







在2019年11月1日上午的北京智源大会“脑科学与AI专题论坛”中,北京大学信息科学技术学院长聘教授吴思为我们分享了题为《视觉信息处理的闭环》的主题演讲,从计算神经科学的角度阐述了其团队目前在类脑智能视觉信息处理方向所进行的最新研究。
吴思的报告深入浅出,从人工智能、认知科学、认知神经科学及计算神经科学四个不同角度揭示了视觉信息处理同时激活两条通路的机制:
在人类的众多本能行为中,视觉信息处理通过皮层下通路首先将信息传递到上丘,进而传递到高级皮层,皮层下通路可以快速识别物体的全局信息,人脑能够根据已有的先验知识(记忆、经验等)对下通路中传递的模糊信息进行快速猜想,皮层上通路同时进行速度较慢的局部信息精细提取,两条通路的信息相互融合,将猜想内容反复迭代认证后得出最终的决策,形成闭环。
吴思强调,虽然已有众多科研成果支持“视觉信息处理的闭环”理论,但很多核心问题亟待解决,最后他运用三个实例向我们展示了其当前的研究方向及重心。下面是吴思演讲的精彩要点。
01
“视觉信息处理的闭环”
成立的可能性推演论证
目前,人工智能的核心技术--深度学习正以势如破竹之势突破了许多经典的难题。原理上,深度学习主要模拟了生物视觉腹侧通路前馈信息从简单到复杂的加工的过程,但是真正视觉神经的工作原理要比这个复杂很多。

图1 熊的视觉识别
上图中,图(a)是将局部信息去掉,只保留了全局轮廓的一只熊,人类观察可将其识别到。图(b)是把熊的图片进行切割并且打乱顺序后重新组合形成的,这张图片相信很多人是无法识别出熊的,但是深度学习可以识别出这只熊。这个实验很有力的说明了深度学习更侧重识别图中的局部特征信息。
这个实验引出几个问题值得思考,首先深度学习它的确能够识别物体,但是与我们人类的识别的机制相差甚远。我们每日处理的相当于一个连续不断的视频流,因此信息量是相当巨大的,如果也如同深度学习一样将所有需要的局部信息都完整的提取,那么人脑这个CPU将会超负荷工作。而实验中图1(a)启发我们,视觉神经更多时候主要识别的是全局信息(例如:global shape)。接下来,吴思从四个不同学科角度,来分析视觉信息是否存在处理闭环。
I. A Story from Artificial Neural Network
我们在识别物体全局,如拓扑信息时,前馈神经网络的表达并不很理想。吴教授认为,可能的原因在于网络中的pooling层,会使得网络表达丢掉local patch之间的空间关联信息,如果层层迭代下去,那么全局特征将会丢失非常严重。这也能比较好的说明上述的实验中,将熊的图片切割重排,全局信息已经完全丢失的情况下,深度学习仍然可以识别到熊。
II. A Story from Cognitive Science
我们到底对一个物体出现的识别是从local到global,还是global到local?如果我们从皮层上通路去看的话,实际上我们像深度学习一样,对物体特征的分析是从local到global逐步变复杂,但是我们认知却是一个反的过程,我们是从global到local。陈林院士提出了“Global First Theory”:视觉系统更敏感于物体的拓扑差异,也就是说人类第一步感知的是物体最具有不变性的拓扑结构,并且人对其反应是最快的,准确率是最高的,如下图2中对“有洞”或者“没洞”的识别;相反,我们人对于物体的形状等其他信息的错误率会提高,反应也会变慢,如图2中对几何图形的识别。

图2 视觉系统反应的拓扑差异
III. A Story from Cognitive Neuroscience
认知神经科学认为,人脑的视觉系统有两条通路(如图3),一条通过皮层上通路经过层层特征提取识别物体,另外一条通过皮层下通路,从视网膜直接到达了上丘,然后再到高级皮层。

