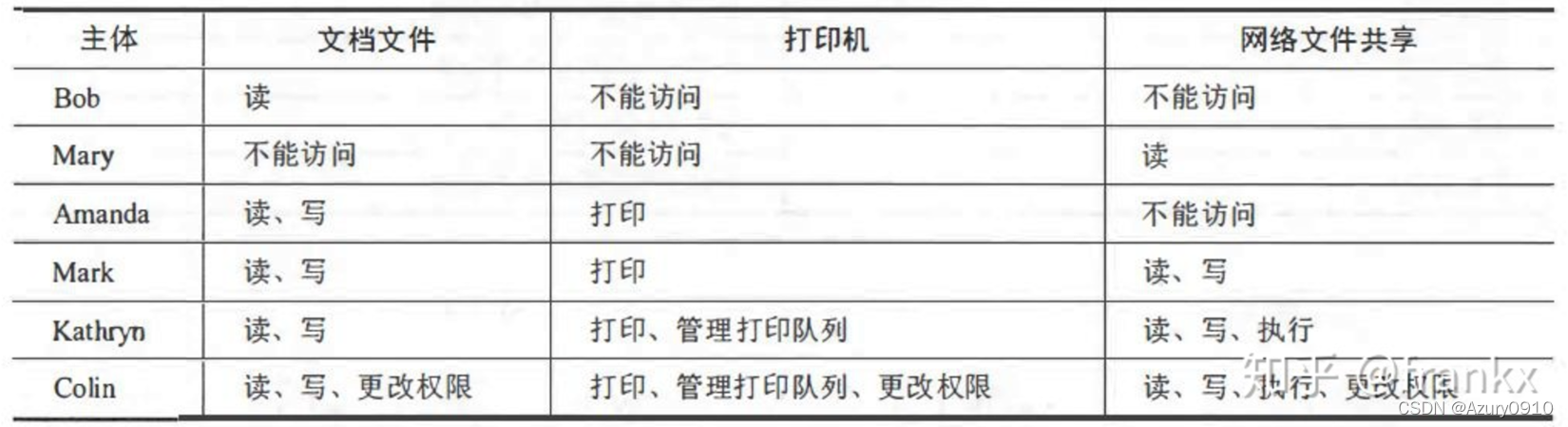
系统在初始情况下往往已经有了简单的访问权限分配——“哪些用户能够访问哪些数据”,例如授权信息表。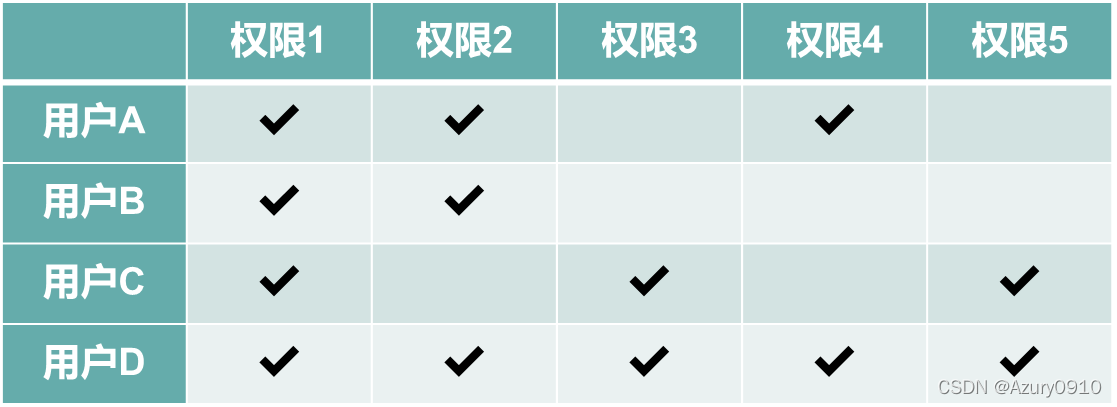
以上表格中所呈现的权限组合往往暗示着为了完成工作而应该设置的角色,因此,可以对已有的权限分配关系进行数据挖掘来寻找潜在的角色概念,并将角色与用户、角色与权限分别关联。
我们将角色看作大量用户共享的权限组合,并假设真实的角色定义已经正确且完整地隐含在当前的授权数据中。也就是说,所有人持有的权限都是有意义的,同时已有的权限分配都是正确的。
聚类是一种非监督场景下的发现数据潜在模式的经典方法。系统的用户基数越大,权限越多,这种权限分配的潜在模式就越明显,采用聚类进行角色挖掘的效果就越好。
基于层次聚类的角色挖掘根据层次聚类方式的不同又可以分为:
(a)凝聚式的角色挖掘
将权限看作是聚类的对象,通过不断合并距离近的类簇完成对权限的层次聚类,聚类结果为候选的角色。
基本定义
- 类簇Cluster:由权限和持有这些权限的用户组成的二元组c=<rights,members>。
- 用户集合Persons:所有用户组成的集合。
- 类簇集合Clusters:包含所有类簇的聚类结果集。
- 偏序关系集合 < < <:聚类之间的偏序关系构成的集合。
- 无偏序关系类簇集合
T
<
T_<
T<:类簇集合中的类簇,两两间不存在偏序关系。即
T < = c ∈ C l u s t e r s : ∄ d ∈ C l u s t e r s : c < 𝑑 T_<={c∈Clusters: ∄d∈Clusters:c<𝑑} T<=c∈Clusters:∄d∈Clusters:c<d
且对于任意的类簇对 < c , d > ∈ T < <c,d>∈T_< <c,d>∈T<有如下定义:
m e m b e r s ( < c , d > ) = m e m b e r s ( c ) ∩ m e m b e r s ( d ) members(<c,d>)= members(c) ∩members(d) members(<c,d>)=members(c)∩members(d)
r i g h t s ( < c , d > ) = r i g h t s ( c ) ∪ r i g h t s ( d ) rights(<c,d>)= rights(c) ∪rights(d) rights(<c,d>)=rights(c)∪rights(d)
(b)分裂式的角色挖掘
将初始较大的权限集合不断地细分为更小的权限集合,从而形成由权限类簇构成的树。
U:系统中所有用户构成的集合。
P(u):用户u所持有的权限集合。
R(x):由权限集合x构成的角色。
Count(r):与角色r相关联的用户的数量。
intersection(i,j):角色i和 角色j所共有的权限构成的集合。
(c)存在的问题@
基于层次聚类的角色挖掘方法它们是对已有的权限分配数据进行角色挖掘,所以挖掘出的角色定义的质量往往过多地依赖于已有权限分配的质量。而对于大数据应用这种复杂场景来说,已有权限分配的质量往往很难保证。
聚类层次和角色层次在结构上不是一一对应的。凝聚式角色挖掘通常会产生包含大量权限的超级类簇,而分裂式角色挖掘通常会产生许多很小的权限集合,这些集合不一定适合作为有意义的角色。
凝聚式角色挖掘方法得到的类簇是排他的,即某个权限被归入一个类簇后,只能被合并该类簇的父类簇包含,不符合权限的使用规律。
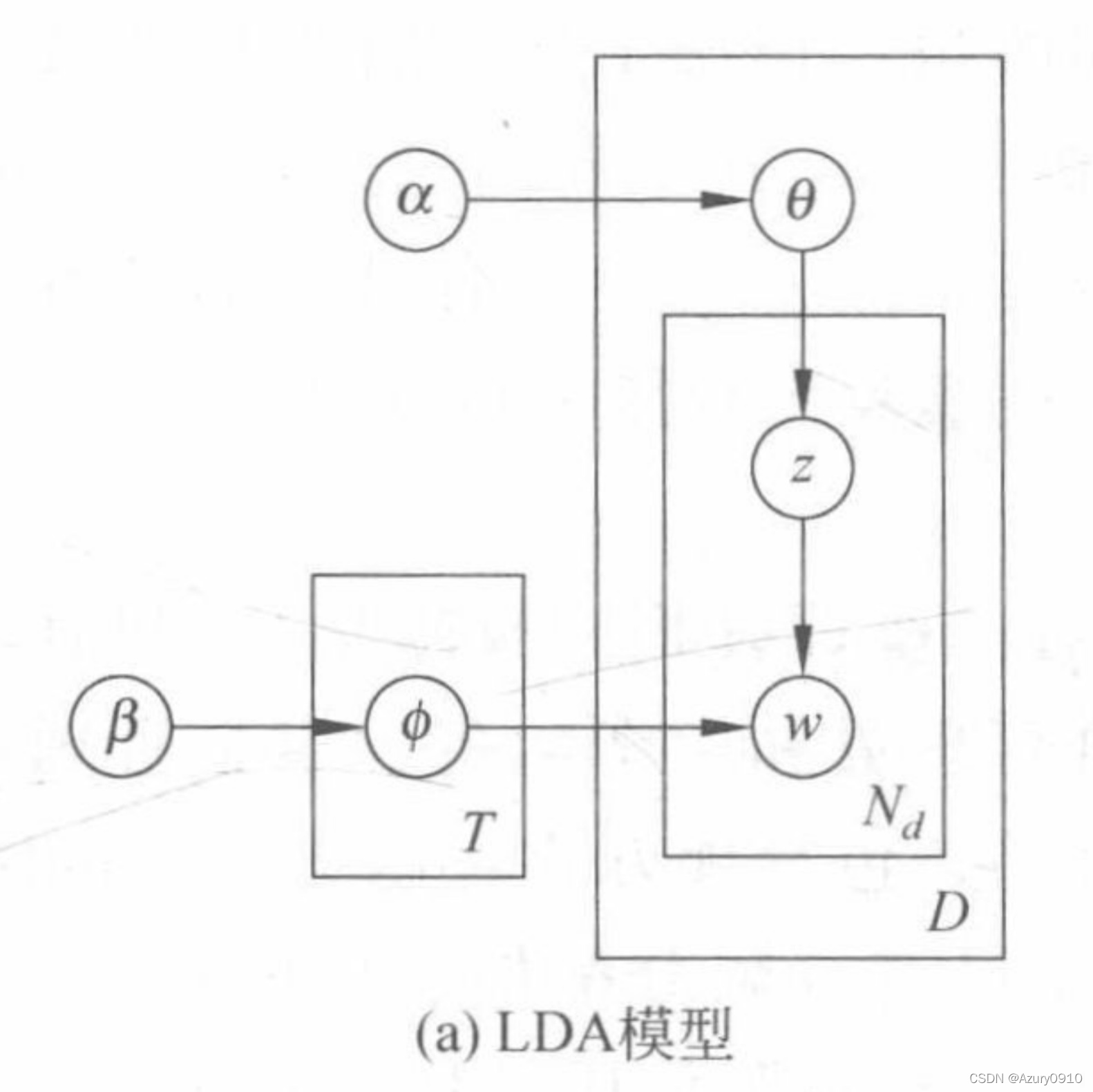
(2)生成式角色挖掘方法:@LDA
LDA模型认为 θ θ θ和 φ φ φ也应该满足一定的概率分布,而不是固定值,因此进一步引入了以 α α α和 β β β为参数的两个狄利克雷分布来完善文档的生成过程:
LDA文本生成过程:
- D i r i c h l e t ( α ) Dirichlet(α) Dirichlet(α)中抽样产生文档 i i i的主题分布 θ 𝑖 \theta_𝑖 θi
- 从文档 i i i的主题分布 θ 𝑖 \theta_𝑖 θi中抽样生成第 j j j个词的主题 z i j z_{ij} zij。
- 从 D i r i c h l e t ( β ) Dirichlet(β) Dirichlet(β)中抽样产生主题 z i j z_{ij} zij的单词分布 φ 𝑧 𝑖 𝑗 \varphi_{𝑧_{𝑖𝑗}} φzij
- 从主题 z i j z_{ij} zij的单词分布 φ 𝑧 𝑖 𝑗 \varphi_{𝑧_{𝑖𝑗}} φzij中抽样产生单词 𝑤 i j 𝑤_{ij} wij。
| 文档生成问题 | 角色挖掘问题 |
|---|---|
| 文档生成问题 | 角色挖掘问题 |
| 包含多个文档的“语料库” | 访问控制日志 |
| 一个文档u | 用户u的权限使用记录 |
| 单词p | 权限p |
| 文档u中单词p的词频n | 用户u对权限p的使用次数n |
| 主题r | 角色r |
将角色挖掘问题映射为文本分析问题,采用两类主题模型LDA和ATM进行生成式角色挖掘,从权限使用情况的历史数据来获得用户的权限使用模式,进而产生角色,并为它赋予合适的权限,同时根据用户属性数据为用户分配恰当的角色。
具体来说,用LDA或ATM方法得到用户(文档)到角色(主题)的映射 θ θ θ以及角色(主题)到权限(单词)的映射 φ φ φ。将 θ θ θ中的概率值按降序排列,找到急剧下降的点,然后将前 k k k个概率值对应的角色赋予用户 u u u,剩下的角色被忽略。类似地,将 φ φ φ中前 m m m个概率值对应的权限赋予角色 r r r,剩下的权限被忽略。
2 风险自适应的访问控制技术[O常见的风险要素]
从风险管理的角度看,访问控制是一种平衡风险和收益的机制。
传统访问控制:风险与收益的平衡被静态定义在访问控制策略中,即“满足策略约束条件的访问行为所带来的风险”被视为系统可接受的风险。这种风险被定义在访问控制策略中,比较适合访问风险十分明确的场景。
而大数据的一大显著特点就是先有数据、后有应用。人们在采集和存储数据的时候,往往无法预先知道所有的数据应用场景,因此安全管理员也往往无法获知访问行为带来的风险和收益的关系,进而难以预先定义恰当的访问控制策略。
基于风险的访问控制:根据访问行为带来的风险,动态地赋予访问权限。风险与收益的平衡是访问过程中动态实施的,而非预先定义在由管理员分析获得并隐含在访问控制策略中。
(1)风险量化
风险量化是将访问行为对系统造成的风险进行数值评估,它是基于风险来实施访问控制的前提。
(a)风险要素选择
风险量化的第一步是确定影响风险值的要素集合。
常见的风险要素:
- 被访问客体敏感程度是客体重要性的体现。敏感度越高的客体,其重要性越高,所以访问它们带来的风险也就越大。
- 被访问客体的数量是指主体在一次访问请求中或一段时间内所访问的客体的规模。访问客体的数量越大,累加的风险也越大。
- 客体之间的互斥关系描述了多次访问行为的风险累加是非线性的。即两个客体存在如下关系:对其中一个客体访问后将不能访问另一客体,或者再访问另一客体时带来的风险会急剧增加。
- 访问主体的安全级别是实施了强制访问控制的系统中对主体访问敏感客体时所能达到的安全性的评估。高安全级别的主体可以访问同级or低安全级别的客体。
- 访问目的与被访问客体的相关性体现了在业务流程中主体对客体的需求程度。两者的相关程度越高,则主体访问客体的风险越小,同时能获得收益也越高。
(b)风险计算方法
在确定了要素风险后,需要进一步根据这些要素来为访问行为计算出量化的风险值。
①基于概率论或模糊理论的静态方式
核心思想是“风险量化值由危害发生的可能性和危害程度决定”,即
Q
u
a
n
t
i
f
i
e
d
R
i
s
k
=
(
P
r
o
b
a
b
i
l
i
t
y
o
f
D
a
m
a
g
e
)
×
(
V
a
l
u
e
o
f
D
a
m
a
g
e
)
Quantified Risk = (Probability of Damage)× (Value of Damage)
QuantifiedRisk=(ProbabilityofDamage)×(ValueofDamage)
风
险
量
化
值
=
危
害
发
生
的
可
能
性
×
危
害
的
值
风险量化值=危害发生的可能性×危害的值
风险量化值=危害发生的可能性×危害的值
其中,危害的值(Value of Damage)是一个对危害程度的量化度量,往往取决于信息资源的价值,只能由企业或组织根据业务背景自行评估。而危害发生的可能性(Probability of Damage)是指引发该危害的事件发生的可能性,通常采用概率论进行计算。
②基于协同过滤的动态方式
基本思想是利用系统中用户的历史访问行为来构建正常用户的访问行为画像,并以此为风险量化的基准,然后计算每次用户访问行为与该基准的偏离程度作为风险量化值。即访问行为偏离基准越大,则该访问产生的风险越大。
其特点是通过行为异常的概率来衡量风险值,所以风险量化结果可以随着系统中整体用户的行为变化而动态变化,相比于静态计算方法更加灵活。然而这种计算往往需要大量的系统历史数据以确保风险量化的准确性。
(2)访问控制实施方案
在对访问行为的风险进行量化之后,还需要进一步利用这些风险值设计灵活的访问控制实施方案。
(a)判定方法
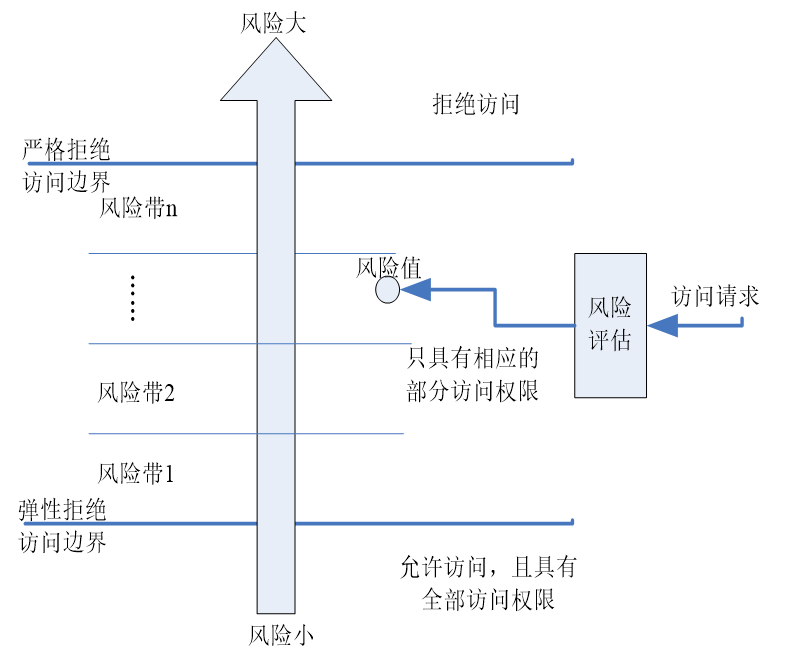
判定结果从“允许/拒绝”的二值向多值发展,引入了部分允许的概念。
(b)风险与收益的平衡
- 信用卡式:它为每个用户分配风险额度,并让用户在访问资源时根据访问带来的风险去消耗额度。当额度不足以支付新的访问时,系统将阻止用户的访问行为。
- 市场交易式:它将风险视为市场上的商品,而整个系统能够容忍的风险被视为可以交易的商品总量。作为商品的风险流通越充分,则越能够实现整体系统的风险与收益的最优化配置。
(c)实施框架
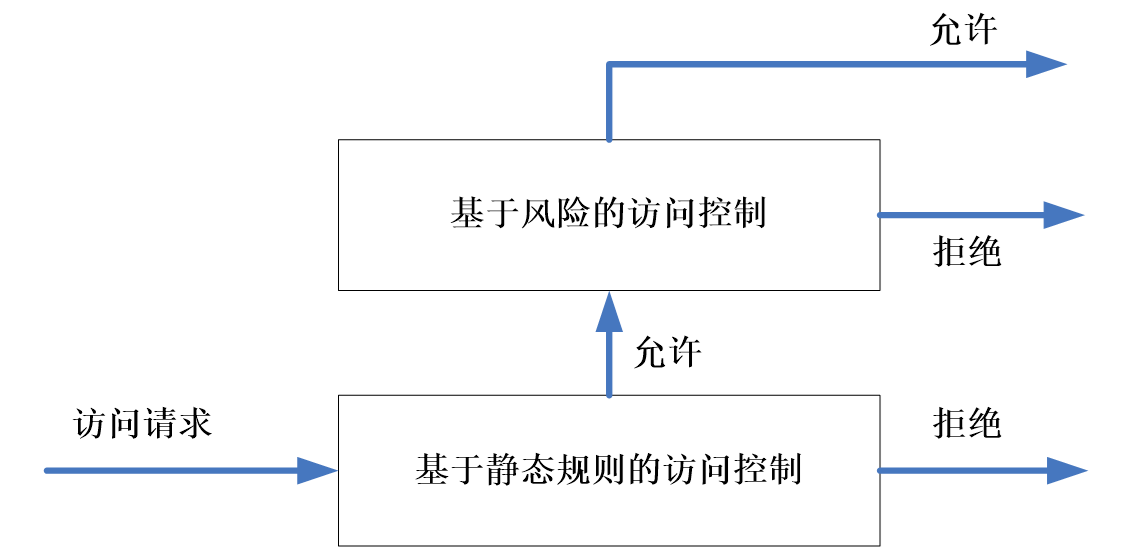
风险访问控制通常采用与传统访问控制结合的实施框架
(三)基于密码学的访问控制技术
1 基于密钥管理的访问控制技术
基于密钥管理的访问控制技术的安全性依赖于密钥的安全性,而无须可信引用监控机的存在。
该技术是通过严格的密钥管理来确保授权用户才能有解密数据所需要的密钥来实现访问控制。根据访问控制系统所支持的能够发送数据的用户数量,可以分为:
- 基于单发送者广播加密的访问控制
- 基于公钥广播加密的访问控制
前者仅支持少量的可信的数据所有者向其他用户分享自己的数据,后者则支持系统内所有用户间的数据分享。
(1)基于单发送者广播加密的访问控制
(a)参与方
- 数据所有者:拥有数据和完整的用户密钥树,负责根据数据分享的目标对象,有选择地从用户密钥树中选取加密密钥对数据进行加密,并将加密结果广播式发送给所有用户。
- 普通用户:拥有用户密钥树中的与自己相关的部分密钥,负责接收数据密文并利用自己持有的密钥解密数据。
(b)用户密钥树
用户密钥树中所有的密钥均为对称密钥。
系统中的每个用户拥有一个自己的密钥 ,作为用户密钥树的叶子节点。
- 数据所有者持有整个用户密钥树。
- 普通用户持有自己的密钥和包含自己在内的用户子集所对应的密钥。
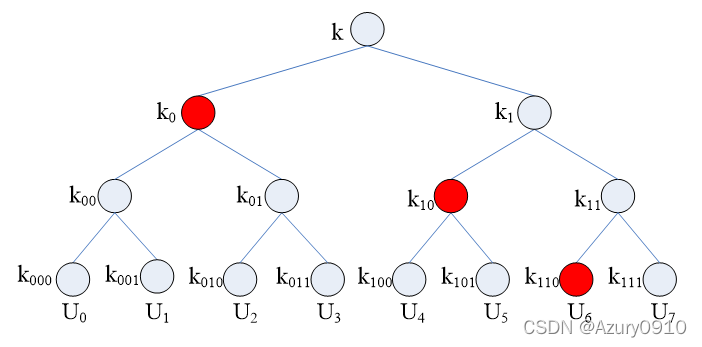
选择红色节点处的密钥集 { k 0 , k 10 , k 110 } \{k_0,k_{10},k_{110}\} {k0,k10,k110}进行数据加密,则未授权的普通用户就是U7,他将无法解密数据。
(2) 基于公钥广播加密的访问控制技术
(a)参与方
- 公钥服务器:负责维护一个采用Complete Subtree、Subset Difference或Layered Subset Difference方法产生的密钥集合。即将系统中的所有用户按照上述三种方案之一划分为子集,每个子集代表了可能的数据接收者集合。为每个子集产生公私钥对,并将私钥安全分发给其包含的用户。
- 数据所有者:负责将数据加密,并采用基于公钥广播加密技术对加密密钥进行分发,以实现对授权接收者的限定。
- 数据服务者:负责加密数据的存储,并向用户提供对数据的操作。
- 用户:是数据的访问者。只有被数据所有者授权的用户才能获得数据的加密密钥,并进一步解密出数据。
由于采用公钥加密方式,所以系统的所有用户都可以是数据所有者,并向其他用户分享数据,消除了单发送者广播加密方案对发送者范围的限制。

(b)数据文件的产生和加密存储@
(1)数据所有者为新产生的数据文件m产生非对称密钥FSK用于对文件m进行签名,对称密钥FEK对文件m 加密。
(2)数据所有者用自己的主加密密钥(非对称)MEK加密FSK私钥和FEK,产生密钥块,并将自己的ID标识在密钥块上 。
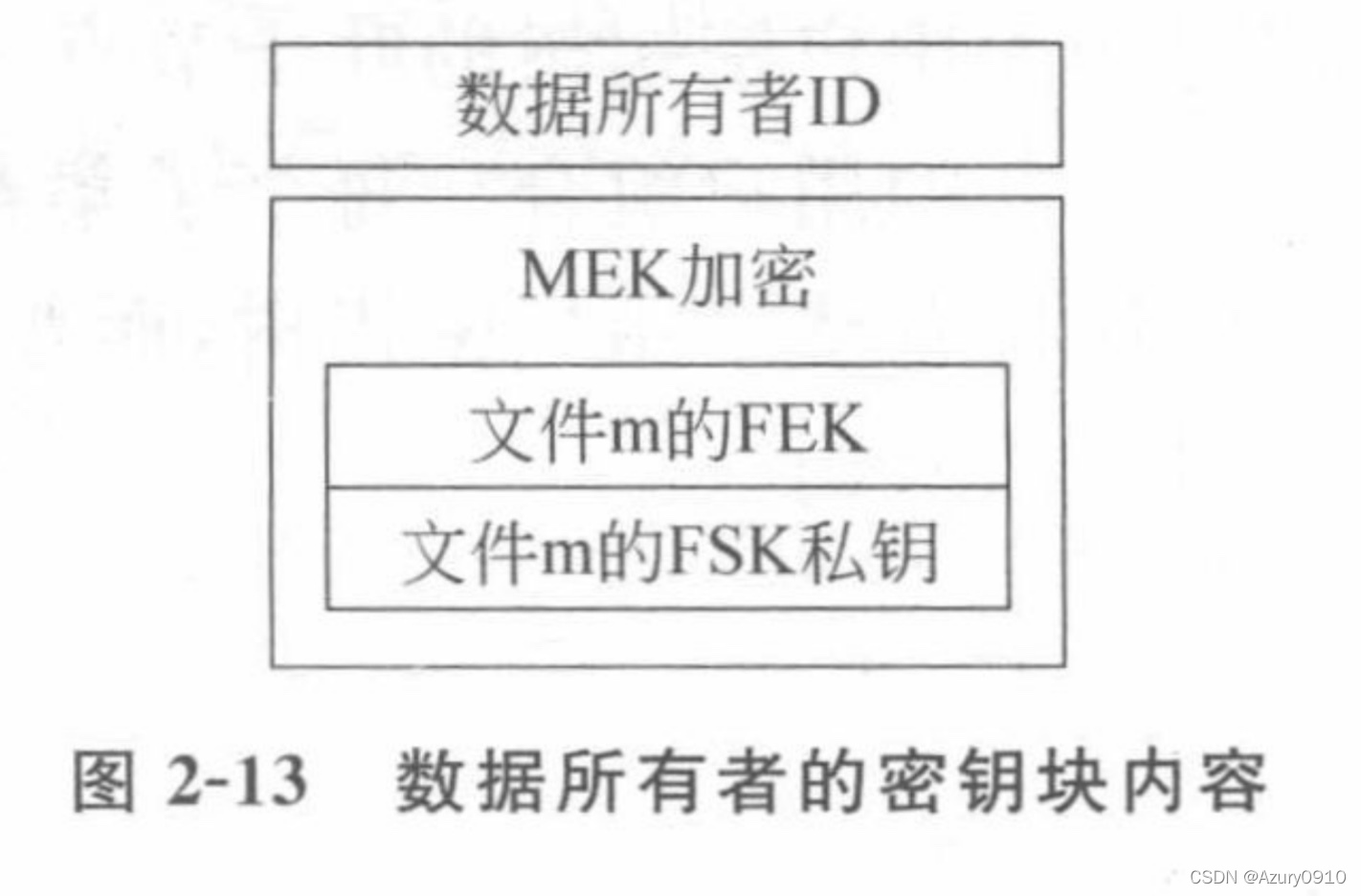
(3)数据所有者对密钥块、FSK公钥、时间戳、文件名进行Hash运算 ,并用自己对主签名密钥MSK(非对称)对Hash值进行签名,产生数据所有者签名块。
(4)数据所有者将密钥块、FSK公钥、时间戳、文件名、数据所有者签名块合并形成元数据md-file。

(5)数据所有者用FEK加密文件m,并用FSK私钥对文件m进行签名,产生加密后的数据文件结构d-file。
(6)数据所有者将md-file和d-file一起发送给数据服务者进行存储。
(c)授权@
(1)数据所有者从数据服务者处根据文件名取回文件m和对应的md-file,并用自己的MSK验证 md-file数据所有者的签名块。
(2)数据所有者从公钥服务器获取用户群组X对应的公钥集合,即用户群组X中的每个用户至少拥有该公钥集合中的一个公钥对应的私钥。数据所有者用公钥集合中的每个公钥对数据文件的FEK进行加密,分别产生一个密钥块,并将公钥的ID标识在密钥块上。若对用户组群X的授权还包含写权限,则将FSK私钥和FEK一起加密 。
这样就实现了读、写权限的分离,即拥有FEK的用户能够读该数据,而拥有FSK私钥的用户能够写该数据。
数据所有者将新产生的这些密钥块都添加到md-file中。
(3)数据所有者更新md-file中的时间戳,并用自己的MSK重新产生数据所有者签名块,然后将新的md-file发送给数据服务者进行存储。
(d)数据文件访问@
(1)用户A从数据服务者处获得文件m的md-file,并从公钥服务器获得数据所有者的MSK来验证md-file的签名以及时间戳。
(2)用户A根据自己持有的公钥ID来查找密钥块,并用该公钥对应的私钥进行解密,以获得该数据对应的FEK(以及FSK的私钥)。
(3)用户A从数据服务者处获得文件m的d-file,用FSK公钥验证签名。
(4)用户A用FEK解密d-file中的加密数据,完成数据的读访问。若密钥块中包含FSK私钥,则用户A能够进一步写 d-file中的数据内容,再重新用FEK加密数据,并用FSK私钥产生新的签名。最后,用户A将更新后的d-file提交给数据服务者进行存储。
2 基于属性加密的访问控制技术[O访问结构、(t,n)门限及实现方法]
在基于密钥管理的访问控制中,系统通过控制用户持有的密钥集合来区分用户,进而实施授权和访问控制。因此数据所有者需要预先知道系统中潜在的授权用户,并获得他们的对称密钥或公钥。这对于规模较大且用户较多的大数据应用来说是不方便的。
基于属性加密的访问控制是通过更加灵活的属性管理来实现访问控制,即将属性集合作为公钥进行数据加密,要求只有满足该属性集合的用户才能解密数据。
(1) 基本定义
(a)访问结构
(访问结构,Access Structure) 令 { P 1 , P 2 , . . . . , P n } \{P1,P2,....,Pn\} {P1,P2,....,Pn}是一个参与者集合。令 A ⊆ 2 { P 1 , P 2 , . . . . , P n } A⊆2^{\{P1,P2,....,Pn\}} A⊆2{P1,P2,....,Pn},若 ∀ B , C ∀B,C ∀B,C,有 B ∈ A B∈A B∈A,且 B ⊆ C B⊆C B⊆C,那么 C ∈ A C∈A C∈A,则称 A A A是单调的。若 A A A是单调的,且是非空的,即 A ⊆ 2 { P 1 , P 2 , . . . . , P n } \ { ∅ } A⊆2^{\{P1,P2,....,Pn\}} \backslash\{∅\} A⊆2{P1,P2,....,Pn}\{∅},则称 A A A为一个访问结构。
A A A中的元素被称为授权集,非 A A A中的元素被称为未授权集。
常见的访问结构主要分为门限结构、访问树结构、LSSS矩阵结构等。目前应用较多的是访问树结构,它可以看作是对单层**(t,n)门限**结构的扩展。
(t,n)门限及实现方法@
(t,n)门限指秘密信息被分成 n n n份,要重构秘密信息就必须获得其中至少 t t t份。
- AND操作可以看作 ( n , n ) (n,n) (n,n)门限
- OR操作可以看作 ( 1 , n ) (1,n) (1,n)门限。
通常可通过插值法够造门限,如拉格朗日插值法。
