





F2FS:一种新的闪存文件系统
李昌万、沈东浩、黄周永、赵尚渊
S/W开发团队
存储业务
三星电子有限公司
目录
摘要
F2FS是一种专为现代闪存设备优化的Linux文件系统。该文件系统基于仅追加日志记录的原理构建,并根据闪存特性做出了关键设计决策。本文详细介绍了F2FS的主要设计思想、数据结构、算法和性能。
实验结果表明,F2FS具有卓越的性能;在最先进的移动系统上,综合工作负载下,其性能比EXT4高出3.1倍(iozone)和2倍(SQLite)。此外,它还将多个实际工作负载的运行时间最大程度地减少了40%。而在服务器系统上,相较于SATA SSD和PCIe SSD,F2FS分别提升了2.5倍和1.8倍的性能。
1.引言
NAND闪存已被广泛运用于各类移动设备,包括智能手机、平板电脑和MP3播放器等。此外,服务器系统开始采用闪存装置作为主要储存介质。虽然闪存广泛应用,但是它也存在一些限制:需先行执行写前擦除操作;在对已经完成擦除的块进行写入时必须按照顺序进行;并且每个擦除块都具有有限的可写次数。
在早期,许多消费电子设备直接采用“裸”NAND闪存。然而,随着存储需求的增长,越来越普遍地使用具备以下特性的“解决方案”,即通过专用控制器连接多个闪存芯片。这些控制器上运行的固件通常被称为FTL(闪存转换层),它们克服了NAND闪存的局限性,并提供了一个通用块设备抽象。这类例子包括eMMC(嵌入式多媒体卡)、UFS(通用闪存)和SSD(固态硬盘)。一般来说,与机械硬盘驱动器(HDD)相比,这些现代化的闪存设备具有更低的访问延迟。对于随机I/O操作而言,SSD执行速度比硬盘好上数个数量级。
然而,在特定的使用条件下,NAND闪存介质展现出其独特性。例如,Min等人[21]观察到频繁进行随机写入操作会导致底层介质内部产生碎片,并降低SSD的持续性能。研究表明,随机写模式非常普遍,在移动设备中资源受限的闪存解决方案上甚至更严重。Kim等人[12]对Facebook移动应用程序进行了量化分析,结果显示随机写比顺序写多150%,WebBench的随机写比顺序写多70%。此外,超过80%的I/O操作是随机进行的,而超过70%的随机写入是由像Facebook和Twitter等这样的应用程序通过fsync命令触发的[8]。这种特定的I/O模式源自于这些应用程序中大量使用的SQLite[2]。除非小心处理,否则频繁的进行随机写入和刷新操作可能会严重增加闪存设备的I/O延迟并缩短其寿命。
随机写入的有害影响可以通过log-structured file system(日志结构文件系统 LFS)方法[27]和copy-on-write(写时复制)策略来减少。例如,人们可能会认为像BTRFS[26]和NILFS2[15]这样的文件系统在NAND闪存上表现良好,很遗憾,它们没有考虑闪存设备的特性,并且在性能和设备寿命方面不可避免地是次优的。我们认为传统的文件系统设计策略虽然对hdd有益,但不能充分利用和优化NAND闪存介质。
本文介绍了一种针对现代闪存设备优化的新型文件系统F2FS的设计与实现。据我们所知,F2FS是第一个公开且广泛可用的文件系统,它从头开始设计以优化性能和具有通用块接口的闪存设备的使用寿命。本文介绍了该系统的设计与实现。
下面列出了设计F2FS的主要考虑因素:
- 闪存友好的磁盘布局(第2.1节)。F2FS采用三个可配置单元:segment, section and zone。它以segment为单位从许多独立的zones分配存储块。它以section为单位执行“清理”。这些单位的引入是为了与底层FTL的操作单位保持一致,以避免不必要的(但代价很高的)数据复制。
- 性价比高的索引结构(第2.2节)。LFS将数据和索引块写入新分配的空闲空间。如果一个叶子数据块被更新(并被写入某个地方),它的直接索引块应该被更新。一旦直接索引块被写入,它的间接索引块也应该被更新。这样的递归更新导致一连串的写,从而产生“wandering tree”(漫游树)问题。为了解决这个问题,我们提出了一种新的索引表——node address table(节点地址表)。
- 多头日志记录(第2.4节)。我们设计了一个有效的热/冷数据分离方案,应用于日志记录期间(即块分配期间)。它并发地运行多个活动日志段,并根据预期的更新频率将数据和元数据追加到单独的日志段。由于发挥了闪存存储设备的介质并发特性,多个活动日志段可以同时运行,而无需频繁的管理操作,这样由于多次日志记录而导致的性能下降问题(与单段日志记录相比)就变得微不足道了。
- 自适应日志记录(第2.6节)。F2FS基本上建立在只追加日志的基础上,来实现将随机写转换为顺序写。然而,在高存储空间使用率时,它将日志策略更改为线程日志[23],以避免较长的写延迟。实际上,线程日志策略是将新数据写入脏段中的空闲空间,而不会在前台清理它。这种策略在现代闪存设备上很有效,但在hdd上可能行不通。
- Fsync加速与前滚恢复(第2.7节)。F2FS通过最小化所需的元数据写入和使用有效的前滚机制恢复同步数据,优化了小批量数据同步写入,以减少fsync请求的延迟。
简而言之,F2FS建立在LFS的概念之上,但又与最初的LFS提案有很大的不同,有新的设计考虑。我们把F2FS实现成linux文件系统,并与两个先进的linux文件系统——EXT4 和 BTRFS进行比较。我们还评估了NILFS2,这一Linux中LFS的另一种实现。我们的评估考虑了两个目标系统:移动设备系统和服务器系统。在服务器系统中,我们研究了SATA SSD和PCIe SSD上的文件系统。我们在这项工作中获得和呈现的结果更加突出体现了F2FS的总体理想性能特征。
在本文的其余部分中,第2节首先描述了F2FS的设计和实现。第3节提供了性能结果和论述。我们在第4节描述相关工作,并在第5节结束。
