







预备知识
英文缩写&术语
| 英语 | 简中 | 补充 |
|---|---|---|
| Large Language Model (LLM) | 大语言模型 | |
| Artificial General Intelligence (AGI) | 通用人工智能 | 一个远大的目标 |
| Agent | 智能体/代理 | |
| Embody | 具身 | |
| Multi-Agent System (MAS) | 多智能体系统 | |
| Token | 文本分割后得到的最小语义单位 | |
| Prompt | 提示词 | 我们向AI提出的问题或指令 |
| Reason | 推理 | 模型根据已有的知识,通过逻辑的推导得出结论 |
| align | 对齐 | 确保大语言模型的行为与用户的意图或期望一致 |
| Chain-of-Thought (CoT) | 让LLM通过(intermediate step)解决问题的技术 | |
| decode | 解码 | 将模型生成的内部表示转化为人类可读的文本的过程 |
| Universal Self-Consistency (USC) | 通用自一致性 |
Dawn Song 的开场白
人员

引言
Accelerated development of large language models
大语言模型近期的加速发展
LLM agents: enabling LLMs to interact with the environments
大预言模型智能体:使大预言模型能与环境交互
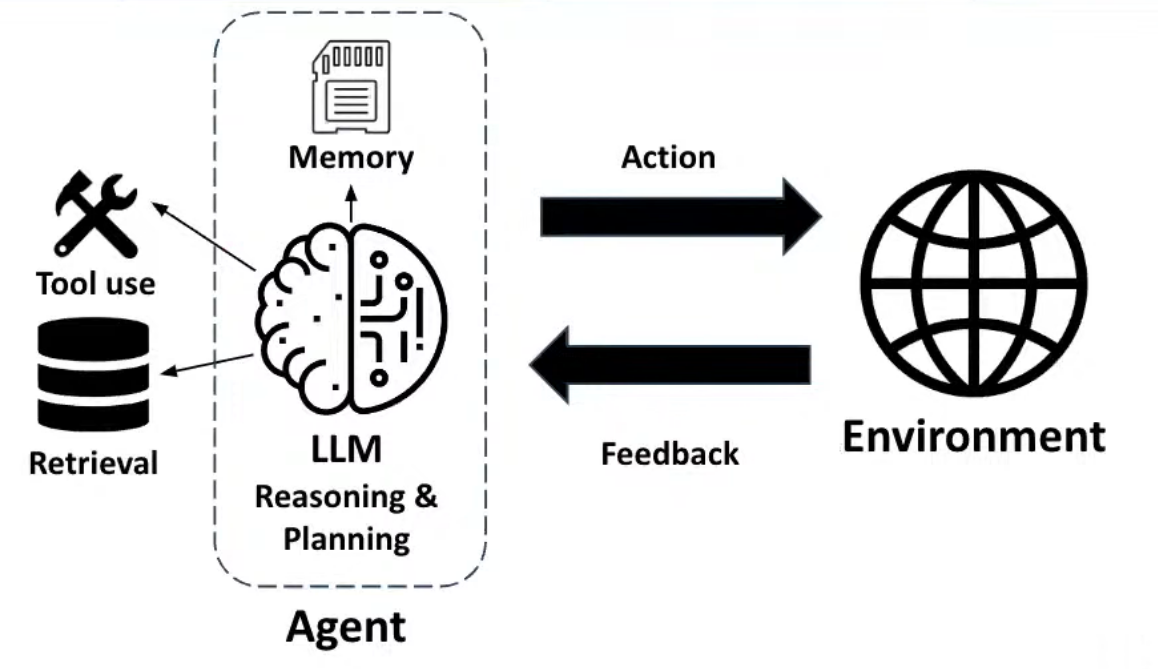
Agent(智能体): LLM + Memory: 大语言模型(LLM)负责进行推理和规划(Reasoning & Planning)。Memory 保存智能体的记忆,用于帮助其在行动时参考过去的经验和数据。
Tool use(工具使用)+ Retrieval(检索):Agent 使用外部工具来执行任务或辅助计算。或从外部数据源中检索信息,以增强其推理和决策能力。
Action(行动):智能体根据推理和规划采取的实际行为,作用于环境中。
Feedback(反馈):智能体从环境中接收到的反馈信息,用于调整和优化后续行动。
详细解释:
-
LLM(Reasoning & Planning)
-
大语言模型(LLM)*位于智能体的核心,负责进行*推理和规划。LLM通过分析输入信息(如文本、对话等)来推测下一步的行动。它不仅能通过语言理解问题,还能生成解决方案或做出复杂的规划决策。其推理能力依赖于模型的训练数据以及内部的算法设计。
-
Memory(记忆)
-
记忆在这里指的是智能体能够保存之前的交互或信息,用于在后续的任务中参考。这种记忆机制帮助LLM保持上下文的连贯性,并增强智能体的长期决策能力。记忆可能包含外部存储的内容,如数据库、先前执行的任务结果、与用户的历史交互等。
-
Tool use(工具使用)
-
工具使用意味着智能体能够调用外部的工具来完成任务,这些工具可能包括计算工具、API、爬虫或其他自动化工具。工具的使用使得智能体超越了其语言模型的局限性,可以处理更多类型的数据,执行计算密集型操作,或进行系统级别的任务。