记要共享的秘密为
s
s
s,随机选取一组
𝑎
𝑖
𝑎_𝑖
ai构造
t
−
1
t-1
t−1次多项式
𝑓
(
𝑥
)
=
𝑠
+
𝑎
1
𝑥
+
𝑎
2
𝑥
2
+
⋯
+
𝑎
𝑡
−
1
𝑥
𝑡
−
1
𝑓(𝑥)=𝑠+𝑎_1 𝑥+𝑎_2𝑥^2+⋯+𝑎_{𝑡−1}𝑥^{𝑡−1}
f(x)=s+a1x+a2x2+⋯+at−1xt−1选择
n
n
n个
𝑥
𝑖
𝑥_𝑖
xi,计算
𝑓
(
𝑥
𝑖
)
𝑓(𝑥_𝑖)
f(xi),并将
(
𝑥
𝑖
,
𝑓
(
𝑥
𝑖
)
)
(𝑥_𝑖, 𝑓(𝑥_𝑖 ))
(xi,f(xi))分发给
n
n
n个不同的参与方
𝑃
𝑖
𝑃_𝑖
Pi。
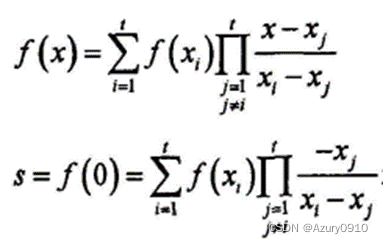
当 n n n个参与方中有 t t t个加入,出示他们的子秘密,得到 t t t个点 ( 𝑥 𝑖 , 𝑓 ( 𝑥 𝑖 ) ) (𝑥_𝑖, 𝑓(𝑥_𝑖 )) (xi,f(xi)),可通过插值法恢复多项式 𝑓 ( 𝑥 ) 𝑓(𝑥) f(x),进而得到秘密 s = 𝑓 ( 0 ) s=𝑓(0) s=f(0)。任意少于 t t t个参与者无法恢复多项式,因而无法获得秘密。
(b)访问结构树
(访问树结构,Access Tree)
T
T
T为一棵访问树,树中的每个节点被记为
x
x
x,该节点的子节点树被记为
𝑛
𝑥
𝑛_𝑥
nx,其对应的门限值被记为
𝑡
𝑥
𝑡_𝑥
tx。每个叶子节点代表一个属性,且
𝑡
𝑥
=
1
𝑡_𝑥=1
tx=1,
𝑛
𝑥
=
0
𝑛_𝑥=0
nx=0。非叶子节点可以通过
𝑛
𝑥
𝑛_𝑥
nx和
𝑡
𝑥
𝑡_𝑥
tx定义属性上的AND、OR或门限关系。
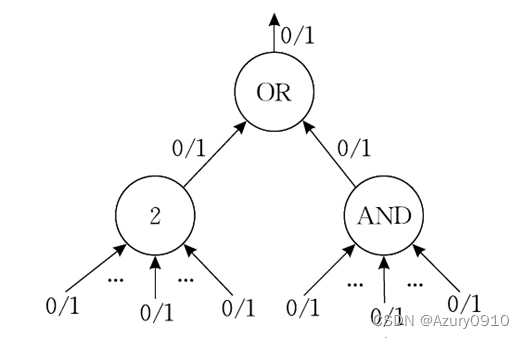
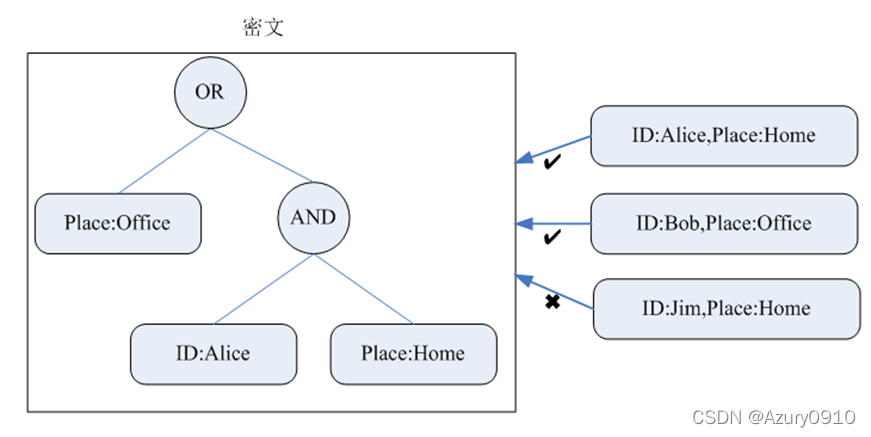
下图表示了一条策略,即 “Place属性为Office,或ID为Alice且Place为Home的用户能够解密数据”
(2) 基于CP-ABE的访问控制
CP-ABE算法(基于属性的访问控制算法),包含以下四个步骤:
(1)Setup:生成主密钥MK和公开参数PK。MK由算法构建者掌握,不允许被泄露,而PK则被发送给系统中的所有参与者。
(2)Encrypt:使用PK、访问结构T将数据明文加密为密文C
(3)KeyGen:使用MK、用户属性值S生成用户的私钥SK
(4)Decrypt:使用私钥解密密文C得到明文M,只有在S满足T的条件下,解密操作才能成功
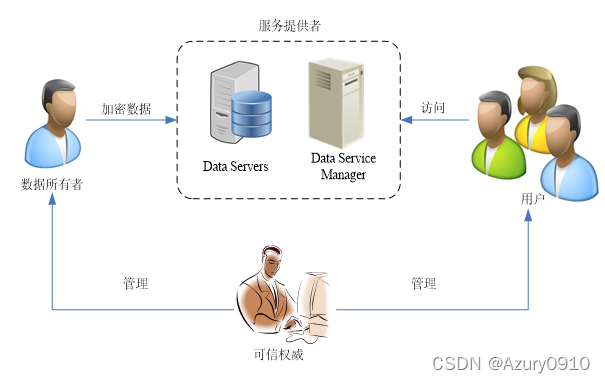
基本访问控制方案的参与方
(1)可信权威:维护了每个用户的属性与密钥的对应关系,为用户发布属性密钥。执行算法的(1)和(3)步,是整个系统中唯一需要被其他参与方完全信任的参与方。
(2)数据所有者:具有数据的所有权,负责访问策略(访问结构T)的定义,并产生与策略绑定的密文数据,然后发送给服务提供者,即算法的第(2)步。
(3)用户:是数据的访问者。若该用户具有满足密文数据所绑定策略中要求的属性,即持有恰当属性密钥,那么就可以解密出数据明文,即算法的第(4)步。
(4)服务提供者:负责提供数据的外包存储。
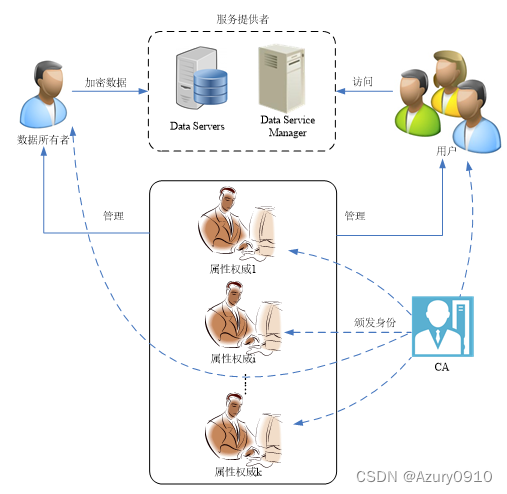
(3) 多属性权威的CP-ABE方案架构
CA:负责为整个系统中所有用户和属性权威颁发和维护身份。
属性权威:负责颁发、撤销和更新用户属性。
数据所有者:具有数据的所有权,产生访问结构来描述授权用户的范围,并采用多权威的属性加密算法对数据加密。
用户:是数据的访问者。如果用户的属性满足访问结构,则用户能够成功解密出数据。
服务提供者:负责提供数据的外包存储。
第三章 安全检索技术
(一) 基本概念
1 背景介绍
云存储是在云计算概念上衍生出来的,其继承了云计算的按需使用、高可扩展性、快速部署等特点,解决了当前政府和企业需要不断增加软硬件设备和数据库管理人员来自主地存储、管理和维护海量数据的问题。由于云存储使得数据的所有权和管理权相分离,用户数据将面临多方面的安全威胁:
- 美国政府雇员窃取社保信息;
- 前支付宝员工以500元售出5万条支付宝用户数据;
- 2014年至2017年,多起icloud好莱坞明星隐私泄露事件;
- 著名的美国国家安全局的“棱镜”项目
为保证云数据的安全性,一种通用的方法是用户首先使用安全的加密机制对数据进行加密,然后再将密文数据上传至云服务器。由于只有用户知道解密密钥,而云存储服务提供商得到的信息是完全随机化的,数据的安全性完全掌握在用户手中。当用户需要对数据进行检索时,只能把全部密文下载到本地,将其解密后再查询。这个过程要求客户端具有较大的存储空间以及较强的计算能力,且没有充分发挥云存储的优势。
密文检索(Searchable Encryption,SE,叫做可搜索加密)技术支持云存储系统在密文场景下对用户数据进行检索,然后将满足检索条件的密文数据返回给用户。在检索过程中,云服务器无法获得用户的敏感数据和查询条件,即密文检索可以同时保护数据机密性以及查询机密性。
2 密文检索概述
(1) 系统模型
密文检索主要涉及数据所有者、数据检索者以及服务器 3种角色。
- 数据所有者是敏感数据的拥有者;数据检索者是查询请求的发起者
这二者通常仅具备有限的存储空间和计算能力; - 服务器为所有者和检索者提供数据存储和数据查询服务,其由云存储服务提供商进行管理和维护,并具有强大的存储能力和计算能力。
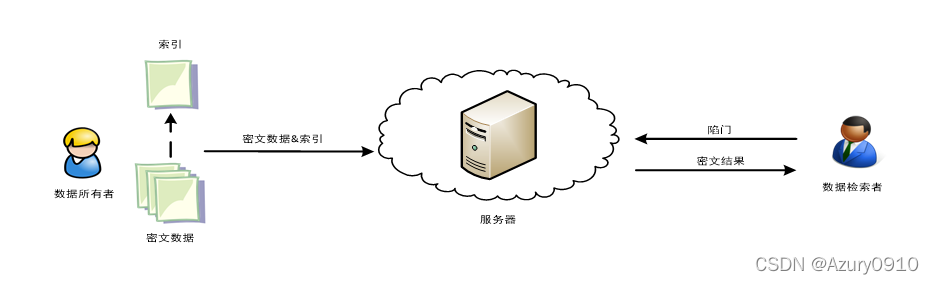
(2) 系统流程
① 数据所有者首先为数据构造支持检索功能的索引,同时使用传统的加密技术加密全部数据,然后将密文数据和索引共同存储到服务器。
② 需要检索时,数据检索者为检索条件生成相应的陷门,并发送给服务器。
③ 服务器使用索引和陷门进行协议预设的运算,并将满足检索条件的密文数据返回给数据检索者。
④ 数据检索者使用密钥将检索结果解密,得到明文数据。
有时服务器返回的密文数据中可能包含不满足检索条件的冗余数据,此时数据检索者还需要对解密后的明文数据进行二次检索,即在本地剔除冗余数据。
(3) 安全模型
通常认为数据所有者和数据检索者是完全可信的,而服务器属于攻击者,其对用户的敏感数据和检索条件比较好奇。目前大部分密文检索方案均假设服务器是诚实但好奇的(Honest-but-Curious,HBC),即服务器会忠实地执行数据检索者提交的检索请求,并返回相应的检索结果,同时其可能会利用自己所掌握的一切背景知识来进行分析,期望获得真实的敏感数据和检索条件。
3 密文检索分类
根据应用场景的不同,密文检索技术可以分为对称密文检索(Symmetric Searable Encrption, SSE)和非对称密文检索(Asymmetric Searable Encrption,ASE)两大类:
- 对称密文检索:在对称密钥环境下,只有数据所有者拥有密钥,也只有数据所有者可以提交敏感数据、生成陷门,即数据所有者和数据检索者为同一人。
- 非对称密文检索:在非对称密钥环境下,任何可以获得数据检索者公钥的用户都可以提交敏感数据,但只有拥有私钥的数据检索者可以生成陷门。
根据检索的数据类型的不同,密文检索技术可以分为关键词检索和区间检索两大类:
- 关键词检索:主要用于检索字符型数据,如查询包含关键词“云存储”的文档。最初,关键词检索的研究以单关键词检索为主,后来逐渐扩展到多关键词检索、模糊检索以及Top-k检索。
- 区间检索:主要用于对数值型数据进行范围查询,如查询学生信息表中年龄属性小于18的学生。根据属性的数目,区间检索又可进一步分为单维区间检索和多维区间检索。
(二)早期安全检索技术
1 PIR技术 @定义3-1
PIR(Private Information Retrieval,隐私信息检索)技术的研究主要针对公开数据库,其目标是允许用户在不向服务器暴露查询意图的前提下,对服务器中的数据进行查询并取得指定内容。
保护查询意图:专利
根据服务器的数目以及用户与服务器之间的交互轮数的不同,可将PIR技术分为4大类:单服务器的、多服务器的、单轮交互的以及多轮交互的。目前主要研究的是单轮交互的PIR问题。
定义3-1 (单轮交互的PIR问题)@
设存在
𝑘
≥
1
𝑘≥1
k≥1个服务器,其存储的内容完全相同,均为
𝑛
𝑛
n个比特的信息
𝑋
=
{
𝑥
1
,
𝑥
2
,
…
,
𝑥
𝑛
}
𝑋=\{𝑥_1,𝑥_2,…,𝑥_𝑛\}
X={x1,x2,…,xn},且服务器之间不会进行相互通信。
A
A
A希望对服务器中的数据进行查询,并得到
𝑥
𝑖
𝑥_𝑖
xi ,其具体查询过程如下:
- A A A生成一个随机数 𝑟 𝑟 r,并根据 𝑟 𝑟 r和 𝑖 𝑖 i生成 𝑘 𝑘 k个查询 { 𝑞 1 , 𝑞 2 , … , 𝑞 𝑘 } \{𝑞_1,𝑞_2,…,𝑞_𝑘\} {q1,q2,…,qk},然后将其分别发送给𝑘个服务器;
- 各服务器分别返回相应的查询结果: { 𝐴 𝑛 𝑠 ( 𝑞 1 ) , … , 𝐴 𝑛 𝑠 ( 𝑞 𝑘 ) } \{𝐴𝑛𝑠(𝑞_1),…,𝐴𝑛𝑠(𝑞_𝑘)\} {Ans(q1),…,Ans(qk)};
- A A A根据 𝑟 𝑟 r和 { 𝐴 𝑛 𝑠 ( 𝑞 1 ) , … , 𝐴 𝑛 𝑠 ( 𝑞 𝑘 ) } \{𝐴𝑛𝑠(𝑞_1),…,𝐴𝑛𝑠(𝑞_𝑘)\} {Ans(q1),…,Ans(qk)}计算得到正确的 𝑥 𝑖 𝑥_𝑖 xi 。
如果在上述查询过程中,任意服务器均不了解关于
𝑖
𝑖
i的任何信息,则称这一交互是PIR的。换句话说,如果
A
A
A进行了两次查询,分别访问了
𝑥
𝑖
𝑥_𝑖
xi和
𝑥
𝑖
′
𝑥_𝑖′
xi′ ,则服务器𝑗对这两次查询所见的视图在概率分布上没有区别,即
P
r
[
V
i
e
w
j
(
X
,
i
)
=
V
i
e
w
]
=
P
r
[
V
i
e
w
j
(
X
,
i
′
)
=
V
i
e
w
]
Pr[View_j(X,i)=View]=Pr[View_j(X,i^{'})=View]
Pr[Viewj(X,i)=View]=Pr[Viewj(X,i′)=View]
2 PIRK技术以及SPIR技术
(1) PIRK技术 不简答
PIR方案假设数据是二进制的,且客户端已经了解待获取的数据在数据集中的位置。但是在实际检索场景中,客户端一般都是输入一个感兴趣的关键词,然后服务器根据该关键词找到对应的数据内容。为此,提出了PIRK(Private Information Retrieval by Keywords)技术。
定义3-3 (PIRK问题)
设存在
𝑘
𝑘
k个服务器,其存储的内容完全相同,均为
𝑛
𝑛
n个长度为
𝑙
𝑙
l的字符串
𝑆
=
{
𝑠
1
,
𝑠
2
,
…
,
𝑠
𝑛
}
𝑆=\{𝑠_1,𝑠_2,…,𝑠_𝑛\}
S={s1,s2,…,sn},且服务器之间不会进行相互通信。
A
A
A感兴趣的关键词是一个长度为𝑙的字符串
𝑤
𝑤
w。
如果存在一个协议使A能够得到所有满足
𝑠
𝑗
=
𝑤
𝑠_𝑗=𝑤
sj=w的
𝑗
𝑗
j,且任意服务器均不了解关于
𝑤
𝑤
w的任何信息,则称该协议是
𝑃
𝐼
𝑅
𝐾
(
𝑙
,
𝑛
,
𝑘
)
𝑃𝐼𝑅𝐾(𝑙,𝑛,𝑘)
PIRK(l,n,k)的。
需要注意的是,此定义只包含了找到
𝑠
𝑗
=
𝑤
𝑠_𝑗=𝑤
sj=w的过程,至于找到
𝑠
𝑗
𝑠_𝑗
sj之后如何获取
𝑠
𝑗
𝑠_𝑗
sj对应的数据内容,则可以通过运行一般的PIR协议来完成。
(2) SPIR技术
(a) SPIR问题 @
从服务器的角度来看,PIR技术仅保护了客户端的查询意图,而对服务器中的数据集缺乏保护。因此,由PIR技术进一步发展至SPIR(Symmetric Private Information Retrieval)技术,其目标是将保护范围扩大到服务器。
SPIR问题与PIR问题相似,但是在其基础上增加了一项要求:
A
A
A不了解
𝑥
𝑖
𝑥_𝑖
xi之外的任何信息。换句话说,如果存在两个数据源
𝑋
=
{
𝑥
1
,
𝑥
2
,
…
,
𝑥
𝑛
}
𝑋=\{𝑥_1,𝑥_2,…,𝑥_𝑛\}
X={x1,x2,…,xn}和
𝑌
=
{
𝑦
1
,
𝑦
2
,
…
,
𝑦
𝑛
}
𝑌=\{𝑦_1,𝑦_2,…,𝑦_𝑛\}
Y={y1,y2,…,yn},且
𝑥
𝑖
=
𝑦
𝑖
𝑥_𝑖=𝑦_𝑖
xi=yi。则对于这两个数据源,
A
A
A查询第
𝑖
𝑖
i份数据,所见的视图应当没有任何区别,即
P
r
[
V
i
e
w
A
(
X
,
i
)
=
v
i
e
w
]
=
P
r
[
V
i
e
w
A
(
Y
,
i
)
=
v
i
e
w
]
Pr[View_A(X,i)=view]=Pr[View_A(Y,i)=view]
Pr[ViewA(X,i)=view]=Pr[ViewA(Y,i)=view]
任意
N
N
N服务器的PIR方法都可以转换为
N
+
1
N+1
N+1服务器、同样数量级复杂度的SPIR方法。
(b) SPIR技术 @
Bob有n个秘密 { m 1 , m 2 , . . . , m n } \{m_1,m_2,...,m_n\} {m1,m2,...,mn} ,Alice想获得其中的1个,但是Bob不知道Alice获取的是哪一个,同时Alice也不知道Bob剩下的 n − 1 n-1 n−1个秘密中的任何一个。Alice和Bob共享数 g g g和 h h h。
- Alice私有随机数r,并计算 y = g r h α y=g^{r} h^{α} y=grhα,将y传给Bob
- Bob私有随机数 { k 1 , k 2 , . . . , k n } \{k_1,k_2,...,k_n\} {k1,k2,...,kn},计算 B i = y / h i B_i=y/h^i Bi=y/hi,将 c i = ( g k i , m i B k i ) , 𝑖 = 1 , ⋯ , n c_i=(g^{k_i},m_i B^{k_i}), 𝑖=1, ⋯ , n ci=(gki,miBki),i=1,⋯,n 传给Alice
- Alice计算得到 m α = b / a r m_α=b/a^{r} mα=b/ar,其中 b = m α B k α , a = g k α b = m_α B^{k_α}, a=g^{k_α} b=mαBkα,a=gkα
SPIR技术要求保护客户端查询意图不被服务器知道的同时,也对服务器中的数据集加以保护,使得客户端无法了解所查询信息以外的任何信息。
- 客户端生成私有随机数r,并计算 y = g r h α y=g^{r} h^{α} y=grhα,将y传给服务器
- 服务器生成私有随机数 { k 1 , k 2 , . . . , k n } \{k_1,k_2,...,k_n\} {k1,k2,...,kn},计算 B i = y / h i B_i=y/h^i Bi=y/hi,将 c i = ( g k i , m i B k i ) , 𝑖 = 1 , ⋯ , n c_i=(g^{k_i},m_i B^{k_i}), 𝑖=1, ⋯ , n ci=(gki,miBki),i=1,⋯,n 传给客户端
- 客户端计算得到 m α = b / a r m_α=b/a^{r} mα=b/ar,其中 b = m α B k α , a = g k α b = m_α B^{k_α}, a=g^{k_α} b=mαBkα,a=gkα
3 ORAM技术 不简答
ORAM技术的目标是在读写过程中向服务器隐藏用户的访问模式。这里,访问模式是指客户端向服务器发起访问所泄露的信息,包括操作是读还是写、操作的数据地址、操作的数据内容等。与PIR的不同之处在于,PIR只考虑保护客户端的查询意图;而ORAM保护的内容更为广泛。
定义3-4 (ORAM系统)
- 用户的输入序列 𝑌 𝑌 Y:定义为一组输入 ( o 1 , o 2 , … , o n ) (o_1,o_2,…,o_n) (o1,o2,…,on)。
- 用户的输入
o
o
o:代表用户的操作类型、操作数据内容、操作地址
o
=
(
o
p
,
d
a
t
a
,
i
)
o=(op,data,i)
o=(op,data,i)。
- 当 o p op op是读时 o p = r e a d op=read op=read, d a t a = ∅ data=∅ data=∅;
- 当 o p op op是写时 o p = w r i t e op=write op=write, d a t a data data是用户写入的明文内容。
- 访问模式
A
(
Y
)
A(Y)
A(Y):对于用户发起的一个输入序列
Y
=
(
o
1
,
o
2
,
…
,
o
n
)
,
Y=(o_1,o_2,…,o_n),
Y=(o1,o2,…,on),假设经过翻译后,在服务器实际实施的序列为
Y
=
(
O
1
,
O
2
,
…
,
O
m
)
Y=(O_1,O_2,…,O_m)
Y=(O1,O2,…,Om)。
A
(
Y
)
A(Y)
A(Y)记录了
Y
Y
Y中各输入的访问地址
i
i
i,以及
Y
Y
Y是读还是写。