2.F2FS的设计与实现
2.1.磁盘布局
F2FS的磁盘数据结构经过精心布置,以匹配底层NAND闪存的组织和管理方式。如图1所示,F2FS将整个卷划分为固定大小的segments。segments是F2FS中的基本管理单位,用于确定初始文件系统元数据布局
一个section由连续的segments组成,一个zone由一系列的sections组成。这些单位在日志记录和清理过程中非常重要,这将在2.4节和2.5节中进一步讨论。

F2FS将整个卷分为六个区域:
- Superblock (SB 超级块) 具有F2FS的基本分区信息和默认参数,在格式化时给出,不可更改。
- Checkpoint (CP 检查点) 保存文件系统状态,有效NAT/SIT集的位图(见下文),孤儿inode列表和当前活动segments的摘要项。一个成功的“检查点包”应该在给定的时间点上——在突然断电事件后的恢复点(第2.7节),存储一致的F2FS状态。CP区域在两个segments(#0和#1)中存储两个检查点包:一个用于最后的稳定版本,另一个用于中间(过时)版本。
- Segment Information Table (SIT Segment 信息表) 包含segment信息,例如有效块的数量和“Main”区域中所有块的有效性的位图(见下文)。在清理过程中,检索SIT信息以选择受害段并识别其中的有效块(第2.5节)。
- Node Address Table (NAT 节点地址表) 是一个用来定位存储在Main区域的所有“节点块”的块地址表。
- Segment Summary Area (SSA Segment 摘要区域) 存储表示Main区域中所有块的所有者信息的摘要项。例如,父节点号及其节点/数据偏移。SSA表项在清理期间迁移有效块之前识别父节点块。
- Main Area(主区域)由4KB的块填充。每个块被分配并键入为节点或数据。节点块包含数据块的索引节点或索引,而数据块包含目录或用户文件数据。节点块包含索引节点或数据块的索引,而一个数据块包含目录或用户文件数据。注意,section不会同时存储数据和节点块。
给定上述磁盘上的数据结构,让我们演示一下文件查找操作是如何完成的。假设文件“/dir/file”,F2FS执行以下步骤:(1)通过读取从NAT获取的地址块来获取根索引节点;(2)在根索引节点块的数据块中,搜索名为dir的目录项,并获得其索引节点号;(3)通过NAT将检索到的索引节点号转换为物理位置;(4)通过读取相应的块获取名为dir的索引节点;(5)在dir 索引节点中,识别名为file的目录项,最后通过对file重复步骤(3)和(4)获得文件索引节点。实际数据可以从Main区域检索,并通过相应的文件结构获得索引。
2.2.文件结构
最初的LFS引入了索引节点映射来将索引节点号转换为磁盘上的位置。相比之下,F2FS利用扩展索引节点映射的“节点”结构来定位更多的索引块。每个节点块都有一个唯一的标识号“节点ID”。NAT以节点ID为索引,提供所有节点块的物理位置。有三种类型的节点块:节点索引,直接和间接节点。一个索引节点块包含文件的元数据,如文件名、索引节点号、文件大小、atime和dtime。直接节点块包含数据的块地址,而间接节点块则具有用于定位其他节点块的节点ID。
如图2所示,F2FS采用基于指针的文件索引方法,利用直接和间接节点块来避免更新传播,即“漫游树”问题[27]。在传统的 LFS 设计中,如果叶数据被更新,则其直接和间接指针块会被递归地更新。然而,F2FS仅更新一个直接节点块及其NAT项,从而有效地解决了“漫游树”问题。例如,当一个4KB的数据被追加到8MB至4GB的文件中,LFS会递归地更新两个指针块,而F2FS仅更新一个直接节点块(不考虑缓存效应)。对于大于4GB的文件,LFS会额外再更新一个指针块(总共三个),而F2FS仍然仅更新一个块。

一个索引节点块包含指向文件数据块的直接指针,以及两个单间接指针、两个双间接指针和一个三间接指针。F2FS支持内联数据和内联扩展属性,即将小型数据或扩展属性内嵌于索引节点块之中。内联技术不仅减少了空间需求,还提升了I/O性能。请注意,许多系统具有小文件和少量的扩展属性。默认情况下,如果文件大小小于3,692个字节,F2FS会启用数据内联功能。F2FS在索引节点块中预留了200个字节用于存储扩展属性。
2.3.目录结构
在F2FS中,一个4KB的目录项(“文件名”)块由一个位图和两组成对命名的slots组成。该位图用于表示每个slots是否有效。一个slot包含一个哈希值、索引节点号、文件名的长度和文件类型(例如,普通文件、目录和符号链接)。目录文件构造多级哈希表,以有效地管理大量数据项。
当F2FS在目录中查找给定的文件名时,它首先计算文件名的哈希值。然后,从第0级开始,逐步遍历到索引节点中记录的最大分配级别。在每一级,它会扫描一bucket的两个或四个目录项块,时间复杂度为O(log(目录项数量))。为了更快速地找到一个目录项,它会依次比较位图、哈希值和文件名。
当倾向于选择大型目录(例如,在服务器环境中)时,用户可以设置F2FS,为众多目录项初始分配空间。借助较低层级的大型哈希表,F2FS能更为迅速地达到目标目录。
2.4.多头日志记录
与只有一个大型日志区域的LFS不同,F2FS维护了六个主要的日志区域,以最大化实现冷热数据分离的效果。F2FS静态的定义了节点和数据块的三个温度级别——热、温、冷,如表1总结。
表1:多活动段中的对象分离情况

直接节点块被视为比间接节点块更为活跃,因为它们的更新更为频繁。间接节点块包含节点ID,仅在新增或移除专用节点块时会被写入。直接节点块和目录的数据块被视为热,因为它们的写入模式与常规文件的块有显著的不同。满足以下三个条件之一的数据块被视为冷:
