







【编者按:随着大数据和AI的关注重点转向工程化和能效,DataOps和MLOps逐渐兴起。DataOps侧重于提高数据分析质量、缩短数据交付周期,MLOps侧重于快速交付AI模型。
数据是AI开发生产的重要元素,在数据驱动的AI时代,割裂的DataOps和MLOps是否依然能满足企业数据挖掘和AI应用的需求?
带着这个疑问,IDP和大家一起跟随资深AI从业者Debmalya Biswas的实践分享,一探“如何将DataOps嵌入到MLOps中”。
以下是译文,Enjoy!】
作者 | Debmalya Biswas
翻译 | 王旭博
根据我作为数据分析和AI/ML从业者的经验来看,数据分析和AI/ML这两个领域目前仍然很是脱节。
当我第一次了解到,DataOps(Data operations,数据运维)和MLOps(Machine Learning Operations,机器学习运维)这两个框架都支持Data和ML管道时就产生了疑问:那我们为什么还需要两个独立的框架?尤其在这个以数据为中心的AI时代,数据是AI/ML的关键要素(至少对于进行监督学习的ML是这样,如今,该类模型约占企业级AI的80%)。
以数据为中心的AI重新将AI/ML从算法/建模部分聚焦到底层数据部分。这基于这样一个假设:一个好的算法或模型能够从训练数据集中提取出的“理解量(understanding)”是有限的。所以本文推荐的提高模型准确性的方法是专注于训练数据集:收集更多数据、添加合成(外部)数据、提高数据质量、尝试新的数据转换等方法。
我们仍未解决为什么要分开使用DataOps和MLOps两套框架的问题,或许,我们可以将DataOps嵌入到MLOps中,将前者作为后者的一部分?那就让我们开始吧,希望新框架最终的名字不会是DataMLOps——还请推荐一个更好、更流行的名字,毕竟天知道我们的框架什么时候会突然出名。
01. 整合BI和ML
理想的解决方案应该想下图这样:
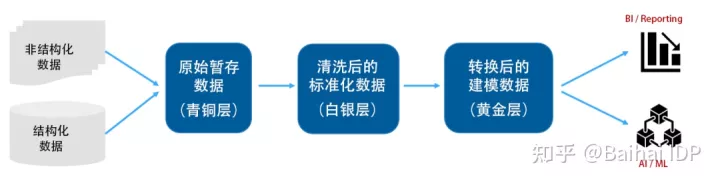
图1. 统一的BI和AI/ML管道(图片来自作者)
结构化和非结构化的数据都会被提取到青铜层;这些数据在青铜层被清洗和标注后,进入白银层;再经过进一步的建模和转换后,这些数据进入到黄金层。
此时,这些数据已经可以被BI-Reporting工具(BI -Reporting工具用于从公司的数据源、本地或云中读取数据,来识别销售、收入、库存等数据,并应用日期、采购订单或客户信息等维度来创建分析报表)和ML管道(ML pipeline,用于自动将数据输入ML模型)使用。
然而,实际上,我们看到的这些被整理过的数据移动到了另一个位置,例如云存储空间或者是另一个数据湖。在那里,这些数据被进一步用于ML的训练和部署。
因此,相比于图1,企业环境中的架构更像图2(下图)。
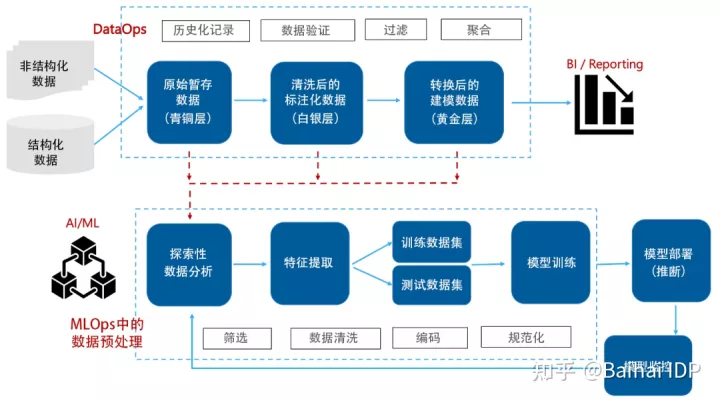
图 2. DataOps 和 MLOps 管道中的数据处理
MLOps的数据(预)处理部分侧重于将数据从数据源移动到ML模型,而不必包括模型如何处理数据。该部分通常包括一系列用于支持学习算法的变换(transformation),例如,数据科学家为将数据传输给ML模型,可能选择构建线性回归pipeline或探索性因子分析pipeline。
ML训练所需要执行的功能比传统ETL工具所提供的功能更加复杂。这种现象经常出现在复杂的数据处理、聚合和回归中。本文推荐的方法是使用有向无环图(Directed Acyclic Graph,简称DAG)流来完善数据处理策略。