- 当操作是写时, A ( Y ) A(Y) A(Y)还记录了用户希望服务器写入的内容。具体地, A ( Y ) = ( ( o p 1 , E d a t a 1 , i 1 ) , … , ( o p m , E d a t a m , i m ) ) A(Y)=((op_1,Edata_1,i_1 ),…,(op_m,Edata_m,i_m)) A(Y)=((op1,Edata1,i1),…,(opm,Edatam,im)),其中 E d a t a Edata Edata是从服务器的角度写入的密文内容。
- 当操作是读时, E d a t a = ∅ Edata=∅ Edata=∅。
如果对于系统中任意两个输入序列 Y Y Y和 Y ′ Y^{′} Y′,从服务器的角度来看,访问模式 A ( Y ) A(Y) A(Y)和 A ( Y ′ ) A(Y^{′}) A(Y′)是不可区分的,则认为这个系统是一个ORAM系统。
其基本解决思想是:设计一种转换协议,将1次访问转换为k次访问,从而保证两组访问经过转换之后无法区分
(三)对称密文检索
在对称密文检索方案中,数据所有者和数据检索者为同一方。该场景适用于大部分第三方存储,也是近几年本领域的研究热点。一个典型的对称密文检索方案包括如下算法:
- Setup算法:该算法由数据所有者执行,生成用于加密数据和索引的密钥;
- BuildIndex算法:该算法由数据所有者执行,根据数据内容建立索引,并将加密后的索引和数据本身上传到服务器;
- GenTrapdoor算法:该算法由数据所有者执行,根据检索条件生成相应的陷门(又称“搜索凭证”),然后将其发送给服务器;
- Search算法:该算法由服务器执行,将接收到的陷门和本地存储的密文索引作为输入,并进行协议所预设的计算,最后输出满足条件的密文结果。
对称密文检索的核心与基础部分是单关键词检索。目前,SSE可以根据检索机制的不同大致分为三大类:
- 基于全文扫描的方法
- 基于文档-关键词索引的方法
- 基于关键词-文档索引的方法
1 基于全文扫描的方案 O ( n s ) O(ns) O(ns)@
- n:服务器上存储的文件数目
- s:文件平均长度
异或运算:a、b两个值不同时,异或结果为1;否则为0
异或性质:
(
a
⊕
b
)
⊕
a
=
b
(a⊕b)⊕a=b
(a⊕b)⊕a=b
该方案的核心思想是对文档进行分组加密,然后将分组加密结果与一个伪随机流进行异或得到最终用于检索的密文。检索时,用户将检索关键词对应的陷门发送给服务器,服务器对所有密文依次使用陷门计算密文是否满足预设的条件,若满足则返回该文档。
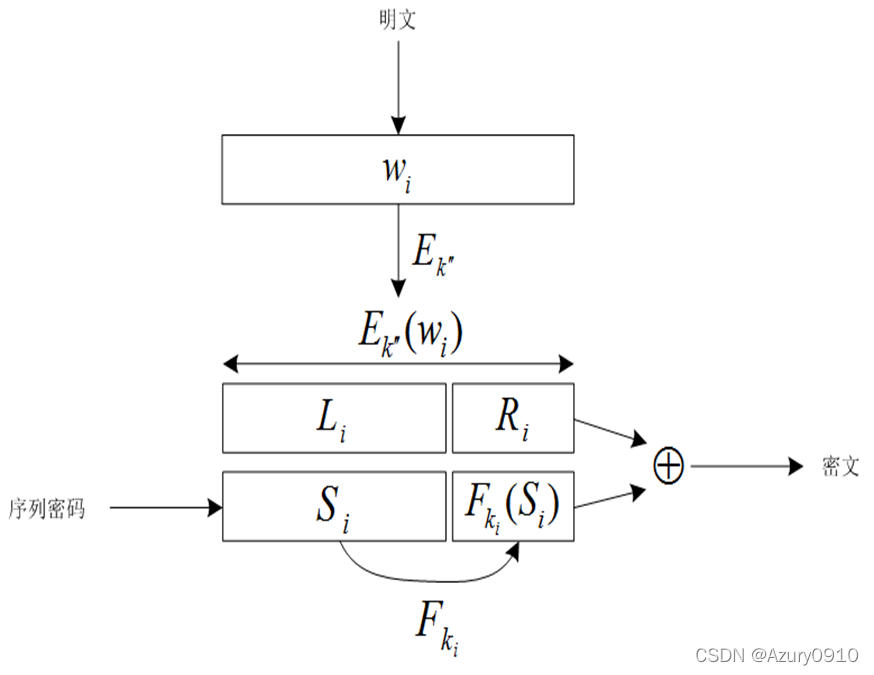

- Setup算法:数据所有者生成密钥 𝑘 ′ , 𝑘 ′ ′ 𝑘^{′},𝑘^{′′} k′,k′′,伪随机数 𝑆 1 , 𝑆 2 , … , 𝑆 𝑙 𝑆_1,𝑆_2,…,𝑆_𝑙 S1,S2,…,Sl,伪随机置换𝐸以及伪随机函数 𝐹 𝐹 F, 𝑓 𝑓 f;
- BuildIndex算法:假设文档的内容为关键词序列
𝑤
1
,
𝑤
2
,
…
,
𝑤
𝑙
𝑤_1,𝑤_2,…,𝑤_𝑙
w1,w2,…,wl。
对于关键词 𝑤 𝑖 𝑤_𝑖 wi,数据所有者首先将其加密得到 𝐸 𝑘 ′ ′ ( 𝑤 𝑖 ) 𝐸_{𝑘^{′′}} (𝑤_𝑖) Ek′′(wi),并将 𝐸 𝑘 ′ ′ ( 𝑤 𝑖 ) 𝐸_{𝑘^{′′}}(𝑤_𝑖) Ek′′(wi)拆分为 𝐿 𝑖 𝐿_𝑖 Li和 𝑅 𝑖 𝑅_𝑖 Ri两个部分;
然后,使用伪随机数 𝑆 𝑖 𝑆_𝑖 Si计算 𝐹 𝑘 𝑖 ( 𝑆 𝑖 ) 𝐹_{𝑘_𝑖 }(𝑆_𝑖) Fki(Si),其中 𝑘 𝑖 = 𝑓 𝑘 ′ ( 𝐿 𝑖 ) 𝑘_𝑖=𝑓_{𝑘^{′}} (𝐿_𝑖) ki=fk′(Li);
最后,将 ( 𝑆 𝑖 , 𝐹 𝑘 𝑖 ( 𝑆 𝑖 ) ) (𝑆_𝑖,𝐹_{𝑘_𝑖 } (𝑆_𝑖)) (Si,Fki(Si))与 ( 𝐿 𝑖 , 𝑅 𝑖 ) (𝐿_𝑖,𝑅_𝑖) (Li,Ri)经过异或运算生成密文块 𝐶 𝑖 𝐶_𝑖 Ci ; - GenTrapdoor算法:当需要搜索关键词 𝑤 𝑤 w时,数据所有者将 𝐸 𝑘 ′ ′ ( 𝑤 ) = ( 𝐿 , 𝑅 ) 𝐸_{𝑘^{′′}} (𝑤)=(𝐿,𝑅) Ek′′(w)=(L,R)以及 𝑘 = 𝑓 𝑘 ′ ( 𝐿 ) 𝑘=𝑓_{𝑘^{′}}(𝐿) k=fk′(L)发送给服务器;
- Search算法:服务器依次将密文 𝐶 𝑖 𝐶_𝑖 Ci与 𝐸 𝑘 ′ ′ ( 𝑤 ) 𝐸_{𝑘^{′′}}(𝑤) Ek′′(w)进行异或运算,然后判断得到的结果是否满足 ( 𝑆 , 𝐹 𝑘 ( 𝑆 ) ) (𝑆,𝐹_{𝑘} (𝑆)) (S,Fk(S))的形式。如果满足,则说明匹配成功,并将该文档返回。
基于全文扫描的方案需要对每个密文块进行扫描并计算,在最坏的情况下,检索一篇文档的时间与该文档的长度呈线性关系,检索效率较低。
目前,人们主要集中于研究基于文档-关键词索引和基于关键词-文档索引的密文关键词检索方案,其将索引从密文中独立出来,即数据本身可以采用任意加密算法加密,检索功能由索引实现。
2 基于文档-关键词索引的方案 O ( n ) O(n) O(n)@

基于文档-关键词索引的方案的核心思路是为每篇文档建立单独的索引,且服务器在检索时需要遍历全部索引,因此,这类方案的检索时间复杂度与文档数目成正比。
(key,value)
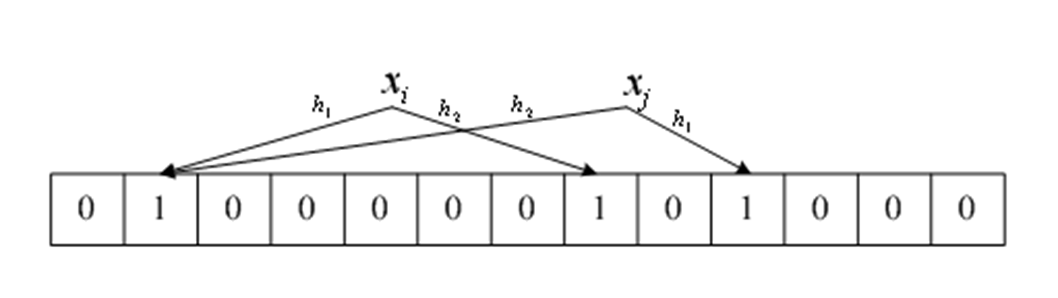
布隆过滤器利用位数组表示集合,并可以快速判断一个元素是否属于该集合。记位数组的长度为
𝑚
𝑚
m,集合为
𝑆
=
𝑥
1
,
…
,
𝑥
𝑛
𝑆={𝑥_1,…,𝑥_𝑛}
S=x1,…,xn 。
首先,构造各位置均为0的初始数组
B
F
BF
BF,并选取
𝑘
𝑘
k个Hash函数
h
1
,
…
,
h
𝑘
ℎ_1,…,ℎ_𝑘
h1,…,hk,这些Hash函数可以将集合中的元素映射到位数组中的某一位。
然后对于各元素
𝑥
𝑖
𝑥_𝑖
xi,为其计算
𝑘
𝑘
k个Hash值
h
1
(
𝑥
𝑖
)
,
…
,
h
𝑘
(
𝑥
𝑖
)
ℎ_1 (𝑥_𝑖),…,ℎ_𝑘 (𝑥_𝑖)
h1(xi),…,hk(xi),并将位数组中的相应位置设为1。
当想要判断元素
𝑦
𝑦
y是否属于集合
𝑆
𝑆
S时,我们同样使用Hash函数
h
1
,
…
,
h
𝑘
ℎ_1,…,ℎ_𝑘
h1,…,hk为其计算
𝑘
𝑘
k个值
h
1
(
𝑦
)
,
…
,
h
𝑘
(
𝑦
)
ℎ_1 (𝑦),…,ℎ_𝑘 (𝑦)
h1(y),…,hk(y),**如果位数组
B
F
BF
BF中的相应位置均为1,我们则认为
𝑦
𝑦
y是
𝑆
𝑆
S中的元素。**但实际上,由于Hash函数的计算结果可能存在冲突,
𝑦
𝑦
y有可能并不属于
𝑆
𝑆
S。
如下图所示的例子,如果
h
1
(
𝑦
)
=
h
2
(
𝑥
𝑖
)
ℎ_1 (𝑦)=ℎ_2 (𝑥_𝑖)
h1(y)=h2(xi)且
h
2
(
𝑦
)
=
h
1
(
𝑥
𝑗
)
ℎ_2 (𝑦)=ℎ_1(𝑥_𝑗)
h2(y)=h1(xj),则会发生误判。
借助于布隆过滤器,人们提出了一种基于文档-关键词索引地秘闻关键词检索方案
使用布隆过滤器为每篇文档分别构造索引,并使用伪随机函数为每个关键词计算两遍伪随机数,其一将关键词作为输入,其二将文档标识作为输入,从而同一关键词在不同文档中的计算结果不一致。
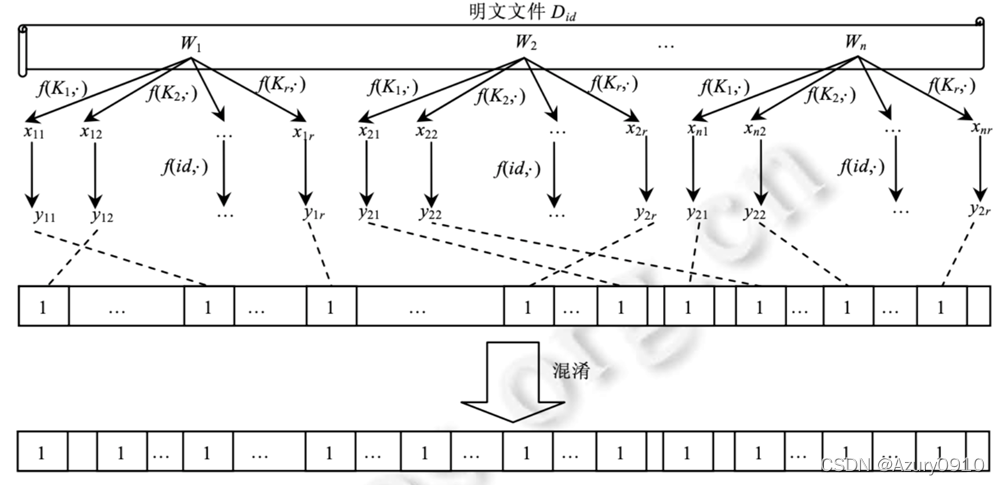
上述方案在检索判定时只需要计算若干次伪随机数,速度比基于全文扫描的方法提高很多。然而,由于布隆过滤器的特性,会有一定的概率返回不包含查询关键词的文档。
- Setup算法:数据所有者生成 𝑟 𝑟 r个密钥 𝑘 1 , … , 𝑘 𝑟 𝑘_1,…,𝑘_𝑟 k1,…,kr以及伪随机函数 𝑓 𝑓 f;
- BuildIndex算法:对于包含
𝑡
𝑡
t个关键词
𝑤
1
,
…
,
𝑤
𝑡
𝑤_1,…,𝑤_𝑡
w1,…,wt的文档
D
D
D,数据所有者首先为其生成一个位数组
B
F
(
D
)
BF(D)
BF(D),并置
B
F
(
D
)
BF(D)
BF(D)所有位均为0。然后,对于每个关键词
𝑤
𝑖
𝑤_𝑖
wi:
- 以关键词 𝑤 𝑖 𝑤_𝑖 wi作为输入计算 𝑟 𝑟 r个值: 𝑥 1 = 𝑓 ( 𝑤 𝑖 , 𝑘 1 ) , … , 𝑥 𝑟 = 𝑓 ( 𝑤 𝑖 , 𝑘 𝑟 ) 𝑥_1=𝑓(𝑤_𝑖,𝑘_1 ),…,𝑥_𝑟=𝑓(𝑤_𝑖,𝑘_𝑟 ) x1=f(wi,k1),…,xr=f(wi,kr);
- 以文档标识 i d id id作为输入计算 𝑟 𝑟 r个值: 𝑦 1 = 𝑓 ( 𝑖 𝑑 , 𝑥 1 ) , … , 𝑦 𝑟 = 𝑓 ( 𝑖 𝑑 , 𝑥 𝑟 ) 𝑦_1=𝑓(𝑖𝑑,𝑥_1 ),…,𝑦_𝑟=𝑓(𝑖𝑑,𝑥_𝑟 ) y1=f(id,x1),…,yr=f(id,xr);
- 将 B F ( D ) BF(D) BF(D)中 𝑦 1 , … , 𝑦 𝑟 𝑦_1,…,𝑦_𝑟 y1,…,yr这 𝑟 𝑟 r个值对应的位置设为1,并对 B F ( D ) BF(D) BF(D)进行随机填充;
- GenTrapdoor算法:数据所有者为检索关键词 𝑤 𝑤 w计算 𝑟 𝑟 r个值: 𝑥 1 ′ = 𝑓 ( 𝑤 , 𝑘 1 ) , … , 𝑥 𝑟 ′ = 𝑓 ( 𝑤 , 𝑘 𝑟 ) 𝑥^{′}_1=𝑓(𝑤,𝑘_1 ),…,𝑥^{′}_𝑟=𝑓(𝑤,𝑘_𝑟 ) x1′=f(w,k1),…,xr′=f(w,kr),然后将这 𝑟 𝑟 r个值发送给服务器;
- Search算法:根据陷门,服务器为文档 D D D计算 𝑟 𝑟 r个值 𝑦 1 ′ = 𝑓 ( i d , 𝑥 1 ′ ) , … , 𝑦 r ′ = 𝑓 ( 𝑖 𝑑 , 𝑥 r ′ ) 𝑦_{1}^{′}=𝑓(id,𝑥^{′}_1),…,{𝑦^{′}_r}=𝑓(𝑖𝑑,𝑥^{′}_r) y1′=f(id,x1′),…,yr′=f(id,xr′),并检查 D D D对应的索引 B F ( D BF(D BF(D)中,这 𝑟 𝑟 r个值对应的位置是否都为1。若是,则说明文档 D D D包含 w w w ,并将其返回给用户。
3 基于关键词-文档索引的方案 O ( 1 ) O(1) O(1) 不简答
在基于文档-关键词索引的方案中,查询效率与文档数目呈线性关系,导致这类方案难以应用于大数据场景。为此,提出了基于关键词-文档索引的方案。
此类方案在初始化时为每个关键词生成包含该关键词的文档标识集合,然后加密存储这些索引结构。基于关键词-文档索引的方案不需要逐个检索每篇文档,其检索时间复杂度仅与返回的结果数目呈线性关系,因此查询效率远高于前两类方案。
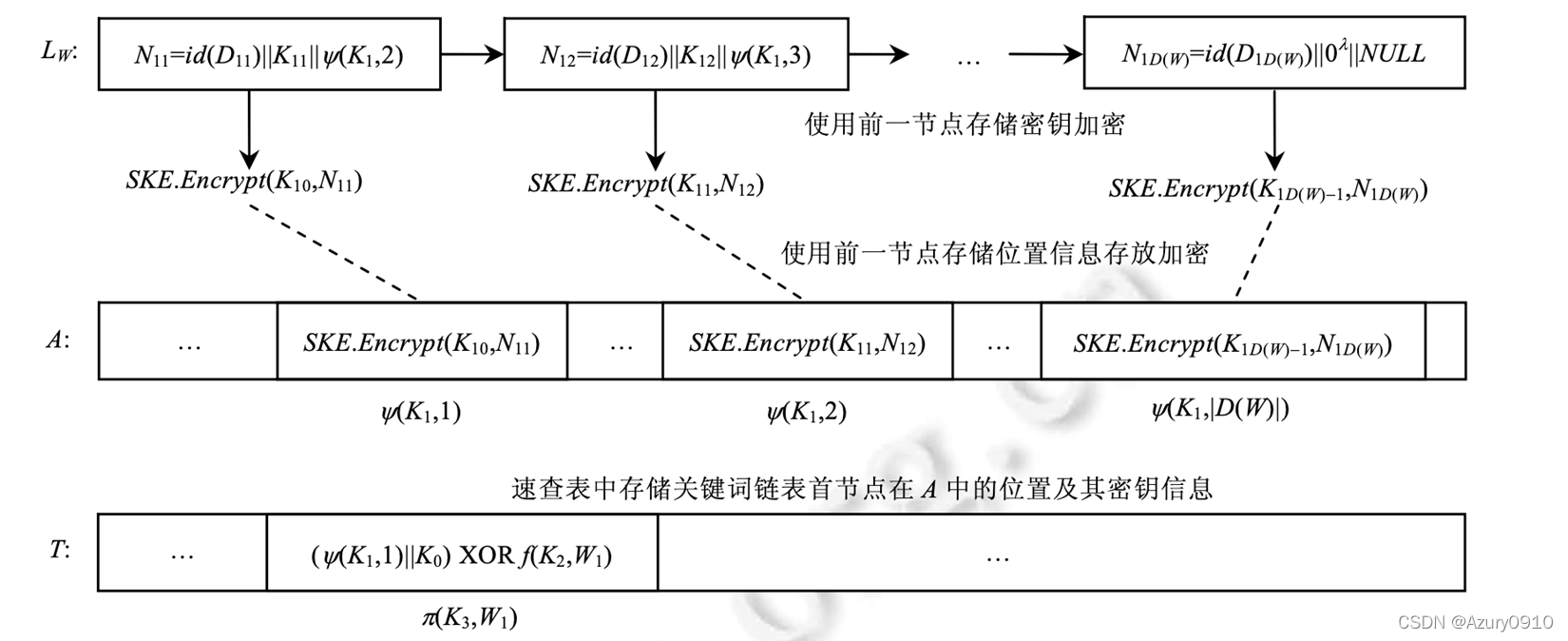
基于关键词-文档索引的方案𝝅
索引包括一个数组
A
A
A以及一个查找表
T
T
T。
其核心思路是首先为包含关键词
𝑤
𝑖
𝑤_𝑖
wi的第
𝑗
𝑗
j篇文档构造节点
𝑁
𝑖
,
j
𝑁_{𝑖,j}
Ni,j,此节点包含该文档的标识、下一个节点的加密密钥及其在数组
A
A
A中的存储位置,然后将此节点加密保存在数组
A
A
A中。
最后,将第一个节点
𝑁
𝑖
,
1
𝑁_{𝑖,1}
Ni,1的加密密钥以及存储位置异或一个掩码后存储在查找表T中。
检索时,服务器首先通过查找表
T
T
T找到检索关键词对应的第一个节点的信息,然后对数组A进行查找和解密,直到获得检索关键词对应的最后一个节点。
- Setup算法:数据所有者生成密钥 𝐾 1 , 𝐾 2 , 𝐾 3 𝐾_1,𝐾_2,𝐾_3 K1,K2,K3,对称加密算法Enc,伪随机置换 φ , π φ,π φ,π以及伪随机函数 𝑓 𝑓 f;
- BuildIndex算法:给定文档集合
D
D
D,数据所有者首先对其进行分词得到关键词集合
δ
(
D
)
δ(D)
δ(D),并为每个关键词
𝑤
𝑖
∈
δ
(
D
)
𝑤_𝑖∈δ(D)
wi∈δ(D)生成所有包含该关键词的文档集合
D
(
𝑤
𝑖
)
D(𝑤_𝑖)
D(wi)。然后,初始化计数器
c
t
r
=
1
ctr=1
ctr=1、数组
A
A
A以及查找表
T
T
T。对于各关键词
𝑤
𝑖
𝑤_𝑖
wi,
1
≤
𝑖
≤
∣
δ
(
D
)
∣
1≤𝑖≤|δ(D)|
1≤i≤∣δ(D)∣:
- 生成密钥 𝐾 𝑖 , 0 𝐾_{𝑖,0} Ki,0;
- 对于 1 ≤ 𝑗 ≤ ∣ D ( 𝑤 𝑖 ) ∣ − 1 1≤𝑗≤|D(𝑤_𝑖 )|−1 1≤j≤∣D(wi)∣−1:首先生成密钥 𝐾 𝑖 , 𝑗 𝐾_{𝑖,𝑗} Ki,j,然后构造节点 𝑁 𝑖 , 𝑗 = < 𝑖 𝑑 ( 𝐷 𝑖 , 𝑗 ) ) ∣ ∣ 𝐾 𝑖 , 𝑗 ) ∣ ∣ φ ( 𝐾 1 ) ( c t r + 1 ) > 𝑁_{𝑖,𝑗}=<𝑖𝑑(𝐷_{𝑖,𝑗}))||𝐾_{𝑖,𝑗)}||φ_(𝐾_1 ) (ctr+1)> Ni,j=<id(Di,j))∣∣Ki,j)∣∣φ(K1)(ctr+1)>,其中 𝑖 𝑑 ( 𝐷 ( 𝑖 , 𝑗 ) ) 𝑖𝑑(𝐷_{(𝑖,𝑗)}) id(D(i,j))为 D ( 𝑤 𝑖 ) D(𝑤_𝑖) D(wi)中第 𝑗 𝑗 j篇文档的标识。最后,使用密钥 𝐾 ( 𝑖 , 𝑗 − 1 ) 𝐾_{(𝑖,𝑗−1)} K(i,j−1)加密节点 𝑁 ( 𝑖 , 𝑗 ) 𝑁_{(𝑖,𝑗)} N(i,j),并将其保存在数组A的第 φ ( 𝐾 1 ) ( c t r ) φ_{(𝐾_1)}(ctr) φ(K1)(ctr)个位置,即 𝐴 [ φ ( 𝐾 1 ) ( c t r ) ] = 𝐸 𝑛 𝑐 ( 𝐾 ( 𝑖 , 𝑗 − 1 ) ) ( 𝑁 ( 𝑖 , 𝑗 ) ) 𝐴[φ_{(𝐾_1 )}(ctr)]=𝐸𝑛𝑐_{(𝐾_(𝑖,𝑗−1) ) }(𝑁_{(𝑖,𝑗)}) A[φ(K1)(ctr)]=Enc(K(i,j−1))(N(i,j)),同时令 c t r = c t r + 1 ctr=ctr+1 ctr=ctr+1;
- 对于 𝑗 = ∣ D ( 𝑤 𝑖 ) ∣ 𝑗=|D(𝑤_𝑖 )| j=∣D(wi)∣:构造节点 𝑁 ( 𝑖 , ∣ D ( 𝑤 𝑖 ) ∣ ) = < 𝑖 𝑑 ( 𝐷 ( 𝑖 , ∣ D ( 𝑤 𝑖 ) ∣ ) ) ∣ ∣ 0 𝑘 ∣ ∣ 𝑁 𝑈 𝐿 𝐿 > 𝑁_(𝑖,|D(𝑤_𝑖 )| )=<𝑖𝑑(𝐷_(𝑖,|D(𝑤_𝑖 )| ) )||0^𝑘 ||𝑁𝑈𝐿𝐿> N(i,∣D(wi)∣)=<id(D(i,∣D(wi)∣))∣∣0k∣∣NULL>,使用密钥 𝐾 ( 𝑖 , ∣ D ( 𝑤 𝑖 ) ∣ − 1 ) 𝐾_(𝑖,|D(𝑤_𝑖 )|−1) K(i,∣D(wi)∣−1)加密该节点,并将其保存在数组A的第 φ ( 𝐾 1 ) ( c t r ) φ_{(𝐾_1)} (ctr) φ(K1)(ctr)个位置,即 𝐴 [ φ ( 𝐾 1 ) ( c t r ) ] = 𝐸 𝑛 𝑐 ( 𝐾 ( 𝑖 , ∣ D ( 𝑤 𝑖 ) ∣ − 1 ) ) ( 𝑁 ( 𝑖 , ∣ D ( 𝑤 𝑖 ) ∣ ) ) 𝐴[φ_{(𝐾_1 )}(ctr)]=𝐸𝑛𝑐_{(𝐾_(𝑖,|D(𝑤_𝑖 )|−1))}(𝑁_{(𝑖,|D(𝑤_𝑖 )|)}) A[φ(K1)(ctr)]=Enc(K(i,∣D(wi)∣−1))(N(i,∣D(wi)∣)),同时令 c t r = c t r + 1 ctr=ctr+1 ctr=ctr+1;
- 置 T [ π ( 𝐾 3 ) ( 𝑤 𝑖 ) ] = < 𝑎 𝑑 𝑑 𝑟 𝐴 ( 𝑁 ( 𝑖 , 1 ) ) ∣ ∣ 𝐾 ( 𝑖 , 0 ) > ⨁ 𝑓 ( 𝐾 2 ) ( 𝑤 𝑖 ) T[π_{(𝐾_3 )}(𝑤_𝑖 )]=<𝑎𝑑𝑑𝑟_𝐴(𝑁_{(𝑖,1)})||𝐾_(𝑖,0)>⨁𝑓_{(𝐾_2 )}(𝑤_𝑖) T[π(K3)(wi)]=<addrA(N(i,1))∣∣K(i,0)>⨁f(K2)(wi),其中 𝑎 𝑑 𝑑 𝑟 𝐴 ( 𝑁 ( 𝑖 , 1 ) ) 𝑎𝑑𝑑𝑟_𝐴 (𝑁_{(𝑖,1)}) addrA(N(i,1))为节点𝑁_(𝑖,1)在数组 A A A中的存储位置。最后,对数组 A A A以及查找表 T T T中剩下的0进行混淆;
- GenTrapdoor算法:数据所有者为检索关键词w生成陷门 𝑡 = ( π ( 𝐾 3 ) ( 𝑤 ) , 𝑓 ( 𝐾 2 ) ( 𝑤 ) ) 𝑡=(π_{(𝐾_3 )}(𝑤),𝑓_{(𝐾_2 )}(𝑤)) t=(π(K3)(w),f(K2)(w));
- Search算法:服务器首先根据陷门
𝑡
=
(
γ
,
η
)
𝑡=(γ,η)
t=(γ,η)得到
θ
=
T
[
γ
]
θ=T[γ]
θ=T[γ]。如果
θ
≠
⊥
θ≠⊥
θ=⊥,则通过计算
θ
⨁
η
θ⨁η
θ⨁η得到
<
α
∣
∣
𝐾
′
>
<α||𝐾^′>
<α∣∣K′>,然后使用
𝐾
′
𝐾^′
K′解密
A
[
α
]
A[α]
A[α]保存的节点,并得到该节点对应的文档标识以及后续节点在数组
A
A
A中的存储位置和解密密钥,从而依次获得其后续节点的内容。最后服务器将检索到的文档标识返回给数据所有者。
4 小结:检索方案的比较