图3 人脑视觉的两条通路
图4左侧展示了皮层上通路信息处理的基本耗时:眼睛会看到橘色和绿色其中之一的颜色,做出决定后按下颜色相应的按钮。从图中不难看出:光信号转化成电信号,电信号层层传递,最终按下按钮的时间约为250毫秒。在右图中,我们将老鼠放置在箱内,并且在箱子上方投射由小变大的黑影,老鼠在看到黑影变化后以为是俯冲而下的老鹰,因此迅速装死,这个时间要远小于250ms。我们生活当中有些动作也是非常快的,而这部分本能行为,神经科学发现不是通过皮层上通路,而是通过皮层下通路处理。
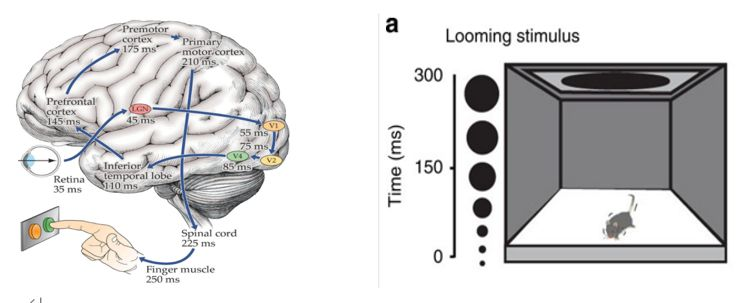
图4 认知神经科学的两个实验:人脑和老鼠脑
人工智能模拟大脑的智能,是模拟大脑通过长期进化、不断优化后在脑中形成的算法、结构等,这部分更多的是本能行为,而不是后天我们学到的技能(比如逻辑推演等)。因此人工智能的算法设计更应贴近于大脑皮层下通路的信息处理过程。
IV. A Story fromComputational Neuroscience
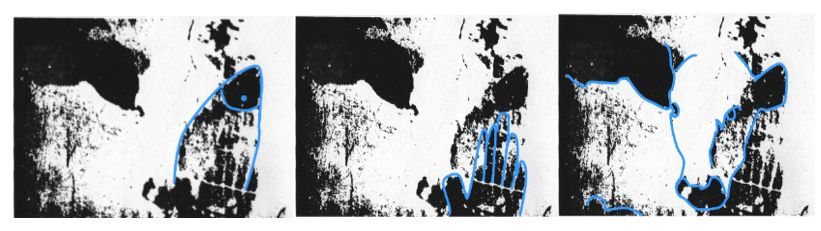
图5 “所想即所见”:图像识别的神经反馈
我们看到,图中究竟是手掌、鱼还是牛,相信“一千个人有一千个哈姆雷特”,这就是目前计算机视觉没有真正解决的图像理解问题。目前深度学习所做的是图像分类,也就是预先给出了类别,再做判断。但很多图像的理解实际是随着场景变化的,那么人脑是如何解决这个问题的呢?神经生物学大量实验证明,人脑在理解场景问题的过程类似猜测-印证的不断迭代。实验数据也表明在视觉通路中,反向连接比正向连接还多。
从上述四个不同学科给出的证据中,吴教授大胆猜测,生物视觉信息处理是一个闭环,其大体的步骤可能如下:
1.皮层下通路会快速提取物体的全局特征(例如:拓扑结构、轮廓等);
2.大脑将全局特征与个人先验知识(比如经验、记忆等)融合后,对观察到的物体做出了大胆的猜测;
3.与此同时皮层上神经通路也在进行信息处理,这条通路正在缓慢的进行局部特征的提取和传递;
4.皮层上神经通路得出的结果和反向传播的皮层下神经通路得出的结果进行交叉融合验证,最终完成视觉信息感知。
02
“视觉信息处理的闭环”
亟待解决的核心科学问题
由此我们大体知道了视觉信息处理闭环的工作流程,那么问题来了:在皮层下通路大脑是如何进行信息传递的?为什么人脑可以如此快速的感知到物体的全局特征?前馈和反馈神经计算得出的结果又是如何进行交互和融合的呢?人脑中所谓的“先验知识”又怎么运用或表达到算法中?这也是吴思和他的团队正在解决的问题,他在本次讲座中为我们分享了三个初步结果。
第一个例子,A retina-SC model for topologyperception
近年,生物学家发现皮层下通路上有一种特殊的神经元,叫做视网膜特化感光神经节细胞(ipRGCs)。这种神经元有三个很特别的性质:
1.它能表达黑视素蛋白(由Opn4基因编码),这是一种在ipRGCs的胞体和树突上均有分布的膜蛋白,它具备直接对光产生反应的能力,因此反应速度非常快;
2.神经元的连接是通过电突触而非化学突触,也就是说如果大量的神经元接受了同样的光强,那么这批神经元会立刻同步化;
3.神经元的传递过程服从动力学原理,通过动力学传递过程迅速感知拓扑结构的连通域。

