







泰坦尼克号
查看数据情况
训练集
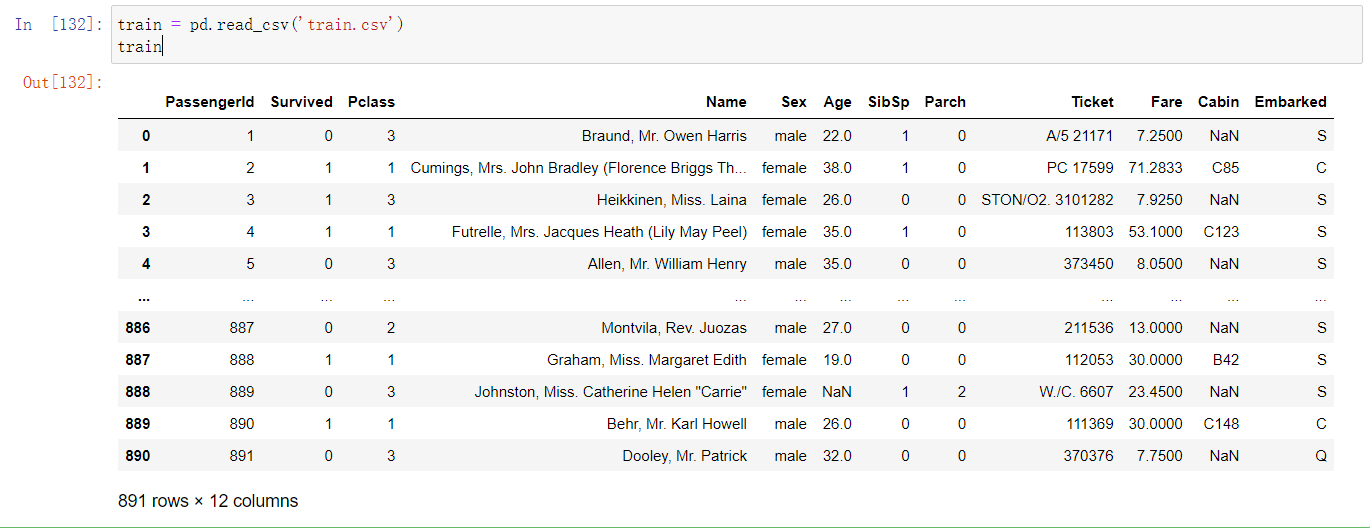
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train.info()
train.info()
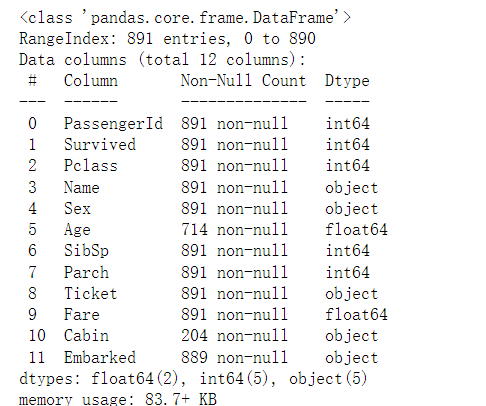
从中可以看出,该数据是存在缺失值的。
数据各字段说明:
-
Survived 是否存活(label)
-
PassengerId (乘客ID)
-
Pclass(用户阶级):1 - 1st class,高等用户;2 - 2nd class,中等用户;3 - 3rd
class,低等用户; -
Name(名字)
-
Sex(性别)
-
Age(年龄)
-
SibSp:描述了泰坦尼克号上与乘客同行的兄弟姐妹(Siblings)和配偶
(Spouse)数目;
-
Parch:描述了泰坦尼克号上与乘客同行的家长(Parents)和孩子(Children)数目;
-
Ticket(船票号)
-
Fare(乘客费用)
-
Cabin(船舱)
-
Embarked(港口):用户上船时的港口
获取数据集
链接:百度网盘
提取码:8888
说明:train是训练集,test是测试集(不含标签),gender_submission是测试集的标签(即测试集乘客的存活情况)。
数据处理部分
引入需要用的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
读取数据并合并测试集和训练集
合并的目的:便于一同对数据进行清洗
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
dataset = train.append(test,sort=False) # 将训练集和测试集合并在一起
查看数据的缺失情况
dataset.isnull().sum() # 统计缺失值

