







算法在哪个领域起源再向其它领域迁移,在过去十年间发生了巨变。
计算机视觉在研究的领域曾经一直是研究最前沿,最新的算法从视觉领域产生,然后再转移到语音、NLP和其他的领域。自从Transformer诞生之后,风水轮流转,变成everything comes from NLP,新算法再慢慢转移到视觉。但是今年的状况有变化,自从年初Sora出现之后,计算机视觉似乎又要重回第一赛道。因此本次视觉大模型会场主题是,计算机视觉在技术领域是否又重新回到第一赛道?
6月15日上午,智源大会「视觉大模型」专题论坛如期举行。本次论坛由智源学者、昆仑万维2050全球研究院院长颜水成,南开大学教授程明明担任论坛主席,邀请到了潞晨科技Open-Sora负责人申琛惠、生数科技CTO鲍凡、独立研究者李俊男等该领域的头部研究者,共同交流视觉大模型领域的最新研究成果和实践经验。(回放链接:https://event.baai.ac.cn/live/798)
潞晨科技申琛惠:Open Sora高效低成本视频生成模型

什么是Open Sora
OpenAI Sora目前没有公开的版本,一方面说明Sora大视频的技术并没有完全成熟,另一方面消耗的成本非常高昂。这种封闭的状况导致目前不能对它的应用场景或者模型做进一步的拓展,因此我们开发了Open Sora这个模型。该模型是根据OpenAI Sora报告中的一些技术做的类Sora模型,主要目标是用低成本完全开源的方案,把它的模型引入社区。
Open Sora技术解析
1.模型架构设计及Open Sora应用原理
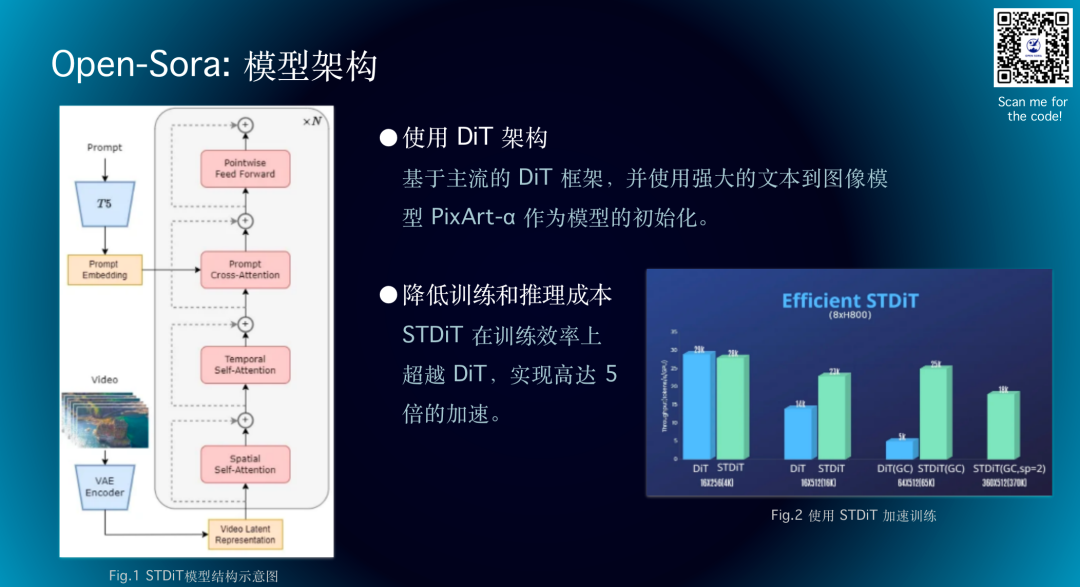
采用了基于主流的 DiT 框架,用PixArt-α作为模型初始化。左图是第一个版本的模型架构,在空间的自注意力后面多加了一层时间的自注意力机制,通过将空间和时间进行分开处理,可以大幅度降低模型的成本。右图是我们对于DiT和STDiT架构进行测速,随着Token数量增加,STDiT在吞吐量上有非常大的优势。
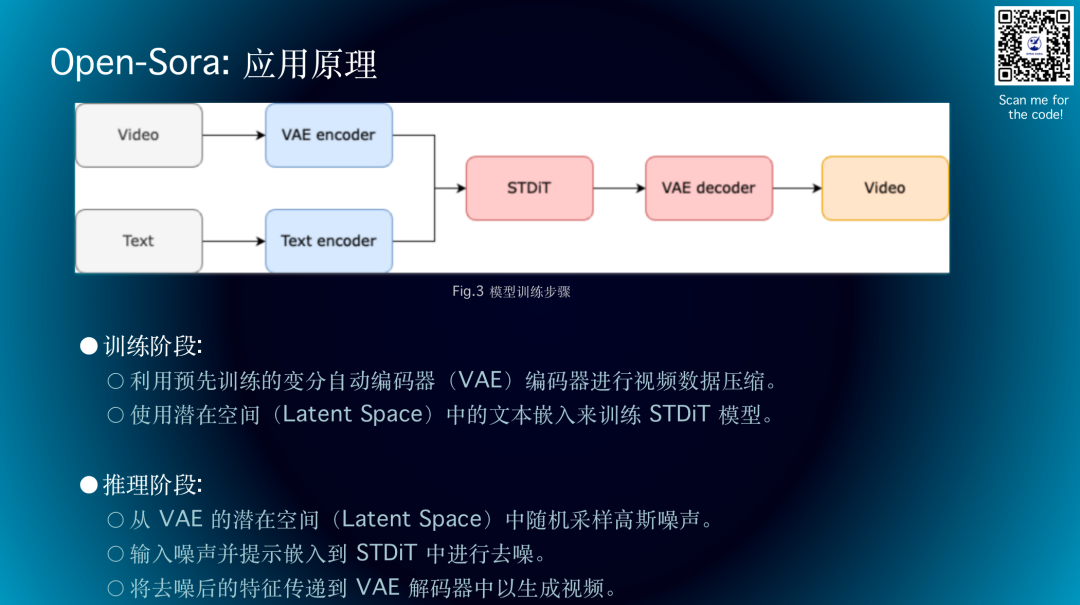
Open Sora根据Sora的技术报告,采用类似的过程生成视频。
2.类Sora训练方案
Sora的方案训练成本推测是数千万到数亿美元,我们的目标是要将成本控制在1万美元左右。