-
Retrieval(检索)
-
检索是指智能体能够从外部数据库或信息源中获取相关数据。这一机制帮助LLM补充其有限的知识,因为LLM的训练数据不一定包含实时或具体的细节。通过检索,智能体能够获得最新或特定的信息,以做出更好的决策。
-
Action(行动)
-
行动是智能体根据推理结果在外部环境中执行的具体行为。这可能包括生成文本回答、操作系统任务、与外部API交互等。行动是智能体与外界互动的体现。
-
Environment(环境)
-
环境是智能体所作用的外部世界,它可以是一个虚拟环境(如软件系统)、物理环境(如机器人执行任务的现实世界)或者社会环境(如智能体与用户的对话场景)。环境的状态会受到智能体行动的影响。
-
Feedback(反馈)
-
反馈是智能体从环境中收到的回馈信息。这些反馈帮助智能体调整行动策略,例如,环境的反馈可以用来判断智能体的某个行为是否成功,从而帮助智能体改进后续的推理和决策。
LLM Agents in Diverse Environments
大语言模型智能体可用于多种环境
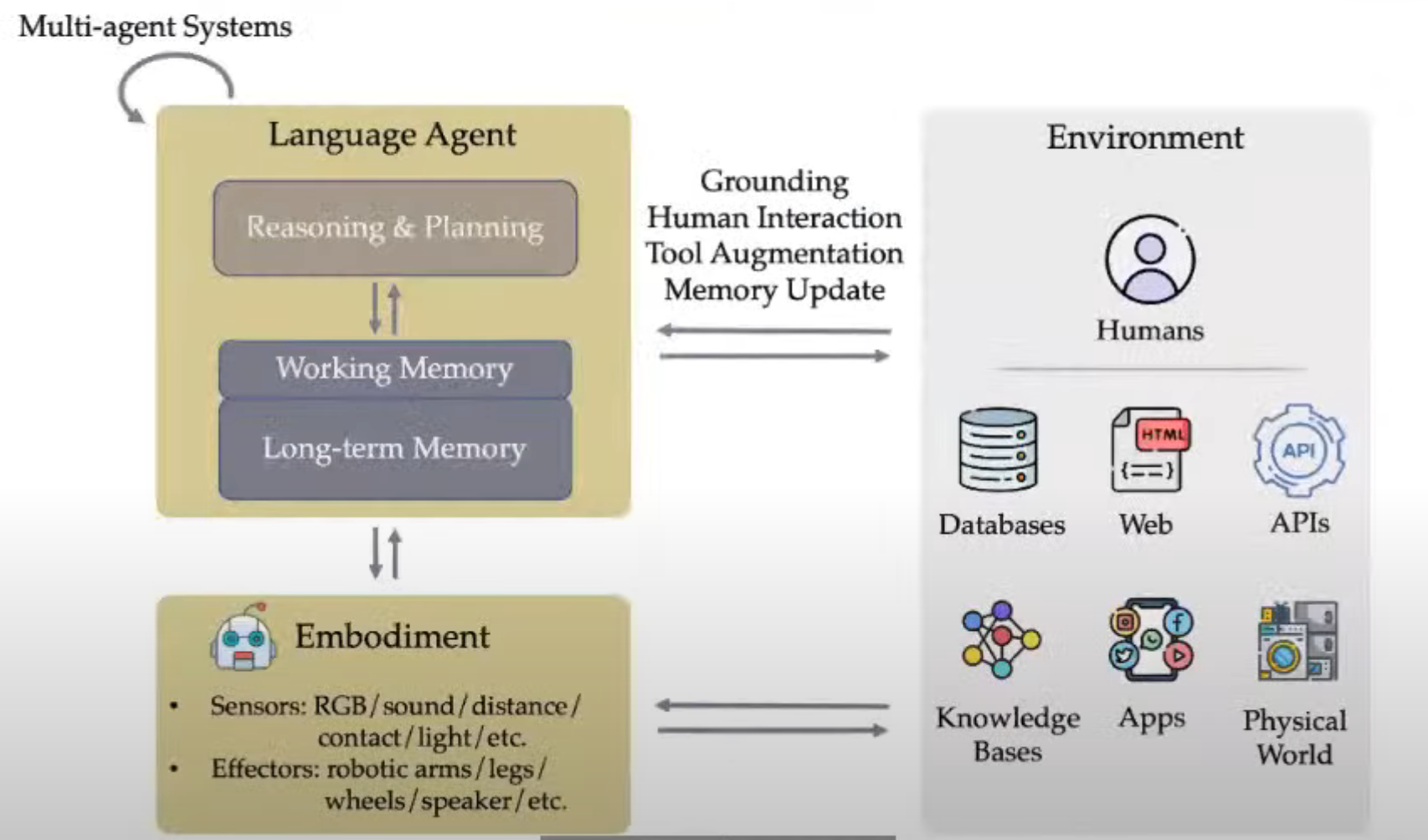
这张图描绘了多智能体系统(Multi-agent Systems)中的一个语言智能体(Language Agent)如何与外部环境互动,并通过化身(Embodiment)与物理世界进行交互。图中包括了语言智能体的内部组成(推理与规划、工作记忆、长期记忆)以及与环境的双向信息交流。以下是这幅图的详细翻译和解释:
翻译:
左侧部分:
-
Language Agent(语言智能体)
-
Reasoning & Planning(推理与规划):负责决策和解决问题。
-
Working Memory(工作记忆):处理短期任务和信息的记忆模块。
-
Long-term Memory(长期记忆):存储长期信息和经验。
-
多智能体系统(Multi-Agent System,MAS) 是由多个智能体(agent)组成的系统,这些智能体可以在一个共享的环境中相互作用、通信、协作或竞争,以完成共同的任务或解决问题。
-
-
Embodiment(化身/体现)
-
Sensors(传感器):RGB摄像头、声音、距离、接触、光线等传感器,用于感知环境。
-
Effectors(执行器):如机械臂、腿、轮子、扬声器等,用于与物理世界进行物理交互。
-
右侧部分:
-
Environment(环境)
-
Humans(人类):与人类进行交互。
-
Databases(数据库):访问和使用数据库中的数据。
-
Web(网页):从网络中获取信息。
-
APIs(应用程序接口):通过API与其他系统或服务进行通信。
-
Knowledge Bases(知识库):使用结构化的知识库作为信息源。
-
Apps(应用程序):与各种应用程序进行集成和交互。
-
Physical World(物理世界):与物理环境直接互动。
-
双向箭头解释:
-
Grounding(落地/基础化):语言智能体通过与人类交互和使用工具等方式,增强其对现实世界的理解。
-
Human Interaction(人机交互):智能体与人类之间的互动,包括对话、任务协作等。