- 全文扫描方案要求服务器检索需遍历整个文件,时间复杂度为 O ( n s ) O(ns) O(ns)(n 为服务器上存储的文件数目,s 为文件平均长度),效率极低。
- 采用“文件-关键词”构建思想的 SSE 方案以文件为基本单位,使其在文件更新(该操作以文件为基本单位)时,只需更新当前使用的数据结构,具有较高的效率。由于检索是以关键词为基本单位进行,要求服务器遍历所有文件的数据结构,花费 O ( n ) O(n) O(n)时间,效率较低。
- 采用“关键词-文件”构建思想的 SSE 方案处理以关键词为基本操作单位的检索操作时,只需 O ( 1 ) O(1) O(1)时间,具备较高的效率。由于文件更新的基本操作单位为文件,而该思想的基本构建单位为关键词,使得文件更新时,服务器需重新构建适应更新后状态以关键词为基本单位的索引,造成较大开销。
5 检索方案的安全性
(1) 文档-关键词方案的安全性
为证明该方案的安全性,首先需要形式化地定义选择关键词语义安全IND-CKA和IND2-CKA(更为严格),并证明该方案满足这些安全性。
选择关键词语义安全IND2-CKA的含义是:
对于两个数据文档
𝑉
0
𝑉_0
V0和
𝑉
1
𝑉_1
V1,仅凭其密文索引无法对二者进行区分。
为了定义IND2-CKA,先定义如下游戏:
游戏3-1
- Setup过程:挑战者 C C C创建一个关键词集合 S S S,并将其发送给敌手 A A A(可将敌手 A A A视作一个概率多项式时间(PPT)算法)。 A A A选择 S S S的若干个子集,这些子集的集合记为 S ∗ S^* S∗,并将 C C C返回给 C C C。此处,一个子集可以看成一个数据文档。 C C C运行Setup算法,并对 S ∗ S^* S∗的每个元素运行BuildIndex算法,最后将全部索引及其对应的子集发送给 A A A;
- Query过程:敌手 A A A向挑战者 C C C请求关键词 𝑥 𝑥 x的陷门 𝑇 𝑥 𝑇_𝑥 Tx,并在任意索引上运行Search算法以判定该索引是否包含𝑥 ;
- Challenge过程:在运行若干次Query之后,敌手 A A A从 S ∗ S^* S∗中选择两个非空子集 𝑉 0 𝑉_0 V0和 𝑉 1 𝑉_1 V1 ,且 ∣ ( 𝑉 0 − 𝑉 1 ) ∪ ( 𝑉 1 − 𝑉 0 ) ∣ ≠ 0 |(𝑉_0−𝑉_1)∪(𝑉_1−𝑉_0)|≠0 ∣(V0−V1)∪(V1−V0)∣=0, ( 𝑉 0 − 𝑉 1 ) ∪ ( 𝑉 1 − 𝑉 0 ) (𝑉_0−𝑉_1)∪(𝑉_1−𝑉_0) (V0−V1)∪(V1−V0)中的任意关键词均未被查询过。 A A A将 𝑉 0 𝑉_0 V0和 𝑉 1 𝑉_1 V1发送给 C C C, C C C随机抛掷硬币 𝑏 𝑏 b,并在 𝑉 𝑏 𝑉_𝑏 Vb上运行BuildIndex算法,最后将对应的结果发给 A A A;
- Response过程:敌手 A A A给出对 𝑏 𝑏 b的猜测 𝑏 ′ 𝑏^′ b′。
我们将上述游戏的优势定义为 𝐴 𝑑 𝑣 𝐴 = ∣ P r ( 𝑏 ′ = 𝑏 ) − 1 / 2 ∣ 𝐴𝑑𝑣_𝐴=|Pr(𝑏^′=𝑏)−1/2| AdvA=∣Pr(b′=b)−1/2∣。
定义3-5 称一个SSE方案是IND2-CKA安全的,如果任何敌手A在上述游戏中的优势都是可忽略的。
定理 3-1 如果函数𝑓是一个伪随机函数,则基于布隆过滤器的方案 ϵ 1 \epsilon_1 ϵ1满足IND2-CKA安全性。
IND2-CKA安全性缺陷
(2)关键词-文档方案2的安全性
记 ∆ = 𝑤 1 , … , 𝑤 𝑑 ∆={𝑤_1,…,𝑤_𝑑} ∆=w1,…,wd为关键词集合,为每篇文档分别构造索引,具体步骤如下:
- Setup算法:数据所有者生成密钥 K K K以及伪随机置换函数 π \pi π;
- BuildIndex算法:假设数据所有者为文档集合中的第
c
t
r
ctr
ctr篇文档
D
D
D构造索引,首先初始化一个长度为
d
d
d的数组
A
A
A,然后对于关键词集合中的各关键词
𝑤
𝑖
∈
∆
𝑤_𝑖∈∆
wi∈∆,如果文档
D
D
D包含关键词
𝑤
𝑖
𝑤_𝑖
wi,则执行如下操作:
- 计算 𝑟 = π K ( 𝑤 𝑖 ∣ ∣ 𝑐 𝑡 𝑟 ) 𝑟=\pi_K(𝑤_𝑖 ||𝑐𝑡𝑟) r=πK(wi∣∣ctr);
- 将 A [ i ] A[i] A[i]设置为𝑟 ⨁ ( w 𝑖 ∣ ∣ 0 𝑘 ) ⨁(w_𝑖 ||0^𝑘) ⨁(wi∣∣0k),并在数组 A A A中没有存储数据的位置填充随机串;
- GenTrapdoor算法:数据所有者为检索关键词 w w w生成陷门 𝑟 1 = π 𝐾 ( 𝑤 ∣ ∣ 1 ) , … , 𝑟 𝑛 = π 𝐾 ( 𝑤 ∣ ∣ 𝑛 ) 𝑟_1=\pi_𝐾 (𝑤||1),…,𝑟_𝑛=\pi_𝐾 (𝑤||𝑛) r1=πK(w∣∣1),…,rn=πK(w∣∣n),其中n为文档集合中的文档总数,即每篇文档对应的陷门不同;
- Search算法:对于文档 D D D对应的数组 A A A,如果存在 1 ≤ 𝑗 ≤ ∣ 𝐴 ∣ 1≤𝑗≤|𝐴| 1≤j≤∣A∣,使得 𝐴 [ 𝑗 ] ⨁ 𝑟 𝑐 𝑡 𝑟 𝐴[𝑗]⨁𝑟_{𝑐𝑡𝑟} A[j]⨁rctr的后 k k k位均为0,则输出1;否则,输出0。
定理3-2 如果 π \pi π是伪随机置换函数,则上述方案满足IND2-CKA安全性。
显然,虽然上述方案可以满足IND2-CKA安全性,但是由于Search算法直接暴露了关键词 w w w的明文内容,该方案实际上是不安全的。究其根本原因,在于IND2-CKA安全性只考虑了索引和陷门孤立的安全性,而检索操作需要将索引和陷门二者同时作为输入,还需要考虑二者结合的安全性。
为此,人们提出了4个新的安全性的定义:
- 非适应性语义安全NS
- 非适应性不可区分性NI
- 适应性语义安全AS
- 适应性不可区分性AS
NS=NI<AI≤AS
这里介绍非适应性语义安全NS和适应性语义安全AS,它们的安全级别关系是NS<AS。在描述具体的安全性定义之前,首先介绍几个辅助概念:
定义3-7(查询历史) 一个查询历史
H
H
H包括两个组成部分:被查询的文档集合
D
=
{
𝐷
1
,
…
,
𝐷
𝑛
}
D=\{𝐷_1,…,𝐷_𝑛\}
D={D1,…,Dn}以及查询关键词列表
W
=
{
𝑤
1
,
…
,
𝑤
𝑞
}
W=\{𝑤_1,…,𝑤_𝑞\}
W={w1,…,wq},即
H
=
(
D
,
W
)
H=(D,W)
H=(D,W)。
定义3-8(访问模式) 一个查询历史H的访问模式α是所有查询返回的文档列表: α ( 𝐻 ) = ( 𝐷 ( 𝑤 1 ) , … , 𝐷 ( 𝑤 𝑞 ) ) \alpha(𝐻)=(𝐷(𝑤_1 ),…,𝐷(𝑤_𝑞 )) α(H)=(D(w1),…,D(wq))。
定义3-9(搜索模式) 一个查询历史H的搜索模式
δ
δ
δ是一个对称的
q
×
q
q×q
q×q矩阵,表示两次查询的关键词是否相等:
当且仅当
𝑤
𝑖
=
𝑤
𝑗
𝑤_𝑖=𝑤_𝑗
wi=wj时,矩阵
δ
(
H
)
δ(H)
δ(H)第
i
i
i行
j
j
j列的元素为1即
δ
(
𝐻
)
[
𝑖
,
𝑗
]
=
1
δ(𝐻)[𝑖,𝑗]=1
δ(H)[i,j]=1;否则,
δ
(
𝐻
)
[
𝑖
,
𝑗
]
=
0
δ(𝐻)[𝑖,𝑗]=0
δ(H)[i,j]=0。
定义3-10(轨迹) 一个查询历史 H H H的轨迹 t t t包括文档集合中每篇文档的长度以及访问模式和搜索模式: 𝑡 ( 𝐻 ) = ( ∣ 𝐷 1 ∣ , … , ∣ 𝐷 𝑛 ∣ , α ( 𝐻 ) , δ ( 𝐻 ) ) 𝑡(𝐻)=(|𝐷_1 |,…,|𝐷_𝑛 |,\alpha(𝐻),δ(𝐻)) t(H)=(∣D1∣,…,∣Dn∣,α(H),δ(H))。
定义3-11 (非适应性语义安全)
设Real是如下的一个游戏过程:
- 挑战者运行Setup算法获得密钥;
- 敌手选择查询历史 H = ( D , W ) H=(D,W) H=(D,W) ;
- 挑战者对文档集合 D D D加密得到密文 [ D ] [D] [D],并运行BuildIndex算法得到索引 I I I。同时,运行GenTrapdoor算法为查询关键词列表 W W W中的各关键词 𝑤 𝑖 𝑤_𝑖 wi生成陷门 𝑡 𝑖 𝑡_𝑖 ti;
- 输出 ( 𝐼 , [ D ] , 𝑡 1 , … , 𝑡 𝑞 ) (𝐼,[D],𝑡_1,…,𝑡_𝑞) (I,[D],t1,…,tq)。
设Sim是如下的一个模拟过程:
- 敌手选择查询历史 H = ( D , W ) H=(D,W) H=(D,W);
- 挑战者根据轨迹 t ( H ) t(H) t(H)模拟生成 ( 𝐼 , [ D ] , 𝑡 1 , … , 𝑡 𝑞 ) (𝐼,[D],𝑡_1,…,𝑡_𝑞) (I,[D],t1,…,tq);
- 输出 ( 𝐼 , [ D ] , 𝑡 1 , … , 𝑡 𝑞 ) (𝐼,[D],𝑡_1,…,𝑡_𝑞) (I,[D],t1,…,tq)。
称一个密文检索方案是非适应性语义安全的,如果对于任意多项式能力的敌手,均存在一个多项式时间模拟算法,使得Real和Sim的输出结果无法区分。
定义3-12 (适应性语义安全)
Real是一个如下的游戏过程:
- 挑战者运行Setup算法得到密钥;
- 敌手选择文档集合 D D D;
- 挑战者对文档集合 D D D加密得到密文 [ D ] [D] [D],并运行BuildIndex算法得到索引$I4;
- 敌手根据密文 [ D ] [D] [D]和索引 I I I选择第一个查询关键词 w 1 w_1 w1;
- 挑战者运行GenTrapdoor算法生成关键词 w 1 w_1 w1对应的陷门 t 1 t_1 t1;
- 对于
2
≤
i
≤
q
2≤i≤ q
2≤i≤q:
6.1)敌手根据 [ D ] [D] [D]、 I I I以及前 i − 1 i-1 i−1次的陷门 t 1 , … , t i − 1 t_1,…,t_{i-1} t1,…,ti−1选择查询关键词 w i w_i wi;
6.2)挑战者运行GenTrapdoor算法生成关键词 w i w_i wi对应的陷门 t i t_i ti ; - 输出 ( 𝐼 , [ D ] , 𝑡 1 , … , 𝑡 𝑞 ) (𝐼,[D],𝑡_1,…,𝑡_𝑞) (I,[D],t1,…,tq)。
Sim是一个如下的模拟过程:
- 敌手选择文档集合 D D D;
- 挑战者根据轨迹 t ( D ) t(D) t(D)模拟生成密文 [ D ] [D] [D]以及索引 I I I;
- 敌手根据密文 [ D ] [D] [D]和索引 I I I选择第一个查询关键词 w 1 w_1 w1 ;
- 挑战者根据轨迹 t ( D , w 1 ) t(D,w_1) t(D,w1)模拟生成陷门 t 1 t_1 t1 ;
- 对于
2
≤
i
≤
q
2≤i≤ q
2≤i≤q:
5.1)敌手根据 [ D ] [D] [D]、 I I I以及前 i − 1 i-1 i−1次的陷门$t1,…, t i − 1 t_{i-1} ti−1选择查询关键词 w i w_i wi ;
5.2)挑战者根据轨迹 t ( D , w 1 , … , w i ) t(D,w_1,…,w_i) t(D,w1,…,wi)模拟生成陷门 t i t_i ti ; - 输出 ( 𝐼 , [ D ] , 𝑡 1 , … , 𝑡 𝑞 ) (𝐼,[D],𝑡_1,…,𝑡_𝑞) (I,[D],t1,…,tq)。
称一个密文检索方案是适应性语义安全的,如果对于任意多项式能力的敌手,均存在一个多项式时间模拟算法,使得Real和Sim的输出结果无法区分。
上述两种安全性说明了仅凭轨迹信息就能模拟出与原始方案不可区分的方案,这表明轨迹是密文检索方案唯一泄露的信息。非适应性安全定义和适应性安全定义的主要区别在于敌手的攻击能力,其中前者的背景知识是敌手一次性选定的,而后者的敌手可以根据以往的背景知识选择下一次需要获得的背景知识。
适应性安全高于非适应性
- 文档-关键词 非适应性语义安全
- 关键词-文档 适应性语义安全
(四)非对称密文检索(不细考 适用场景和算法组成)
非对称密文检索是指数据所有者(数据发送者)和数据检索者(数据接收者)不是同一方的密文检索技术。与非对称密码体制类似,数据所有者可以是了解公钥的任意用户,而只有拥有私钥的用户可以生成检索陷门。一个典型的非对称密文检索过程如下:
- Setup算法:该算法由数据检索者执行,生成公钥PK和私钥SK
- BuildIndex算法:该算法由数据所有者执行,根据数据内容建立索引,并将公钥加密后的索引和数据本身上传到服务器
- GenTrapdoor算法:该算法由数据检索者执行,将私钥和检索关键词作为输入,生成相应的陷门(又称“搜索凭证”),然后将陷门发送给服务器;
- Search算法:该算法由服务器执行,将公钥、接收到的陷门和本地存储的索引作为输入,进行协议所预设的计算,最后输出满足条件的搜索结果。
1 BDOP-PEKS方案
2 KR-PEKS方案
3 DS-PEKS方案
4 小结:三种方案比较
(五)密文区间检索
1 早期工作
(1) 基于桶式索引的方案
主要思路:将属性值域进行分桶,并为各分桶分配一个唯一的标识,记录的索引即为其属性值所在分桶的标识。当需要进行检索时,用户将与检索区间相交的分桶的标识集合发送给服务器,服务器随后将这些分桶内的全部密文数据作为检索结果返回给用户。
方案特点:实现简单,在一定程度上保证了敏感数据的机密性。但是,服务器返回的检索结果中可能包含大量的冗余数据,需要客户端进行二次检索。此外,客户端还需要将分桶策略保存在本地。
(2) 基于B+树和传统加密技术的方案
主要思路:为数据构造B+树,并使用传统加密技术将各节点分别加密后存储到服务器。当需要进行检索时,服务器将密文节点返回给用户,由用户在解密后进行判断,然后通知服务器下一个需要查询的密文节点。
方案特点:客户端工作量较大,且需要服务器和客户端之间进行多轮交互操作。
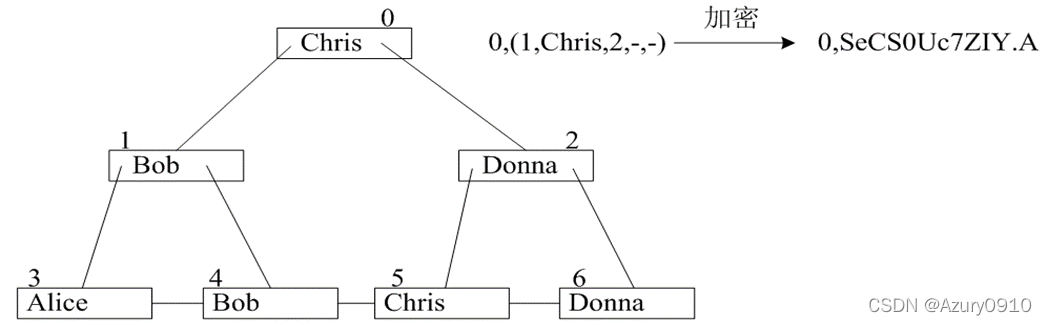
2 基于矩阵加密的方案 @
矩阵加密是密文区间检索方案中一种常用的对称加密技术,其用于安全地计算两个向量的内积。矩阵加密具有实现简单、运算效率高、适用于处理高精度数据等优势,但是安全性较差。
假设 d d d为向量的维度,需要计算数据向量 P P P与查询向量 Q Q Q的内积。基础的矩阵加密方案的工作流程如下:
- ASPE.setup(d):输出一个 d × d d×d d×d的可逆矩阵 M M M;
- ASPE.data_enc(P,M):输出 P ^ = M T P \hat{P}=M^TP P^=MTP;
- ASPE.query_enc(Q,M):输出
Q
^
=
M
−
1
P
\hat{Q}=M^{-1}P
Q^=M−1P。
易知,
P ^ ⋅ Q ^ = M T P ⋅ M − 1 P = ( M P T ) T ⋅ M − 1 P = P T M M − 1 P = P ⋅ Q \hat{P} \cdot \hat{Q}=M^TP \cdot M^{-1}P= (MP^T)^T \cdot M^{-1}P= P^TM M^{-1}P=P\cdot Q P^⋅Q^=MTP⋅M−1P=(MPT)T⋅M−1P=PTMM−1P=P⋅Q
密文向量保留了明文向量的内积。

定理3-4 如图3-8所示,已知在一个原点为O的坐标系中存在一个单位圆,上半圆周上有A、B、C3个不同的点,OA和OB,OB和OC,OA和OC之间的夹角分别为θ1,θ2,θ3,其中0<θi<π,i=1,2,3。那么当且仅当cosθ3<cosθ1cosθ2 ,OB位于OA和OC之间(仅考虑上半圆)。
推论3-1 已知在一个原点为O的坐标系中存在一个圆,上半圆周上有V、VL、VH3个不同的点,OV、OVL、OVH与横坐标的夹角分别是θ,θL,θH ,其中0<θ,θL,θH<π 。那么当且仅当cos(θH-θL)<cos(θ-θL)cos(θ-θH)时,θL<θ<θH。
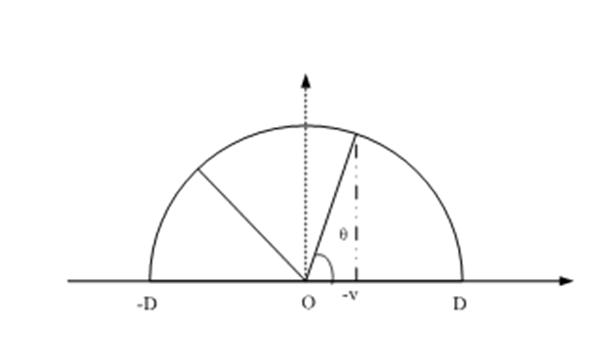
基于以上定理以及推论,我们可以将区间判断映射为单断言。假设属性值域为
[
−
D
,
D
]
[-D,D]
[−D,D],如图3-9所示,值映射函数 将值
v
v
v映射为角度
θ
θ
θ。由于该映射函数在
v
∈
[
−
D
,
D
]
v∈[-D,D]
v∈[−D,D]时是单调递增的,那么对于任意
v
1
>
v
2
,
v
1
,
v
2
∈
[
−
D
,
D
]
v_1>v_2,v_1,v_2∈[-D,D]
v1>v2,v1,v2∈[−D,D],其对应的映射角度
θ
1
,
θ
2
θ1,θ2
θ1,θ2必然满足
θ
1
>
θ
2
,
θ
1
,
θ
2
∈
[
0
,
π
]
θ_1>θ_2,θ_1, θ_2∈[0,π]
θ1>θ2,θ1,θ2∈[0,π] 。因此,对于属性值
v
v
v和检索区间
(
v
L
,
v
H
)
,
v
∈
(
v
L
,
v
H
)
(v_L,v_H), v∈(v_L,v_H)
(vL,vH),v∈(vL,vH)的充分必要条件是