我们直接利用已有的文生图模型和Stable Diffusion空间上面的VAE降低训练成本。

第一个版本经过2808 GPU小时的训练,成本大概是7000美金。文生图模型之前已经有了一定的special self attention的能力,我们新引入的temporal self-attention需要完全从头训练,目标是一起进行训练以后,让两者都可以达到更高的水平。虽然大模型不同框架上的学习能力不太对等,但是也可以通过速的学习,达到水平的快速增长。

在数据方面,与第二阶段中视频源的主要区别是,视频的质量更高、时长更长。在模型方面,我们借鉴了Transformer的掩码策略,使得模型的应用更加灵活。并且采用了分统训练的策略,以支持不同时长、分辨率、宽高比、帧率的训练。
3.数据预处理
我们的数据总量非常大,大概在100TB的样子,对于存储而言是非常大的挑战。在数据的收集过程中,会对输入视频进行场景检测,分割城不同短视频对质量打分,再做标注和检测。其中出于成本考虑,标注部分采用的是开源的LLaVA1.6。
Open-Sora计划在生成视频的质量与时长上,做进一步的优化,内容上将完善生成人类的内容,提高视频的美学质量。
提问
提问:第一版本模型是用2D VAE训练,但是现在V1.2的时候,相当于用3D VAE训练的,这个过程中checkpoint的natural space会发生改变,在继续进行训练的时候有没有什么技巧?
申琛惠:有论文指出Diffusion模型对于VAE adaptation非常快,因此在我们最新版本的VAE训练中,是将已有的模型与新训练的VAE进行混训。由于没有太多的计算资源做很多的实验,因此我们的策略是将论文中提出觉得不错的方法,直接投入到训练当中。
生数科技CTO鲍凡:高保真4D重构模型Vidu4D

Vidu的技术路线

U-ViT是两年前4月份开始做架构,比OpenAI还要早发表3个月左右,全球首个 Diffusion Transformer 融合的架构,两者思路一致。
所有输入不作区分对待,统一处理为toke,输入到不作任何改变的Transformer架构中,因此任取一个Transformer,就可以在很短时间内转为Diffusion Transformer,实验表明,这种简洁的设计效果也是非常好的。
在做Vidu之前,我们已经有了UniDiffuser的工作,当时想把架构做成多模态统一的生成式建模,完成模态之间的转换以及模态的独立或联合生成。这个架构只对扩散模型本身的formulation做一些小的改动,即从一个单模态的输入变成双模态的输入,将单模态的时间拓展为双模态的时间,并同时预测模态上面噪声,恰好UViT非常适合处理这样的任务。
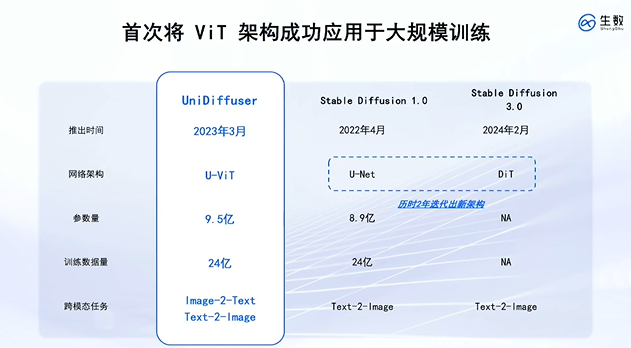
当时的架构能够对标Stable Diffusion,无论是数据量还是模型的参数量上,首次验证纯Transformer的Diffusion能够有非常好的图像生成的效果。

利用Diffusion的架构在更高质量数据上学习的效果。该架构也支持多分辨率的生成,无论竖屏横屏还是美学多元的风格,都能够非常好的掌握,是在工业界实验中充分论证有效的架构。并且这种架构有非常好的语义理解能力,能够把所有prompt中每个细节都刻画到。

基于这种架构,可以在上面去搭一些3D的东西,如文生3D、图生3D和贴图生成。除了图像的模态外,也有很多3D和4D的工作,给任意一段真实视频,可以把物体4D的表示提出来并做任意的编辑,例如替换视频中运动的主体,从任意角度对它做渲染。除了编辑4D的物体外,也可以编辑场景,例如增加或者删除物品。
上图为生数科技在生成式建模上的研究成果,还是有比较充足的耕耘,基于此,近期的Vidu能够支持32秒的视频。