缺失值处理
注意这里的Survived不算缺失值,因为在测试集上不包含这一项。后面我们会通过模型预测这一项。
-Age为连续性变量,这里使用均值填充。
-Cabin缺失值太多,参考价值低,这里直接舍去。
-Embarked离散变量,它包含三个值,其中S最多,这里我们就直接填充S
-Fare,票价,这里也采用均值填充。
dataset['Age'] = dataset['Age'].fillna(dataset['Age'].mean()) # 使用平均值补充
dataset.drop(['Cabin'],axis=1,inplace=True) # 字段Cabin,缺失率很高,这里直接舍去
dataset.Embarked = dataset.Embarked.fillna('S') # Embarked中包含三个变量,其中S最多,这里我们就直接填充S
dataset['Fare'] = dataset['Fare'].fillna(dataset['Fare'].mean())
对性别进行编码,转换成01
目的:因为机器不能直接学习文本数据,需要转换成数值的。
sexdict = {'male':1,'female':0}
dataset.Sex = dataset.Sex.map(sexdict) # 对性别进行编码,转换成0,1

独热编码
目的:因为有些变量是离散型的,它分为几个值,我们可以将这几个值拆开(设置为01),探究每一个值对于总体的影响。
对Embarked和Pclass进行独热编码。
embarked2 = pd.get_dummies(dataset.Embarked, prefix = 'Embarked') # 进行独热编码,相当于将这一列的变量拆开,变为几个,设置为0,1
dataset = pd.concat([dataset,embarked2], axis = 1) ## 将编码好的数据添加到原数据上
dataset.drop(['Embarked'], axis = 1, inplace=True) ## 将原来的删除
embarked2 = pd.get_dummies(dataset.Pclass, prefix = 'Pclass')
dataset = pd.concat([dataset,embarked2], axis = 1)
dataset.drop(['Pclass'], axis = 1, inplace=True)

建立family_size特征
我们认为,家人数,应该跟存活率有关,所以新增一列家人数。SibSp和Parch分别代表了兄弟姐妹和配偶数量,以及父母与子女数量。通过这两个数字,我们可以计算出该乘客的随行人数,作为一列新的特征。
dataset['family'] = dataset.SibSp + dataset.Parch + 1
dataset.head(1)
删除一些影响不大的列
dataset.drop(['Ticket'], axis=1,inplace=True)
dataset.drop(['Name'], axis=1,inplace=True)
dataset.drop(['SibSp'], axis=1,inplace=True)
dataset.head(5)