θ
L
<
θ
<
θ
H
θ_L<θ<θ_H
θL<θ<θH,即
c
o
s
(
θ
H
−
θ
L
)
<
c
o
s
(
θ
−
θ
L
)
c
o
s
(
θ
−
θ
H
)
cos(θ_H-θ_L)<cos(θ-θ_L)cos(θ-θ_H)
cos(θH−θL)<cos(θ−θL)cos(θ−θH)。通过如下公式,可以将判断条件中的
θ
θ
θ与
θ
L
,
θ
H
θ_L,θ_H
θL,θH进行分离,然后使用矩阵加密对其进行保护:
c
o
s
(
θ
−
θ
L
)
=
c
o
s
θ
c
o
s
θ
L
+
s
i
n
θ
s
i
n
θ
L
=
[
c
o
s
θ
s
i
n
θ
]
[
c
o
s
θ
L
s
i
n
θ
L
]
cos(θ-θ_L)=cosθcosθ_L+sinθsinθ_L=\begin{bmatrix}cosθ&sinθ\\\end{bmatrix}\begin{bmatrix}cosθ_L\\sinθ_L\\\end{bmatrix}
cos(θ−θL)=cosθcosθL+sinθsinθL=[cosθsinθ][cosθLsinθL]
c
o
s
(
θ
−
θ
H
)
=
c
o
s
θ
c
o
s
θ
H
+
s
i
n
θ
s
i
n
θ
H
=
[
c
o
s
θ
s
i
n
θ
]
[
c
o
s
θ
H
s
i
n
θ
H
]
cos(θ-θ_H)=cosθcosθ_H+sinθsinθ_H=\begin{bmatrix}cosθ&sinθ\\\end{bmatrix}\begin{bmatrix}cosθ_H\\sinθ_H\\\end{bmatrix}
cos(θ−θH)=cosθcosθH+sinθsinθH=[cosθsinθ][cosθHsinθH]
具体的基于矩阵加密的单维区间检索方案步骤如下:
- Setup:输出一个 2 × 2 2×2 2×2的可逆矩阵 M M M;
- BuildIndex( v v v, M M M):计算得到 θ = F ( v ) θ=F(v) θ=F(v)以及 I = [ c o s θ s i n θ ] I= \begin{bmatrix}cosθ\\sinθ\\\end{bmatrix} I=[cosθsinθ],然后输出 I ^ = M T I \hat{I}=M^TI I^=MTI
- GenTrapdoor( v L v_L vL, v H v_H vH, M M M):计算得到 θ L = F ( v L ) , θ H = F ( v H ) θ_L=F(v_L), θ_H=F(v_H) θL=F(vL),θH=F(vH)以及 T L = [ c o s θ L s i n θ L ] , T H = [ c o s θ H s i n θ H ] T_L= \begin{bmatrix}cosθ_L\\sinθ_L\\\end{bmatrix},T_H= \begin{bmatrix}cosθ_H\\sinθ_H\\\end{bmatrix} TL=[cosθLsinθL],TH=[cosθHsinθH],同时计算 T r a n g e = c o s ( θ H − θ L ) T_{range}=cos(θ_H-θ_L) Trange=cos(θH−θL),然后输出 I ^ = M T I \hat{I}=M^TI I^=MTI运行矩阵加密运算得到 T ^ L = M − 1 T L , T ^ H = M − 1 T H \hat{T}_L=M^{-1}T_L,\hat{T}_H=M^{-1}T_H T^L=M−1TL,T^H=M−1TH,输出 T ^ = { T 1 ^ , T 2 ^ , T r a n g e } \hat{T}=\{\hat{T_1},\hat{T_2},T_{range}\} T^={T1^,T2^,Trange},其中 T 1 ^ , T 2 ^ \hat{T_1},\hat{T_2} T1^,T2^并不是固定地分别对应 T ^ L , T ^ H \hat{T}_L,\hat{T}_H T^L,T^H,其对应关系是随机的;
- Search( I ^ , T ^ \hat{I},\hat{T} I^,T^):进行单断言 T r a n g e < ( I ^ ⋅ T 1 ^ ) ( I ^ ⋅ T 2 ^ ) T_{range}<(\hat{I}\cdot\hat{T_1})(\hat{I}\cdot\hat{T_2}) Trange<(I^⋅T1^)(I^⋅T2^)判断,如果为真,则输出1,否则,输出0。
由于上述方案为各记录分别构造索引,因此,检索时,也需要依次判断各记录是否满足检索条件,即该方案的检索效率与记录数目成正比。
3 基于谓词加密的方案
基于不同类型的谓词加密技术,谓词加密可以分为对称谓词加密和非对称谓词加密 。在基于谓词加密的方案中,假设所有值均为整数。
目标:判断属性值
u
∈
[
1
,
n
]
u∈[1, n]
u∈[1,n]是否属于区间
Q
⊂
[
1
,
n
]
Q\subset[1,n]
Q⊂[1,n]
思路:为属性值
u
u
u构造向量
𝑥
=
𝑥
1
,
𝑥
2
,
⋯
,
𝑥
𝑛
𝑥={𝑥_1, 𝑥_2, ⋯, 𝑥_𝑛}
x=x1,x2,⋯,xn,其中若
i
=
u
i = u
i=u,则
𝑥
𝑖
=
1
𝑥_𝑖=1
xi=1;否则
𝑥
𝑖
=
0
𝑥_𝑖=0
xi=0。
为区间Q构造向量
𝑣
=
𝑣
1
,
𝑣
2
,
⋯
,
𝑣
𝑛
𝑣={𝑣_1, 𝑣_2, ⋯, 𝑣_𝑛}
v=v1,v2,⋯,vn,其中
i
∈
𝑄
i∈𝑄
i∈Q,则
𝑣
𝑖
=
0
𝑣_𝑖=0
vi=0;否则
𝑣
𝑖
=
0
𝑣_𝑖=0
vi=0。
于是判断
u
u
u是否属于
Q
Q
Q就等价于判断向量
x
x
x和
v
v
v的内积是否为0。
而对称谓词加密方案提供了在不公开
x
x
x和
v
v
v的前提下判断内积是否为0的方法。
该方法虽然实现简单,但计算量与向量长度n 成正比,导致该方法检索效率过低。考虑到现实应用场景中大多为实数型数据,因此向量的长度将非常大,超出接受能力。
4 基于等值检索的方案
基于等值检索的密文区间检索方案,其核心思想是将区间检索转换为等值检索,然后使用现有的基于关键词-文档索引的密文关键词检索方案完成查询。将区间检索转换为关键词检索,有利于将这两种检索方式进行结合。
直观上,可以将每个属性值看作一个关键词,然后通过枚举检索区间内的属性值,直接将区间检索转换为多轮等值检索,然而这种方法不适用于处理数值精度较高或者检索区间较大的情况。因此,研究者希望可以将检索区间映射为少量关键词,从而限制陷门的大小。
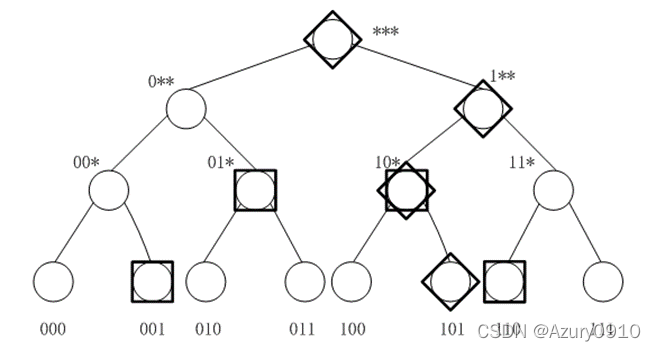
可以使用线段树中的节点来表示属性值和检索区间,并令每个节点对应一个关键词。如图3-7所示,假设属性值域为[0,7],属性值为5的记录对应的关键词即为节点101,10*,1**,***对应的关键词。检索时,假设检索区间为[1,6],其对应的最小节点集合为{001,01*,10*,110},则分别使用这些节点对应的关键词进行单关键词检索,最后对检索结果求并集。
5 基于保序加密的方案
保序加密(Order-Preserving Encryption,OPE)是一种保持数值顺序关系的加密算法,其算法本身可以应用于各种场景,并不仅限于区间检索。
定义3-13 (保序加密) 给定加密算法E,如果对于任何密钥k,以及数值数据x和y(x<y),均存在 E k ( x ) < E k ( y ) E_k(x)<E_k(y) Ek(x)<Ek(y),则称E是保序的。
6 小结:区间检索四种方案优缺点比较
由于谓词加密方案本身实现了可证明安全,因此,基于谓词加密的密文区间检索方案普遍安全性较高。但是其基本运算操作为双线性映射,从而检索效率较低,不适用于处理高维度高精度数据。
基于矩阵加密的方案虽然安全性不如谓词加密方案,但是其基本运算操作为乘法和加法,因此,检索效率较高,且可以方便地处理高精度数据。
基于等值检索的方案灵活性较大,根据用户对于安全性、效率和存储空间的要求,可以采用不同的关键词构造方式。由于这类方法主要基于密文关键词检索方案,因此,容易将区间检索和关键词检索相结合。
保序加密由于其本身的特征,使得密文直接泄露了明文的排序特征,因此安全性较低。但是对于经过保序加密的数据,可以使用任意明文数据结构和检索方式对其进行检索,所以在安全性要求不高的场景中,保序加密具有良好的表现。
第四章 安全处理技术
(一)安全处理技术
1 同态加密:算法组成、正确性、全同态加密、语义安全性、紧凑性
同态加密(Homomorphic Encryption,HE)的思想最早是由Rivest等人于1978年提出的,其基本思想是:在不解密的前提下,能否对密文数据进行任意的计算,且计算结果的解密值等于对应的明文计算的结果。
以云计算应用场景为例。以同态加密处理数据的整个处理过程大致是这样的:
- Alice对数据进行加密。并把加密后的数据发送给Cloud;
- Alice向Cloud提交数据的处理方法,这里用函数f来表示;
- Cloud在函数f下对数据进行处理,并且将处理后的结果发送给Alice;
- Alice对数据进行解密,得到结果。
根据f的限制条件不同,同态加密方案实际上分为了两类:
- 全同态加密(Fully Homomorphic Encryption, FHE):这意味着HE方案支持任意给定的f函数,只要这个f函数可以通过算法描述,用计算机实现。通常FHE的开销较大。
- 类同态加密(Somewhat Homomorphic Encryption, SWHE):这意味着HE方案只支持一些特定的f函数。SWHE方案稍弱,但也意味着开销会变得较小,容易实现。
一个同态加密方案
ε
ε
ε通常由以下四个算法组成:
① KeyGen算法:输入安全参数
λ
λ
λ(
λ
λ
λ通常用来刻画密钥的比特长度),生成公钥
p
k
p_k
pk和私钥
s
k
s_k
sk,即
(
p
k
,
s
k
)
←
K
e
y
G
e
n
(
λ
)
(p_k,s_k)←KeyGen(λ)
(pk,sk)←KeyGen(λ);
② Encrypt算法:输入明文
𝑚
∈
{
0
,
1
}
𝑚 ∈ \{0,1\}
m∈{0,1}和公钥
p
k
p_k
pk,得到密文
𝑐
𝑐
c,即
𝑐
←
E
n
c
r
y
p
t
(
p
k
,
𝑚
)
𝑐 ← Encrypt(p_k, 𝑚 )
c←Encrypt(pk,m) ;
③ Decrypt算法:输入私钥
s
k
s_k
sk和密文
𝑐
𝑐
c,得到明文
𝑚
𝑚
m ,即
𝑚
←
D
e
c
r
y
p
t
(
s
k
,
𝑐
)
𝑚 ← Decrypt(s_k, 𝑐)
m←Decrypt(sk,c);
④ Evaluate算法:输入公钥
p
k
p_k
pk、
t
t
t比特输入的布尔电路
𝐶
𝐶
C和一组密文
𝑐
1
,
𝑐
2
,
⋯
,
𝑐
𝑡
𝑐_1, 𝑐_2, ⋯ , 𝑐_𝑡
c1,c2,⋯,ct,其中
𝑐
𝑖
←
E
n
c
r
y
p
t
(
p
k
,
𝑚
𝑖
)
,
i
=
1
,
2
,
⋯
,
t
𝑐_𝑖 ← Encrypt(p_k, 𝑚_𝑖), i = 1,2, ⋯ ,t
ci←Encrypt(pk,mi),i=1,2,⋯,t,得到另一个密文
𝑐
∗
𝑐^∗
c∗,即
𝑐
∗
←
E
v
a
l
u
a
t
e
(
p
k
,
𝐶
,
𝒄
)
𝑐^∗ ← Evaluate(p_k, 𝐶, 𝒄)
c∗←Evaluate(pk,C,c),其中
𝐜
=
(
𝑐
1
,
𝑐
2
,
⋯
,
𝑐
𝑡
)
𝐜 = (𝑐1, 𝑐2, ⋯ , 𝑐𝑡 )
c=(c1,c2,⋯,ct)。
布尔电路由模2加法门和模2乘法门组成,加密方案的明文空间为
{
0
,
1
}
\{0,1\}
{0,1}
定义4-1(正确性)* 一个方案
ε
=
(
K
e
y
G
e
n
,
E
n
c
r
y
p
t
,
D
e
c
r
y
p
t
,
E
v
a
l
u
a
t
e
)
ε=(KeyGen, Encrypt, Decrypt, Evaluate)
ε=(KeyGen,Encrypt,Decrypt,Evaluate)对一个给定的
t
t
t比特输入的布尔电路
𝐶
𝐶
C是正确的,如果对任何由
K
e
y
G
e
n
(
λ
)
KeyGen(λ)
KeyGen(λ)输出的密钥对
(
p
k
,
s
k
)
(p_k,s_k)
(pk,sk),以及任何明文比特
𝑚
1
,
𝑚
2
,
⋯
,
𝑚
𝑡
𝑚_1, 𝑚_2, ⋯ , 𝑚_𝑡
m1,m2,⋯,mt和任何密文
𝐜
=
𝑐
1
,
𝑐
2
,
⋯
,
𝑐
𝑡
,
𝑐
𝑖
←
E
n
c
r
y
p
t
(
p
k
,
𝑚
𝑖
)
(
i
=
1
,
2
,
⋯
,
t
)
𝐜 = 𝑐_1, 𝑐_2, ⋯ , 𝑐_𝑡, 𝑐_𝑖 ← Encrypt(pk, 𝑚_𝑖) (i = 1,2, ⋯ ,t)
c=c1,c2,⋯,ct,ci←Encrypt(pk,mi)(i=1,2,⋯,t), 都 有
D
e
c
r
y
p
t
(
𝑠
𝑘
,
E
v
a
l
u
a
t
e
(
p
k
,
𝐶
,
𝐜
)
)
=
𝐶
(
𝑚
1
,
𝑚
2
,
⋯
,
𝑚
𝑡
)
Decrypt(𝑠_𝑘, Evaluate(p_k, 𝐶, 𝐜)) = 𝐶(𝑚_1, 𝑚_2, ⋯ , 𝑚_𝑡)
Decrypt(sk,Evaluate(pk,C,c))=C(m1,m2,⋯,mt)。
定义4-2(同态加密) 一个方案
ε
=
(
K
e
y
G
e
n
,
E
n
c
r
y
p
t
,
D
e
c
r
y
p
t
,
E
v
a
l
u
a
t
e
)
ε=(KeyGen, Encrypt, Decrypt, Evaluate)
ε=(KeyGen,Encrypt,Decrypt,Evaluate)对一类布尔电路
C
ℂ
C是同态的,如果对所有的布尔电路
𝐶
∈
C
𝐶 ∈ ℂ
C∈C,
ε
ε
ε都是正确的。
定义4-3(全同态加密)* 一个方案
ε
=
(
K
e
y
G
e
n
,
E
n
c
r
y
p
t
,
D
e
c
r
y
p
t
,
E
v
a
l
u
a
t
e
)
ε=(KeyGen, Encrypt, Decrypt, Evaluate)
ε=(KeyGen,Encrypt,Decrypt,Evaluate)是全同态的,如果对所有的布尔电路,
ε
ε
ε都是正确的。
定义4-4(可忽略函数) 设
μ
(
𝑛
)
:
𝑁
→
𝑅
\mu(𝑛) : 𝑁 → 𝑅
μ(n):N→R,
𝑁
𝑁
N是自然数集,
𝑅
𝑅
R是实数集,称函数
μ
(
𝑛
)
\mu(𝑛)
μ(n) 是可忽略的,如果对任意多项式
𝑝
(
⋅
)
𝑝(\cdot)
p(⋅),存在
𝑁
0
∈
𝑁
𝑁_0 ∈ 𝑁
N0∈N,使得对所有的
𝑛
>
𝑁
0
𝑛 > 𝑁_0
n>N0,都有
μ
𝑛
<
1
/
𝑝
(
𝑛
)
\mu_𝑛 < 1/𝑝(𝑛)
μn<1/p(n)。
语义安全性是相对于被动敌手(也称监听敌手)而言的,这种敌手只是被动地获取密文而非主动进行攻击。语义安全性是指敌手无法区分一个密文是两个确定明文中的哪一个的加密,即使这两个明文是敌手自己选择的也是如此。对于公钥加密方案而言,这正是选择明文攻击下的不可区分安全性,又 称 多 项 式 安 全 。
一 个 方 案 ε = ( K e y G e n , E n c r y p t , D e c r y p t , E v a l u a t e ) ε=(KeyGen,Encrypt, Decrypt, Evaluate) ε=(KeyGen,Encrypt,Decrypt,Evaluate)的语义安全性可通过一个游戏(也称实验)来定义,将这个游戏记为 G a m e A , ε ( λ ) Game_{A,ε}(λ) GameA,ε(λ),其中 A A A为敌手(可视作一个概率多项式时间(PPT)算法), λ λ λ为安全参数。
游戏4-1
G
a
m
e
A
,
ε
(
λ
)
Game_{A,ε}(λ)
GameA,ε(λ)的执行过程如下:
① 挑战者运行
(
p
k
,
s
k
)
←
K
e
y
G
e
n
(
λ
)
(p_k, s_k) ← KeyGen(λ)
(pk,sk)←KeyGen(λ) ,将
p
k
p_k
pk发送给敌手
A
A
A;
② 敌手
A
A
A得到
p
k
p_k
pk,并产生一对等长的消息
𝑚
0
,
𝑚
1
𝑚_0, 𝑚_1
m0,m1;
③ 挑战者选择
b
∈
{
0
,
1
}
b ∈ \{0,1\}
b∈{0,1},计算
𝑐
∗
←
E
n
c
r
y
p
t
(
p
k
,
𝑚
𝑏
)
𝑐^∗ ← Encrypt(p_k, 𝑚_𝑏)
c∗←Encrypt(pk,mb)
,并将
𝑐
∗
𝑐^∗
c∗发送给敌手
A
A
A;
④ 敌手
A
A
A根据
λ
λ
λ和
𝑐
∗
𝑐^∗
c∗输出一个比特
𝑏
′
∈
{
0
,
1
}
𝑏^′ ∈ \{0,1\}
b′∈{0,1},可理解
为
𝑏
′
←
A
(
λ
,
𝑐
∗
)
𝑏′ ← A(λ, 𝑐^∗)
