






在人工智能的快速进展中,视觉语言模型正成为理解和叙述视觉信息的关键工具。MoonDream,一个拥有16亿参数的小型视觉语言模型,凭借其出色的性能和易用性,正迅速成为开发者和爱好者的热门选择。
MoonDream的基本概念在于它能够解码、审查和叙述视觉信息,为那些希望理解图像深层含义的人们提供了一种新的视角。它可以在各种设备上运行。这意味着,无论您是艺术家、开发者还是普通用户,MoonDream都能够帮助您将视觉数据转化为有意义的语言。
为什么应该关注MoonDream?首先,它的性能在多个数据集上表现出色,如VQAv2和GQA,展示了其强大的图像理解能力。其次,MoonDream易于使用,只需简单的命令行操作或Gradio界面,就可以与模型互动,探索图像的各个方面。最后,尽管MoonDream是一个小型模型,但它证明了在数字世界里,大小并不总是与力量同义。
在这个探索视觉领域的时代,MoonDream是一个值得关注和探索的工具。下面一起进行探索
官方地址
Benchmarks
| Model | VQAv2 | GQA | TextVQA | TallyQA (simple) | TallyQA (full) |
|---|---|---|---|---|---|
| moondream1 | 74.7 | 57.9 | 35.6 | - | - |
| moondream2 (latest) | 79.4 | 63.1 | 57.2 | 82.1 | 76.6 |
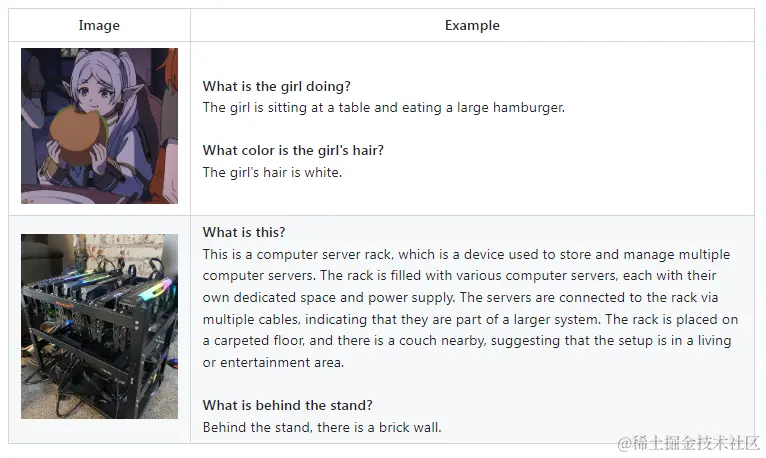
例子
使用方法
MoonDream的安装和运行过程非常简单,只需几个步骤即可开始探索其强大的功能。以下是详细的使用指南:
1. 创建虚拟环境: 首先,在终端中创建一个虚拟环境,这有助于管理依赖项和确保软件包的兼容性。
复制代码
python -m venv venv pip install transformers einops
2. 克隆仓库并安装依赖: 接着,克隆MoonDream的GitHub仓库,并安装所需的依赖项。
bash
复制代码
git clone https://github.com/vikhyat/moondream.git cd moondream ./venv/bin/pip install -r requirements.txt
3. 运行模型:
- 使用
transformers脚本在CPU上运行模型
ini
复制代码