- 通过清理操作移动的数据块(第2.5节)。鉴于它们在较长时间内持续有效,我们预计在不久的将来它们将继续保持有效。
- 用户标记为“冷”的数据块。为此,F2FS支持扩展属性操作。
- 多媒体文件数据。它们可能呈现出一次写入后续只读的特点。F2FS通过比对文件的扩展名与已注册的扩展名来识别它们。
默认情况下,F2FS 允许六个日志进行写操作。如果用户认为在特定存储设备和平台上调整写入流数量至两个或四个会获得更佳的效果,那么可以这样做。如果使用六个日志,则每个日志段直接对应表1中列出的一个温度级别。在四个日志的情况下,F2FS将每个节点和数据类型的冷日志和暖日志组合在一起。F2FS分配两个日志,一个用于节点,另一个用于数据类型。第3.2.3节探讨了日志头的数量如何影响数据分离的有效性。
F2FS引入了可配置的分区以与FTL兼容,目的在于减少垃圾回收(GC)的开销。根据数据与“闪存块”的关联性,FTL算法主要分为三类(块关联、集合关联和完全关联)[24]。一旦为数据闪存块分配了初始数据,日志闪存模块尽可能地整合数据更新,如同EXT4中的日志[18]。日志闪存块可以专门用于单个数据闪存块(块关联) [13],也可以用于所有的数据闪存块(完全关联) [17],还可以用于一组连续的数据闪存块(集合关联) [24]。现代FTL采用全关联或集合关联的方法,以有效处理随机写入。请注意,F2FS采用多头日志记录并行写入节点和数据块,这将混合分离的块(在文件系统级别)到同一个闪存块中。为了避免错位,F2FS 将活动日志映射到不同的区域,以便在 FTL 中将它们分隔。这种策略预计对集合关联 FTL 有效。多头日志记录与最近提出的“多流”接口[10]也是完美的搭配。
2.5.清理
清理是一个回收分散和无效块的过程,并确保有空闲segments以供进一步记录。因为一旦底层存储容量被填满,就会不断地进行清理,所以限制与清理相关的开销对于F2FS(以及一般的任何LFS)的持续性能非常重要。在F2FS中,清理是在一个segments内完成的。
F2FS 以两种不同的方式执行清理,前台与后台。仅当没有足够的空闲区域时,才会触发前台清理。同时,一个内核线程会周期性地唤醒,在后台执行清理。清理过程分为三个步骤:
(1)受害者选择。清理过程首先在非空sections中识别受害者所在的section。在LFS清理过程中,有两种众所周知的受害者选择策略——贪心和成本效益[11,27]。贪心策略选择有效块数量最少的段。直观地说,这种策略控制了迁移有效块的开销。F2FS采用贪心策略进行前台清理,以最小化应用程序可见的延迟。此外,F2FS保留了少量未使用的容量(默认情况下为存储空间的5%),以便在高存储使用率下,清理过程有足够的操作空间。第3.2.4节研究了利用率对清理成本的影响。
另一方面,在F2FS的后台清理过程中实行成本效益策略。该策略不仅基于使用率,还基于其“年龄”来选择目标数据块。F2FS通过计算该数据块中各段年龄的平均值来推算其年龄,而该数据块的年龄又可从SIT中记录的最后一次修改时间获取。借助这种成本效益策略,F2FS获得了再次分离热数据和冷数据的机会。
(2)有效块的识别和迁移。在选定受害section后,F2FS需迅速识别该section中的有效块。为此,F2FS在SIT中为每个segment维护一个有效性位图。通过扫描这些位图,F2FS识别出所有有效块后,从SSA信息中检索包含其索引的父节点块。如果这些块有效,F2FS会将它们迁移到其他空闲日志中。
在进行后台清理时,F2FS并不实际发出I/O操作来迁移有效块。相反,F2FS将块加载到页缓存中,并将其标记为脏块。然后,F2FS仅将它们保留在页缓存中,以待内核工作线程稍后将其写到闪存介质中。这种延迟的迁移不仅减轻了对前台I/O活动的性能影响,还允许少量写入操作被合并。当正常I/O或前台清理正在进行时,后台清理不会启动。
(3) 后清理流程。在所有有效块迁移完毕后,一个受害区域被标记为成为新空闲区域的候选(在F2FS中称为“预空”区域)。在创建检查点之后,该区域正式成为空闲区域,准备进行重新分配。我们采取这一步骤是因为,如果在创建检查点之前预空区域被再次使用,那么在突然断电的情况下,文件系统可能会丢失之前检查点引用的数据。
2.6.自适应日志记录
最初的LFS引入了两种日志记录策略,普通日志记录和线程日志记录。在普通日志记录中,数据块被写入到干净的segments中,从而产生严格的顺序写入。即使用户提交了许多随机的写入请求,只要存在足够的可用日志空间,这个过程也会将它们转换为顺序写入。然而,随着可用空间逐渐变为零,该策略开始产生高额的清理开销,从而导致性能严重下降(在恶劣条件下,性能下降超过90%,详见第3.2.5节)。另一方面,线程日志记录将数据块写入到现有脏segments中的空洞中(已无效、废弃的空间)。该策略不需任何清理操作,但可能会触发随机写,从而可能降低性能。
F2FS同时实施两种策略,并根据文件系统状态动态地在它们之间切换。具体来说,如果有超过k个干净的section,其中k是一个预设的阈值,则启动普通日志记录。否则,启动线程日志记录。默认情况下,k被设置为总section的5%,并且可以进行配置。
当存在分散的空洞时,线程日志记录可能导致不必要的随机写。然而,相较于就地更新文件系统,这些随机写入通常展现出更优的空间局部性,因为F2FS在搜索其他脏segment中的更多空洞之前,会首先填充当前脏segment中的所有空洞。Lee等人[16]的研究表明,在具有强空间局部性的条件下,闪存设备的随机写入性能更为出色。F2FS系统巧妙地选择放弃常规日志记录,而采用线程日志记录模式,以追求更为稳定的持续性能,详见第3.2.5节。
2.7.检查点和恢复