此外能在视频基础上加入音频模态,目前既可以视频到音频,也可以文本到音频,后期会探索视频与音频的联合生成。
视频生成模型因其生成的帧真实且有想象力而受到特别关注,这些模型还被观察到表现出强烈的3D一致性,显著增强了其作为世界模拟器的潜力。
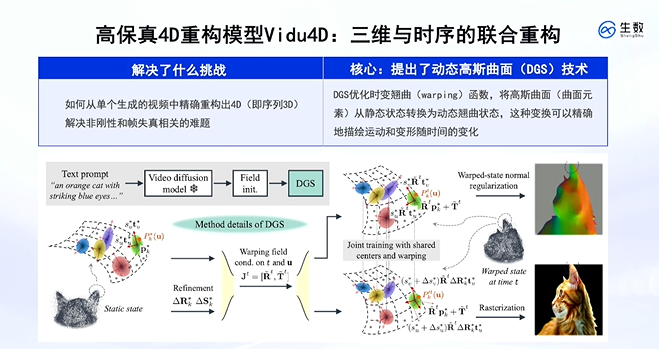
我们在此称带有时序信息的3D表示被称为4D,提取视频的4D表示核心技术是“动态高斯曲面”,高效提取连续帧的表示,可以采用首帧3D表示加其后每帧的变化量(warping)来代表。
基于像素重构和正则化的两个loss,可以对3D的视频做重构,进而能对4D做任意的一些编辑,例如放到游戏引擎中做一些手动的操作,再进一步可以渲染得出新的形态。

从Vidu 4D的工作里面看到,这种视频大模型有作为世界模型的潜力,将世界上各种物理规律模拟出来,后续再结合3D或者4D的技术,提取出具体物理规律的相关表示。
生数科技的自研多模态大模型
提问1:长期来看,4D重建和4D生成有多大意义?模拟世界的建议有多么重要?
鲍凡:世界模型是很重要的事情,目前有两条路:一条是通过大语言模型,先去把抽象的知识构建好,再把它拓展成世界模型;另一条是把这种物理规律构建好,拓展成世界模型。这两条道路目前都是探索状态,我认为两个方向都可能收敛成最终的世界模型。
提问2:与Vidu 4D生成部分的关联在哪里?
鲍凡:Vidu 4D把视频背后的4D表示提取出来了,将表示放入到已经用代码制定好物理规则的工业管线中,这就是非常好的可以用于训练智能体的强化学习场景,Vidu 4D相当于提供了模拟环境,便于后续提供有意义的反馈信息。
提问:您这边看到最大的应用场景是什么?
鲍凡:在短期内最直接的应用是取代相机的多视角拍摄,例如在影视行业中,多人物对话的时候,自动生成出任意的相机角度,而不用在不同人物间来回切换。
独立研究者李俊男:多模态模型的发展

我们最早做的工作——ALBEF,相当于是第一个基于Transformer多模态的encoder。随后的BLIP,把encoder转成既可以做理解,也可以做图像到语言的生成。之后的BLIP-2是在GPT-4出来之前,是第一个可以做Zero-Shot基于大语言模型多模态的大模型。

