






pandas库简介
Pandas库是一个开源的数据分析工具,建立在NumPy之上,提供了用于数据操作和分析的数据结构和函数。Pandas库的主要作用包括:
提供了两种主要的数据结构:Series和DataFrame。Series是一维带标签的数组,类似于字典;DataFrame是二维的表格型数据结构,类似于电子表格或SQL表。
支持数据的读取和写入:Pandas可以读取和写入多种数据格式,如CSV、Excel、SQL数据库、JSON等,方便进行数据的导入和导出。
数据清洗和处理:Pandas提供了丰富的函数和方法,用于数据的清洗、处理、转换和筛选,帮助用户快速处理数据。
数据分析和统计:Pandas提供了各种统计函数和方法,可以进行数据的统计分析、聚合计算、数据透视表等操作,帮助用户进行数据分析。
数据可视化:Pandas结合Matplotlib库,可以进行数据的可视化展示,生成各种图表和图形,直观地展示数据分析结果。 ----来自某智障AI
DataFrame数据类型
本次使用DataFrame将数据写入表格中。DataFrame数据结构可以从多种数据类型转化而来,包括但不限于:
-
Python字典(Dictionary):可以将字典转换为DataFrame,其中字典的键将成为DataFrame的列标签,字典的值将成为DataFrame的数据。
-
NumPy数组(Numpy Array):可以将NumPy数组转换为DataFrame,数组的行和列将成为DataFrame的行索引和列标签。
-
列表(List):可以将列表转换为DataFrame,列表中的元素将成为DataFrame的一列数据。
-
CSV文件:可以从CSV文件中读取数据并转换为DataFrame。
-
Excel文件:可以从Excel文件中读取数据并转换为DataFrame。
-
SQL数据库:可以从SQL数据库中查询数据并转换为DataFrame
转化数据类型很简单
df = pd.DataFrame([原数据], index=[1])参数index 可有可无,当原数据是标量值(单个值)而不是数组或列表时,必须设置索引,用来标注该数据的行位置。
读取excel数据
使用pd.read_excel读取数据,同时读取数据的列名
def read_excel_data_to_dict(file_path, sheet_name, start_row=0, end_row=0):
datalist = []
# 读取Excel文件,并将值转换为字符串类型
df = pd.read_excel(file_path, sheet_name=sheet_name, dtype=str)
# 获取列名
columns = df.columns
# 获取行数
num_rows = len(df.index
# 遍历每一行
for num, row in df.iloc[start_row:end_row].iterrows():
data = {}
# 遍历列名
for column in columns.values:
data[column] = row[column]
datalist.append(data)
return datalist写入excel数据
写入excel的数据需要注意excel表是否存在,工作表是否存在,一般是续写数据,从excel表格中读取数据,将新的数据加入在原有数据之后,在从第一行开始写入。由于两处数据合并,输入的实际上是一个数据的总和体,为标量值,依然需要索引。
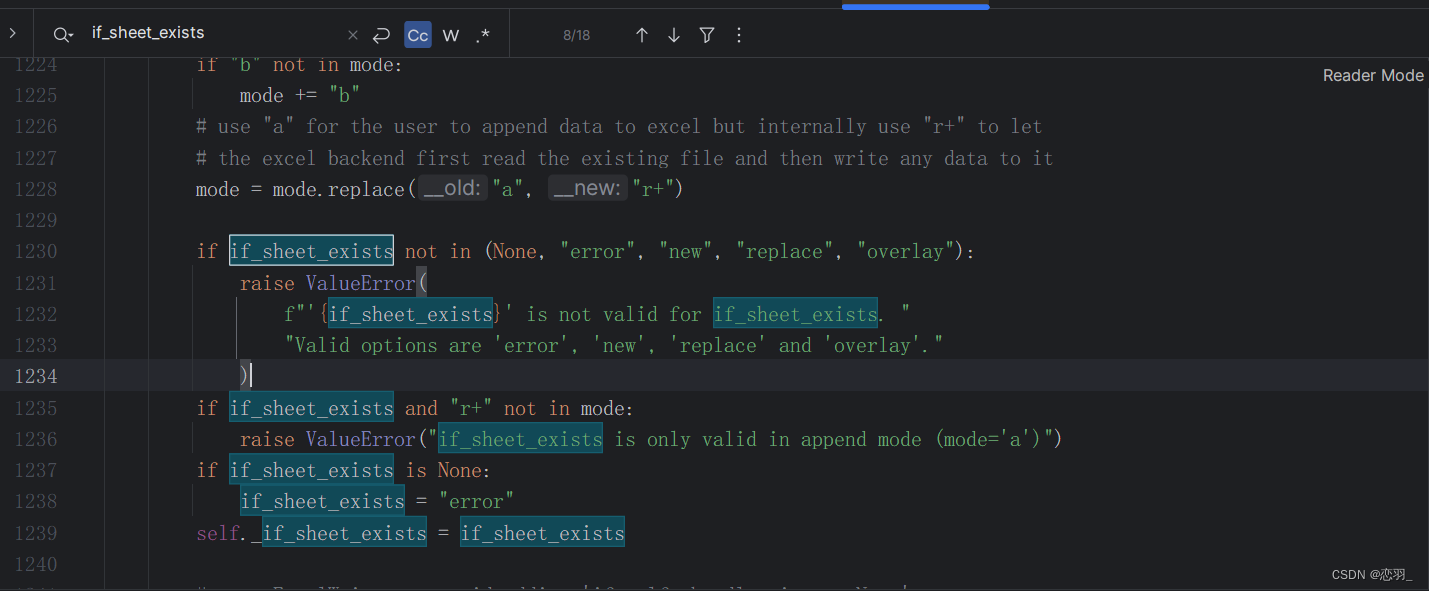
使用pd.ExcelWriter将DataFrame写入到Excel文件的指定工作表中,参数if_sheet_exists可以更改写入模式
def write_excel_data_from_dict(file_path, sheet_name, data_dict):
"""
:param file_path: Excel文件路径
:param sheet_name: sheet名
:param data_dict: 要写入的数据,{'列名1':值1,'列名2':值2}
:return:
"""
data_list.append(data_dict)
# 将字典转换为DataFrame
df = pd.DataFrame(data_dict, index=[0])
# 尝试读取现有的Excel文件
existing_df = pd.read_excel(file_path, sheet_name=sheet_name)
# 将新的数据追加到现有的DataFrame中
# existing_df = existing_df._append(df, ignore_index=True)
combined_df = pd.concat([existing_df, df], ignore_index=True)
# 将DataFrame写入到Excel文件的指定工作表中
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a', if_sheet_exists='overlay') as writer:
combined_df.to_excel(writer, sheet_name=sheet_name, index=False)在pycharm中查看 ExcelWriter的定义得知,参数if_sheet_exists存在几种取值
'error':如果工作表已经存在,则会引发ValueError错误。'new':如果工作表已经存在,则会创建一个新的工作表。'replace':如果工作表已经存在,则会覆盖原有工作表。'overlay':如果工作表已经存在,则会在原有工作表上叠加数据。
根据具体的需求和情况,可以选择适合的if_sheet_exists参数取值来控制工作表的写入行为。
注:写入数据的方法需要在excel关闭时才能运行成功















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