-
Tool Augmentation(工具增强):智能体通过使用外部工具,增强其功能和能力。
-
Memory Update(记忆更新):智能体通过与环境的互动,不断更新其工作记忆和长期记忆。
详细解释:
1. Language Agent(语言智能体)
-
语言智能体是图中的核心部分,主要依赖大语言模型(LLM)进行推理与规划(Reasoning & Planning)。它通过接收输入、处理信息来生成输出。智能体的工作记忆用于管理短期任务信息,长期记忆则用于存储历史数据和经验,帮助其做出更为准确和上下文相关的决策。
2. Embodiment(化身/体现)
-
化身指的是智能体的物理体现方式。通过传感器,智能体能够感知外部世界,包括颜色、声音、距离等多种信息。这些传感器可以帮助智能体获得丰富的环境感知数据。执行器则是智能体用来影响物理世界的“工具”,比如机械臂、轮子等,它们可以让智能体做出物理行为。
3. Environment(环境)
-
环境是智能体操作和交互的外部空间,涵盖了人与数字世界的多个层面。智能体可以从数据库中获取数据,从网页上抓取信息,使用API与外部系统进行通信。它还能与知识库、应用程序(如手机APP或软件)以及物理世界进行互动。智能体在与这些外部资源的交互中不断更新其内部记忆和状态。
4. Grounding(落地/基础化)与 Human Interaction(人机交互)
-
Grounding是指智能体通过与人类交互和工具使用,巩固其对现实世界的理解。这包括从用户反馈中学习,使用工具辅助任务完成等。
-
人机交互是智能体与人类之间的互动,如自然语言对话、协作完成任务等。这种互动帮助智能体提升任务处理的精确性。
5. Tool Augmentation(工具增强)与 Memory Update(记忆更新)
-
工具增强意味着智能体可以通过外部工具(如API或其他软件工具)扩展其能力,做出更复杂的决策或执行任务。
-
记忆更新指的是智能体通过与外界的互动,持续更新其工作记忆和长期记忆,这能让智能体从过去的经验中学习,提升后续的任务表现。
Multi-agent collaboration: division of labor for complex tasks
多智能体协作:复杂任务的分工
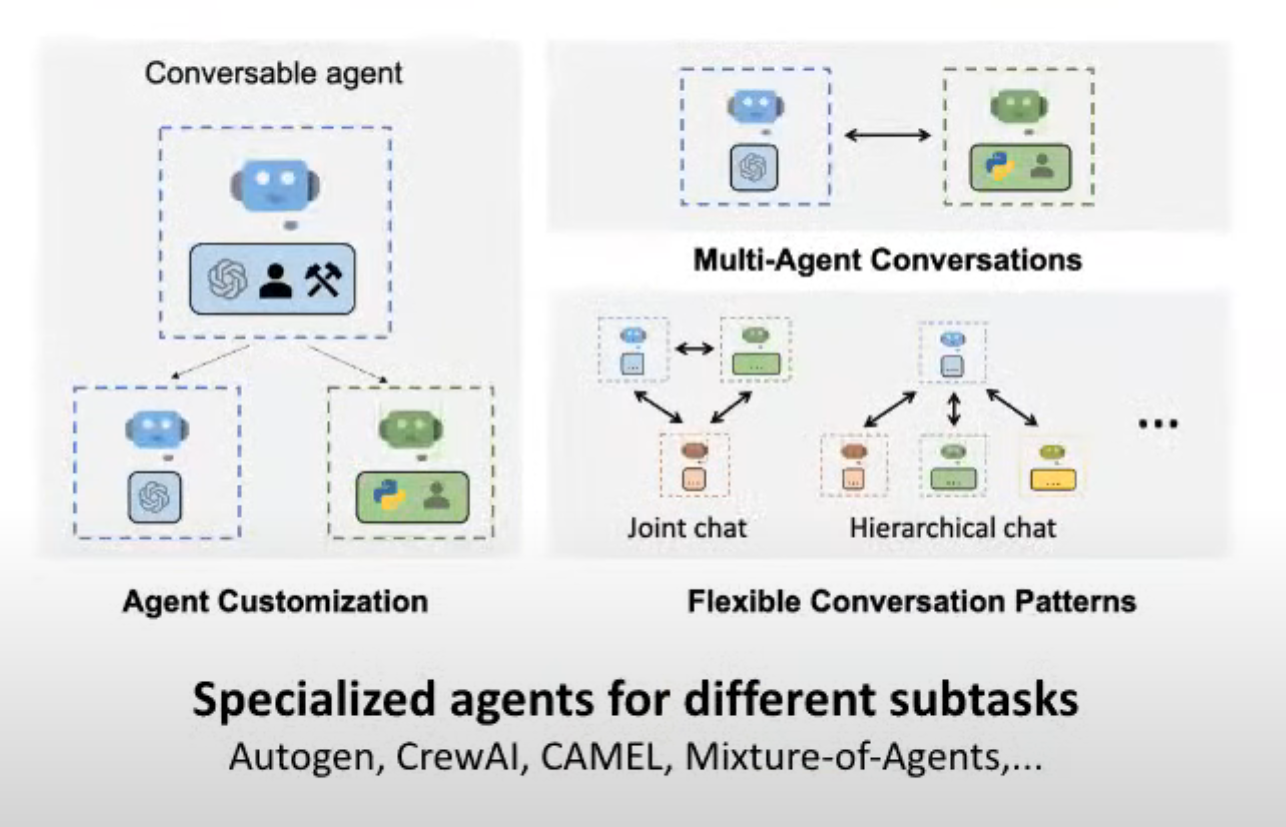
这张图展示了多智能体系统中的可定制智能体(Customizable Agents)和多智能体对话(Multi-Agent Conversations)的概念。主要分为三个部分:可对话智能体(Conversable Agent)、智能体定制(Agent Customization)以及灵活的对话模式(Flexible Conversation Patterns)。以下是这幅图的详细翻译与解释。
翻译:
图的标题:
-
Specialized agents for different subtasks(为不同子任务定制的专门智能体)
-
示例包括:Autogen、CrewAI、CAMEL、Mixture-of-Agents等。
Autogen
-