F2FS采用检查点技术,以在突然断电或系统崩溃时提供一致的恢复点。每当在诸如同步、卸载和前台清理等操作中需要保持一致状态时,F2FS会触发检查点过程,具体如下:(1)所有位于页缓存中的脏节点和记录块都被刷新;(2)中止常规的写入操作,包括如create()、 unglink()和mkdir()等系统调用;(3)文件系统的元数据、NAT、SIT和SSA被写入到磁盘上的特定区域;(4)最后,F2FS将一个包含以下信息的检查点包写入到CP区域:
- 页眉和页脚 分别位于包的开头和末尾。F2FS在页眉和页脚中保存一个版本号,该版本号在创建检查点时进行递增。该版本号用于在装载时区分两个记录包之间的最新稳定包;
- NAT 和 SIT位图 NAT和SIT位图表示构成当前包的NAT和SIT块的集合;
- NAT和SIT日志 中保存了少量近期修改的NAT和SIT条目,以防止频繁的NAT和SIT更新;
- 活动segments的摘要块 由内存中的SSA块组成,这些块未来将被转存到SSA区域;
- 孤儿块 保存“孤儿索引节点”的信息。如果在索引节点被关闭之前被删除(例如,当两个进程同时打开一个文件,然后一个进程将其删除时),它应当被标记为孤儿索引节点,以便F2FS在突然断电后能够恢复它。
2.7.1.回滚恢复
突然断电后,F2FS会回滚至最近的一致性检查点。为了在创建新包时确保至少有一个稳定的数据包,F2FS会维护两个检查点包。如果检查点包的页眉和页脚内容一致,F2FS会认为该包有效。否则,该包将被丢弃。
同样,F2FS也管理两组NAT和SIT块,这两组块通过每个检查点包中的NAT和SIT位图来区分。当F2FS在创建检查的点过程中写入更新后的NAT或SIT块时,它会交替地将这些块写入到这两组块中的一组,然后标记对应的位图以指向其新的组。
如果NAT或SIT条目中有少量条目被频繁更新,F2FS会写入多个4KB大小的NAT或SIT块。为了降低这种开销,F2FS在检查点包中实现了NAT和SIT日志。这种方法减少了I/O的数量,从而也降低了检查点的延迟。
在装载时的恢复过程中,F2FS通过检查页眉和页脚来搜索有效的检查点包。如果两个检查点包均有效,F2FS会通过比较它们的版本号来选取最新的一包。在选取到最新的有效检查点包后,它会检查是否存在孤儿索引节点块。如果存在,它会删除所有被它们引用的数据块,并释放孤儿索引节点。然后,在前滚恢复过程成功完成后,F2FS启动文件系统服务,该服务具有由其位图引用的一组一致的NAT和SIT块,如下所述:
2.7.2.前滚恢复
像SQLite这样的数据库应用经常将少量数据写入文件,并通过fsync来确保持久性。为支持fsync,一种直接的方法是触发检查点并使用回滚模型来恢复数据。然而,这种方法可能会导致性能下降,因为检查点会写入所有与数据库文件无关的节点和记录块。
表2:实验平台。括号中的数字是顺序和随机性能指标,单位是MB/s。

F2FS采用了一种高效的前滚恢复机制,用以提升fsync的性能。其主要思想是仅写入数据块及其直接节点块,而不涉及其他节点或F2FS元数据块。为了在回滚至稳定检查点后有选择地找到数据块,F2FS在直接节点块内保留了一个特殊标志。
F2FS执行前滚恢复,其过程如下。若我们将最后一个稳定检查点的日志位置记为N。(1)F2FS收集在N+n位置上带有特殊标志的直接节点块,同时构建它们的节点信息列表。其中,n代表自上一个检查点以来已更新的块数。(2)利用该列表中的节点信息,它将最近写入的节点块(记为N-n)加载到页面缓存中。(3)然后,它将N-n与N+n之间的数据索引进行比较。(4)如果检测到不同的数据索引,它将使用N+n中存储的新索引来刷新缓存的节点块,并最终将其标记为“脏”的。一旦完成前滚恢复,F2FS将执行更新检查点的操作,将所有内存中的更改存储到磁盘上。
3.评估
3.1.实验设置
我们在两大类目标系统——移动系统和服务器系统上评估了F2FS。我们以Galaxy S4智能手机代表移动系统,以x86平台代表服务器系统。表2总结了这些平台的规格。
对于目标系统,我们将F2FS从3.15-rc1主线内核分别反向移植到3.4.5和3.14内核。在移动系统中,F2FS运行在最先进的eMMC存储器上。在服务器系统的情况下,我们使用SATA SSD和(更高速)PCIe SSD。请注意,括号内标注的值代表每个存储设备的基本顺序读/写和随机读/写带宽(MB/s)。我们使用了一个简单的单线程应用程序,通过O DIRECT模式触发512KB的顺序I/O和4KB的随机I/O,从而对带宽进行了测量。
我们将F2FS与EXT4[18]、Btrfs[26]和NILFS2[15]进行比较。EXT4是一个广泛使用的原地更新文件系统。Btrfs是一个写时复制文件系统,而NILFS2是一个LFS。
表3总结了我们的基准测试及其特性,包括生成的I/O模式、被访问文件的数量和最大大小、工作线程的数量、读写比(R/W)以及是否有fsync系统调用。对于移动系统,我们执行并展示了iozone[22]的结果,以研究基本的文件I/O性能。
由于移动系统会频繁地执行代价高昂的随机写入和fsync调用,我们使用了mobibench[8]——一个宏基准测试——来评估SQLite的性能。我们还回顾了从“Facebook”和“Twitter”应用(分别被称为“Facebook-app”和“Twitter-app”)中收集的两个系统调用跟踪,这些跟踪基于一种真实的用户使用情境[8]。
对于服务器工作负载,我们采用了名为Filebench的合成基准测试[20]。它模拟了多种文件系统工作负载,便于快速、直观地评估系统性能。在该基准测试中,我们采用了四种预设的工作负载——视频服务器、文件服务器、varmail和oltp。它们在I/O模式和fsync的使用上存在差异。
视频服务器主要进行顺序读写操作。 文件服务器预分配了80,000个大小为128KB的文件,随后启动50个线程,每个线程都随机创建和删除文件,并对随机选择的文件进行随机读写和数据追加。因此,这个工作负载代表了一个场景,其中许多大型文件经历了缓冲区的随机读写操作,但没有进行fsync操作。