图6 “有洞”、“没洞”拓扑图的识别
这样我们基于一个连接了上述神经元的电突触网络,就能解释视觉识别拓扑图中有洞、没洞的现象:对于圆,首先中间的黑斑全部同步化发亮,边缘信息进入抑制状态发暗,之后是背景同步化发亮;对于环,首先是环上黑斑同步化发亮,同时环上边缘神经元进入抑制状态发暗,之后是背景同步化发亮,最后是环内的小圆同步化发亮。
第二个例子,A reservoir decision-makingmodel for motion pattern perception
模型模拟皮层下通路大脑工作过程中发现,通路中主要有两个模块,第一是Reservoir Module:解释这个模块,我们可以引入比较典型的例子--步态识别。众所周知,在步态识别的过程中,空间信息和时间信息的变化是耦合的,如何解耦使得问题更简洁呢?Reservoir Module给出的方法是将不同的时空运动模式投影到高维空间中,使得对于不同的时空模式产生不同的空间活动状态。第二个模块是Decision-makingModule:由于时空的模式定义是来自于它在空间连续的变化,所以我们需要一个机制,希望随着时间的推移,时空的信息可以不断积累(Accumulating Evidence over Time)。Decision-makingModule提供了上述所需要的机制,该模型的神经元不断的接收时空信息,直到累计的信息足够进行判断时,将得出的结论发放,同时抑制其他的神经元。Reservoir Decision-making model即是将两个模块进行连接,并将该模型运用到具有时空耦合变化的识别过程中。
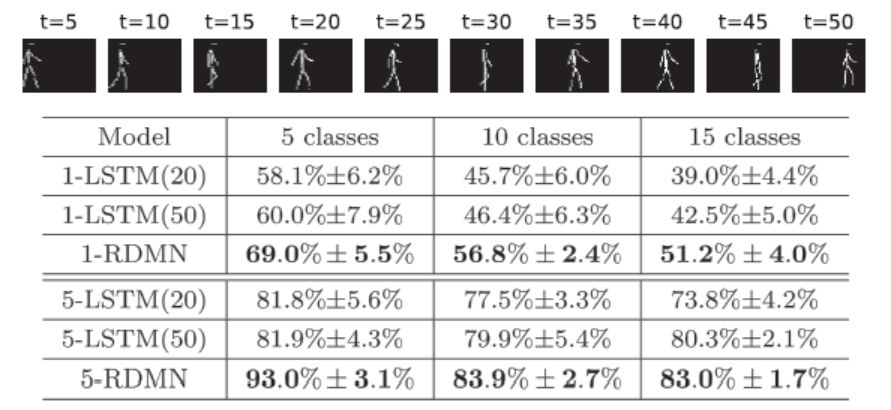
图7 Reservoir Decision-making model与LSTM 的实验比较
如图7所示,实验证明,步态识别在小样本的情况下,Reservoir Decision-makingmodel 的识别精度高于LSTM。
第三个例子,Neural feedback implementsreverse hierarchical information retrieval
实验数据表明神经作用的反馈过程是动态的,是一个先正后负(Push-Pullfeedback)的反馈调节,这样的反馈机制的目的是什么,在人工智能中是否可以迁移使用?吴教授及他的团队对此做了一些探索工作。
首先,我们不妨考虑人脑一般在做识别的过程,如果有一堆猫和狗的图像,我们想识别某一只猫的种类。那么我们首先是识别图像中的动物是否是猫,那么猫的图片反馈是正反馈;第二步是把猫的平均信息去掉,保留后的信息就会将不同猫之间的细微差别放大,该反馈是负反馈;这样,通过正负反馈后识别出了猫的种类。因此,我们可以理解为Push feedback可以放大不同类别的差异性,而Pull feedback可以放大同类间的差异性。如图8所示,当我们首先使用ImageNet进行预训练,使用VGG进行识别,样本为九种猫和九种狗,实验结果显示整个识别过程中,加入Push-Pull feedback网络的表达精度显著提高。
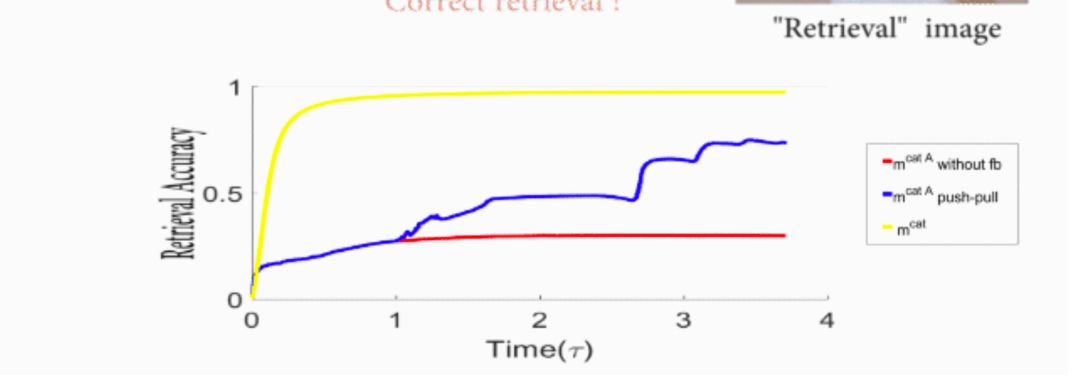
图8 加入Push-Pullfeedback网络的表达精度
正如吴思在演讲中所言,计算神经科学是脑科学和人工智能的桥梁,是用数学建模阐明大脑的工作原理,是发展类脑智能信息处理的必不可少的研究方向。通过吴思所做的研究,我们可以窥见这一学科在脑科学和人工智能研究领域的巨大发展潜力。虽然目前“视觉信息处理的闭环”理论尚有若干问题亟待解决,但这一理论的提出无疑为该领域在类脑视觉认知方面的探索提供了重要的启示和方向。通过将视觉信息处理认知过程迁移到深度学习领域,对神经网络的结构和反馈机制进行改进,将有力推动类脑人工智能的发展。
- 往期文章 -





↓ 点击"阅读原文"加入「智源社区」


















 16
16

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