微软出品: Autogen 是微软推出的一款工具,旨在让大型语言模型(LLM)能够创建下一代应用程序。
-
核心功能: 它能将 LLM 变成一个个可以对话、执行任务的智能体。这些智能体可以互相协作,共同完成复杂任务。
-
应用场景: 从生成文本、翻译语言,到更复杂的任务如编写代码、创建数字内容,Autogen 的应用潜力巨大。
CrewAI
-
协同工作: CrewAI 的理念是让多个 AI 智能体像团队一样协同工作。
-
分工合作: 每个智能体都有自己的角色,比如研究员、作家、规划师。它们可以共同完成一项任务,就像一个真正的团队一样。
-
灵活性强: CrewAI 的灵活性很高,你可以自定义智能体,让它们适应不同的任务。
CAMEL
-
开源社区: CAMEL 是一个开源社区,专注于探索多智能体系统的扩展规律。
-
LLM 多智能体框架: CAMEL 提供了一个框架,可以将多个 LLM 结合起来,形成一个多智能体系统。
-
研究导向: 这个项目更偏向于研究,旨在深入了解多智能体系统的本质。
Mixture-of-Agents
-
模型聚合: Mixture-of-Agents(MoA)是一种通过聚合多个 LLM 的能力来增强性能的方法。
-
优势互补: 不同的 LLM 有不同的擅长领域,MoA 可以将它们的优势结合起来,从而获得更好的效果。
-
应用前景: MoA 在自然语言处理、机器翻译等领域有广阔的应用前景。
-
左上角:
-
Conversable Agent(可对话智能体):代表可以与用户或其他智能体进行对话的基础智能体。
左下角:
-
Agent Customization(智能体定制):展示了可以对智能体进行定制。图中分为两种定制后的智能体:
-
一个蓝色的智能体(表示一般的对话智能体),可能用于常规的对话任务。
-
一个绿色的智能体,带有Python标志,表示此智能体具有编程能力(Python)并且与用户协作完成任务。
-
右上角:
-
Multi-Agent Conversations(多智能体对话):展示了多个智能体之间的对话。
-
蓝色智能体与绿色智能体进行双向对话,表示这些智能体可以协作完成任务。
-
右下角:
-
Flexible Conversation Patterns(灵活的对话模式):
-
Joint chat(联合对话):多个智能体可以同时进行对话,协同工作,解决某个任务或问题。
-
Hierarchical chat(层级对话):在层级结构中,不同智能体承担不同角色,可能通过分层次的管理进行合作。
-
详细解释:
1. Conversable Agent(可对话智能体)
-
这是一个可以通过自然语言与人类或其他智能体交互的基础模块。在这个系统中,智能体可以接收指令,进行对话,处理任务。
2. Agent Customization(智能体定制)
-
智能体定制展示了如何通过扩展功能和工具来增强智能体的能力。
-
图中的蓝色智能体代表一般的对话能力,适用于常规交互。
-
绿色智能体则表示具备特定的技术能力(如Python编程)和合作特性,能够与用户协作编程或执行复杂任务。这展示了智能体可以根据需求定制,适应不同的任务环境。
-
3. Multi-Agent Conversations(多智能体对话)
-
