










-
先看一下环境效果
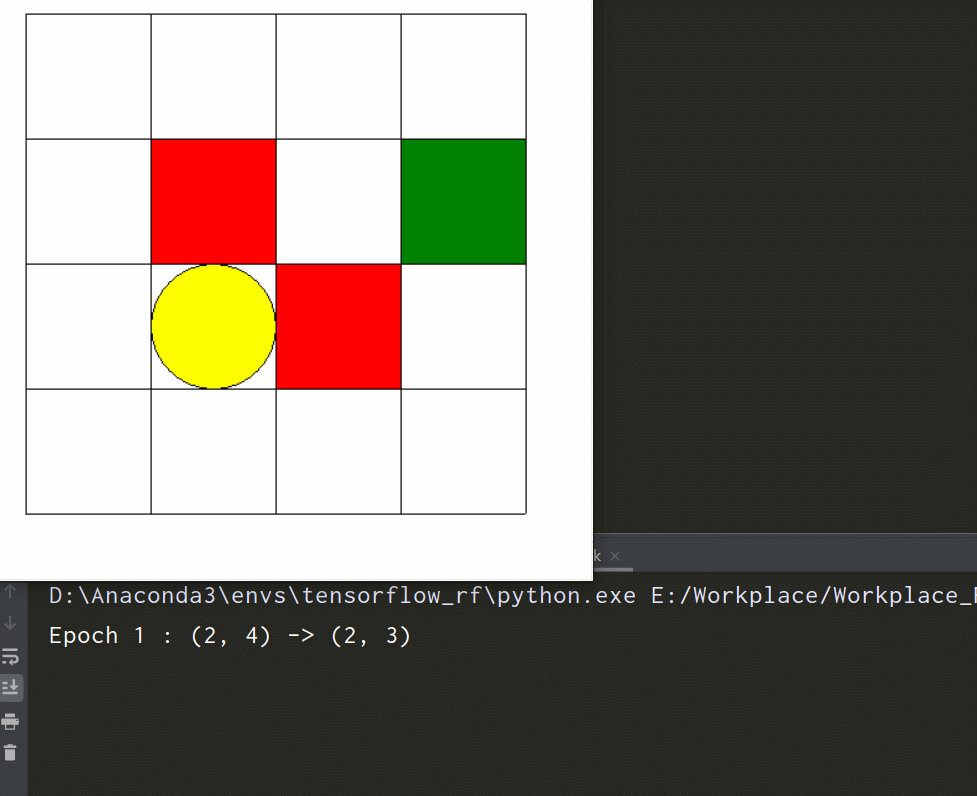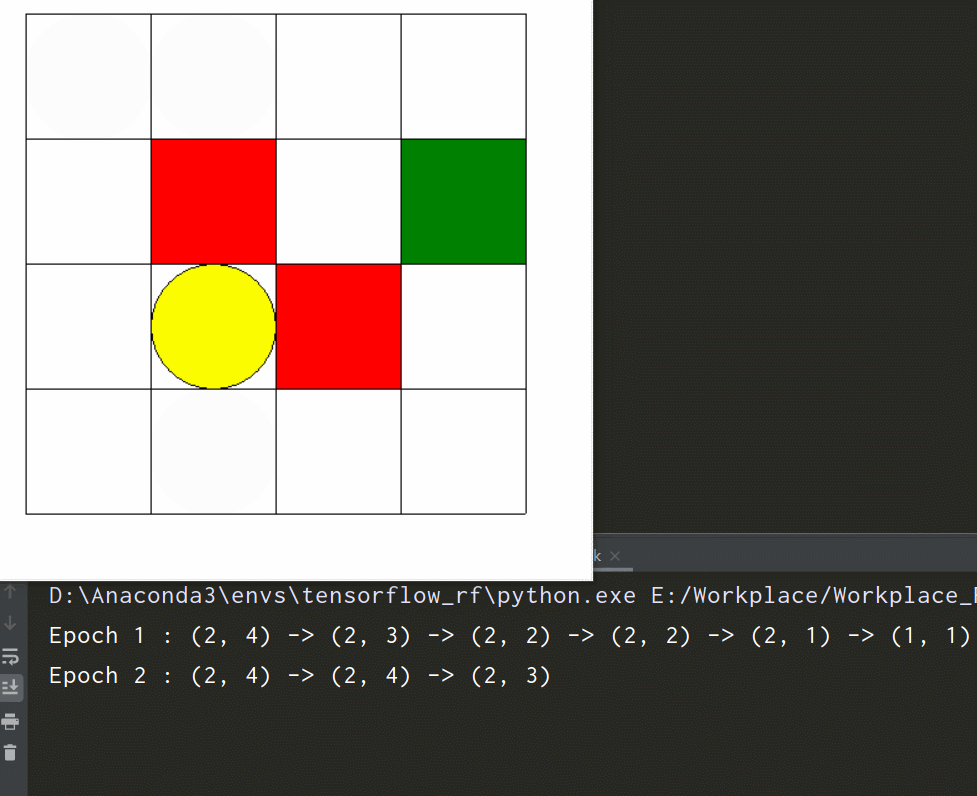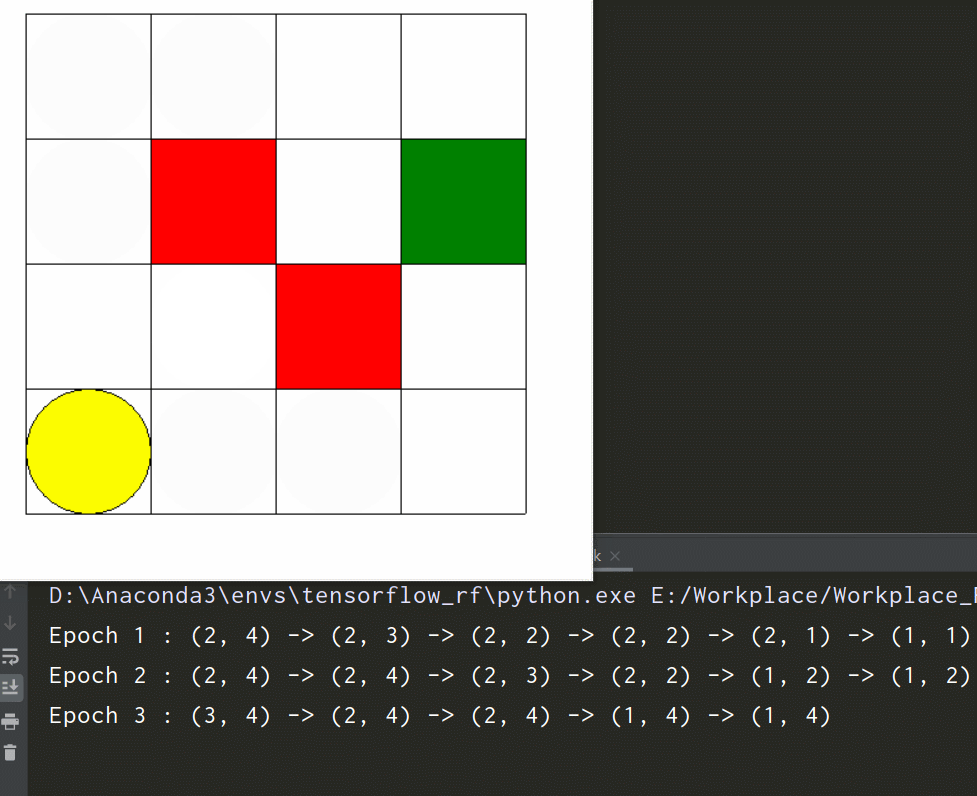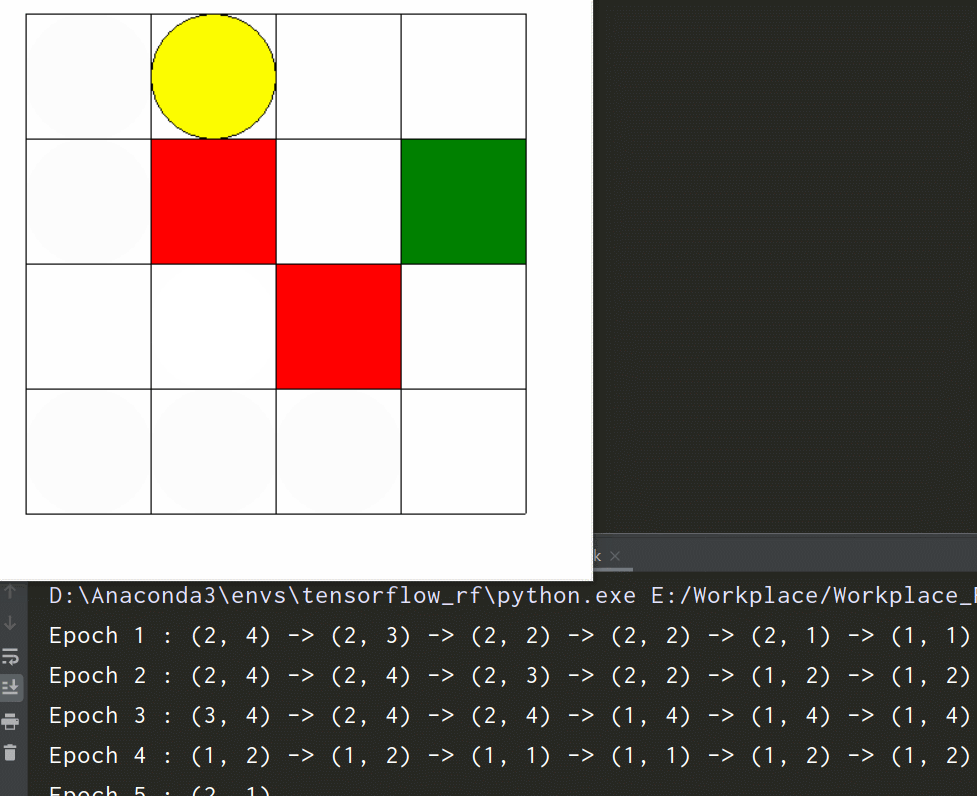
-
强化学习用到的环境通常需要以下几个功能函数
-
_init_()
def __init__(self): super(Maze, self).__init__() self.observatin_space = [(x, y) for x in range(1, 5) for y in range(1, 5)] self.action_space = range(4) self.n_actions = len(self.action_space) self.n_features = np.array(self.observatin_space).shape[-1] self.target = {(4, 2): 10} # 安全/目标状态 self.danger = {(2, 2): -20, (3, 3): -20} # 危险状态 self.state = None # 初始化窗口、画布 self.window = tk.Tk() self.canvas = tk.Canvas(self.window, bg='white', height=500, width=500) -
reset()
用来在每轮训练前重置初始化状态
def reset(self, startstate=None): # 重置初始状态 self.canvas.delete('all') # 操作之前清空画布,否则每步的状态将都会堆在画面上 if startstate == None: # 如果不指定起始状态,随机生成一个状态 self.state = self.observatin_space[np.random.choice(range(len(self.observatin_space)))] else: # 如果指定了初始状态,就初始化为指定状态 self.state = startstate self.counts = 0 return self.state -
step()
用来处理每一步的逻辑,获得下一个状态,回报以及判断是否结束