b′←A(λ,c∗);
⑤ 如果
𝑏
′
=
𝑏
𝑏^′ = 𝑏
b′=b,则游戏成功并输出1,否则游戏失败并输出0。
从上述游戏的执行过程中可以看出,敌手 A A A可以不顾密文而均匀随机地输出一个比特 𝑏 ′ 𝑏^′ b′,成功的概率为1/2。一般地,把一个敌手 A A A成功的概率超过1/2的量 称 为 其 成 功 的 优 势 , 记 为 A d v A , ε ( λ ) = P r [ G a m e A , ε ( λ ) = 1 ] − 1 / 2 Adv_{A,ε}(λ) =Pr[Game_{A,ε}(λ)= 1] − 1/2 AdvA,ε(λ)=Pr[GameA,ε(λ)=1]−1/2
定义4-5(语义安全性)* 一个方案
ε
=
(
K
e
y
G
e
n
,
E
n
c
r
y
p
t
,
D
e
c
r
y
p
t
,
E
v
a
l
u
a
t
e
)
ε=(KeyGen, Encrypt, Decrypt, Evaluate)
ε=(KeyGen,Encrypt,Decrypt,Evaluate)是语义安全的,如果任何PPT敌手
A
A
A在游戏4-1中成功的优势都是可忽略的,即对任何PPT敌手
A
A
A,都存在一个可忽略函数𝜇 λ ,使得
A
d
v
A
,
ε
(
λ
)
≤
μ
(
λ
)
Adv_{A,ε}(λ) ≤\mu(λ)
AdvA,ε(λ)≤μ(λ)。
显然,根据定义4-3,有一种平凡的方法可将任何公钥加密方案转化为全同态加密方案。将Evaluate算法取为首先用Decrypt解密所有的密文
c
c
c,然后将所对应的明文作为𝐶 的输入计算其值,即
E
v
a
l
u
a
t
e
(
p
k
,
𝐶
,
c
=
𝐶
(
D
e
c
r
y
p
t
(
s
k
,
𝑐
1
)
,
D
e
c
r
y
p
t
(
s
k
,
𝑐
2
)
,
…
,
D
e
c
r
y
p
t
(
s
k
,
𝑐
𝑡
)
)
Evaluate(p_k, 𝐶, c = 𝐶(Decrypt(s_k, 𝑐_1), Decrypt(s_k, 𝑐_2), … , Decrypt (s_k, 𝑐_𝑡 ))
Evaluate(pk,C,c=C(Decrypt(sk,c1),Decrypt(sk,c2),…,Decrypt(sk,ct))
**紧凑性(compactness)**可排除全同态加密方案的这种平凡解决方法。
紧凑性是指由
E
v
a
l
u
a
t
e
(
p
k
,
𝐶
,
𝐜
)
Evaluate(pk, 𝐶, 𝐜)
Evaluate(pk,C,c)产生的密文的尺寸不依赖于电路
𝐶
𝐶
C 的尺寸(也称规模),看起来像普通密文一样。
定义4-6(紧凑性) 一个方案
ε
=
(
K
e
y
G
e
n
,
E
n
c
r
y
p
t
,
D
e
c
r
y
p
t
,
E
v
a
l
u
a
t
e
)
ε=(KeyGen, Encrypt, Decrypt, Evaluate)
ε=(KeyGen,Encrypt,Decrypt,Evaluate)是紧凑的,如果存在一个固定的多项式界
b
(
λ
)
b(λ)
b(λ),使得对任何由
K
e
y
G
e
n
(
λ
)
KeyGen(λ)
KeyGen(λ)输出的密钥对
(
p
k
,
s
k
)
(p_k, s_k)
(pk,sk),任何电路
𝐶
𝐶
C ,以及任何用
p
k
p_k
pk产生的密文序列
𝐜
=
(
𝑐
1
,
𝑐
2
,
⋯
,
𝑐
𝑡
)
𝐜 =(𝑐_1, 𝑐_2, ⋯ , 𝑐_𝑡)
c=(c1,c2,⋯,ct),密文
E
v
a
l
u
a
t
e
(
p
k
,
𝐶
,
𝐜
)
Evaluate(p_k, 𝐶, 𝐜)
Evaluate(pk,C,c)的尺寸不超过
b
(
λ
)
b(λ)
b(λ)比特,即密文
E
v
a
l
u
a
t
e
(
p
k
,
𝐶
,
𝐜
)
Evaluate(p_k, 𝐶, 𝐜)
Evaluate(pk,C,c)的尺寸独立于
𝐶
𝐶
C的尺寸。
2 自举加密
Gentry于2009年基于理想格构造了第一个全同态加密方案,该方案的基本思路是:首先构造 一个类同态加密方案。类同态加密方案只能对加密数据进行低次多项式计算,也就是说只能同态计算“浅的电路”;其次给出一种将类同态加密方案修改为自举(ootstrappble)同态加密方案的方法;最后通过递归式自嵌入 ,任何一个自举同态加密
方案都可以转化为一个全同态方案。
定义4-7(增强型解密电路) 对于加密方案 ε = ( K e y G e n , E n c r y p t , D e c r y p t , E v a l u a t e ) ε=(KeyGen, Encrypt, Decrypt, Evaluate) ε=(KeyGen,Encrypt,Decrypt,Evaluate),其中Decrypt可由一个仅依赖于安全参数的电路来实现(这个条件意味着对于一个固定的安全参数,私钥的尺寸总是一样的,而且能被解密的所有密文有同样的尺寸)。对于给定的安全参数 λ λ λ,对应的增强型解密电路由两个电路组成,这两个电路的输入参数都为一个私钥和两个密文,其中一个电路将两个密文分别解密后对恢复出的两个明文进行模2加操作,而另一个电路则将两个密文分别解密后对恢复出的两个明文进行模2乘操作。记所有增强型解密电路的集合为 𝐷 ε ( λ ) 𝐷_ε(λ) Dε(λ)。
定义4-8(自举加密) 对于同态加密方案
ε
=
(
K
e
y
G
e
n
,
E
n
c
r
y
p
t
,
D
e
c
r
y
p
t
,
E
v
a
l
u
a
t
e
)
ε=(KeyGen, Encrypt, Decrypt, Evaluate)
ε=(KeyGen,Encrypt,Decrypt,Evaluate),对于每个安全参数
λ
λ
λ,记所有使得
ε
ε
ε是正确的电路的集合为
𝐶
ε
(
λ
)
𝐶_ε(λ)
Cε(λ) 。称
ε
ε
ε是自举的,如果对于每个安全参数
λ
λ
λ,都有
𝐷
ε
(
λ
)
∈
𝐶
ε
(
λ
)
𝐷_ε(λ) ∈ 𝐶_ε(λ)
Dε(λ)∈Cε(λ)成立。
通俗地讲,自举同态加密方案具有能够处理自身解密函数能力的自引用特性。自举性要求一个同态加密方案
ε
ε
ε的Decrypt也是
ε
ε
ε可同态计算的函数。
3 类同态加密方案
(1) 参数选择
(2) 类同态对称加密方案 @
① KeyGen(λ):输入安全参数
λ
λ
λ,随机生成一个
η
\eta
η比特的奇正整数
𝑝
𝑝
p作为密钥
𝑘
𝑘
k;
② Encrypt(𝑘, 𝑚):输入密钥
𝑘
=
𝑝
𝑘 = 𝑝
k=p和明文
𝑚
∈
{
0
,
1
}
𝑚 ∈ \{0,1\}
m∈{0,1},随机选择一个
γ
−
η
\gamma − \eta
γ−η比特的正整数
𝑞
𝑞
q和一个
ρ
\rho
ρ比特的整数
𝑟
𝑟
r,显然
2
𝑟
+
𝑚
2𝑟 + 𝑚
2r+m 远小于
𝑝
𝑝
p,生成密文
𝑐
=
𝑘
𝑞
+
2
𝑟
+
𝑚
𝑐 = 𝑘𝑞 + 2𝑟 + 𝑚
c=kq+2r+m ;
③ Decrypt(𝑘, 𝑐):输入密钥
𝑘
=
𝑝
𝑘 = 𝑝
k=p和密文
𝑐
𝑐
c,恢复明文
𝑚
=
(
𝑐
m
o
d
𝑘
)
m
o
d
2
𝑚 = (𝑐 \mod 𝑘) \mod 2
m=(cmodk)mod2;
④ Evaluate(𝑘, 𝐶, 𝑐1, 𝑐2, ⋯ , 𝑐𝑡):给定
𝑡
𝑡
t比特输入的布尔电路
𝐶
𝐶
C和
𝑡
𝑡
t个密文
𝑐
𝑖
𝑐_𝑖
ci,将密文
𝑐
𝑖
𝑐_𝑖
ci作为
𝐶
𝐶
C的输入,此时将
𝐶
𝐶
C的加法门和乘法门视作整数加法和乘法进行运算并返回所计算出的整数。
4 全同态加密方案【不考】
(二)可验证计算技术
1 基本概念
(1) 比特承诺 @
比特承诺(bit commitment)方案可通过一个函数 𝑓 : { 0 , 1 } × X → Y 𝑓: \{0,1\} × X\rightarrow Y f:{0,1}×X→Y来实现,这里 𝑋 𝑋 X和 𝑌 𝑌 Y是两个有限集。 𝑏 ∈ { 0 , 1 } 𝑏 ∈ \{0,1\} b∈{0,1}的密文随机地在集合 { f ( b , x ) : x ∈ X } \{f(b,x):x\in X\} {f(b,x):x∈X}中取值。
定义4-11(比特承诺) 设 𝑋 𝑋 X和 𝑌 𝑌 Y是两个有限集, 𝑓 : { 0 , 1 } × X → Y 𝑓: \{0,1\} × X\rightarrow Y f:{0,1}×X→Y。我们称 𝑓 𝑓 f是一个比特承诺方案,如果它满足以下两个特性:
- 隐藏性(hiding):对 𝑏 ∈ { 0 , 1 } 𝑏 ∈ \{0,1\} b∈{0,1},接收者不能从 𝑓 ( 𝑏 , 𝑥 ) 𝑓(𝑏, 𝑥) f(b,x)确定出 𝑏 𝑏 b的值。
- 绑定性(binding):发送者能打开(也称解开) 𝑓 ( 𝑏 , 𝑥 ) 𝑓(𝑏, 𝑥) f(b,x),即发送者能通过揭示辅助值 𝑥 𝑥 x使接收者相信 𝑏 𝑏 b是唯一可能被加密的值。
如果发送者想承诺任何比特串
𝑠
𝑠
s,那么他可以通过分别独立地承诺
𝑠
𝑠
s的每一个比特来完成。
比特承诺方案可记为
𝑓
(
𝑠
,
𝑘
)
𝑓(𝑠, 𝑘)
f(s,k)。
接下来介绍一个基于Goldwasser-Micali概率加密算法的比特承诺方案。
设
𝑛
=
𝑝
𝑞
𝑛 = 𝑝𝑞
n=pq,
𝑝
𝑝
p和
𝑞
𝑞
q都是素数,
𝑚
∈
𝑄
𝑅
‾
(
𝑛
)
=
{
𝑥
∣
(
𝑥
/
𝑝
)
=
(
𝑥
/
𝑞
)
=
−
1
}
𝑚 ∈ \overline{𝑄𝑅}(𝑛) = \{𝑥|(𝑥/𝑝) = (𝑥/𝑞) = −1\}
m∈QR(n)={x∣(x/p)=(x/q)=−1},公开
𝑛
𝑛
n和
𝑚
𝑚
m ,
n
n
n的分解只有发送者知道。设
𝑋
=
𝑌
=
𝑍
n
∗
𝑋 = 𝑌 = 𝑍_n^∗
X=Y=Zn∗,
𝑓
(
𝑏
,
𝑥
)
=
𝑚
𝑏
𝑥
2
m
o
d
𝑛
𝑓(𝑏, 𝑥) = 𝑚^{𝑏}𝑥^2 \mod 𝑛
f(b,x)=mbx2modn。
- 1)承诺阶段。发送者通过选择一个随机数 𝑥 𝑥 x加密 𝑏 𝑏 b,加密结果为 𝑦 = 𝑓 ( 𝑏 , 𝑥 ) 𝑦 = 𝑓(𝑏, 𝑥) y=f(b,x)。
- 2)打开阶段。当发送者想打开 𝑦 𝑦 y时,他揭示值 𝑏 𝑏 b和 𝑥 𝑥 x,接收者验证 𝑦 = 𝑚 𝑏 𝑥 2 m o d 𝑛 𝑦 = 𝑚^{𝑏}𝑥^2 \mod 𝑛 y=mbx2modn。
假定二次剩余问题是困难的,那么 𝑓 ( 𝑏 , 𝑥 ) 𝑓(𝑏, 𝑥) f(b,x)没有泄露关于 𝑏 𝑏 b和 𝑥 𝑥 x的任何信息。所以该方案满足隐藏性。现在我们来说明该方案满足绑定性。若该方案不满足绑定性,则存在 𝑥 1 , 𝑥 2 ∈ 𝑍 𝑛 ∗ 𝑥1, 𝑥2 ∈𝑍_𝑛^∗ x1,x2∈Zn∗,使得 𝑚 𝑥 1 2 ≡ 𝑥 2 2 m o d 𝑛 𝑚 𝑥_1^2≡𝑥_2^2mod 𝑛 mx12≡x22modn ,这样 𝑚 ≡ ( 𝑥 2 𝑥 1 − 1 ) 2 m o d 𝑛 𝑚 ≡(𝑥_2𝑥_1 ^{−1})^2mod 𝑛 m≡(x2x1−1)2modn。说明 𝑚 ∈ 𝑄 𝑅 ( 𝑛 ) 𝑚∈𝑄𝑅(𝑛) m∈QR(n),即m是一个二次剩余,这与 𝑚 ∈ 𝑄 𝑅 ( 𝑛 ) 𝑚 ∈ 𝑄𝑅(𝑛) m∈QR(n)相矛盾。
(2) 零知识证明
设 𝐿 ⊂ { 0 , 1 } ∗ 𝐿 ⊂ \{0,1\}^∗ L⊂{0,1}∗是一个语言, 𝑈 = { 𝑈 𝑥 } 𝑥 ∈ 𝐿 𝑈 = \{𝑈_𝑥\}_{𝑥∈𝐿} U={Ux}x∈L和 V = { V 𝑥 } 𝑥 ∈ 𝐿 V = \{V_𝑥\}_{𝑥∈𝐿} V={Vx}x∈L两族随机变量。
定义4-13(完美不可区分)
称
𝑈
=
{
𝑈
𝑥
}
𝑥
∈
𝐿
𝑈 = \{𝑈_𝑥\}_{𝑥∈𝐿}
U={Ux}x∈L和
V
=
{
V
𝑥
}
𝑥
∈
𝐿
V = \{V_𝑥\}_{𝑥∈𝐿}
V={Vx}x∈L在语言
L
L
L上是完美不可区分的,如果对每个充分长的
x
∈
L
x∈L
x∈L,
𝑈
𝑥
𝑈_𝑥
Ux和
𝑉
𝑥
𝑉_𝑥
Vx的概率分布相等,即对每个
α
∈
{
0
,
1
}
∗
\alpha ∈ \{0,1\}^∗
α∈{0,1}∗,
P
r
(
𝑈
𝑥
=
α
)
=
P
r
(
𝑉
𝑥
=
α
)
Pr (𝑈_𝑥 = \alpha) = Pr (𝑉_𝑥 = \alpha)
Pr(Ux=α)=Pr(Vx=α)。
这时也称
𝑈
=
{
𝑈
𝑥
}
𝑥
∈
𝐿
𝑈 = \{𝑈_𝑥\}_{𝑥∈𝐿}
U={Ux}x∈L和
V
=
{
V
𝑥
}
𝑥
∈
𝐿
V = \{V_𝑥\}_{𝑥∈𝐿}
V={Vx}x∈L相等(equality)
由定义可知,如果两族随机变量 𝑈 = { 𝑈 𝑥 } 𝑥 ∈ 𝐿 𝑈 = \{𝑈_𝑥\}_{𝑥∈𝐿} U={Ux}x∈L和 V = { V 𝑥 } 𝑥 ∈ 𝐿 V = \{V_𝑥\}_{𝑥∈𝐿} V={Vx}x∈L在语言 L L L上是相等的,那么对充分长的 x ∈ L x∈L x∈L ,判决者即使具有无限的计算能力和拥有无穷多的样本也无法判定这些样本来自 𝑈 𝑥 𝑈_𝑥 Ux还是来自 𝑉 𝑥 𝑉_𝑥 Vx
定义4-14(统计不可区分)
称
𝑈
=
{
𝑈
𝑥
}
𝑥
∈
𝐿
𝑈 = \{𝑈_𝑥\}_{𝑥∈𝐿}
U={Ux}x∈L和
V
=
{
V
𝑥
}
𝑥
∈
𝐿
V = \{V_𝑥\}_{𝑥∈𝐿}
V={Vx}x∈L在语言
L
L
L上是统计不可区分的,如果对任意常数
c
>
0
c>0
c>0和每个充分长的
x
∈
L
x∈L
x∈L,都有
∑
α
∈
{
0
,
1
}
∗
∣
P
r
(
𝑈
𝑥
=
α
)
−
P
r
(
V
𝑥
=
α
)
∣
<
∣
x
∣
−
c
\sum_{\alpha ∈ \{0,1\}^∗}|Pr (𝑈_𝑥 = \alpha) -Pr (V_𝑥 = \alpha) |<|x|^{-c}
α∈{0,1}∗∑∣Pr(Ux=α)−Pr(Vx=α)∣<∣x∣−c由定义可知,如果两族随机变量
𝑈
=
{
𝑈
𝑥
}
𝑥
∈
𝐿
𝑈 = \{𝑈_𝑥\}_{𝑥∈𝐿}
U={Ux}x∈L和
V
=
{
V
𝑥
}
𝑥
∈
𝐿
V = \{V_𝑥\}_{𝑥∈𝐿}
V={Vx}x∈L在语言
L
L
L上是统计不可区分的,那么对充分长的
x
∈
L
x∈L
x∈L,对拥有多项式个样本和具有无限计算能力的判决者,他也基本上无法判定这些样本来自
𝑈
𝑥
𝑈_𝑥
Ux还是来自
𝑉
𝑥
𝑉_𝑥
Vx。
定义4-16(计算不可区分)
设
𝑈
=
{
𝑈
𝑥
}
𝑥
∈
𝐿
𝑈 = \{𝑈_𝑥\}_{𝑥∈𝐿}
U={Ux}x∈L和
V
=
{
V
𝑥
}
𝑥
∈
𝐿
V = \{V_𝑥\}_{𝑥∈𝐿}
V={Vx}x∈L是两个多项式界随机变量
族,
C
=
{
C
𝑥
}
𝑥
∈
𝐿
C = \{C_𝑥\}_{𝑥∈𝐿}
C={Cx}x∈L是多项式规模的电路族,用
P
r
(
𝑈
,
𝐶
,
𝑥
)
Pr (𝑈, 𝐶, 𝑥)
Pr(U,C,x)表示按
𝑈
𝑥
𝑈_𝑥
Ux分布的随机串作为输入,
𝐶
𝑥
𝐶_𝑥
Cx输出1的概率。称
U
U
U和
V
V
V在语言
L
L
L上是计算不可区分的,如果对任意常数
c
>
0
c>0
c>0和每个充分长的
x
∈
L
x∈L
x∈L,都有
∣
P
r
(
𝑈
,
𝐶
,
𝑥
)
−
P
r
(
𝑉
,
𝐶
,
𝑥
)
∣
<
∣
𝑥
∣
−
C
|Pr(𝑈, 𝐶, 𝑥)− Pr(𝑉, 𝐶, 𝑥)|< |𝑥|^{-C}
∣Pr(U,C,x)−Pr(V,C,x)∣<∣x∣−C
由定义易知,对于两个随机变量族 𝑈 = { 𝑈 𝑥 } 𝑥 ∈ 𝐿 𝑈 = \{𝑈_𝑥\}_{𝑥∈𝐿} U={Ux}x∈L和 V = { V 𝑥 } 𝑥 ∈ 𝐿 V = \{V_𝑥\}_{𝑥∈𝐿} V={Vx}x∈L,如果它们在语言 L L L上是完美不可区分的,那么它们在语言L上必定是统计不可区分的。如果它们在语言L上是统计不可区分的,那么它们在语言L上必定是计算不可区分的
2 基于承诺的可验证计算:朴素地证明x=y的协议(协议4-1)
协议4-1 朴素地证明 x i = x j x_i=x_j xi=xj的协议,记为PROVE-EQUAL-NAIV( x i , s j x_i,s_j xi,sj)
- P将 𝑥 𝑖 0 ⨁ 𝑥 𝑗 0 𝑥_𝑖^0⨁𝑥_𝑗^0 xi0⨁xj0的值发送给 V V V;
- V V V均匀地选择 𝑏 ∈ { 0 , 1 } 𝑏 ∈ \{0,1\} b∈{0,1},并将 b b b发送给 P P P;
- P P P使用理想的承诺方案揭示 𝑥 𝑖 𝑏 𝑥_𝑖^𝑏 xib和 𝑥 𝑗 𝑏 𝑥_𝑗^𝑏 xjb,如果 𝑥 𝑖 𝑏 𝑏 ⨁ 𝑥 𝑗 𝑏 𝑥_𝑖^𝑏𝑏⨁𝑥_𝑗^𝑏 xibb⨁xjb与第1)步发送的值相等,则 V V V接受。
3 基于同态加密的可验证计算:线性MIP和线性PCP,具体方案(协议4-8+协议4-9)
(三)安全多方计算技术
1 百万富翁问题 @
百万富翁问题:在没有第三方参与的情况下,两个百万富翁如何在不暴露自己的财产数额的情况下比较谁更富有?