多智能体对话展示了多个智能体之间的互动,可以通过合作完成复杂的任务。例如,一个智能体可能擅长语言处理,另一个可能专注于编程任务,两者可以互相协作。
4. Flexible Conversation Patterns(灵活的对话模式)
-
联合对话(Joint chat):多个智能体平等参与同一个对话,可以同时响应同一任务。这种模式适合需要多方协作的任务,如团队讨论。
-
层级对话(Hierarchical chat):智能体之间存在某种层级关系,一个智能体可能管理或指导其他智能体。这种模式可以用于复杂任务的管理和分配,类似于组织中的管理层级。
5. Specialized agents for different subtasks(为不同子任务定制的专门智能体)
-
图中列举的Autogen、CrewAI、CAMEL、Mixture-of-Agents等,都是专为不同子任务设计的智能体系统。这些系统可以根据不同任务需求进行智能体的定制或组合,以提高任务的处理效率。
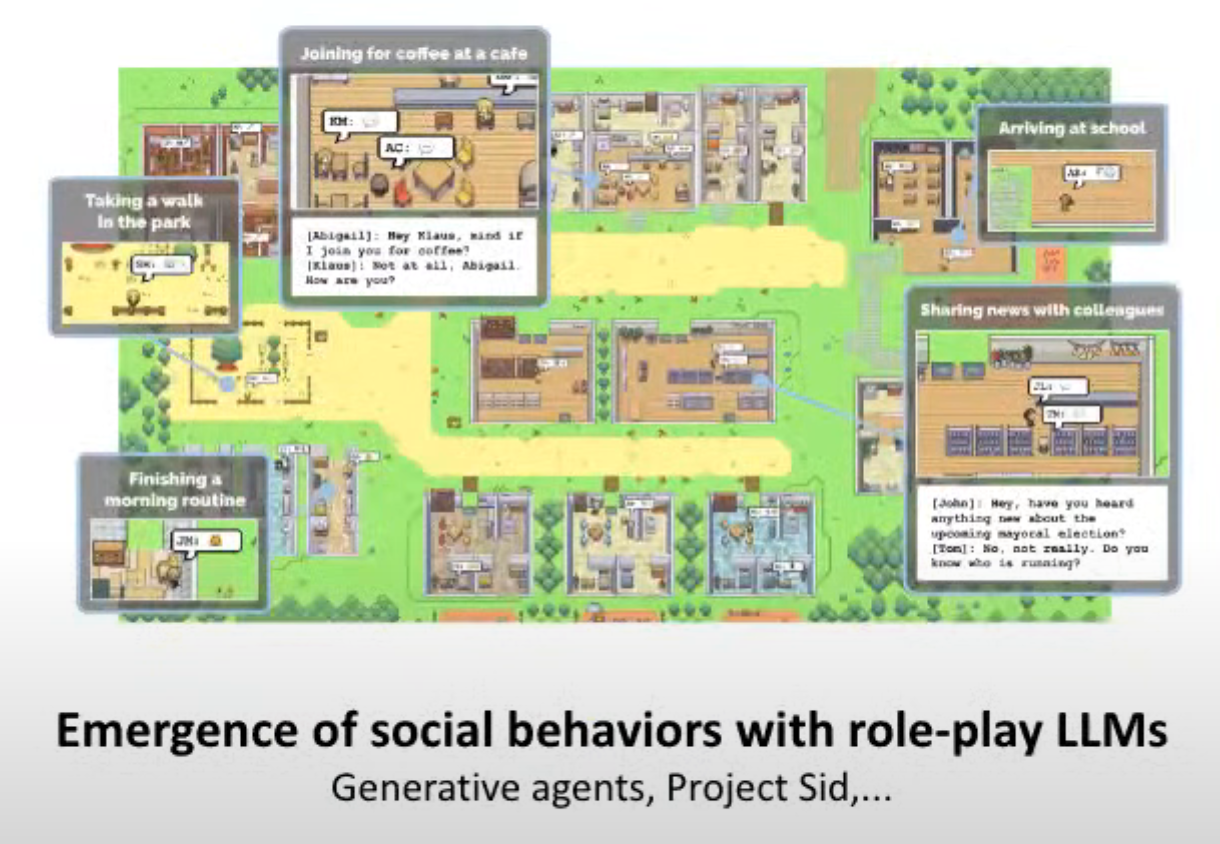
Emergence of social behaviors with role-play LLMs
角色扮演大预言模型的社会行为的出现
Generative agents, Project Sid, ...
Why empowering LLMs with the agent framework
幻灯片的原文如下:
-
Solving real-world tasks typically involves a trial-and-error process
-
Leveraging external tools and retrieving from external knowledge expand LLM’s capabilities
-
Agent workflow facilitates complex tasks
-
Task decomposition
-
Allocation of subtasks to specialized modules
-
Division of labor for project collaboration
-
Multi-agent generation inspires better responses
-
翻译:
-
解决现实世界任务通常涉及一个试错过程
-
利用外部工具和从外部知识中检索信息扩展了LLM的能力
-
智能体的工作流程促进了复杂任务的处理
-
任务分解
-
将子任务分配给专门的模块
-
通过分工协作完成项目
-
多智能体的生成启发更好的响应
-
Challenges for LLM agent deployment in the wild
这张幻灯片的原文如下:
-
Reasoning and planning
-
LLM agents tend to make mistakes when performing complex tasks end-to-end
-
-
Embodiment and learning from environment feedback
-