def step(self, action): self.canvas.delete('all') # self.canvas.delete(self.statepos) x, y = self.state if action == 0: # 不动 x = x y = y elif action == 1: # 上 x = x y = y + 1 elif action == 2: # 下 x = x y = y - 1 elif action == 3: # 左 x = x - 1 y = y elif action == 4: # 右 x = x + 1 y = y # 判断下一个状态是否属于状态空间,如果在状态空间中更新当前状态,如果不在状态空间保持当前状态 next_state = (x, y) self.state = next_state if next_state in self.observatin_space else self.state self.counts += 1 s = tuple(self.state) # 为了能用in操作 if s in self.danger.keys(): reward = self.danger[s] done = True elif s in self.target.keys(): reward = self.target[s] done = True else: reward = -0.5 # 每多走一个,加个小的负反馈 done = False return self.state, reward, done -
render()
完成可视化画面搭建
def render(self): # 注意tkinter的平面为向下x轴正向,向右y轴正向 # 格线 for i in range(5): # 两个顶点的四个坐标 self.canvas.create_line(50, 50 + 100 * i, 450, 50 + 100 * i) self.canvas.create_line(50 + 100 * i, 50, 50 + 100 * i, 450) # 绘制出口(安全状态) for state in self.target: # 我自己把画格的操作封装了一个方法 self.drawrectangle(state, fill='green') # 绘制危险区域 for state in self.danger: self.drawrectangle(state, fill='red') # 绘制当前state的位置(圆) self.statepos = self.drawoval(self.state, fill='yellow') self.canvas.pack() self.window.update() # 为了方便的复用,将画格点和画圆另外进行了封装 def drawrectangle(self, point, **attrs): ''' 根据格点画一个方格 :param point: 格点坐标(4,3) :param attrs: 其他参数,such as fill='red' :return: ''' size = 100 self.canvas.create_rectangle( 50 + (point[0] - 1) * size, 50 + (point[1] - 1) * size, 50 + point[0] * size, 50 + point[1] * size, **attrs ) # 向右为x正方向,向下为y轴正方向 # 左上角坐标和右下角坐标 # 画椭圆 def drawoval(self, point, **attrs): ''' 画(椭)圆 :param point: 格点坐标(4,3) :param attrs: 其他参数,such as fill='red' :return: ''' size = 100 self.canvas.create_oval( 50 + (point[0] - 1) * size, 50 + (point[1] - 1) * size, 50 + point[0] * size, 50 + point[1] * size, **attrs ) -
close()
def close(self): if self.window: self.window.destroy() -
测试
if __name__ == '__main__': env = Maze() for epoch in range(5): env.reset() print('Epoch', epoch + 1, ': ', end='') print(env.state, end='') env.render() # 刷新画面 time.sleep(0.5) for i in range(5): env.step(np.random.choice(env.action_space)) # 随机选择一个动作执行 print(' ->', env.state, end='') env.render() # 刷新画面 time.sleep(0.5) print() env.close()测试效果如文首所示
-
相关内容
什么是gym
gym自定义可视化环境绘制
gym自定义可视化环境实例
强化学习:gym环境解读及使用
从Q_Learning看强化学习
一个Q_Learning强化学习自定义gym环境可视化实例
Pytorch实现DQN
















10-11
 5388
5388
5388
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