大模型预训练时有三个挑战:其一,如何将语言和视觉这两种模态对齐到一个模型中?其二,如何从有噪音的数据中学习?其三,如何节省计算资源?
VIT把Transformer结构引入到视觉领域。之后的CLIP用的是现在还被广泛使用的Transformer视觉编码框架,这个框架下,图片和文本各自在单独的空间。
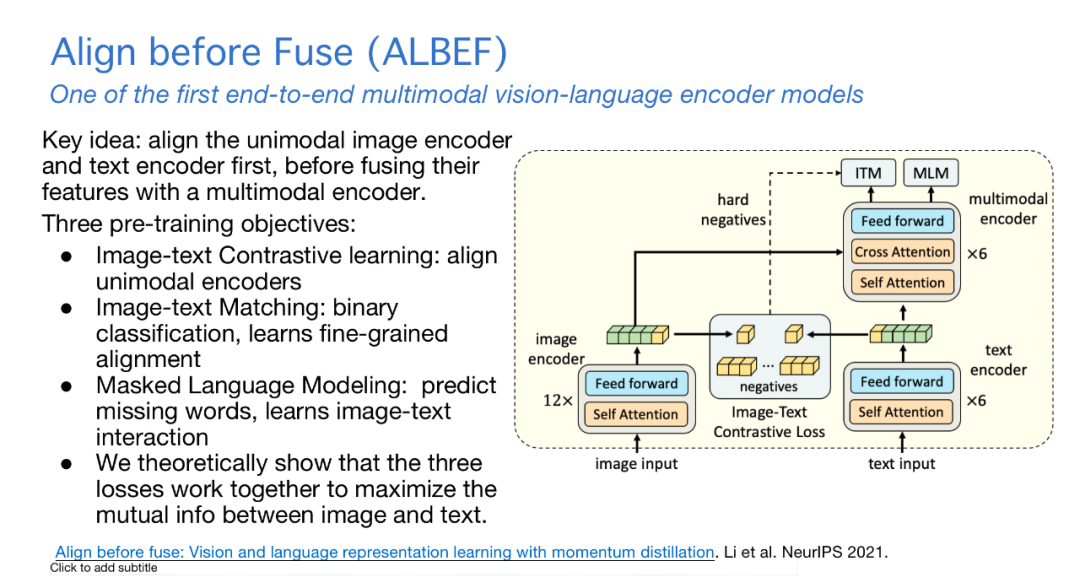
我们提出了ALBEF工作,首次将图片和文本编码到同一空间中进行Transformer,有三个训练目标,一是将图片与文本对齐的二分类任务;二是将特征进行编码,将图文信息进行融合;三是基于bert的多模态掩码模型,让图片和文本共同预测被掩盖掉的词。经证明,这三点可以共同最大化文本和图像之间的互信息,得到很好的多模态融合效果。
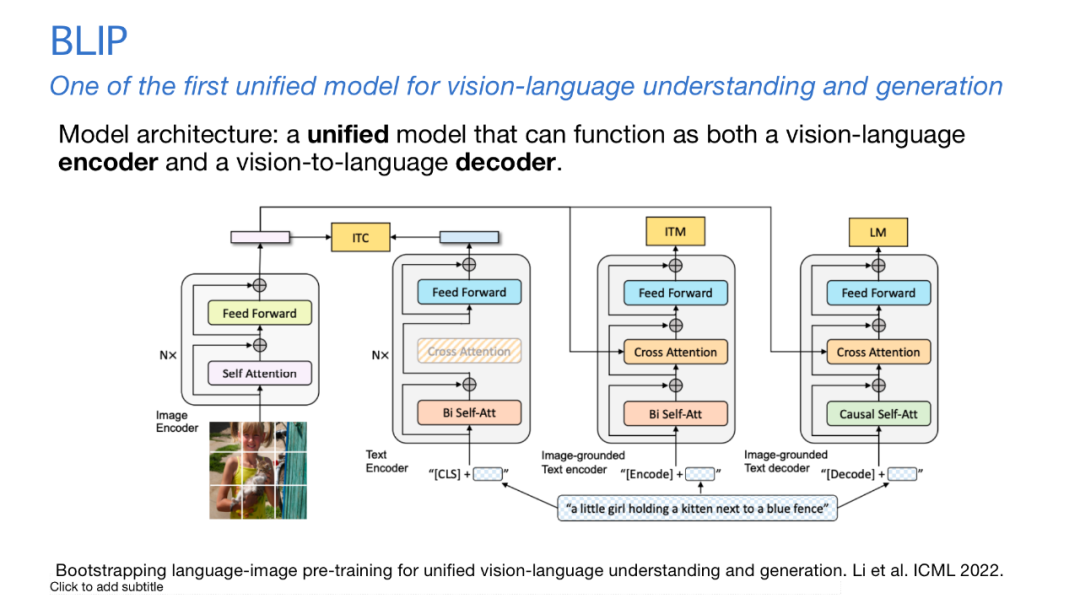
思路一脉相承下去有BLIP的工作,同样是三个loss,只是掩码的语言模型改成了自回归。数据处理过程,是用筛选模型挑出高质量的人工图片描述,反复迭代得到更好的描述器和筛选器。过程中我们发现,需要保证足够的数据多样性,才能对模型的训练起到较强的正面效果。
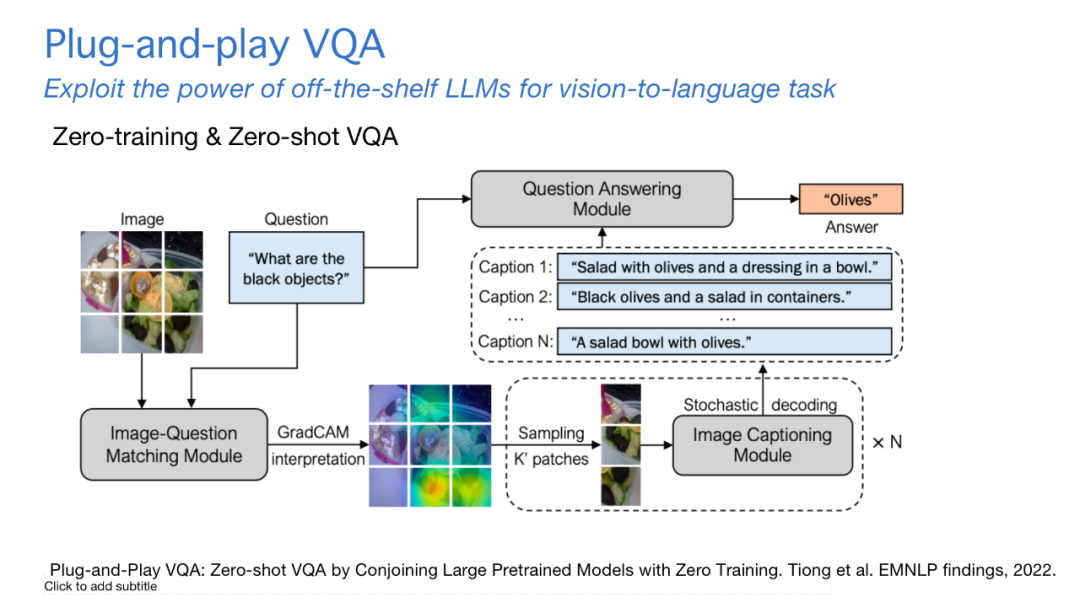
