







本文会介绍 Spark 核心社区开发的生态系统库,以及 ML MLlib 及 Spark Streaming 的 Spark 库的具体用法,对于企业的各种用例及框架也进行了说明。

spark拥有一个庞大的、不断增长的社区,还有在企业环境中不可或缺的生态系统。这些生态系统提供了不同生产环境案例所需的许多功能。一般来说,Spark 应用做的是机器学习算法、日志聚合分析或者商务智能相关的运算,因为它在许多领域都有广泛的应用,包括商务智能、数据仓库、推荐系统、反欺诈等。
数据仓库
对任何业务来说,数据分析都是一个核心环节。对分析型的应用来说,数据仓库系统就是其核心系统。Spark 有众多的框架和生态系统,所以它能作为核心组件为企业环境提供数据仓库功能,如图1所示。

图1 Spark 可以用作数据仓库核心组件
当然,与其他现有的工具相比,Spark 提供的功能有较大不同。SQL 是很多数据分析师、数据科学家和工程师使用的细粒度数据分析方法。Spark 也可以用作数据仓库框架,支持 SQL 处理,名为 SparkSQL。
Spark 内核已经集成到其他分布式文件系统中,例如 HDFS、S3。如果你的业务数据本来就保存在这样的系统中,很容易将现有业务流程转移到 Spark 环境,因为你只需要在数据存储系统上启动 Spark 集群即可。针对开发人员,Spark 还提供了一个友好的 API,可以用数据科学家们喜爱的 Python 和 R 来访问它。这个功能存在很长一段时间了。如果你习惯使用这些语言,那么选择 Spark 作为自己的数据仓库引擎还是很容易的。
你可以使用熟悉的接口在 Spark 上处理更大的数据集。SparkSQL 特有的接口是DataFrame(数据帧),这是受 R 语言启发而引入的。建议使用这个接口来访问结构化数据。我们将在下一节详细介绍 DataFrame。先来看一个纯 SQL 接口。Spark 大致提供了三种类型的 DW(数据仓库)功能:SparkSQL、DataFrame 及 Hive On Spark。如前所述,尽管 DataFrame 一开始是使用 SparkSQL 来开发的,已经为大家精心准备了大数据的系统学习资料,从Linux-Hadoop-spark-......,需要的小伙伴可以点击但它与机器学习管道的关联度更高。我们将把它与 ML / MLlib 放到一起介绍。本节介绍SparkSQL 和 Hive on Spark,重点关注怎样配置集群。在尝试 Spark 的这些 SQL 功能之前,需要下载带 Hive profile(配置)的预编译包,或者用 Hive profile 去构建这个包。如果你要自己创建,可以使用如下命令:
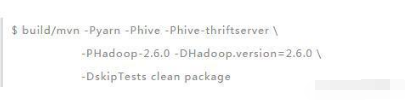
一定要安装 Zinc,它是一个长时运行的服务器程序,用于 sbt 的增量编译。如果你用的是 OS X 系统,可以用命令 brew install zinc 来安装它。
在运行这条命令后,可以得到一个带有 Hive 类的 Spark 二进制包。你或许会发现能用-P 配置及-DHadoop.version 环境变量轻松选择 Hadoop 版本。最好依据 Hadoop 集群及 Hive 功能选择你所需要的版本。换句话说,如果想在 Hadoop 2.7.0 上运行 Hive 0.13,可以使用如下命令:

Hive on Spark
Hive 是用于管理分布式存储(例如 HDFS)中的大型数据集的数据仓库软件。Hive 一开始被开发来作为生成 Had
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