3.2.结论
本节展示了通过深入块迹线级别分析得到的性能结果和深入分析。我们考察了各种I/O模式(如读、写、fsync和discard3)、I/O数量及请求大小分布。为了确保比较的直观性和一致性,我们将性能结果与EXT4的性能进行了标准化。我们注意到,性能基本上取决于顺序I/O和随机I/O之间的速度差距。在计算能力较低、存储速度较慢的移动系统中,I/O模式及其数量是主要的性能因素。对于服务器系统,CPU效率与指令执行开销和锁争用成为了一个额外的关键因素。
3.2.1.移动系统的性能
图3(a)展示了顺序读写(SR/SW)与随机读写(RR/RW)带宽在1GB文件上的iozone结果。在SW模式中,NILFS2的性能相较于EXT4下降了近50%,这是由于其根据自身的数据刷新策略,定期触发代价高昂的同步写入所导致的。在RW场景下,F2FS的性能相较于EXT4提升了3.1倍,因为它可以将90%的4KB随机写入转化为512KB的连续写入(图中未直接显示)。Btrfs的性能也相当不错,性能提升了1.8倍,因为它通过“写时复制”策略产生连续写入。虽然NILFS2将随机写入转化为顺序写入,但由于代价高昂的同步写入,其性能仅提升了10%。而且,它的写入请求数量比其他文件系统高出30%。在RR场景中,所有文件系统的性能相当。Btrfs的性能略有降低,这与其树索引的开销有关。图3(b)给出了以每秒事务数(TPS)衡量的SQLite性能,并与EXT4的性能进行了标准化。我们在由1000条记录构成的数据库上,测量三种类型的事务——插入、更新和删除——在预写日志(WAL)模式下。此日志模式在SQLite中被认为是速度最快的。F2FS展现出相较于其他文件系统显著的性能优势,其性能比EXT4高2倍。对于此工作负载,F2FS的前滚恢复策略带来了巨大的效益。实际上,与EXT4相比,F2FS减少了约46%的数据写入。由于索引开销很大,
BTRFS比EXT4多写3倍的数据,导致性能下降近80%。与EXT4相比,NILFS2以几乎相同的数据写入量表现出类似的性能。图3(c)展示了Facebook应用和Twitter应用跟踪的标准化运行时间。这些应用使用SQLite存储数据,与EXT4相比,F2FS减少了20%(Facebook应用)和40%(Twitter应用)的运行时间。

3.2.2.服务器系统性能
图4展示了所研究的文件系统在使用SATA和PCIe SSD时的性能表现。每个条形图都代表了标准化性能(即,如果条形图的值大于1,则表示性能提升)。
视频服务主要产生连续的读写操作,且无论使用何种设备,所有结果均未显示出所研究的文件系统之间的性能差异。这证明了对于常规的顺序I/O,F2FS的性能并未出现下降。
文件服务器的I/O模式各不相同;图5展示了来自SATA SSD上所有文件系统的块跟踪的比较。深入分析发现,EXT4生成的写入请求中,仅有0.9%为512KB,而F2FS则有6.9%(未在图中直接显示)。此外,EXT4频繁发出小型的丢弃命令,这在SATA驱动器上导致了明显的命令处理开销,它调整了所有数据写入覆盖的块地址中的三分之二,并且近60%的丢弃命令针对的是小于256KB的地址空间。相比之下,F2FS只在触发检查点时丢弃以分段为单位的过时空间,它调整了38%的块地址空间,且没有小型的丢弃命令。这些差异导致了2.4倍的性能提升(图4(a))。另一方面,Btrfs的性能降低了8%,因为它在所有写入请求中,仅占3.8%执行512KB的数据写入。另外,如图5(c)所示,在读取服务期间,它通过少量的丢弃命令修剪了47%的块地址空间(相当于所有丢弃命令的75%)。而在NILFS2的情况下,如图5(d)所示,多达78%的写入请求都是512KB。然而,其周期性的同步数据刷新使得在EXT4上的性能提升限制在1.8倍。在PCIe SSD上,所有文件系统的性能表现相当。这主要是因为研究中采用的PCIe SSD能够很好地实现并发缓冲写入。

在varmail的测试场景中,F2FS的性能相较于EXT4分别高出2.5倍与1.8倍。由于varmail在并发fsync的同时产生了众多的小型写入,这一结果进一步凸显了F2FS在fsync处理上的效率优势。而Btrfs的性能与EXT4相当,NILFS2在PCIe SSD上的表现则相对出色。
oltp工作负载在单个800MB的数据库文件上生成大量随机写入和fsync调用(与varmail不同,后者涉及许多小文件)。与EXT4相比,F2FS显示出16%和13%的性能优势,分别在SATA SSD和PCIe SSD上。另一方面,Btrfs和NILFS2在PCIe驱动器上的表现都相当糟糕。PCIe驱动器上的快速命令处理和高效随机写入似乎转移了性能瓶颈点,并且,BTRFS和NILFS2表现出不稳定的性能。
到目前为止,我们的结果已经清楚地证明了F2FS整体设计和实现的相对有效性。现在我们将检查F2FS日志记录和清理策略的影响。
3.2.3.多头日志记录效果
本节主要研究F2FS的多头日志策略的有效性。我们并未展示涵盖多种不同工作负载的全面评估结果,而是集中关注了一个能够直观展现我们设计意图的实验。在此实验中,我们采用了“清理前给定脏段中的有效块数”作为度量标准。如果热数据和冷数据分离做得很好,那么脏segment要么没有有效块,要么在一个segment中有最大有效块数(默认配置下为512)。如果存储在segment中的所有(热)数据都已无效,则老化的脏segment将不存在有效块。相比之下,填满有效块的脏segment可能会保存冷数据。