在BLIP工作之后,大语言模型就迎来一波比较关键的发展,其中GPT3是最关键的模型。思考怎么利用这种大语言模型增强多模态模型的能力,我们有了第一篇工作Plug-play VQA,直接把图像的信号转化成语言的信号,让语言模型理解。这里比较关键的技术,是会根据用户提出的问题,找到最相关的图片区域,采样这些区域从而生成一些和问题最相关的caption,首次验证了大语言模型在多模态理解里面的力量。
BLIP-2直接把视觉的模型和大语言模型的模块连在一起,这里BLIP解决了四点关键的挑战,并且算法高效,只需要16张A100的卡。
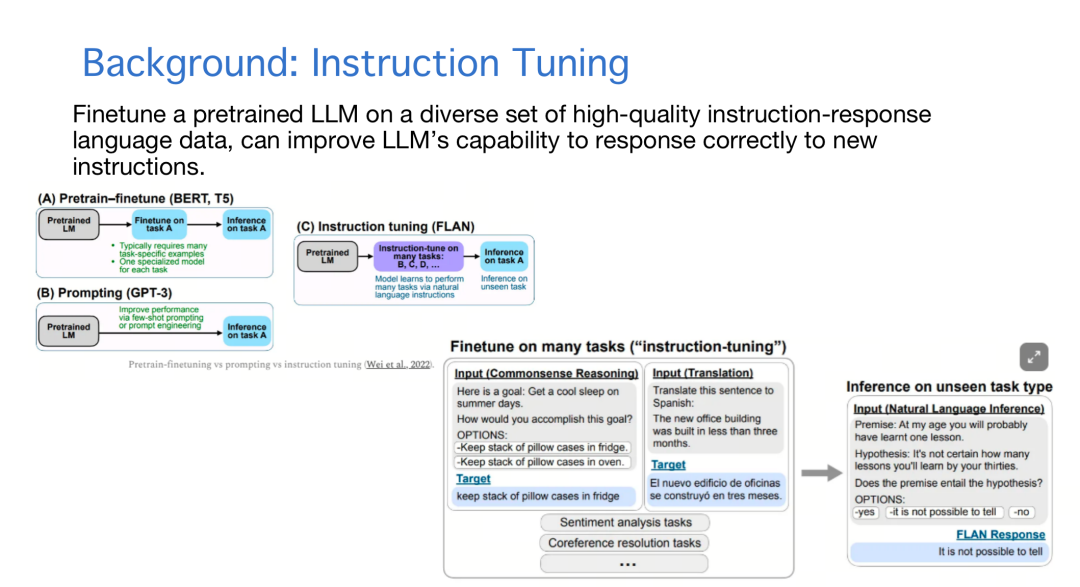
接下来语言模型的空间又发生一个事情,Instruction Tuning。提示词或构建的不同任务结合在一起,会形成有输入有输出的Instruction Tuning数据,用这些数据进一步训练预训练模型,能增强模型对指令遵循的能力。
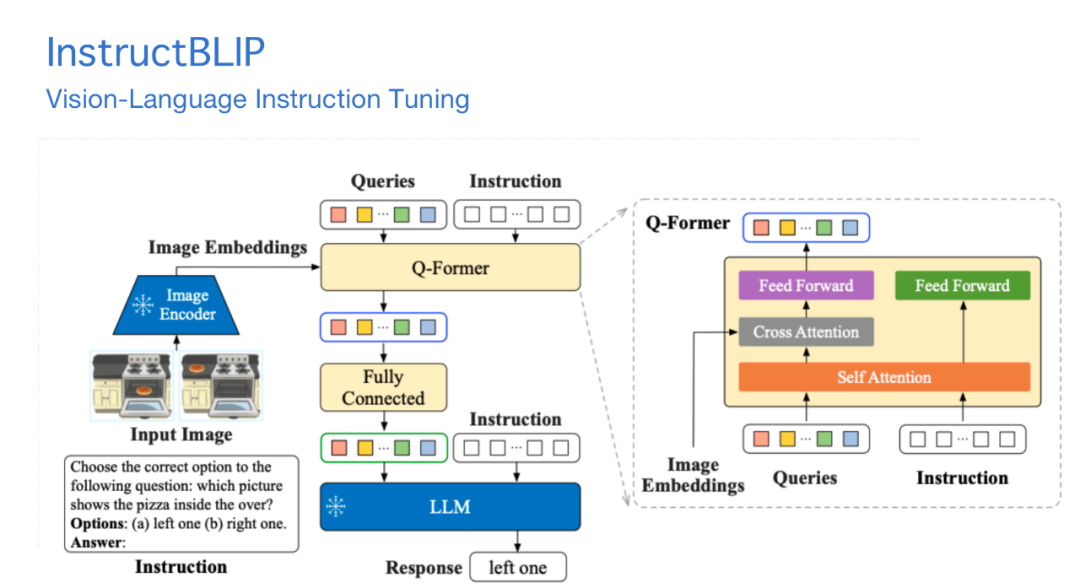
基于类似的想法,我们构建了一些从开源数据整理、帅选后形成的图片、问题和答案数据库。
接下来讲从语言到视觉生成的一些工作。背景是Diffusion Model的出现极大地增强了这个领域研究的热度和模型的能力,Diffusion Model做的是去噪音的事情,会学习到从噪声到图片的过程。
最开始引领这个领域的论文是Latent Diffusion Model,在图片转成的隐式空间做Diffusion,能够极大提升图片Diffusion过程的效率和最终的结果。基于此,出现开源的Stable Diffusion,通过大量数据把Diffusion Models结合起来。