from transformers import AutoModelForCausalLM, AutoTokenizer from PIL import Image model_id = "vikhyatk/moondream2" revision = "2024-05-20" model = AutoModelForCausalLM.from_pretrained( model_id, trust_remote_code=True, revision=revision ) tokenizer = AutoTokenizer.from_pretrained(model_id, revision=revision) image = Image.open('<IMAGE_PATH>') enc_image = model.encode_image(image) print(model.answer_question(enc_image, "Describe this image.", tokenizer))
该模型定期更新,所以建议将模型版本固定为上述所示的具体版本。
要在文本模型上启用Flash Attention,在实例化模型时传入attn_implementation=“flash_attention_2”。需要GPU服务器
ini
复制代码
model = AutoModelForCausalLM.from_pretrained( model_id, trust_remote_code=True, revision=revision, torch_dtype=torch.float16, attn_implementation="flash_attention_2" ).to("cuda")
批量推理也得到支持
ini
复制代码
answers = moondream.batch_answer( images=[Image.open('<IMAGE_PATH_1>'), Image.open('<IMAGE_PATH_2>')], prompts=["Describe this image.", "Are there people in this image?"], tokenizer=tokenizer, )
- 使用
sample.py脚本在CPU上运行模型。您可以指定图像路径和提示来生成描述。
css
复制代码
./venv/bin/python sample.py --image [PATH TO IMAGE] --prompt [PROMPT]
如果没有提供提示,脚本将允许您进行交互式提问。
4. 使用Gradio界面: 启动Gradio应用程序,通过浏览器与模型互动。
bash
复制代码
./venv/bin/python gradio_demo.py
在浏览器中打开http://127.0.0.1:7860,体验图像问答的乐趣。 如果想在终端中退出服务,使用Ctrl + C中断。
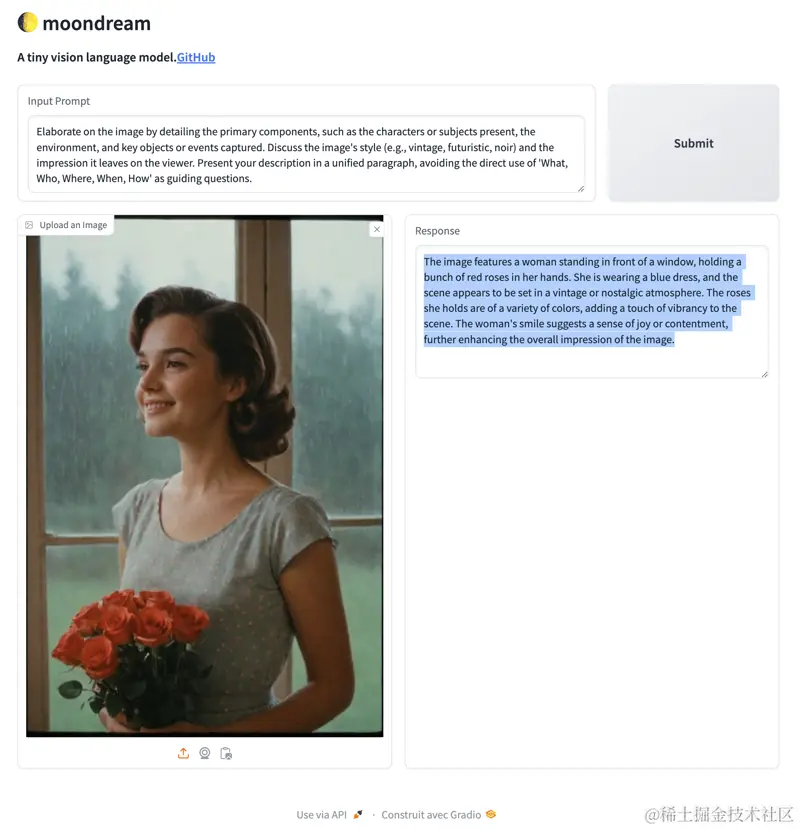
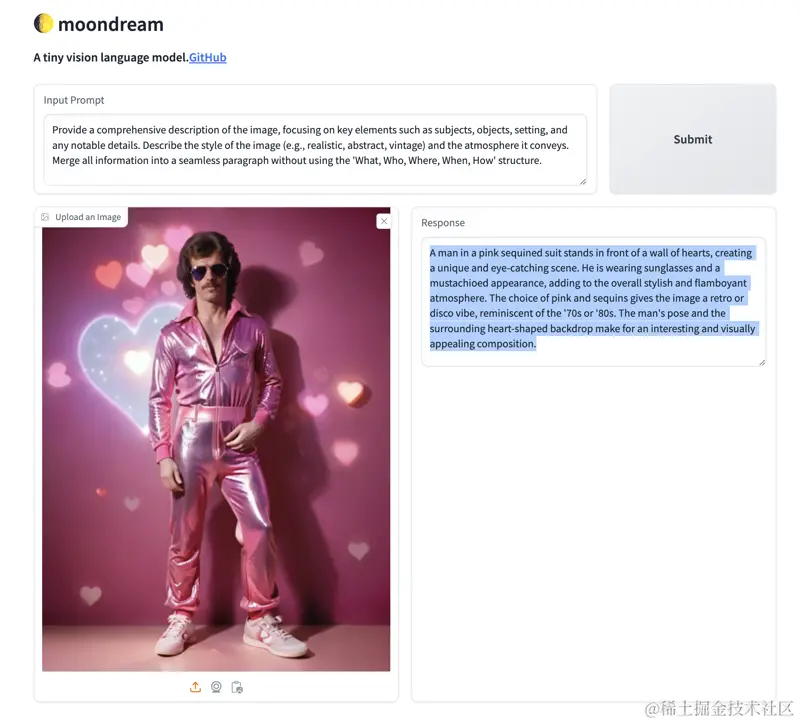