LLM agents are not yet efficient at recovering from mistakes for long-horizon tasks
-
Continuous learning, self-improvement
-
Multimodal understanding, grounding and world models
-
-
Multi-agent learning, theory of mind
-
Safety and privacy
-
LLMs are susceptible to adversarial attacks, can emit harmful messages and leak private data
-
-
Human-agent interaction, ethics
-
How to effectively control the LLM agent behavior, and design the interaction mode between humans and LLM agents
-
翻译:
-
推理与计划
-
大型语言模型(LLM)代理在执行端到端的复杂任务时容易犯错
-
-
具身性与从环境反馈中学习
-
LLM代理还未能高效地从长时间任务中的错误中恢复
-
持续学习、自我提升
-
多模态理解、基础认知和世界模型
-
-
多智能体学习、心智理论
-
安全与隐私
-
大型语言模型容易受到对抗性攻击,可能会发送有害信息并泄露私人数据
-
-
人机互动与伦理
-
如何有效控制LLM代理的行为,并设计人类与LLM代理的交互模式
-
Topics covered in this course
这张幻灯片的原文如下:
-
Topics covered in this course
-
Model core capabilities
-
Reasoning
-
Planning
-
Multimodal understanding
-
-
LLM agent frameworks
-
Workflow design
-
Tool use
-
Retrieval-augmented generation
-
Multi-agent systems
-
-
Applications
-
Software development
-
Workflow automation
-
Multimodal applications
-
Enterprise applications
-
-
Safety and ethics
-
翻译:
-
本课程涵盖的主题
-
模型核心能力
-
推理
-
计划
-
多模态理解
-
-
大型语言模型代理框架
-
工作流程设计
-
工具使用
-
检索增强生成
-
多智能体系统
-
-
应用
-
软件开发
-
工作流程自动化
-
多模态应用
-
企业应用
-
-
安全与伦理
-
Lecture 1, Denny Zhou
LLM Reasoning: Key Ideas and Limitations
大预言模型推理:关键idea和局限性
LLM is a "transformer" model trained to predict the next word.
