









一.引言
使用Hive执行 select count(*) from table 这种基础语法竟然爆出 GC overhead limit exceeded,于是开始了新的踩坑之旅
二.hive语句与报错
hive -e "select count(*) from $table where day between '20201101' and '20201130';"统计一下总数结果报错,一脸懵逼
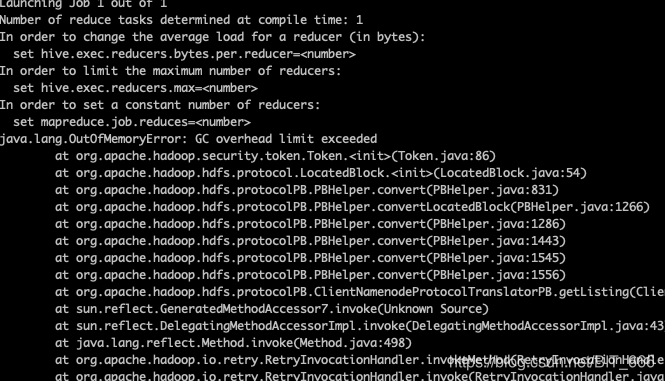
三.解决方案尝试
1.增加内存
既然是内存不足,那就增加堆内存尝试一下,尝试失败:
set mapreduce.map.java.opts=-Xmx4096m -XX:+UseConcMarkSweepGC;2.数据倾斜
第一个是map阶段groupBy阶段防止倾斜的,第二个是防止join阶段出现数据倾斜设置的,在count(*)场景下显然都没有用:
set hive.groupby.skewindata=true
set hive.optimize.skewjoin=true3.小文件过多
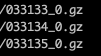
查看原始表的文件数达到3w+,加起来30天可想而知小文件有多少。小文件多会开很多map,一个map开一个JVM去执行,大量任务的初始化,启动,执行会浪费大量的资源,所以报内存溢出,所以解决需要从源头解决即将原始表生成的文件数量减少。
如果原始任务是map-reduce,最简单的直接设置 reduce 的数量:
set mapred.reduce.tasks = 100我的原始任务是纯map,没有reduce所有需要通过控制map的量去控制输出文件个数:
之前hive常用参数整理详细介绍了怎么调整map的个数,这里简单写一下,主要调大hive.merge.size.per.task 提高每个task处理的数据量即可减小map,参数调大一倍,map数量少一倍。原始文件数调小后,再运行之前的count任务就可以正常执行了。当时以为count(*)任何时候都有可以无压力运行还是太天真了。
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
set hive.merge.mapfiles = true;
set hive.merge.size.per.task = 256000000;四.总结
1.为什么只有map的原始任务生成的小文件太多?
原表的生成脚本是从一个小分区很多的大表中筛选一部分数据出来,所以原表的数据就很分散,如果原表不执行小文件合并则会导致map出很多小文件,所以在生成原表时就要注意控制文件数量。
2.怎么判断 GC overhead limit exceeded 的缘由?
内存溢出有很多情况,如果像上面遇到的情况一样,无法开始正常的MR任务,无法显示启动了多少个map reduce,则可能是因为启动资源过大造成的内存溢出,这时候就要看表原始的数据,数据量是不是有问题;如果是map和reduce执行了一段时间显示内存溢出的问题,很有可能是脚本设计不合理或者原始数据倾斜,则需要通过set参数来进行调整,最常见的就是group by,或者map,reduce处理的数据量不均匀导致。



















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