图像提问的文本提示
为了更好地与MoonDream互动,可以使用以下示例文本提示来提问:
- 提供一幅图像的全面描述,重点关注主题、对象、背景和任何显著的细节和视觉风格。
- 描述图像的风格(例如,现实主义、抽象、复古)和它传达的氛围。
- 描述图像的主要组成部分、任何可辨认的人物、背景、暗示的时间框架和艺术方法。
- 深入探讨图像的本质,讨论其视觉元素、画面中的角色、场景的设置、它唤起的时期以及它是如何创作的。
通过这些提示,可以引导MoonDream生成详细且富有洞察力的图像描述。
限制
尽管MoonDream是一个出色的工具,但它也有一些局限性和潜在问题需要注意:
- 不准确性:MoonDream可能会生成不准确的说法,特别是在处理复杂或微妙的指令时。用户在使用时应保持警惕,并对其生成的内容进行批判性思考。
- 语言限制:该模型主要是为理解英语而设计的。非正式英语、俚语和非英语语言可能无法正确工作,或者生成的描述可能不够准确。
- 社会偏见:模型可能存在社会偏见,这可能会影响其对某些主题或人群的描述。在使用模型时,用户应意识到这一点,并对其生成的内容持谨慎态度。
- 情感和微妙性的理解:尽管MoonDream能够提供关于图像的详细描述,但它可能在理解图像的情感和微妙性方面存在局限。这可能导致生成的描述缺乏深度或与原始图像的意图不符。
- 资源需求:虽然MoonDream是一个相对较小的模型,但它仍然需要一定的计算资源来运行。在低性能设备上,可能需要一些时间来生成描述。
- 交互式体验:虽然Gradio界面提供了一种交互式的方式来与模型互动,但在某些情况下,用户可能需要提供更具体的提示来获得满意的描述。
尽管存在这些限制,MoonDream仍然是一个非常有用的工具,特别是对于那些需要快速理解和描述图像内容的项目。用户在使用时应了解这些局限性,并根据自己的需求和预期来调整使用方式。
结论
MoonDream以其16亿参数的规模和卓越的性能,在视觉语言模型领域中占有一席之地。它不仅在多个数据集上的表现出色,如VQAv2和GQA,而且易于部署和使用,无论是在命令行界面还是通过Gradio界面,都能提供丰富的交互体验。
然而,MoonDream并非完美无缺。它可能在处理复杂或微妙的指令时遇到困难,生成的描述可能不够准确。此外,它主要是为理解英语而设计的,对非英语语言和非正式英语的支持有限。
尽管存在这些局限性,MoonDream在特定应用场景中仍展现出巨大的潜力。例如,它可用于图像标注、艺术作品分析、视觉内容创作等领域。用户可以通过了解其优势和局限性,更好地利用MoonDream来满足他们的特定需求。总的来说,它是一个熟练的模型,非常适合为构建Lora源准备文本描述。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