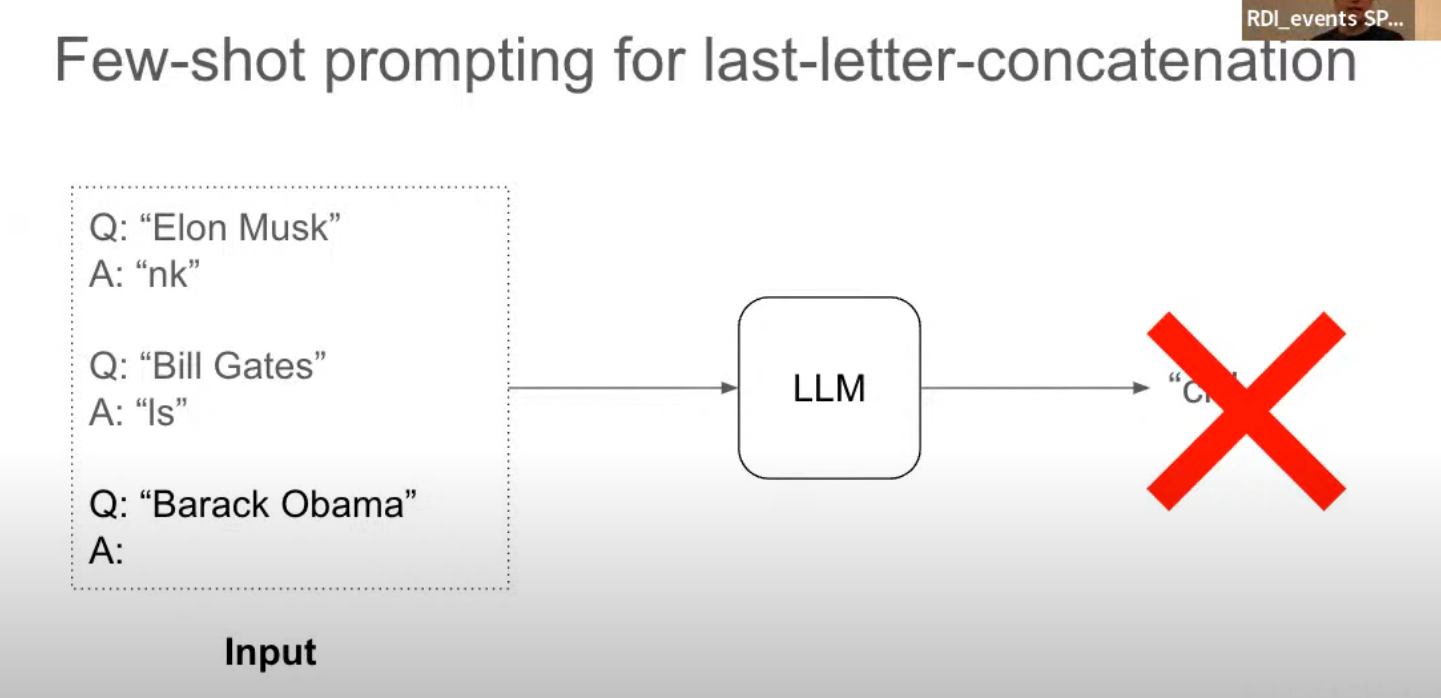
Few-shot prompting -> reasoning process

Key Idea: Derive the Final Answer through
Intermediate Steps
Regardless of training, fine-tuning, or prompting, when provided with examples that include intermediate steps, LLMs will generate responses that also include intermediate steps.
无论经过训练、微调还是提示,只要提供包含中间步骤的示例,大型语言模型(LLM)都会生成也包含中间步骤的响应。
In addition to intermediate steps, is it helpful to introduce reasoning strategies in demonstration examples?
除了中间步骤之外,在示例中引入推理策略是否有帮助?
demonstration examples: 示例
Least-to-Most Prompting
Enable easy-to-hard generalization by decomposition
从易到难提示:通过分解实现简单到复杂的泛化
泛化 在机器学习中,特别是自然语言处理领域,指的是模型在训练数据上学习到的知识,能够应用到未曾见过的新数据上的能力。简单来说,就是模型能够举一反三,不仅能解决训练时遇到的问题,还能处理新的、相似的问题。
SCAN (Compositional Generalization)
组合泛化
在大型语言模型(LLM)领域,组合泛化指的是模型能够将学到的知识组合起来,以应对从未见过的、由已知组件组成的复杂任务的能力。换句话说,就是模型能够通过将已知的知识模块进行组合,来解决新的问题。
CFQ (Compositional Generalization): Text-to-Code
Why interediate steps are helpful?