在我们的实验中,我们同时运行两个工作负载:varmail和复制jpeg文件。Varmail在100个目录中写入了10,000个文件,总共6.5GB的数据。我们复制了大约5000个jpeg文件每个500KB,因此产生2.5GB的数据写入。注意,F2FS静态地将jpeg文件归类为冷数据。在这些工作负载完成后,我们计算所有脏segments中有效块的数量。我们把日志的数量从2改成6时,再重复这个实验。
图6给出了结果。在两个日志中,超过75%的segments拥有超过256个有效块,而具有512个有效块的“满segments”非常少。因为双日志配置只拆分数据段(占所有脏segments的85%,未显示)节点segments(15%),多头日志记录的有效性相当有限。再添加两个日志会在一定程度上改变情况;它增加了少于256个有效块的segments的数量。它还略微增加了接近满segments的数量。
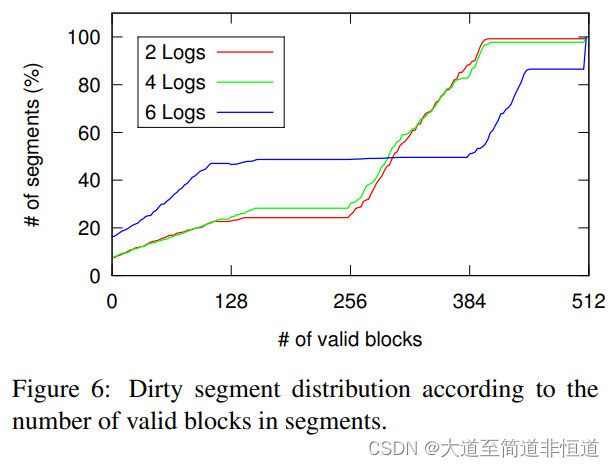
最后,通过六个日志,我们清楚地看到了冷热数据分离的好处;具有零有效块的预释放segments的数量和满segments的数量显着增加。此外,有更多的segments具有相对较少的有效块(128或更少)和具有较多的有效块(384或更多)。这种双峰分布的一个明显影响是提高了清理效率(因为清理开销取决于受害段中有效块的数量)。
在结束本节之前,我们做了一些观察。首先,结果表明,更多的日志,可以更精细地分离数据温度,通常带来更多的好处。然而,在我们执行的特定实验中,4个日志的好处相比与2个日志显得相当微不足道。如果我们将冷数据与热数据和温数据(如表1中定义的)分开,而不是将热数据与温数据和冷数据分开(默认),那么结果看起来会有所不同。其次,由于脏segments中的有效块的数量将随着时间的推移而逐渐减少,图6中曲线的最左弯将向上移动(根据所选择的日志配置以不同的速度移动)。因此,如果我们老化文件系统,我们期望多头日志记录的好处会变得更加明显。充分研究这些观察结果超出了本文的范围。
3.2.4.清理开销
在本节中,我们量化了清理对F2FS的影响。为了专注于文件系统级别的清理开销,我们故意在SSD中留下足够的空闲空间,以确保在实验期间不会发生SSD级别的垃圾回收。为此,我们格式化一个250GB的SSD,并获得一个(仅)120GB的分区。
预留5%的空间用于额外的存储空间后(第2.5节),我们将剩余容量分为“冷”和“热”区域。我们通过如下方式填充两个区域,构建反映不同文件系统利用率水平的四种配置:80%(60(冷):20(热))、
90%(60:30), 95%(60:35)和97.5%(60:37.5)。然后,我们迭代10次实验,每次运行随机将4KB大小的20GB数据写入热区。
图7展示了在两个指标上绘制的前十次运行的结果:性能(吞吐量)和写入放大因子(WAF)。这些结果与在干净的SSD上获得的结果进行了对比。我们可以得出两个主要的观察结果。首先,文件系统利用率增加会导致WAF增大,同时性能下降。但在80%的利用率下,性能下降和WAF的增加并不显著。在第三次运行时,文件系统的空闲segments就用完了,性能有所降低。在运行期间,它从普通日志记录切换成线程日志记录,因此,性能表现平稳。(我们将在3.2.5节中重新讨论自适应线程日志记录的影响)在第三次运行之后,几乎所有数据都是通过线程日志记录写入的。在这种情况下,需要清理的不是数据,而是记录节点。由于我们把利用率从80%提高到了97.5%,垃圾回收量增加了,性能下降变得更加明显。利用率在97.5%时,性能损失约30%,WAF为1.02。
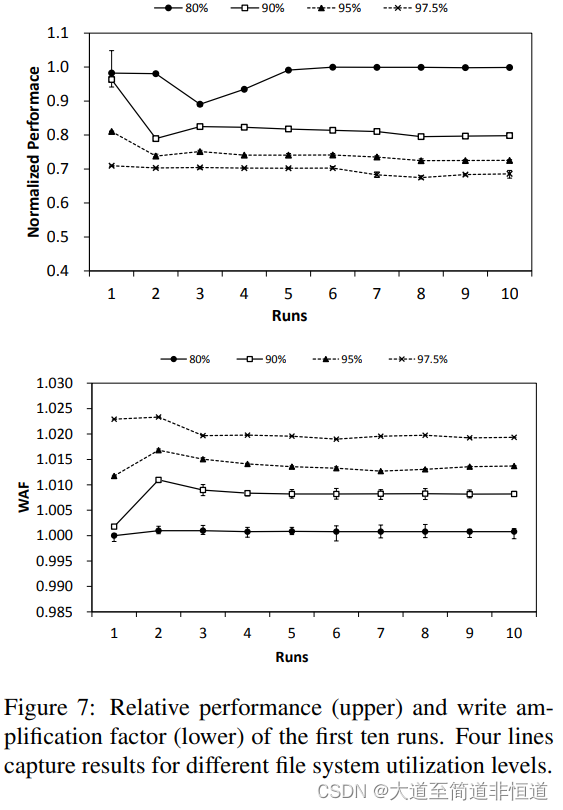
第二个观察结果是,在高使用率水平下,F2FS不会显著增加WAF;自适应日志记录在降低WAF方面起着重要作用。注意,线程日志导致随机写入,而普通日志导致顺序写入。相对较高的随机写入开销迫使追加日志(append-only logging)作为许多文件系统的首选操作模式,但我们的设计选择(切换到线程日志)是合理的,因为,当文件系统存在碎片化时,由于高WAF,清理开销可能会变得非常高,而SSD具有出色的随机写入性能。本节中的结果显示,F2FS在高使用率水平下成功地控制了清理开销。
展示后台清理的积极影响并不简单,因为后台清理在系统繁忙时受到抑制。尽管如此,我们还是通过在系统运行时插入10分钟或更长时间的空闲时间,在90%的存储空间使用率水平下,观测到了10%的性能提升。
3.2.5.自适应日志性能
本节将深入探讨这个问题:带有线程日志的F2FS自适应日志策略的效果如何?默认情况下,当空闲section的数量低于总section的5%时,F2FS会从普通日志记录切换到线程日志记录。我们比较这个默认配置(“F2FS 自适应”)和“F2FS 普通”,后者一直保持普通日志记录策略不变。为了进行实验,我们在SATA SSD上设计并进行了以下两个直观的测试。
- 文件服务测试。这个测试首先用数百个1GB文件填充了94%的目标存储区域。然后测试运行文件服务工作负载四次,并测量性能趋势(图8(a))。当我们重复实验时,底层闪存存储设备以及文件系统会变得碎片化。因此,工作负载的性能应该会下降。请注意,我们无法使用NILFS2执行此测试,因为它停止时显示“no space”错误报告。
EXT4在第一轮和第二轮时表现出最小的性能损失——17%。相比之下,BTRFS和F2FS(特别是“F2FS normal”)的性能分别下降了22%和48%,因为它们没有找到足够的顺序空间。另一方面,
“F2FS自适应”使用线程日志服务51%的写操作(图中没有显示),并成功地将第二轮的性能损失限制在22%(与BTRFS相当,与EXT4相差不大)。因此,与EXT4相比,F2FS总体上保持了两倍或更多的性能改进比率。所有文件系统在第二轮之后性能都保持稳定。
进一步检测发现,由于前台清理,“F2FS普通”比“F2FS自适应”多27%的写入。BTRFS的巨大性能损失部分是由于大量使用小的丢弃命令。