1982年,姚期智教授提出的百万富翁协议是解决百万富翁问题的最早方案。假设Alice的秘密输入 a a a,Bob的秘密输入 b b b,满足 𝑎 ≠ 𝑏 ∈ [ 1 , 𝑛 ] 𝑎 ≠ 𝑏 ∈ [1, 𝑛] a=b∈[1,n],令M是所有N比特非负整数的集合, 𝑄 𝑁 𝑄_𝑁 QN是所有从M到M的一一映射函数的集合。令 𝐸 𝐴 𝐸_𝐴 EA是Alice的公钥加密算法,它是从 𝑄 𝑁 𝑄_𝑁 QN中随机抽取的。
百万富翁协议的具体描述如下:
输入:Alice的秘密输入
a
a
a,Bob的秘密输入
b
b
b
输出:
a
a
a和
b
b
b的大小关系
- Bob随机选取一个N比特的整数 x x x,计算 𝑘 = 𝐸 𝐴 ( 𝑥 ) 𝑘 = 𝐸_𝐴(𝑥) k=EA(x),并将 k − b + 1 k-b+1 k−b+1发送给Alice。
- Alice计算 𝑦 𝑢 = 𝐷 𝐴 ( 𝑘 − b + 𝑢 ) 𝑦_𝑢 = 𝐷_𝐴(𝑘 −b +𝑢) yu=DA(k−b+u),其中(u = 1, 2, …, n)。
- Alice产生一个N/2比特的随机素数 p p p,对所有 u u u计算 𝑧 𝑢 = 𝑦 𝑢 m o d p 𝑧_𝑢 = 𝑦_𝑢 \mod p zu=yumodp。如果所有的 𝑧 𝑢 𝑧_𝑢 zu在模 p p p运算下至少相差2,则停止;否则重新产生一个随机素数 p p p重复上面的步骤。
- Alice将素数p以及 z 1 , z 2 , . . . , z a , z a + 1 + 1 , z n + 1 z_{1},z_{2},...,z_{a},z_{a+1}+1,z_n+1 z1,z2,...,za,za+1+1,zn+1,这n个数都发送给Bob
- Bob检验Alice传过来的不包括 p p p在内的第 b b b个值,若它等于 x m o d p x \mod p xmodp,则 𝑎 > 𝑏 𝑎 > 𝑏 a>b;否则 𝑎 < 𝑏 𝑎 < 𝑏 a<b
- Bob把结论告诉Alice。
正确性分析:因为
z
u
=
D
A
[
E
A
(
x
)
−
b
+
u
]
m
o
d
p
z_u=D_A[E_A(x)-b+u]\mod p
zu=DA[EA(x)−b+u]modp
特别地,有
z
b
=
D
A
[
E
A
(
x
)
−
b
+
b
]
m
o
d
p
=
D
A
[
E
A
(
x
)
]
m
o
d
p
=
x
m
o
d
p
z_b=D_A[E_A(x)-b+b] \mod p=D_A[E_A(x)]\mod p = x\mod p
zb=DA[EA(x)−b+b]modp=DA[EA(x)]modp=xmodp
如果
a
>
b
a>b
a>b,那么第
b
b
b个值为
z
b
z_b
zb,否则为
z
b
+
1
z_b+1
zb+1。所以Bob通过检验第
b
b
b个值可以判断
a
a
a和
b
b
b的大小。
安全性分析:首先,Alice从Bob那里仅仅得到 k − b + 1 k-b+1 k−b+1,由于 k k k的存在,Alice不能从中得知 b b b。其次Bob通过Alice发送来的序列无法辨认出 𝑧 𝑢 𝑧_𝑢 zu和 𝑧 𝑢 + 1 𝑧_𝑢 + 1 zu+1,因此无法得知 a a a。
但是协议仍存在一些可以被攻击的地方。例如,Bob可以选择随机数 t t t,验证 𝐸 𝐴 ( 𝑡 ) = 𝑘 − b + m 𝐸_𝐴(𝑡) = 𝑘−b+m EA(t)=k−b+m是否成立。如果尝试成功,他便知道 𝑦 m = 𝑡 𝑦_m= 𝑡 ym=t, 从而知道 𝑧 m 𝑧_m zm的值,进而判断 a a a是否大于 m m m。而且在协议的最后一步,Bob可能欺骗Alice,告诉Alice一个错误的结论。也就是说,该协议不能使用在恶意模型下。
2 参与者分类
- 诚实参与者:在协议执行过程中,完全按照协议的要求完成协议的各个步骤,同时对自己的输入、输出及中间结果进行保密。
- 半诚实参与者:在协议执行过程中,半诚实参与者按照协议的要求完成协议的各个步骤,但会收集并记录协议运行中的信息和计算结果,也可以根据信息和计算结果推断其他参与者的信息。
- 恶意参与者:恶意参与者可以完全不遵守协议指令运行,包括拒绝参与协议运行、以替换的输入参与协议运行、中断协议运行。
3 模型分类
- 半诚实模型:参与者是诚实的或半诚实的
- 恶意模型:存在恶意参与者的模型
(四)函数加密技术
(五)外包计算技术
外包计算(outsourced computation)允许计算资源受限的用户将计算复杂性较高的计算外包给远端的半可信或恶意服务器完成。
外包计算的研究主要集中用户数据的安全性和隐私性以及如何验证服务器返回结果的正确性(完整性)上,同时还要实现高效性。
1 多个服务器的外包计算方案(协议4-14)@
外包者 O O O有两个矩阵 𝑀 ( 1 ) 𝑀^{ (1)} M(1)和 𝑀 ( 2 ) 𝑀^{ (2)} M(2),他希望获得 𝑀 ( 1 ) 𝑀 ( 2 ) 𝑀^{ (1)}𝑀^{ (2)} M(1)M(2)。下列介绍的协议实际上可以计算任意大小的矩阵乘法,但为了便于表示,我们仅考虑 𝑛 × 𝑛 𝑛 × 𝑛 n×n矩阵(方阵),并设 𝑁 = 𝑛 2 𝑁 = 𝑛^2 N=n2。
假定 O O O能完成 𝑂 ( 𝑛 2 ) 𝑂(𝑛^2) O(n2)计算,但不能完成 𝑂 ( 𝑛 3 ) 𝑂(𝑛^3) O(n3)计算。
矩阵 𝑀 𝑀 M的第 𝑖 𝑖 i行第 𝑗 𝑗 j列元素表示为 𝑀 𝑖 , 𝑗 , 𝑖 , 𝑗 = 0 , 1 , … , 𝑛 − 1 𝑀_{𝑖,𝑗}, 𝑖,𝑗 = 0,1, … , 𝑛 − 1 Mi,j,i,j=0,1,…,n−1。设 𝑝 𝑝 p是一个所有参与方都知道的大素数,用 𝑃 𝑀 𝑖 , 𝑗 ( 𝑡 ) 𝑃_{𝑀_{𝑖,𝑗}}^{(𝑡)} PMi,j(t)表示隐藏值 𝑀 𝑖 , 𝑗 𝑀_{𝑖,𝑗} Mi,j的 𝑡 𝑡 t次多项式,即 𝑃 𝑀 𝑖 , 𝑗 ( 𝑡 ) = a t x t + a t + 1 x t + 1 + ⋯ + a 1 x + 𝑀 𝑖 , 𝑗 𝑃_{𝑀_{𝑖,𝑗}}^{(𝑡)}=a_tx_t+a_{t+1}x_{t+1}+\cdots+a_1x+𝑀_{𝑖,𝑗} PMi,j(t)=atxt+at+1xt+1+⋯+a1x+Mi,j, a i ( i = 1 , 2 , ⋯ , t ) a_i(i=1,2,\cdots,t) ai(i=1,2,⋯,t)是从 Z p Z_p Zp中随机选择的;用 𝑃 𝑀 ( 𝑡 ) ( x ) 𝑃_{𝑀}^{(𝑡)}(x) PM(t)(x)表示第 𝑖 𝑖 i行第 𝑗 𝑗 j列元素为 𝑃 𝑀 𝑖 , 𝑗 ( 𝑡 ) ( x ) 𝑃_{𝑀_{𝑖,𝑗}}^{(𝑡)}(x) PMi,j(t)(x)的矩阵。
协议4-14 具有多个服务器的外包计算协议
- 1)对矩阵 𝑀 ( 1 ) 𝑀^{ (1)} M(1)和 𝑀 ( 2 ) 𝑀^{ (2)} M(2)的每一个元素, O O O产生一个隐藏该元素的 t t t次多项式,把这些矩阵多项式表示为 𝑃 𝑀 ( 1 ) ( 𝑡 ) ( 𝑥 ) 𝑃_{𝑀 ^{(1)}}^{(𝑡)}(𝑥) PM(1)(t)(x)和 𝑃 𝑀 ( 2 ) ( 𝑡 ) ( 𝑥 ) 𝑃_{𝑀 ^{(2)}}^{(𝑡)}(𝑥) PM(2)(t)(x);对 𝑠 = 1 , 2 , … , 2 𝑡 + 1 𝑠 = 1,2, … , 2𝑡 + 1 s=1,2,…,2t+1, O O O把矩阵 𝑃 𝑀 ( 1 ) ( 𝑡 ) ( s ) 𝑃_{𝑀 ^{(1)}}^{(𝑡)}(s) PM(1)(t)(s)和 𝑃 𝑀 ( 2 ) ( 𝑡 ) ( s ) 𝑃_{𝑀 ^{(2)}}^{(𝑡)}(s) PM(2)(t)(s)发送给 𝑈 𝑠 𝑈_𝑠 Us;
Q首先随机产生关于 𝑀 ( 1 ) 𝑀^{ (1)} M(1)和 𝑀 ( 2 ) 𝑀^{ (2)} M(2)的隐藏多项式,然后发送每个矩阵的一个分享给每个不可信第三方;
- 2) 𝑈 𝑠 𝑈_𝑠 Us计算矩阵 𝑅 ( 𝑠 ) = 𝑃 𝑀 ( 1 ) ( 𝑡 ) ( s ) 𝑃 𝑀 ( 2 ) ( 𝑡 ) ( s ) 𝑅(𝑠) =𝑃_{𝑀 ^{(1)}}^{(𝑡)}(s)𝑃_{𝑀 ^{(2)}}^{(𝑡)}(s) R(s)=PM(1)(t)(s)PM(2)(t)(s)并将 𝑅 ( 𝑠 ) 𝑅(𝑠) R(s)返回给 O O O;
第三方计算它们的各个分项的矩阵乘法并将计算结果返回给 O O O
- 3)对所有的 𝑖 , 𝑗 𝑖,𝑗 i,j, O O O插值计算矩阵 𝑅 𝑖 , 𝑗 ( 1 ) , … , 𝑅 𝑖 , 𝑗 ( 2 t + 1 ) 𝑅_{𝑖,𝑗}(1) , … , 𝑅_{𝑖,𝑗}(2t+1) Ri,j(1),…,Ri,j(2t+1)获得 𝑀 ( 1 ) 𝑀 i , j ( 2 ) 𝑀^{ (1)}𝑀^{ (2)}_{i,j} M(1)Mi,j(2)因此, O O O最终获得 𝑀 ( 1 ) 𝑀 ( 2 ) 𝑀^{ (1)}𝑀^{ (2)} M(1)M(2)。
O O O将插值计算这些结果,获得两个矩阵的乘积。
𝑃 𝑀 ( 1 ) ( 𝑡 ) ( s ) 𝑃_{𝑀 ^{(1)}}^{(𝑡)}(s) PM(1)(t)(s)和 𝑃 𝑀 ( 2 ) ( 𝑡 ) ( s ) 𝑃_{𝑀 ^{(2)}}^{(𝑡)}(s) PM(2)(t)(s)分别是 𝑀 ( 1 ) 𝑀^{ (1)} M(1)和 𝑀 ( 2 ) 𝑀^{ (2)} M(2)的分享矩阵,两个矩阵的乘积是它们的元素的乘积之和,因此,分享的矩阵乘法是 𝑀 ( 1 ) 𝑀 ( 2 ) 𝑀^{ (1)}𝑀^{ (2)} M(1)M(2)的 2 t 2t 2t次多项式。
2 两个服务器的外包计算方案:弱秘密隐藏假设
3 单个服务器的外包计算方案:抢秘密隐藏假设
第五章 隐私保护技术
(一)基本知识
大数据时代,人类活动前所未有地被数据化。大数据为各行业的发展提供例强有力的支持,但也面临越来越严重但隐私挖掘威胁。
为满足用户保护个人隐私的需求及相关法律法规的要求,大数据隐私保护技术需要确保公开发布的数据不泄露任何用户的敏感信息,同时还应考虑到发布数据的可用性,避免数据过度失真。因此,数据隐私保护技术的目标在于实现数据可用性和隐私性之间的良好平衡。
1 隐私保护数据的参与方
一个隐私保护数据发布方案的构建涉及以下四个参与方:
- 个人用户:被收集数据的用户。
- 数据采集/发布者:数据采集者与用户签订一定的数据收集、使用协议,获得用户的相关数据。数据采集者通常也负责数据发布(用户本地隐私保护情景除外),并根据发布目的和限制条件对数据进行一定的处理提供给数据使用者。
- 数据使用者:任意可获取该公开数据的机构和个人。希望获得满足其使用目的的尽可能真实有效的数据。
- 攻击者:可获取该公开数据的恶意使用者。可能具有额外的信息或知识等,并以此获取该公开数据中特定用户身份、敏感信息,进而从中牟取利益。
2 分类
(1) 根据隐私保护需求
根据用户隐私保护需求可分为身份隐私、属性隐私、社交关系隐私、位置轨迹隐私等几大类。
- 身份隐私:指数据记录中的用户ID或社交网络中的虚拟节点对应的真实用户身份信息。保护目标是降低攻击者从数据集中识别出某特定用户的可能性。
- 属性隐私:属性数据用来描述个人用户的属性特征。保护目标是防止用户敏感属性特征泄露。
- 社交关系隐私:用户和用户之间形成的社交关系也是隐私的一种。社交关系隐私保护要求节点对应的社交关系保持匿名,攻击者无法确认特定用户拥有哪些社交关系。
- 位置轨迹隐私:位置轨迹数据来源广泛,且可能暴露用户隐私属性、私密关系、出行规律、甚至真实身份。用户位置轨迹隐私保护要求对用户的真实位置、敏感位置进行隐藏或处理,不泄露用户的行动规律,从而保护用户安全。
(2) 数据类型
从数据类型角度看,用户隐私数据可以表示为结构化或者非结构化数据。
-
通常用户的属性信息属于典型的结构化数据,可以表示为数据库表;
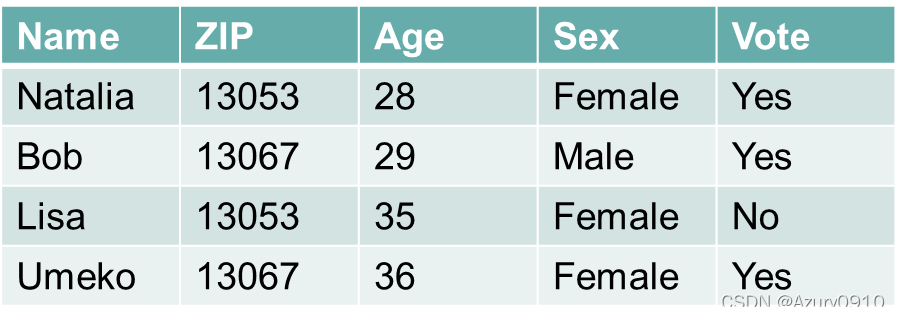
-
用户的位置、轨迹数据一般以点集的形式表示也属于结构化数据;
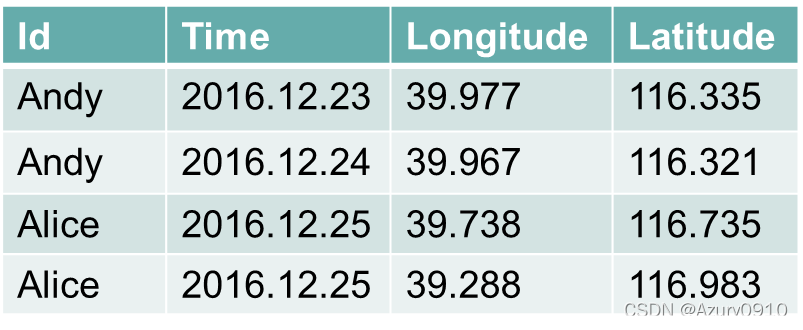
-
用户社交关系数据表现为相对复杂的网络关系,属于非结构化数据,一般用图结构表示。
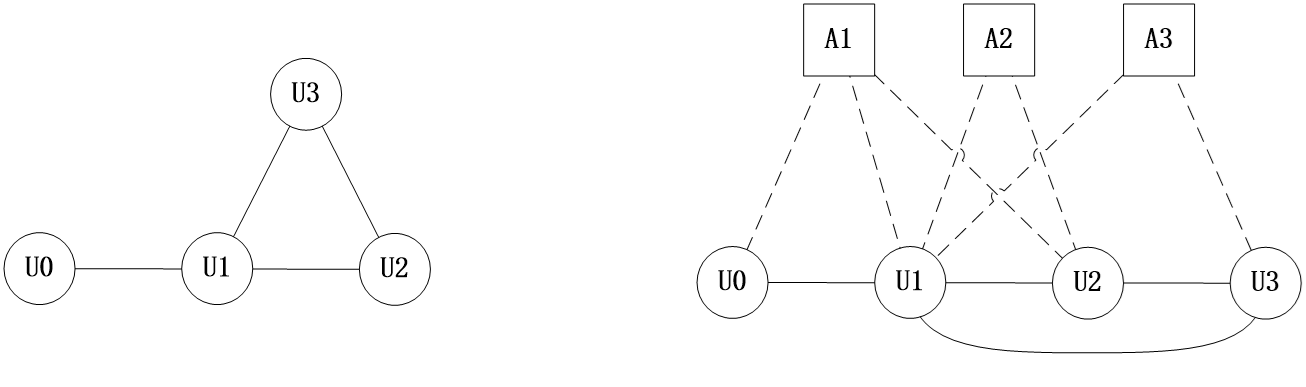
3 典型的隐私保护技术手段 @
典型的隐私保护技术手段包括:抑制(suppression)、泛化(generalization)、置换(permutation)、扰动(perturbation),裁剪(anatomy)等。此外,也有人通过密码学技术手段实现隐私保护。
-
抑制:是最常见的数据匿名措施,通过将数据置空的方式限制数据发布
-
泛化:是指通过降低数据精度来提供匿名的方法。属性泛化即通过制定泛化规则,使得多个元组的在规则下近似的取值相同。最深的属性泛化效果通常等同于抑制。社交关系数据的泛化则是将某些节点以及这些节点间的连接进行泛化。位置轨迹数据可进行时间、空间泛化。
-
置换:不对数据内容作更改,但是改变数据的属主。例如,将不同的个人用户的属性值互相交换,将用户a与b之间的边置换为a与c的边。
-
扰动:是在数据发布时添加一定的噪音,包括数据增删、变换等,使攻击者无法区分真实数据和噪音数据,从而造成干扰。
-
裁剪技术的基本思想是将数据分开发布。例如,将用户信息与敏感数据分别发布,同一组用户有同一个组标识符,其敏感属性也对应同一个组标识符。攻击者即使可以确定攻击目标的组标识符,但是无法有效的从具有相同组标识符的敏感数据中判定攻击目标对应的敏感数据。
-
密码学手段利用数据加密技术阻止非法用户对数据的未授权访问和滥用。
(二)关系型数据隐私保护
1 身份匿名:链接攻击、k-匿名
(1) 链接攻击与身份匿名
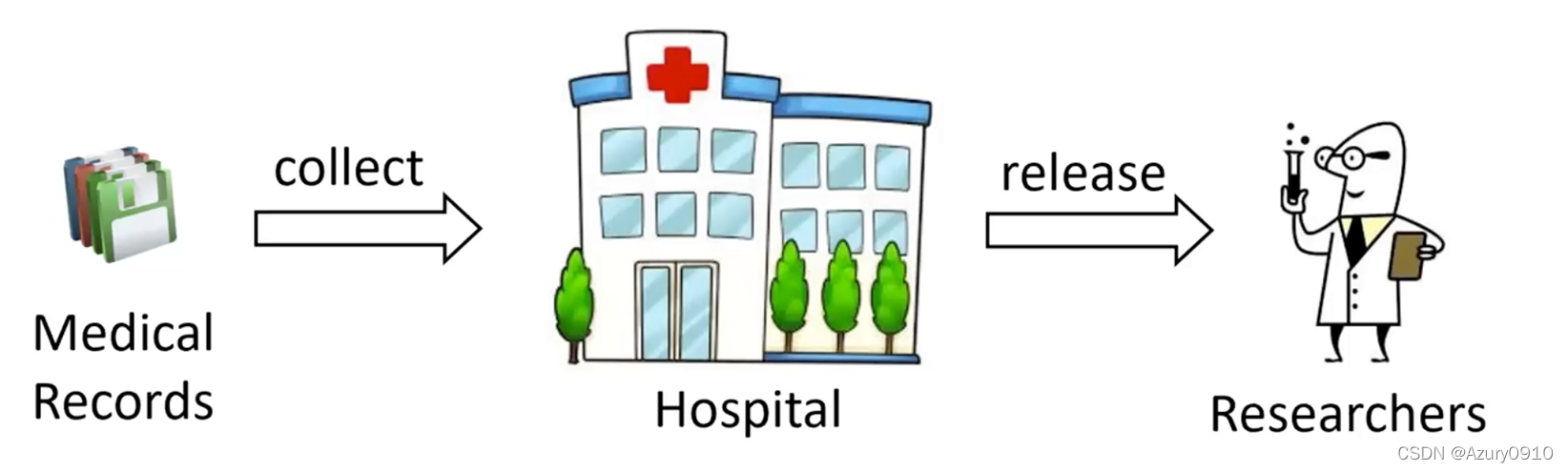
链接攻击带来身份隐私威胁
即便去除了表中的身份ID等标志性信息,攻击者仍可凭借背景知识,如地域、性别等准标识符信息,迅速确定攻击目标对应的记录。此类攻击称为记录链接(record linkage)攻击。
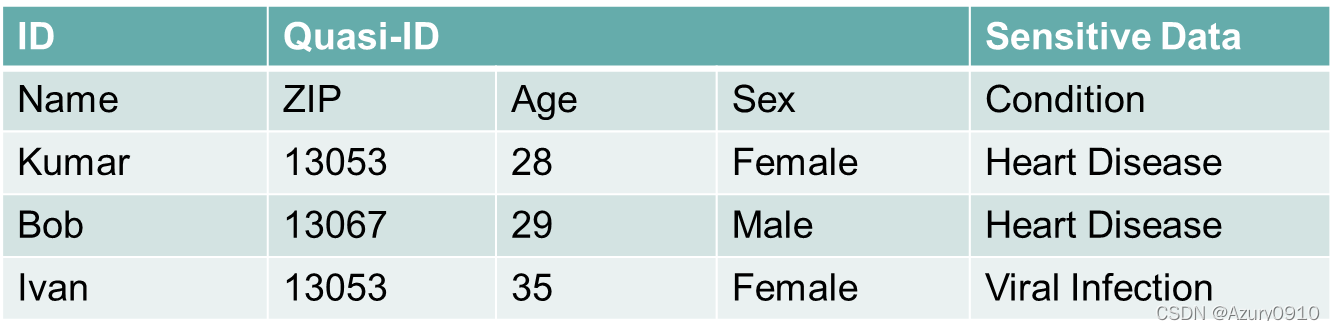
原始的用户医疗记录表中包含了Name这一标识符,简单删除标识符列得到匿名记录表。
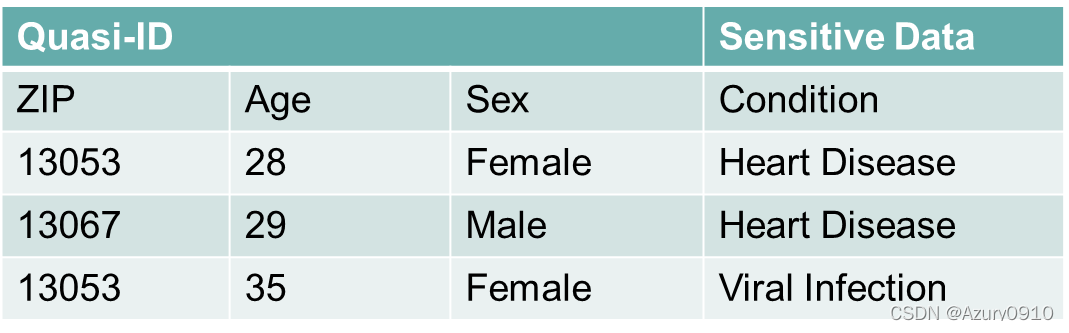
如果攻击者持有公开的选民记录表作为背景知识,与公开发布的匿名记录表对比,通过邮编、年龄等若干项属性信息,攻击者仍可以唯一地识别出某些用户。
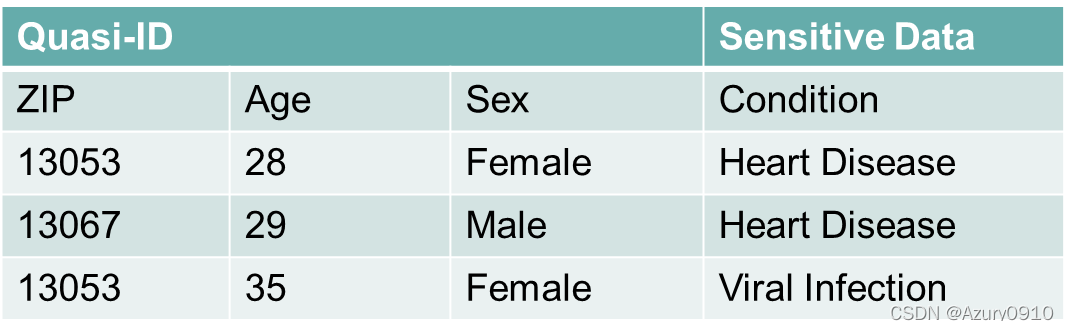
(2) K-匿名基本模型
为避免上述问题攻击者通过链接攻击从发布的数据中唯一地识别出特定匹配用户,导致用户身份泄露,Samarati和Sweeney最早提出适用于关系型数据表的K-匿名模型。
这一方案按照准标识符将数据记录分组,且每一分组中至少包含k条记录。这样,每个具有某准标识符的记录都至少与k-1个其他记录不可区分,从而实现用户身份匿名保护。
定义5-1 (K-匿名)
令
𝑇
(
𝐴
1
,
…
𝐴
𝑛
)
𝑇(𝐴_1,…𝐴_𝑛)
T(A1,…An)为一张具有有限行的表,属性集合为
𝐴
1
,
…
𝐴
𝑛
{𝐴_1,…𝐴_𝑛}
A1,…An。
𝑄
𝐼
𝑇
𝑄𝐼_𝑇
QIT为表中的准标识符
𝑄
𝐼
𝑇
=
{
A
i
,
A
i
+
1
,
…
,
A
j
}
𝑄𝐼_𝑇=\{A_i,A_{i+1},…,A_j\}
QIT={Ai,Ai+1,…,Aj}。表
𝑇
𝑇
T满足K-匿名,当且仅当每一组准标识符的取值序列在
𝑇
[
𝑄
𝐼
]
𝑇[𝑄𝐼]
T[QI]中出现至少k次。
f泛化可以通过将某个属性的值取“*”或“任意”来实现,例如ZIP编码可由具体的02138逐步泛化成0213*、021**、02***、0****、*****。出生年份可由具体的1965泛化为1960-1970、1950-1970等。
显然,泛化程度越大,对数据的破坏越大。
(3)K-匿名模型的局限性
然而,很多数据如用户购物历史、观影历史等都难以判断明确的准标识符信息。数据发布方无法准确界定那一条购买记录和用户评价信息是用户的准标识符信息,任何非特定记录都可能被攻击者用来重新识别出用户身份。
2006年Netflix的用户隐私泄露事件,就是由于公开的用户观影记录匿名程度不足,导致部分用户的身份泄露。Narayanan等人随后在08年的S&P会议上公开了他们利用IMDB数据库对Netflix数据进行链接攻击的方法。该论文直观地展示了k-匿名模型的不足。
该文定义了判定额外信息和待定用户之间相似度的方法:
S
c
o
r
e
(
a
u
x
,
r
′
)
=
∑
i
∈
s
u
p
p
(
a
u
x
)
w
t
(
i
)
S
i
m
(
a
u
x
i
,
r
i
′
)
Score(aux,r^{'})=\sum_{i\in supp(aux)} wt(i)Sim(aux_i,r^{'}_i)
Score(aux,r′)=i∈supp(aux)∑wt(i)Sim(auxi,ri′)
其中 w t ( i ) wt(i) wt(i)用于权重的定义,越稀有的属性权重越高。两个用户的加权相似性最高,那么他们就可能是同一用户的两个id。基于这个打分算法,Narayanan等人选取了IMDB数据集中的50个用户和Netflix公开数据集的用户进行了打分匹配,发现只要掌握少量的属性(5-10个非热门电影),就能识别出大量用户。
2 属性匿名:同质攻击、熵L-多样化、递归(c,l)-多样化、t-贴近
(1) 同质攻击
经过k-匿名处理后的数据集中,攻击目标至少对应于k个可能的记录。但这些记录只能满足准标识符一致的要求,而非准标识符数据和敏感数据保持不变。以观影数据为例,如果这k个用户的观影记录相同或非常接近,攻击者仍能够获得用户的观影历史,分析用户的隐私属性。例如,这k个用户都喜欢看海洋纪录片,那么攻击目标很可能是环保主义者。
在k-匿名的数据记录中,如果记录的敏感数据接近一致或集中于某个数据,攻击者也可以唯一或以极大概率确定数据持有者的属性。这类攻击称为同质攻击。
(2) L-多样化模型
Machanavajjhala等人提出了L-多样化(l-diversity)这一新的模型,要求在准标识符相同的等价类中,敏感数据要满足一定的多样化要求。
定义5-5(熵L-多样化) 如果对每一个泛化的 q ∗ q^* q∗条记录组,满足 − ∑ s ∈ S p ( q ∗ , s ) l o g p ( q ∗ , s ) ≥ l o g ( l ) −\sum_{s∈S} p_{(q^∗,s)} logp_{(q^∗,s)}≥log(l) −∑s∈Sp(q∗,s)logp(q∗,s)≥log(l),那么它满足熵L-多样化(Entropy L-diversity)。
其中 p ( q ∗ , s ′ ) = n ( q ∗ , s ) ∑ s ′ ∈ S n ( q ∗ , s ′ ) p_{(q^{∗},s^{'})}=\frac{n_{(q^{∗},s)}}{\sum_{s^{'} \in S} n_{(q^{∗},s^{'})}} p(q∗,s′)=∑s′∈Sn(q∗,s′)n(q∗,s)为 q ∗ q^* q∗记录组中敏感值等于 s s s的记录所占的比例。此基础上可以降低多样性的要求,并假设不会影响到用户隐私的属性可以公开,不将其作为敏感值进行保护。
定义5-6(递归(c,l)-多样化) 将每一个 q ∗ q^* q∗元组中用户敏感值按照出现的频繁程度降序排序,其出现次数分别为 r 1 、 r 2 … … r m r_1、r_2…… r_m r1、r2……rm,如果对每一个 q ∗ q^* q∗元组,存在 r 1 < c ( r l + r ( l + 1 ) + ⋯ + r m ) r_1<c(r_l+r_{(l+1)}+⋯+r_m) r1<c(rl+r(l+1)+⋯+rm),即最频繁的属性频率 r 1 r_1 r1不超过最不频繁的 m − ( l − 1 ) m-(l-1) m−(l−1)个属性的频率之和的 c c c倍,那么该表满足递归(c,l)-多样化(recursive(c,l)-diversity)。
(3)近似攻击与t-贴近性模型
L-多样化方案仅能保证敏感属性值(如:是否患病)的多样性,未考虑敏感属性值的分布情况。如果匿名后的敏感属性分布明显不符合整体分布特征,例如相较于人群平均值,该等价类的用户有更高的概率患某种疾病,这种情况也对用户隐私造成侵害。这种攻击方式称为近似攻击。因此人们进一步提出T-贴近(t-closeness)模型。
t-贴近模型要求等价类中敏感属性值的分布与整个表中的数据分布近似。一个等价类是t-贴近的,是指该等价类中的敏感属性的分布与整表的敏感属性分布的距离不超过阈值t。
一个表是t-贴近的,是指其中所有的等价类都是t-贴近的。
(三) 差分隐私
如果只发布数据的一些统计结果,能否保证数据的隐私安全?
