







作者:罗罗攀,林学的研究僧。Python中文社区专栏作者,《从零开始学Python网络爬虫》作者。《从零开始学Python数据分析:视频教学版》作者。
之前我们用过传统的机器学习算法预测过泰坦尼克号数据的生还情况,这次我们使用神经网络算法来进行建模。
数据处理
数据情况
这里的数据来源与kaggle上的数据,读者可以自行进行下载,我们通过pandas读取,首先看看数据的基本情况。
import numpy as npimport pandas as pddata = pd.read_csv('titanic.csv')data.head()

我们使用的字段有下面几个:
Survived:是否生还
Pclass:船舱等级
Sex:性别
Age:年龄
SibSp:手足和配偶在船上的数量
Parch:双亲和手足在船上的数量
Fare:费用
Embarked:登船港口
我们把这些字段筛选出来。
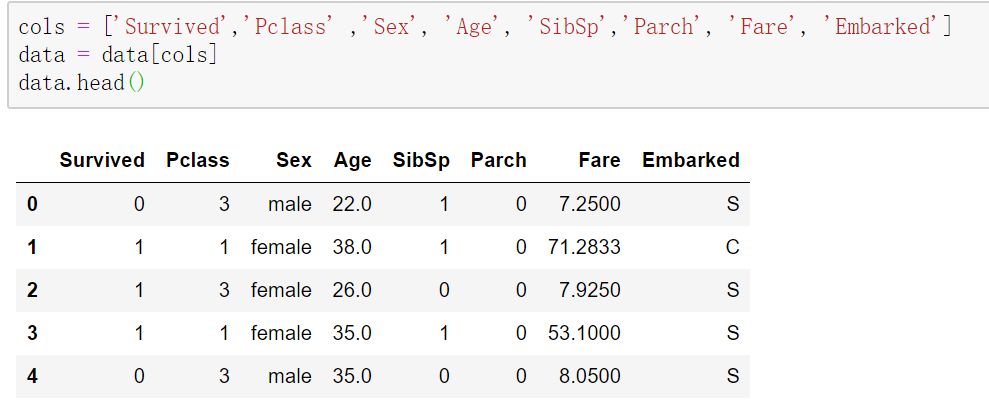
缺失值处理
首先,我们看看数据的缺失情况。
data.isnull().sum()

这里有两个字段有缺失值,age我们用平均值,embarked我们用最多的值进行填充。
age_mean = data['Age'].mean()data['Age'] = data['Age'].fillna(age_mean)data['Embarked'] = data['Embarked'].fillna('S')
性别和embarked
性别需要换成0和1
embarked进行哑变量
data['Sex']= data['Sex'].map({'female':0, 'male': 1}).astype(int)data = pd.get_dummies(data=data,columns=['Embarked'])
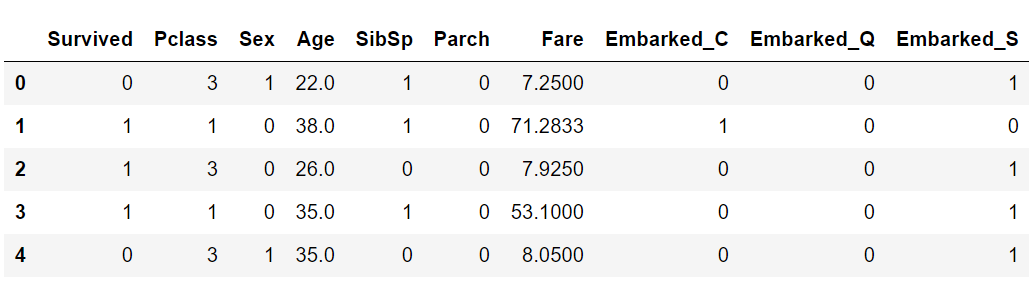
划分数据集
接着我们按0.8划分数据集。
X = data.iloc[:,1:]Y = data.iloc[:,0]from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=33)
标准化
最后我们把数据进行标准化,这样数据我们就处理完了。
from sklearn import preprocessingscale = preprocessing.MinMaxScaler()X_train = scale.fit_transform(X_train)X_test = scale.transform(X_test)
MLP建模
模型结构
模型结构为:
输入层,也就是9个神经元(对应9个字段)
隐藏层1,40个神经元
隐藏层2,30个神经元
输出层,1个神经元
建立模型
from keras.models import Sequentialfrom keras.layers import Dense,Dropoutmodel = Sequential()model.add(Dense(units=40, input_dim=9,kernel_initializer='uniform',activation='relu'))model.add(Dense(units=30,kernel_initializer='uniform',activation='relu'))model.add(Dense(units=1,kernel_initializer='uniform',activation='sigmoid'))
训练模型
model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy'])train_history =model.fit(x=X_train,y=y_train,validation_split=0.1,epochs=30,batch_size=30,verbose=2)
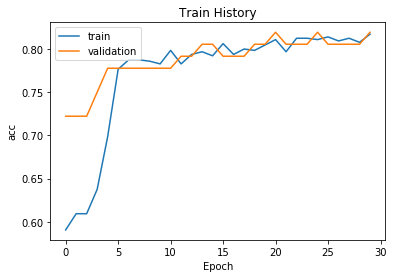
可以看出模型的精度还是比较高的。
测试
scores = model.evaluate(x=X_test,y=y_test)scores[1]# result 0.804
这样,我们的泰坦尼克号数据预测工作就完成了。


Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以公安部、工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

▼ 点击下方阅读原文,免费成为社区注册会员















 5179
5179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