- iozone测试 这个测试首先创建16个4GB的文件和额外的1GB文件,直到它填满设备容量(~ 100%)。然后运行iozone对16个4GB的文件执行4KB的随机写操作。每个文件的总写容量为512MB。我们重复这个步骤十次,这是相当严苛的,因为BTRFS 和 NILFS2都没有完成测试,出现了“没有空间”的错误。请注意,从理论上讲,EXT4(就地更新文件系统)在这个测试中表现最好,因为EXT4发出随机写操作,而不创建额外的文件系统元数据。另一方面,像F2FS这样的日志结构文件系统的清理成本可能很高。还要注意,此工作负载会将存储设备中的数据分割成碎片,并且由于工作负载反复触发设备内部的垃圾回收操作,存储性能将受到影响。
在EXT4下,性能下降大约是75%(图8(b))。在“F2FS 普通”的情况下,正如预期的那样,性能下降到非常低的水平(从第3轮开始不到EXT4的5%),因为文件系统和存储设备都忙于清理碎片容量,以回收新空间进行日志记录。“F2FS自适应”可以更优雅地处理这种情况;在最初的几轮测试中(当碎片不严重时),它的性能比EXT4要好,并且随着实验的进行和更多的随机写入,它的性能与EXT4非常接近。
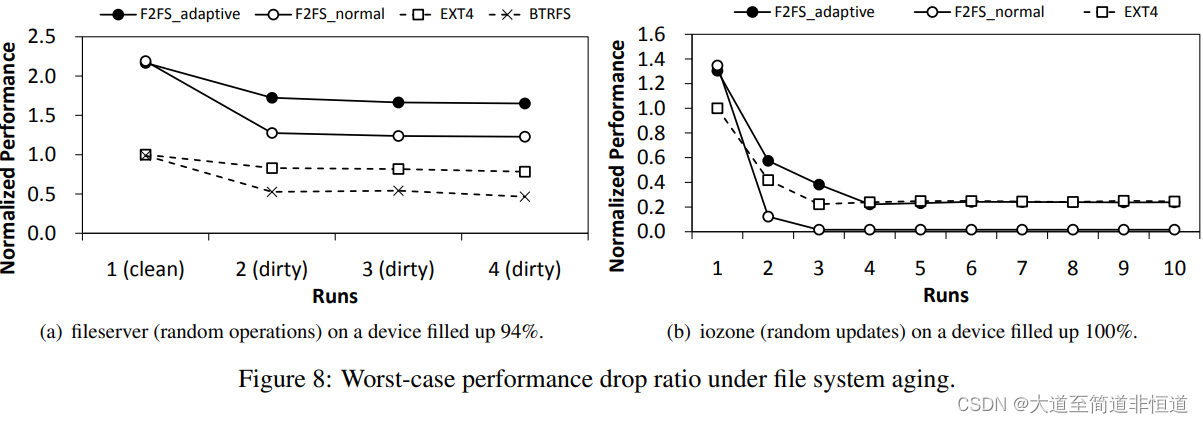
本节中的两个实验表明,自适应日志记录对于F2FS在高存储使用率水平下维持其性能至关重要。自适应日志记录策略也可以有效地限制由于碎片导致的F2FS性能下降。
4.相关的工作
本节将讨论与我们之前的工作相关的三类文件系统——日志结构文件系统、针对闪存的文件系统和特定于FTL的优化的文件系统。
4.1.日志结构文件系统(LFS)
从Rosenblum等人[27]提出的原始LFS开始,在日志结构文件系统上已经做了很多工作(用于hdd)。Wilkes等人提出了一种堵孔方法,将受害segment的有效块移到孔中,即移到其他脏segment的无效块中[30]。Matthews等人提出了一种自适应清理策略,他们基于成本效益评估在普通日志记录策略和堵孔策略之间进行选择[19]。Oh等人[23]证明了线程日志在高使用率的卷中有更好的性能。F2FS是根据以前的工作和实际工作负载和设备进行调优的。
许多研究集中在热数据和冷数据的分离上。Wang和Hu[28]提出在缓冲缓存中区分活动数据和非活动数据,而不是将它们写入单个日志并在清理时将它们分开。它们通过监视访问模式来确定哪些数据是活动的。Hylog[29]采用混合方法;它对热页使用日志记录来实现高随机写性能,对冷页使用覆盖来降低清理开销。
SFS[21]是基于NILFS2实现的ssd文件系统。与F2FS一样,SFS使用日志记录来消除随机写带来的性能损耗。为了降低清理开销,他们根据“更新可能性”(或热度)(通过跟踪每个块的写计数和使用时间来确定),将缓冲区缓存中的热数据和冷数据分开[28]。他们根据测量到的热度值,使用迭代量化的方法将segments划分为组。
与依靠运行时监控访问模式来区分热/冷数据的分离方法[21,28]不同,F2FS使用简单有效的信息来估计更新的可能性,例如文件操作(追加或覆盖)、文件类型(目录或常规文件)和文件扩展名。虽然我们的实验结果表明我们采用的简单方法相当有效,但可以在F2FS中加入更复杂的运行时监控方法来精细跟踪数据热度。
NVMFS是一种实验性文件系统,它采用两种不同的存储介质:NVRAM和NAND闪存SSD[25]。这种从NVRAM上快速字节可寻址存储功能用于存储热数据和元数据。此外,对SSD的写入与F2FS一样是顺序的。
4.2.闪存文件系统
已经出现了许多文件系统,它们适用于使用原始NAND闪存作为存储介质的嵌入式系统[1,3,6,14,31]。这些文件系统直接访问NAND闪存,同时解决所有芯片级问题,如磨损平衡和坏块管理。与这些系统不同,F2FS的目标是带有专用控制器和固件(FTL)来处理底层任务的闪存设备。
这种闪存设备更为普遍。
Josephson等人提出了直接文件系统(DFS)[9],它利用运行在主机运端的FTL的特殊支持,包括原子更新接口和非常大的逻辑地址空间,简化了文件系统的设计。然而,DFS仅限于特定的闪存设备和系统配置,并且不是开源的。
4.3.FTL优化
为了提高FTL水平的随机写入性能,已经做了很多工作,并与F2FS分享了一些设计策略。大多数ftl使用日志结构更新方法来克服闪存不能覆盖写的限制。DAC[5]提供了一种页面映射FTL,它通过在运行时监控更新频率对数据进行聚类。为了减少大型页映射表的开销,DFTL[7]根据需要动态地将页映射的一部分加载到工作内存中,使RAM有限的设备有了页映射的随机写入优势。
混合映射(或日志块映射)是块映射的扩展,用以改善随机写入性能[13,17,24]。它具有比页面映射更小的映射表,而对于具有大量局部访问的工作负载而言,它的性能可以与页面映射一样好。
5.综述
F2FS是一个成熟的Linux文件系统,专为现代闪存存储设备而设计,预计将在业界得到更广泛的采用。本文介绍了F2FS的关键设计和实现细节。我们的评估结果凸显了与其他现有文件系统相比,我们的设计决策和权衡是如何带来性能优势的。F2FS相当年轻——它在2012年底被合并到Linux内核3.8中。我们期望新的优化和特性将不断添加到文件系统中。
感谢
作者感谢审稿人和我们的导师Ted Ts 'o提出的建设性意见,这有助于提高本文的质量。这项工作是长期和专注的团队努力的结果;没有之前的F2FS
团队成员的大量贡献(尤其是Jaegeuk)金教授、李哲哲、金炳根、李世焕、高锡荣、朴东彬、朴舜勋)等人的工作是不可能完成的。
参考
[1] Unsorted block image file system. http: //www.linux-mtd.infradead.org/ doc/ubifs.html.