如果进一步删除一些特殊值,或增加一些噪音呢?
[Dinur and Nissim, 2003]证明哪怕每个统计数据都有相当程度的噪声,只要有足够多的统计数据,总能通过线性规划重构出源数据中的大部分元组。
美国普查局用他们2010年所发布的一组统计数据试验了数据重构攻击,结果表明,他们能重构17%美国人口的数据。
为此,他们宣布将于2020年的统计数据发布中使用差分隐私。
作为一种不限定攻击者能力,且能严格证明其安全性的隐私保护框架,差分隐私保护技术收到了人们的广泛关注。
1 基本差分隐私:拉普拉斯差分隐私机制及证明 @
(1) 基本定义
定义5-33(差分隐私) 给定数据集
D
D
D和其相邻数据集
D
′
D^{'}
D′,如果一个隐私算法
f
′
f^{'}
f′(随机算法)满足
ε
\varepsilon
ε-差分隐私,那么对于
f
′
f^{'}
f′的任意输出
C
C
C,均满足
P
r
(
f
′
(
D
)
=
C
)
<
e
ε
P
r
(
f
′
(
D
′
)
=
C
)
Pr(f^{'}(D)=C)<e^{\varepsilon}Pr(f^{'}(D^{'})=C)
Pr(f′(D)=C)<eεPr(f′(D′)=C)
其中,任意和
D
D
D最多相差一条记录的数据集
D
′
D^{'}
D′均为
D
D
D的相邻数据集。【有且仅有一个属性不等】
ε
\varepsilon
ε表示隐私保护程度,对于给定的数据集和查询函数
f
f
f,其对应的隐私算法
f
′
f^{'}
f′的
ε
\varepsilon
ε越小,隐私保护程度越高。
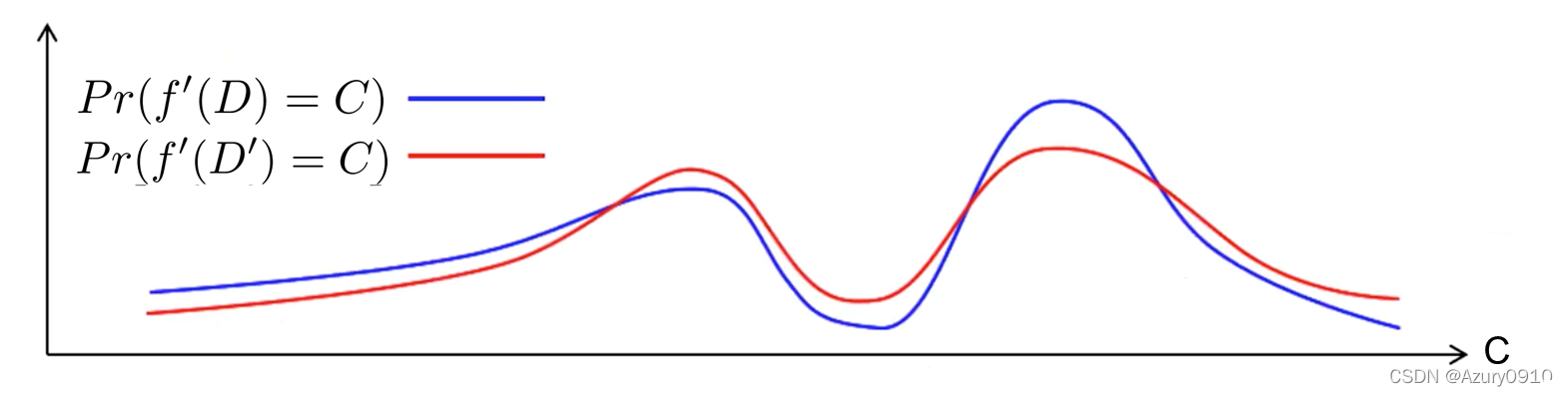
差分隐私能够达成两种效果:
- 首先,因为无论攻击者目标是否在查询数据集中,查询结果都基本保持不变,所以攻击者无法根据查询结果确认攻击目标是否在查询数据集中,也就无法实现链接攻击。
- 其次,这一安全目标有效地保持了数据可用性。无论单个数据记录加入或离开数据集D,对这一数据集的查询结果都基本保持稳定,也可以说保持了数据中有用的知识。
(2) 基本原理
拉普拉斯差分隐私机制
噪声机制是实现差分隐私的主要手段,可以采用拉普拉斯机制向查询结果中添加噪声,使真实输出值产生概率扰动,从而对数值型查询实现差分隐私保护。
p d f ( x ) = 1 2 λ e x p ( − ∣ x ∣ λ ) pdf(x)=\frac{1}{2\lambda}exp(-\frac{|x|}{\lambda}) pdf(x)=2λ1exp(−λ∣x∣)
实例:考虑对医疗数据进行查询,查询函数
f
f
f为统计数据集中糖尿病患的总人数。通过拉普拉斯函数对
f
f
f进行扰动得到
f
′
f^{'}
f′,具体来说,
f
′
(
D
)
=
f
(
D
)
+
L
a
p
(
λ
)
f^{'}(D)=f(D)+Lap(\lambda)
f′(D)=f(D)+Lap(λ)
P
r
(
f
′
(
D
)
=
y
)
P
r
(
f
′
(
D
′
)
=
y
)
=
P
r
(
f
(
D
)
+
L
a
p
(
λ
)
=
y
)
P
r
(
f
(
D
′
)
+
L
a
p
(
λ
)
=
y
)
=
P
r
(
L
a
p
(
λ
)
=
y
−
f
(
D
)
)
P
r
(
L
a
p
(
λ
)
=
y
−
f
(
D
′
)
)
=
e
x
p
(
−
∣
y
−
f
(
D
∣
λ
)
e
x
p
(
−
∣
y
−
f
(
D
′
)
∣
λ
)
=
e
x
p
(
1
λ
(
∣
y
−
f
(
D
′
)
∣
−
∣
y
−
f
(
D
)
∣
)
)
=
e
x
p
(
1
λ
∣
f
(
D
)
−
f
(
D
′
)
∣
)
≤
e
x
p
(
Δ
f
λ
)
\frac{Pr(f^{'}(D)=y)}{Pr(f^{'}(D^{'})=y)} = \frac{Pr(f(D)+Lap(\lambda)=y)}{Pr(f(D^{'})+Lap(\lambda)=y)}\\ = \frac{Pr(Lap(\lambda)=y-f(D))}{Pr(Lap(\lambda)=y-f(D^{'}))} \\ =\frac{exp(-\frac{|y-f(D|}{\lambda})}{exp(-\frac{|y-f(D^{'})|}{\lambda})}\\ =exp(\frac{1}{\lambda}(|y-f(D^{'})|-|y-f(D)|))\\=exp(\frac{1}{\lambda}|f(D)-f(D^{'})|)≤exp(\frac{\Delta f}{\lambda})
Pr(f′(D′)=y)Pr(f′(D)=y)=Pr(f(D′)+Lap(λ)=y)Pr(f(D)+Lap(λ)=y)=Pr(Lap(λ)=y−f(D′))Pr(Lap(λ)=y−f(D))=exp(−λ∣y−f(D′)∣)exp(−λ∣y−f(D∣)=exp(λ1(∣y−f(D′)∣−∣y−f(D)∣))=exp(λ1∣f(D)−f(D′)∣)≤exp(λΔf)
其中,查询函数的全局敏感度
Δ
f
{\Delta f}
Δf 的定义为
Δ
f
=
m
a
x
D
,
D
′
∣
𝑓
(
𝐷
)
−
𝑓
(
𝐷
′
)
∣
{\Delta f}=max_{D,D^{'}}|𝑓(𝐷)−𝑓(𝐷^{'})|
Δf=maxD,D′∣f(D)−f(D′)∣,
D
D
D和
D
′
D^{'}
D′为任意相邻数据集。
在糖尿病人总数统计的例子中, Δ 𝑓 = 1 \Delta𝑓 = 1 Δf=1。因此当 λ = 1 / ε \lambda = 1/ \varepsilon λ=1/ε时,可证明 f ′ f^{'} f′满足𝜀-差分隐私。
由拉普拉斯机制和差分隐私原理可推导出差分隐私的两个基本性质:序列组合性和并行组合性。
定义5-34(序列组合性) 序列组合性是指,给定数据库 D D D与 n n n个差分隐私函数 𝑓 1 , 𝑓 2 , ⋯ 𝑓 𝑛 𝑓_1, 𝑓_2,⋯ 𝑓_𝑛 f1,f2,⋯fn,每个函数的隐私保护参数分别为 ε 1 , ε 2 , ⋯ , ε 𝑛 \varepsilon_1,\varepsilon_2,⋯,\varepsilon_𝑛 ε1,ε2,⋯,εn,对于数据集 D D D,函数组合 𝐹 ( 𝑓 1 ( 𝐷 ) , 𝑓 2 ( 𝐷 ) , ⋯ 𝑓 𝑛 ( 𝐷 ) ) 𝐹(𝑓_1 (𝐷), 𝑓_2 (𝐷),⋯ 𝑓_𝑛 (𝐷)) F(f1(D),f2(D),⋯fn(D)) 提供 ∑ ε 𝑖 \sum \varepsilon_𝑖 ∑εi 差分隐私保护。
定义5-35(并行组合性) 并行组合性是指,给定差分隐私函数 𝑓 1 , 𝑓 2 , ⋯ 𝑓 𝑛 𝑓_1, 𝑓_2,⋯ 𝑓_𝑛 f1,f2,⋯fn,每个函数的隐私保护参数分别为 ε 1 , ε 2 , ⋯ , ε 𝑛 \varepsilon_1,\varepsilon_2,⋯,\varepsilon_𝑛 ε1,ε2,⋯,εn,对于不相交的数据集 𝐷 1 , 𝐷 2 , ⋯ 𝐷 𝑛 𝐷_1, 𝐷_2,⋯ 𝐷_𝑛 D1,D2,⋯Dn ,函数组合 𝐹 ( 𝑓 1 ( 𝐷 ) , 𝑓 2 ( 𝐷 ) , ⋯ 𝑓 𝑛 ( 𝐷 ) ) 𝐹(𝑓_1 (𝐷), 𝑓_2 (𝐷),⋯ 𝑓_𝑛 (𝐷)) F(f1(D),f2(D),⋯fn(D)) 提供 𝑚 𝑎 𝑥 ( ε 𝑖 ) 𝑚𝑎𝑥(\varepsilon_𝑖) max(εi)差分隐私保护。
2 本地差分隐私:Random Response方案、Rappor协议
特点:本地差分隐私(Local Differential Privacy,LDP)与差分隐私的最重要区别在于,本地差分隐私没有一个可信任的数据管理员(服务端不可信任),所以用户的真实敏感数据只会保存在自身的客户端上。
核心思想:用户先在本地将数据进行随机化处理,使其满足差分隐私条件,然后将其再上传给数据采集者(服务端),数据采集者得到添加扰动后的用户数据,经过无偏估计算法得到此所有用户的此类数据的估计值。
(1) Random Response随机回答方案
定义5-36( 本地差分隐私):一个随机化算法 A Α A满足 ε − L D P ε-LDP ε−LDP的条件是,在一个空间域中,对于任意的一对数据 l , l ‘ ∈ Z l,l^{`} \in Z l,l‘∈Z和任意输出 O ∈ R a n g e ( A ) O\in Range(A) O∈Range(A),都存在下列关系:
P
r
[
A
(
l
)
∈
O
]
≤
e
x
p
(
ε
)
⋅
P
r
[
A
(
l
‘
)
∈
O
]
Pr[A(l)\in O]≤exp(\varepsilon)\cdot Pr[A(l^{`})\in O]
Pr[A(l)∈O]≤exp(ε)⋅Pr[A(l‘)∈O]
其中 Random Response 可以看作是最基础的随机化算法A。该协议最早应用与调查问卷,调查问卷中询问用户是否具有某敏感属性如个人信仰、严重疾病,用户只用回答:“是”或者“否”。
协议内容为:
- 调查问卷中询问用户是否具有某属性,候选答案为二选一:“是”或者“否”。
- 此时用户随机扔一个硬币。如果朝上,那么选择如实回答问题,如果朝下,那么选择随机回答问题。
随即回答可以理解为用户可以再扔一次硬币,正面朝上时回答是,朝下时回答否。
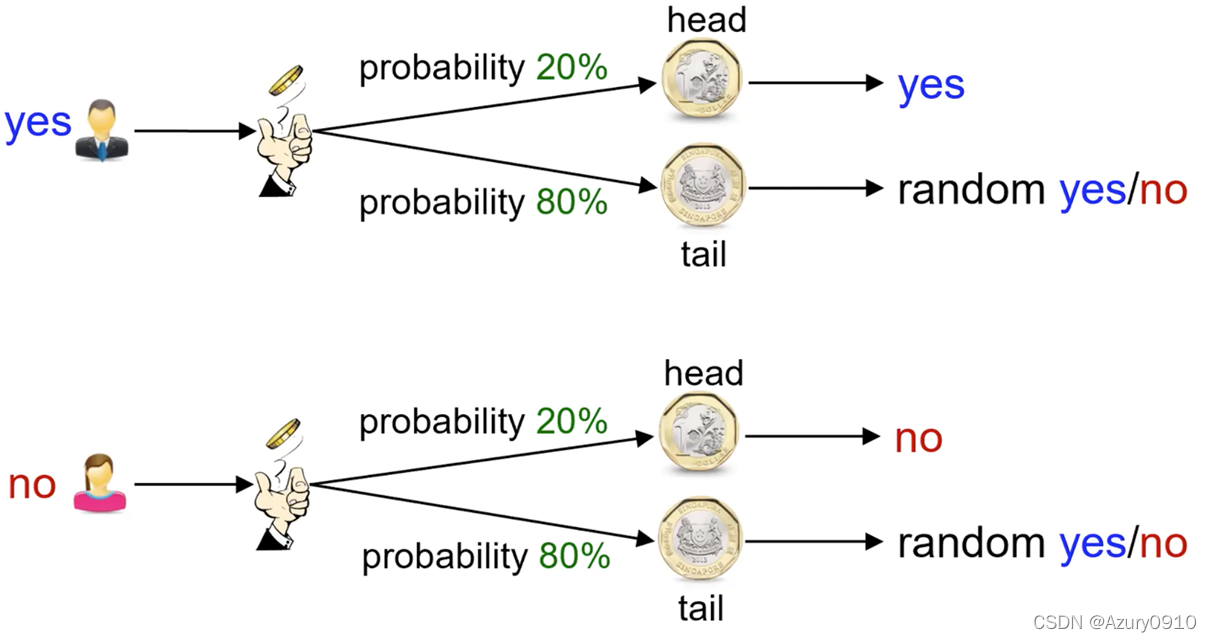
这种随机化回答由于其随机性,攻击者不能从随机输出的是否回答中反推出真实的输入是yes还是no
与此同时,依然可以通过回答得到一些聚合问题的答案,例如:在真实回答中,大概有多少人的回答是yes?
假设有10000人参与了随机回复,其中5500人回复yes,4500人回复no。由于有80%的回复是假回复,所以其中假的yes和no各有4000个。因此在真实回复中大概有1500个yes和500个no。因此在真实回答中,大约有75%的人回答是yes。
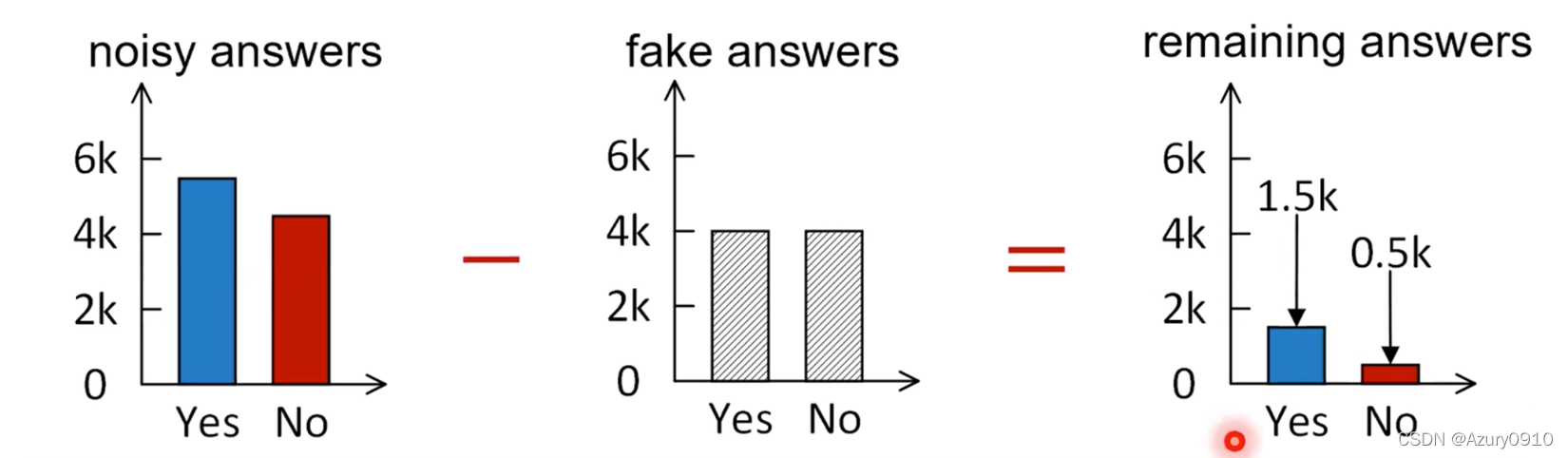
(2) Rappor协议
Rappor协议由Google开发,是一种基于RR协议的用户选项采集统计方法,基本协议包含两部分:
- 一部分是发送在用户终端的本地数据随机化操作
- 另一部分是数据采集者对采集到的噪音数据进行分析处理。
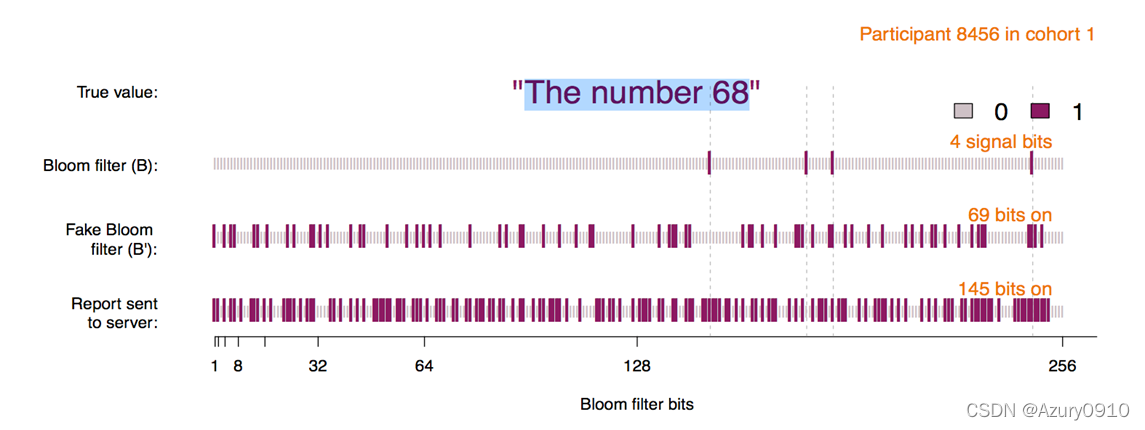
3 ?基本差分隐私和本地差分隐私的区别、拉普拉斯/RR/Rappor协议应用场景的区别
- RR/Rappor协议是基本差分隐私方案,需要中心节点获取全部数据【先汇总再弄脏】;RR/Rappor协议【先弄脏再汇总】
- RR/Rappor协议解决数值型数据,RR回答的是两分类问题;Rappor协议解决的问题更为广泛。
第六章 区块链技术
(一)背景常识
比特币鼻祖:中本聪
比特币与区块链的关系:比特币是区块链的一个应用,区块链是比特币的底层技术。
(二)Hash编码、数字签名
- 计算哈希值的对象
- 上一个区块的hash
- 区块体(账务往来)
- 随机数
- 哈希值的要求
- 64位的16进制串
- 前若干位是0,或等价地,hash<E
- 0x00000000FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
要求上一个区块的Hash值和这个区块的内容加上一个随机数拼接而成的,前若干位是0
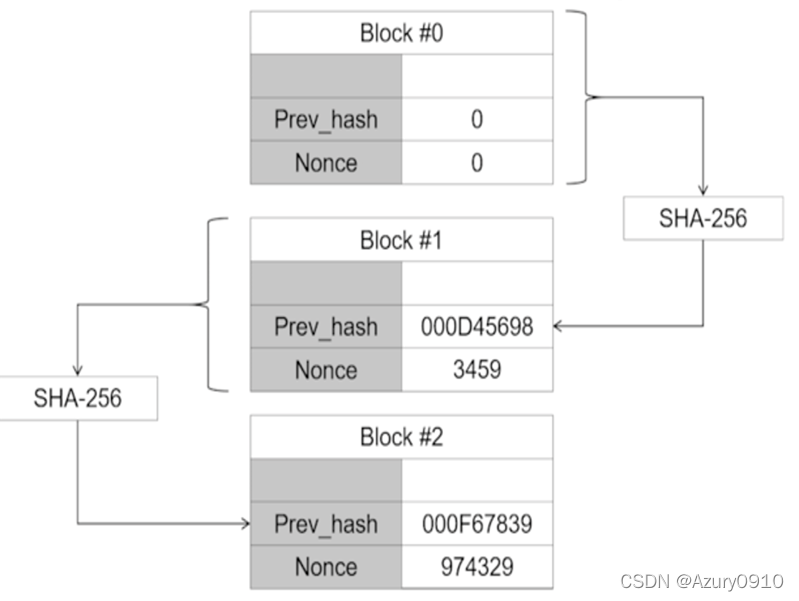
区块链中的每个参与者都需要有自己的公私钥对,其中公钥就是用户地址。
张三通过签名函数Sign(),使用自己的私钥对本次交易进行签名,任何人都可以通过验证函数Verify(),来验证此次签名是否由持有张三私钥的张三本人发出的,从而保证其抗抵赖性。















 3961
3961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