相关性热度图
plt.figure(figsize=(14,12))
sns.heatmap(dataset.corr(),annot = True)
plt.show()
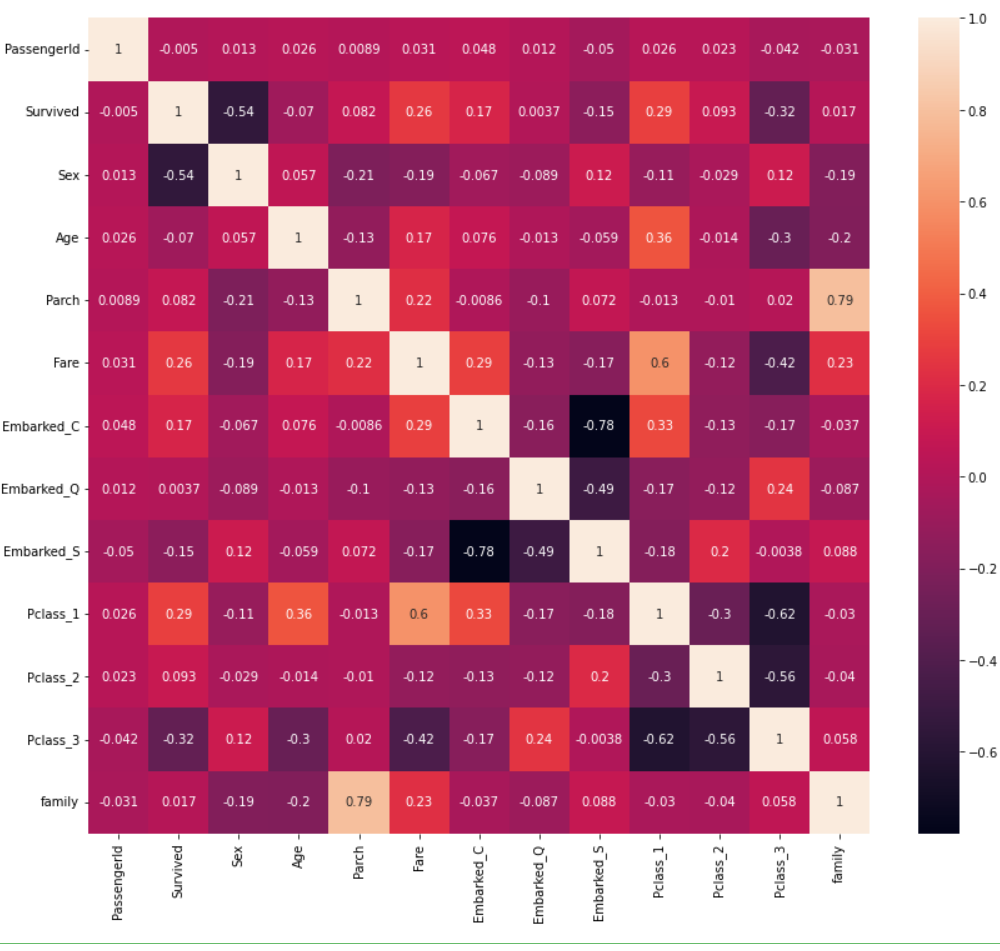
从热力图可以看出,生存与否,与Sex,Fare,Pclass_1相关度比较高。
模型训练与选择
首先,得到处理好的训练集和测试集。gender_submission.csv,文件中,保存的是测试集的存活情况。
x_train = dataset.iloc[0:891, :]
y_train = x_train.Survived
x_train.drop(['Survived'], axis=1, inplace =True)
x_test = dataset.iloc[891:, :]
x_test.drop(['Survived'], axis=1, inplace =True)
y_test = pd.read_csv('gender_submission.csv')#测试集
y_test=np.squeeze(y_test)
LogisticRegression
LogisticRegression 模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
model = LogisticRegression() # 实例化
model.fit(x_train,y_train) # 模型训练
# 保存为csv文件,一会放在kaggle上面测试下
prediction1 = model.predict(x_test)
result = pd.DataFrame({'PassengerId':y_test['PassengerId'].values, 'Survived':prediction1.astype(np.int32)})
result.to_csv("predictions1.csv", index=False)
将csv文件上传到kaggle上的得分为:
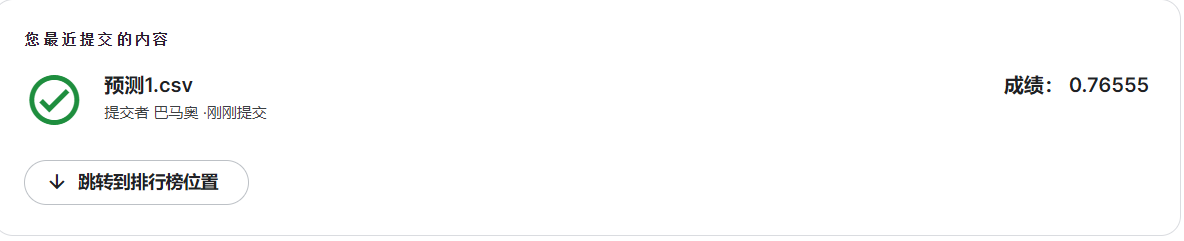
kaggle泰坦尼克号链接:泰坦尼克号
也可以自己评估预测模型:
accuracy_score(model.predict(x_test),y_test['Survived'])