[2] Using databases in android: SQLite. http: //developer.android.com/guide/ topics/data/data-storage.html#db.
[3] Yet another flash file system. http://www. yaffs.net/.
[4] A. B. Bityutskiy. JFFS3 design issues. http:// www.linux-mtd.infradead.org, 2005.
[5] M.-L. Chiang, P. C. Lee, and R.-C. Chang. Using data clustering to improve cleaning performance for flash memory. Software-Practice and Experience, 29(3):267–290, 1999.
[6] J. Engel and R. Mertens. LogFS-finally a scalable flash file system. In Proceedings of the International Linux System Technology Conference, 2005.
[7] A. Gupta, Y. Kim, and B. Urgaonkar. DFTL: a flash translation layer employing demand-based selective caching of page-level address mappings, volume 44. ACM, 2009.
[8] S. Jeong, K. Lee, S. Lee, S. Son, and Y. Won. I/O stack optimization for smartphones. In Proceedings of the USENIX Anual Technical Conference (ATC), pages 309–320, 2013.
[9] W. K. Josephson, L. A. Bongo, K. Li, and D. Flynn. DFS: A file system for virtualized flash storage. ACM Transactions on Storage (TOS), 6(3):14:1– 14:25, 2010.
[10] J.-U. Kang, J. Hyun, H. Maeng, and S. Cho. The multi-streamed solid-state drive. In 6th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 14), Philadelphia, PA, 2014. USENIX Association.
[11] A. Kawaguchi, S. Nishioka, and H. Motoda. A flash-memory based file system. In Proceedings of the USENIX Anual Technical Conference (ATC), pages 155–164, 1995.
[12] H. Kim, N. Agrawal, and C. Ungureanu. Revisiting storage for smartphones. ACM Transactions on Storage (TOS), 8(4):14, 2012.
[13] J. Kim, J. M. Kim, S. H. Noh, S. L. Min, and Y. Cho. A space-efficient flash translation layer for compactflash systems. IEEE Transactions on Consumer Electronics, 48(2):366–375, 2002. [14] J. Kim, H. Shim, S.-Y. Park, S. Maeng, and J.-S. Kim. Flashlight: A lightweight flash file system for embedded systems. ACM Transactions on Embedded Computing Systems (TECS), 11(1):18, 2012.
[15] R. Konishi, Y. Amagai, K. Sato, H. Hifumi, S. Kihara, and S. Moriai. The Linux implementation of a log-structured file system. ACM SIGOPS Operating Systems Review, 40(3):102–107, 2006. [16] S. Lee, D. Shin, Y.-J. Kim, and J. Kim. LAST: locality-aware sector translation for NAND flash memory-based storage systems. ACM SIGOPS Operating Systems Review, 42(6):36–42, 2008. [17] S.-W. Lee, D.-J. Park, T.-S. Chung, D.-H. Lee, S. Park, and H.-J. Song. A log buffer-based flash translation layer using fully-associative sector translation. ACM Transactions on Embedded Computing Systems (TECS), 6(3):18, 2007.
[18] A. Mathur, M. Cao, S. Bhattacharya, A. Dilger, A. Tomas, and L. Vivier. The new ext4 filesystem: current status and future plans. In Proceedings of the Linux Symposium, volume 2, pages 21–33. Citeseer, 2007.
[19] J. N. Matthews, D. Roselli, A. M. Costello, R. Y. Wang, and T. E. Anderson. Improving the performance of log-structured file systems with adaptive methods. In Proceedings of the ACM Symposium on Operating Systems Principles (SOSP),pages 238–251, 1997.
[20] R. McDougall, J. Crase, and S. Debnath. Filebench: File system microbenchmarks. http://www. opensolaris.org, 2006.
[21] C. Min, K. Kim, H. Cho, S.-W. Lee, and Y. I. Eom. SFS: Random write considered harmful in solid state drives. In Proceedings of the USENIX Conference on File and Storage Technologies (FAST), pages 139–154, 2012.
[22] W. D. Norcott and D. Capps. Iozone filesystem benchmark. URL: www.iozone.org, 55, 2003. [23] Y. Oh, E. Kim, J. Choi, D. Lee, and S. H. Noh. Optimizations of LFS with slack space recycling and lazy indirect block update. In Proceedings of the Annual Haifa Experimental Systems Conference, page 2, 2010.
[24] C. Park, W. Cheon, J. Kang, K. Roh, W. Cho, and J.-S. Kim. A reconfigurable FTL (flash translation layer) architecture for NAND flash-based applications. ACM Transactions on Embedded Computing Systems (TECS), 7(4):38, 2008.
[25] S. Qiu and A. L. N. Reddy. NVMFS: A hybrid file system for improving random write in nand-flash SSD. In IEEE 29th Symposium on Mass Storage Systems and Technologies, MSST 2013, May 6-10, 2013, Long Beach, CA, USA, pages 1–5, 2013.
[26] O. Rodeh, J. Bacik, and C. Mason. Btrfs: The linux b-tree filesystem. ACM Transactions on Storage (TOS), 9(3):9, 2013.
[27] M. Rosenblum and J. K. Ousterhout. The design and implementation of a log-structured file system. ACM Transactions on Computer Systems (TOCS), 10(1):26–52, 1992.
[28] J. Wang and Y. Hu. WOLF: A novel reordering write buffer to boost the performance of logstructured file systems. In Proceedings of the USENIX Conference on File and Storage Technologies (FAST), pages 47–60, 2002.
[29] W. Wang, Y. Zhao, and R. Bunt. Hylog: A high performance approach to managing disk layout. In Proceedings of the USENIX Conference on File and Storage Technologies (FAST), pages 144–158, 2004.
[30] J. Wilkes, R. Golding, C. Staelin, and T. Sullivan. The HP AutoRAID hierarchical storage system. ACM Transactions on Computer Systems (TOCS), 14(1):108–136, 1996.
[31] D. Woodhouse. JFFS: The journaling flash file system. In Proceedings of the Ottawa Linux Symposium, 2001.














 1442
1442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