针对Stable Diffusion只能通过文本的提示词生成图片的弱点,我们提出BLIP Diffusion,利用多模态如文本和图片一起的提示,去控制要生成的图片。第一阶段沿用BLIP-2的方式,既可以输入文本也可以输入图片,得到多模态的表征。第二个阶段,会把多模态的表征给到Diffusion的模型里面,把它和本身的文本prompt结合在一起。模型还能进行Zero-Shot的个性化生成、结合ControlNet实现原图+控制图+文本多模态控制图像生成、结合结构控制与风格控制的风格迁移、结合Pix2Pix使用图片+文字控制来进行图像编辑和重绘、通过插值方法实现主体间的融合。
提问1:后面讲的技术与Stable Diffusion ControlNet有什么原理上的不同?
李俊男:ControlNet是结构化的控制,我们的控制更偏风格或者主体,这种控制可以与ControlNet进行互补。
提问2:未来有没有可能实现框架下理解与生成的统一?
李俊男:基于BLIP中的Q-former我们做了一些探索,但现有的工作表明,理解和生成会有一些互斥的任务,在某种程度上面,这还需要更多探索。
南开大学教授程明明:高效能个性化图像生成
今天给大家汇报的是关于高效能个性化图像生成方面的工作,一是,针对Diffusion系列模型训练资源消耗巨大的问题。二是,个性化图像生成问题。由于现阶段的图像生成模型很难做严肃、精确符合物理规律的事情,因此泛娱乐化的应用更贴近于近期的实现,用户的参与感、个性化的内容就比较关键。
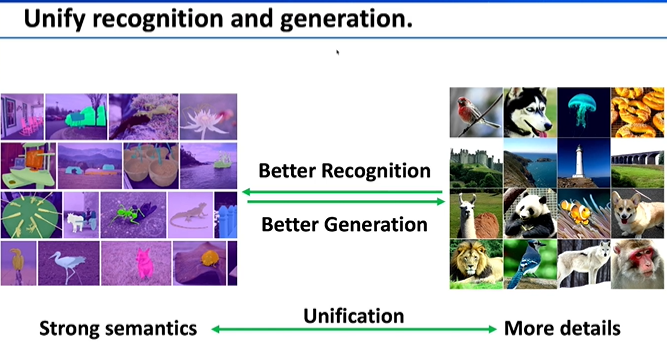
图像生成模型的研究思路,早期是想学习各种各样的表征去理解图像,近期更多的人在尝试通过文字或者多模态的信息做理解和生成,原则上来讲,这两者应该能够相互促进。
我们发现利用如DIT之类的Diffusion系列模型训练时,得到高质量图像需要迭代非常多次,原因是Diffusion的模型特别擅长处理独立的逐点噪声,但是缺少结构化的信息。基于这个观察,我们希望能强化建模的能力,进而增强训练的效率。因此尝试引入Masked autoencoders,它需要建模图像里不同patch间的相互关系,我们认为这样的能力,能够很大程度上增强结构化建模的能力。
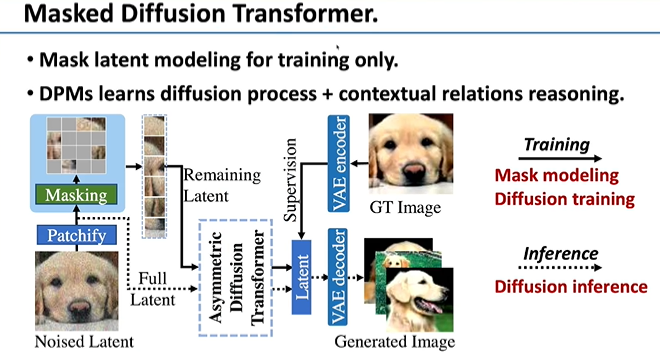
基于此,我们提出了新的工作——Masked Diffusion Transformer,把MAE 机制引入到Diffusion的训练过程中。其中Diffusion Transformer是非对称的,而在重构masked区域即Side-Interpolater时,我们发现可以只需要一个不太大的block就能重建上下文关系。
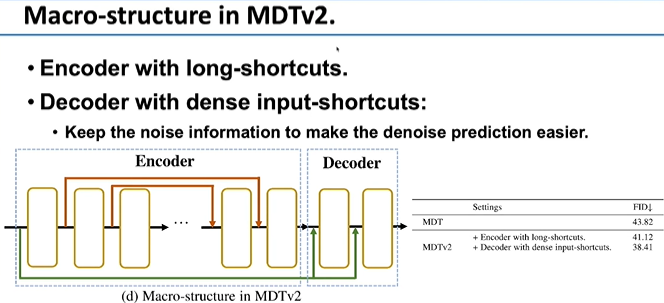
我们近期对MDT做了进一步提升,在根据上下文信息进行建模时,加入了多尺度建模能,发现无论是训练速度还是迭代次数的实际耗时,都得到了非常大的增强。在ImageNet图像生成任务上我们拿到了SOTA。
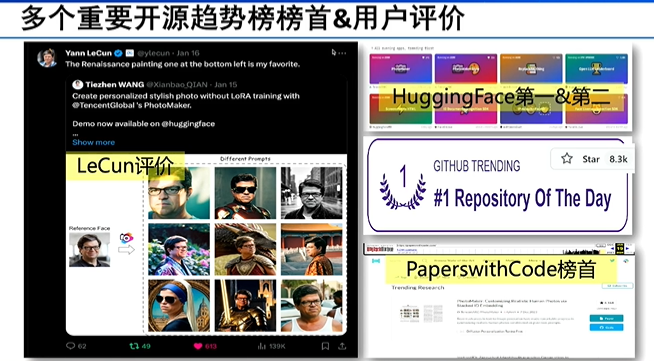
另外,今年年初做了两个个性化图像生成的开源工作,一个是和腾讯合作的Photo Maker。另一个是和头条合作的Story Diffusion。这样的工作被LeCun转发非常火,曾经HuggingFace排名第一和第二,分别用于生成自然图像和风格化图像。
这个工作受启发于DreamBooth(CVPR23),可以给定少量例子,然后生成更多个性化图像,需要对输入ID图像进行上千步迭代,耗时大概十分钟。即便后期有其他加速的工作,但毕竟需要微调模型,时间长的问题依旧无法避免。