随机森林Random Forest模型
from sklearn.ensemble import RandomForestClassifier
model2 = RandomForestClassifier(n_estimators=500, criterion='entropy', max_depth=5, min_samples_split=1.0,
min_samples_leaf=1, max_features='auto', bootstrap=False, oob_score=False, n_jobs=1, random_state=0,
verbose=0)
model2.fit(x_train, y_train) #模型训练
prediction2 = model2.predict(x_test) # 模型预测
result = pd.DataFrame({'PassengerId':y_test['PassengerId'].values, 'Survived':prediction2.astype(np.int32)})
result.to_csv("predictions2.csv", index=False) # 保存为csv文件
accuracy_score(y_test['Survived'], prediction2)
kaggle得分:
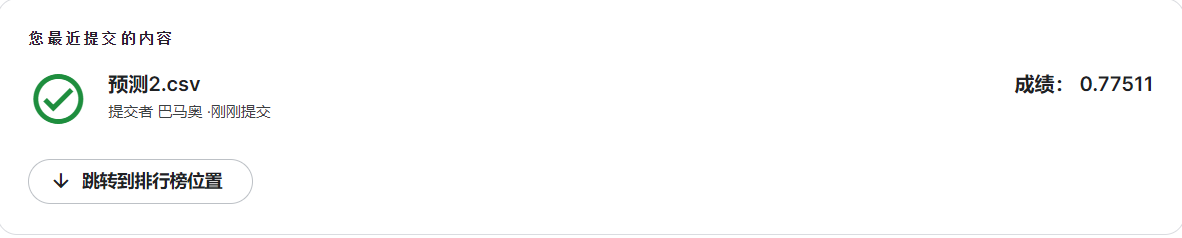
决策树模型
from sklearn.tree import DecisionTreeClassifier
model3 = DecisionTreeClassifier(criterion='entropy', max_depth=7, min_impurity_decrease=0.0)
model3.fit(x_train, y_train)
prediction3 = model3.predict(x_test)
result = pd.DataFrame({'PassengerId':y_test['PassengerId'].values, 'Survived':prediction3.astype(np.int32)})
result.to_csv("predictions3.csv", index=False)
accuracy_score(y_test['Survived'], prediction3)
kaggle 得分:

投票法
投票法是一种集成学习的方法。这里将会结合前面三个模型的预测结果,进行投票,少数服从多数原则。
如下图所示,3代表前面三个模型都预测该乘客是存活的,2代表三个模型,有2个预测是存活的,0代表三个模型都预测该乘客没有存活。
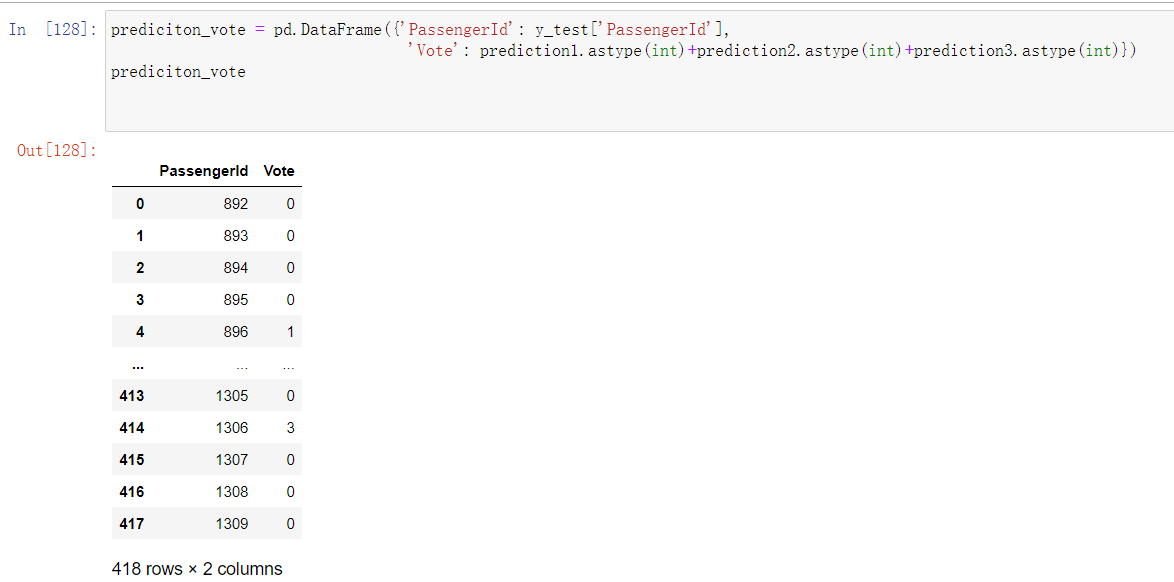
代码:
prediciton_vote = pd.DataFrame({'PassengerId': y_test['PassengerId'],
'Vote': prediction1.astype(int)+prediction2.astype(int)+prediction3.astype(int)})
vote = { 0:False,1:False,2:True,3:True}
prediciton_vote['Survived']=prediciton_vote['Vote'].map(vote) # 该操作将0,1,2,3映射到False和True上。
result = pd.DataFrame({'PassengerId':y_test['PassengerId'].values, 'Survived':prediciton_vote.Survived.astype(np.int32)})
result.to_csv("predictions4.csv", index=False) # 保存为csv文件
kaggle 得分:















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