Transformer generating intermediate steps can solve any inherently serial problem as long as its depth exceeds a constant threshold
Transformer 生成中间步骤可以解决任何固有的串行问题,只要其深度超过一个常数阈值
Transformer generating direct answers either requires a huge depth to solve or cannot solve at all
Transformer 生成直接答案要么需要巨大的深度才能解决,要么根本无法解决
How to trigger step by step reasoning without using demonstration examples?
如何在不使用演示示例的情况下触发逐步推理?
LLMs as Analogical Reasoners
类比推理者
Adaptive generate relevant examples and knowledge, rather than using a fix set of examples.
自适应生成相关示例和知识,而不是使用固定的示例集。
Is it possible to trigger step by step reasoning even without using any prompt like "let's think step by step"?
是否可以在不使用“让我们一步一步思考”这样的提示的情况下,触发模型进行逐步推理?
—— Chain-of-Thought Reasoning without Prompting
无需提示的思维链推理
Key observations:
1: Pre-trained LLMs have had responses with step-by-step reasoning among the generations started with the top-k tokens.
2: Higher confidence in decoding the final answer when a step-by-step reasoning path is present.
主要观察结果:
1、预训练的大型语言模型(LLMs)在生成过程中,已经出现了包含逐步推理的响应。
2、当存在逐步推理路径时,对最终答案的解码置信度更高。
Generating intermediate steps are helpful, but...
Any concern on generating intermediate steps instead of direct answers?
是否担心生成中间步骤而不是直接答案?
Always keep mind that LLMs are probabilistic models(概率模型) of generating next tokens. They are not humans.

sampling:采样是指从模型生成的概率分布中随机选择一个元素的过程。这个概率分布代表了模型认为每个可能的下一个词(或其他token)出现的可能性。

Self-Consistency
Greatly improves step-by-step reasoning
自我一致性 显著增强了 逐步推理能力
自一致性 (Self-Consistency) 在大型语言模型 (LLM) 领域,指的是模型在处理同一问题或相似问题时,能够产生一致的、可靠的答案。换句话说,模型不会出现前后矛盾、自相矛盾的情况。
逐步推理 (Step-by-Step Reasoning) 则是指模型通过一系列中间步骤来解决问题,而不是直接给出最终答案。这类似于人类思考问题的方式,我们通常会将复杂问题分解成更小的子问题,逐一解决。
How about free-from answers? 开放式答案?
Universal Self-Consistency (USC) 通用自一致性
Ask LLMs to self-select the most consistant answer 让大型语言模型自行选择最一致的答案
Limitations
LLMs Can Be Easily Distracted by Irreverent Context
LLMs Cannot Self-Correct Reasoning Yet
Premise Order Matters in LLM Reasoning 前提的顺序在大型语言模型进行推理时会产生影响
oracle: 作为神谕(即权威的判断标准)
Oracle: Let LLMs self correct only when the answer is wrong
当大型语言模型的答案错误时,由一个权威系统来引导模型进行自我纠正。
Multi-LLM debate? Worse than self-consistency!
多个大型语言模型之间的辩论比模型自身的自洽性问题更严重。
Oracle feedback needed for LLM to self-correct
大型语言模型需要来自权威且可靠的外部反馈才能有效地进行自我纠错。
Self-debug naturally leverage unit tests as oracle
自我调试 自然地利用单元测试 作为权威的判断标准

幻灯片的原文如下:
-
Summary
-
Generating intermediate steps improves LLM performance
-
Training / finetuning / prompting with intermediate steps
-
Zero-shot, analogical reasoning, special decoding
-
-
Self-consistency greatly improves step-by-step reasoning
-
Limitation: irrelevant context, self-correction, premise order
-
翻译:
-
总结
-
生成中间步骤可以提高LLM的性能
-
通过中间步骤进行训练/微调/提示
-
零样本推理、类比推理、特殊解码
-
-
自我一致性极大地改善了逐步推理的能力
-
限制:无关上下文、自我纠错、前提顺序
-
解释:
这张幻灯片总结了通过生成中间步骤可以大幅提升大型语言模型(LLM)的性能,尤其是在训练、微调和提示的过程中,通过分步骤完成任务能够使模型更有效地解决复杂问题。零样本推理、类比推理等技术也是提升模型性能的关键。自我一致性,即模型在重复解答中保持一致的推理路径,能进一步提升其逐步推理的能力。不过,模型在处理一些问题时仍然存在局限性,例如无法区分无关的上下文、自我纠正中的错误和前提顺序问题。
What are next?
1: Define a right problem to work on
2: Solve it from the first principles
1:定义一个正确的问题来解决
2:从第一原则入手解决
第一性原理(First Principles)是一个哲学和科学方法论的概念,它强调从最基本的、不可再分的真理出发,通过逻辑推理和演绎,构建起复杂的知识体系。换句话说,就是将问题分解到最基本的组成部分,然后从这些基础部分重新构建起整个问题。
未完待续。。。















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