虽然有一些改进工作,但开源少、生成质量低、姿态单一。这些工作的问题在于,输入图像和目标图像往往来源于同一个图像,模型很难区分出什么信息是需要保留的信息,因此这个方法在很大程度上缺乏变化性,造成生成的结果相对单一。
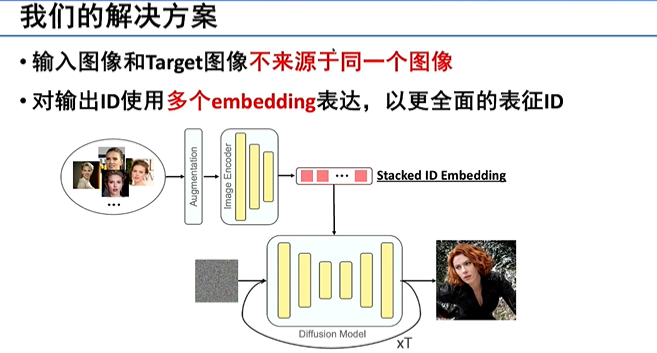
我们的解决方案是输入一组图像,关注到个性化的信息,避免对姿态或者图像的退化记忆,从而能生成具有人脸属性的图像。

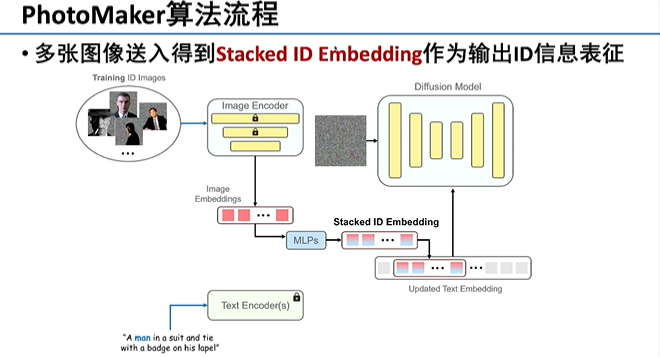
我们给定多张图像,编码后提取图像的嵌入,把嵌入和文本里边关于图像的语义描述结合得到Stacked Embedding,用这个Stacked Embedding替换文本中普通的视觉表,影响Diffusion模型,而不需要每一次给到一组图像,就微调整个Diffusion模型,因此速度可以得到很大提升。
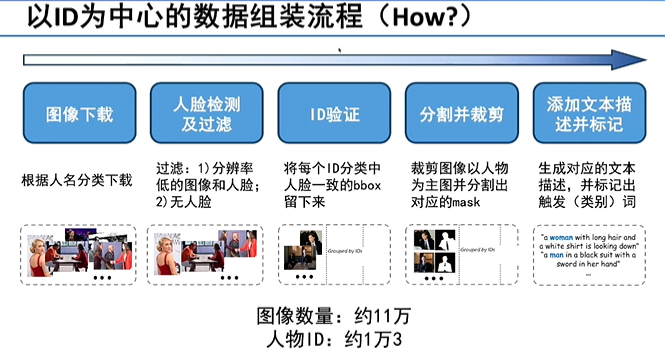
另外,我们希望得到很多关于同一个ID不同图像的数据,现有的数据集不足以支撑,因此还需要以人为主体的自动生成数据,以保证快速定制速度的同时,生成的结果具有很高的生成质量、ID保真度,生成的人脸具有多样性。
目前只需要几张哪怕质量不是很高的图片,就可以生成个性化图像,能够改变年龄或性别、将老照片或是艺术作品中的人物带入现实生活,也能进行人物融合,通过控制不同ID在输入图像池中的占比来调节融合ID的偏向。
最后一个工作,Story Diffusion试图做视频生成的结果。第一阶段是基于图像模型生成关键帧,关键要保持图像的一致性;第二阶段是用我们提出的motion predictor方法,在语义空间中插帧串成视频,避免像素级建模。
提问:你们训练的数据主要还是2D和文字结合为主,为什么没有大量地使用3D数据?这对于Motion的Prediction或许更自然吗?
程明明:一方面出于资源消耗和工作量的角度考虑,我们在高校一般不太倾向于做特别大的系统,更倾向于做一两个突破点。往往找一个baseline,在其中加入我们的想法,看看我们的想法对此的改变。另外一方面,最终论述成果时,如果有多个步骤变化,就难以确定某个性能的提升是出于哪个原因,这跟企业侧重产品性能不太一样。
panel环节:视觉重回第一赛道?
问题1:今年Sora以及原生多模态大模型的成功,意味着视觉的成分变得越来越重要。这些项目的成功是否意味着计算机视觉正在取代自然语言,成为AI最主流和主导的方向?
程明明:视频中的最新进展确实给大家非常大的鼓舞,但我不倾向于什么东西会完全取代什么。从生成的角度来讲,自然语言能够率先取得突破是有道理的,它的信息密度更高,而图像视频想要达到到自然语言的高度,未来对计算量、复杂度等的需求应该是比自然语言大很多。
颜水成:Sora用的数据量和GPT-4用的数量相比没有想象那么大,后来国内复现Sora需要的资源似乎更少一些。
程明明:是的。我的理解是,很多模型第一版出来的时候,目的是为了表明能做某件事情,为了尽快做成,会消耗很多资源,事实上事后复现的时候是有更优方案的。
颜水成:这是很有趣的事情。在NLP领域,第一个做出来,第二个做出来,资源的消耗差距不是那么大。但是计算机视觉前后做出来,资源消耗的量差距往往非常巨大。例如Sora据说是在1万到10万块H100的基础上训练出来的,而中国现在大几千块卡,有几十倍的差距,这是很有意思的现象。
李俊男:Sora从生成的角度证明了,大量的视频和大量的计算资源能够带来效果。但从视觉理解的角度来讲,目前还没有看过通过大量数据得到更好效果的模型,所以这也是现在做视觉非常激动人心的时候,有很多可以探索和借鉴的空间。
颜水成:从产生的内容让人消费来说,视觉比文字更能激活人的多巴胺,从产品娱乐的角度来说视觉也大有可为。
申琛惠:视频生成还是处于非常早期的阶段,自然场景相对容易生成,但细节部分有欠缺。另一方面,虽然也可以用图片作为媒介控制生成的内容,但大语言大模型已经达到相对成熟的状态,采用文字,可以在短期内看到比较令人激动的结果。
鲍凡:机器学习的问题大致分为三类,一是数据的表示问题;二是数据的理解问题;三是数据的生成问题。从数据上说,文本数据更多,知识密度更高。从文表示上说,文本表示的问题已经被较好解决,做生成、理解都没有什么表示上的阻碍。但是图像表示更之后,尤其3D图像的表示本身也是非常困难的问题,至今没有定论。
问题2:什么样的计算机视觉大模型是合适的,离开文本研究视觉大模型可行吗?
李俊男:第一个问题是,现在的视觉数据缺少有效的监督信号,当然也有采用深度图或者分割,来共同监督语言之外的信号,这也是非常值得探索的,并且这里面涉及到数据的获取问题。第二个问题,自动驾驶或机器人有其他的交互方式,对于人类来说最通用的交互模式如果还是语言的话,把语言引入视觉模型就还是比较重要的事情。
鲍凡:单个模态是否能够做成非常通用的大模型,可以从存在性和构造性两个方面考虑。在存在性方面,我们生活的世界就是一个纯视觉模态的大模型,文本是属于所见的一部分。在构造性方面,是比较曲折的过程,没有办法通过当前算法和模型的角度完成它,可能需要新的装置和设备,来构造有实际信息支持的视觉数据,然后才能训练。
程明明:我们需要有多模态的大模型去探索更多的可能,例如模态间的交互以及上限。也可能会在多模态大模型的超级人工智能帮助下,根据不同的应用产生小的垂直领域或单模态人工智能的模型,但也许在某方面做到极致或讲求效率时,还是需要会用到单模态。
问题3:工业界算力相比学术界充足,学术界要为工业界培养人才,两者应该怎样分工,学术界如何发挥自己的价值?
程明明:我们也许可以从两个方面进行尝试。一是,相比于做全系统的事情,选择做pipeline中自己感兴趣且重要的点去突破。我们不尝试去做整个汽车,而是扮演好做螺丝钉的角色,感兴趣什么做什么,还是很自由的。二是,所进行的研究最好具有实际或潜在的用处,能够紧密地与企业合作,在合作中互通资源。
李俊男:我认为出现这个问题的原因是,大模型对于工业界很具有商业化前景。一方面,可以考虑学术界是否有别的没有被挖掘出来,但又具有商业前景的领域。另一方面,学术界可以错位竞争,在自己擅长的领域进行前沿探索,做一些工业界做不到的事情。例如Diffusion的模型有很多理论上可以提升的空间,工业界可能会选择保守的方案,学术界也许有做出创新性突破的可能。
申琛惠:深有体会,不止学校,初创或者中小型企业也会面临财力难以支撑这方面研究的问题。一方面可以借助开源模型;另一方面表明加速工作非常有价值。另外也有一些融合训练的策略,学术界与业界能够相辅相成。
鲍凡:我认为在人工智能里面,最重要的是如何定义数据的分布,因为现阶段关于数据分布的研究滞后于定义损失和优化求解。数据分布取决于智能的上限,既是一个工程问题,也是一个理论研究问题,因此怎样的数据分布可以带来更强大智能,这是学术界和工业界可以共同思考的问题。
问题4:按目前趋势,预估在接下来一年,视觉大模型会有哪些新的事情发生?
鲍凡:我最近关注到大家对数据表示热情越来越高,最近有很多人思考怎么把图像压缩率降下来,我认为这会有非常大的突破。当图像的表示压缩到足够稠密的时候,需要花费的算力门槛变低,从而推动数据生成。
申琛惠:视频生成的质量和视频生成过程的可控性,在短期内可以快速提升。
李俊男:我觉得是评测,现在的视频理解和生成的评测都非常欠缺,有一个大家都公认的类似语言模型里面的评测,是非常必要的。
颜水成:可能有更多的系统出来之后,这个评测更好做一些。现在开源的系统还太少。
- 点击“查看原文” ,观看完整大会视频回放 -

Llama2、王兴兴、王鹤、卢宗青、邵林、高阳等专家共论具身前沿

Llama2、百川、ChatGLM、MiniCPM、Llama作者等共论LLM关键问题

Llama2、3作者中国首讲!LLM前世今生,AGI是我们这代人的哥白尼革命

GPT-4o、SAM、DiT、DCN、SegGPT作者共话多模态模型前沿进展
















 106
106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