相比于BI中更线性的数据流,DAG流可用于数据路由(所谓路由,就是指将数据送一个地方传送到另一个地方的行为)、统计转换和系统逻辑的可扩展有向图。Apache Airflow等很多工具可用于与DAG流相关的创作、管理和维护,我们可以通过编程来将这些工具与ETL管道集成在一起。
不用说,这会导致DataOps和MLOps的管道过多及其碎片化。公平地说,如今,DataOps更多地与BI/结构化分析相关,而由MLOps提供嵌入了数据(预)处理的完整ML管道。
工具/平台提供商已经开始努力解决这个问题,我们也已经能看到一些初期解决方案。近期,Snowflake带来了Snowpark Python API,通过调用该API,数据科学家可以在Snowflake中使用Python(而非使用SQL)训练和部署ML模型。
Google Cloud Platform(GCP)提供了一种可在GCP数据仓库环境中只使用SQL来训练ML模型的工具,名为BigQuery ML。同样,AWS Redshift Data API使任何用Python编写的应用程序都可以轻松的与Redshift交互。这让SageMaker notebook可以连接到RedShift集群,并使用Python调用Data API。就地分析(in-place analysis)提供了一种直接将数据从AWS的DWH(data warehouse,数据仓库)提取到notebook的方法。
02. 将机器学习推理数据作为新数据源
与MLOps管道相连的ML模型会产生新数据,而我们在本节中将会研究MLOps缺少的“数据(data)”方面——将ML模型产生的新数据作为源数据。
让我们考虑一个Compositional AI(组合AI)场景(图3)。
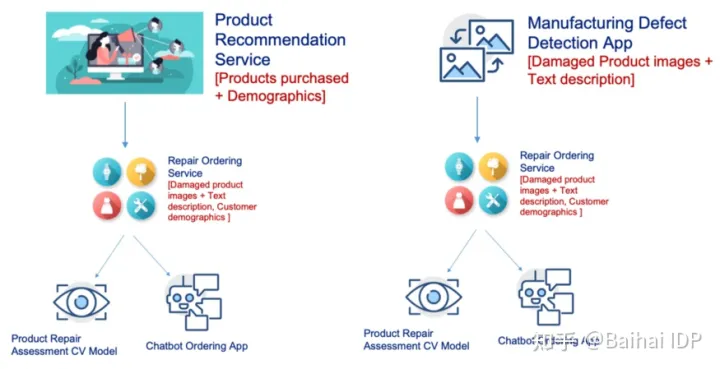
图 3. Compositional AI 组合 AI 场景(图片来自作者)
消费电子供应商为用户提供(在线)维修服务,该服务包括一个计算机视觉(Computer Vision,简称CV)模型,该模型能够根据受损产品的快照(snapshot,用于保留受损产品在某一时刻的状态,可以理解为照片)评估所需的维修服务。如果用户对报价感到满意,则将处理流程转移给聊天机器人,该聊天机器人通过与用户交谈,来获取订购维修服务所需的其他详细信息,例如损坏细节、用户姓名、联系方式等。
将来,当供应商想要开发产品推荐服务时,可以参考维修服务。维修服务收集的数据——用户拥有的产品状态(由CV评估模型收集)、用户们的个人信息(由聊天机器人收集)——额外为推荐服务提供了有标记的训练数据。
进一步,供应商希望开发支持计算机视觉的制造缺陷检测服务(用于供应商在出售产品前检验产品质量)。维修服务已经标记了损坏产品的图像,因此,这些数据也可以用于训练新CV模型。另外,这些被标记的图像也可以作为反馈循(feedback loop)环提供给维修服务,用来改进其基础CV模型。
总而言之,已被部署ML模型所做的推断可以作为反馈循环,来扩大已部署模型的现有训练数据集,或者作为新模型的训练数据集。于是,就产生了已被部署的ML模型产生新数据,而这些新数据又可以供DataOps管道使用的情形。
图4(下图)显示了扩展的MLOps管道,其中(已被部署的)ML模型的推理被集成为一个(新)数据源。合成数据,即经合成(基于生成神经网络)产生的、与原始训练数据集非常相似的数据,也可以被视为与原数据相似的附加数据源。
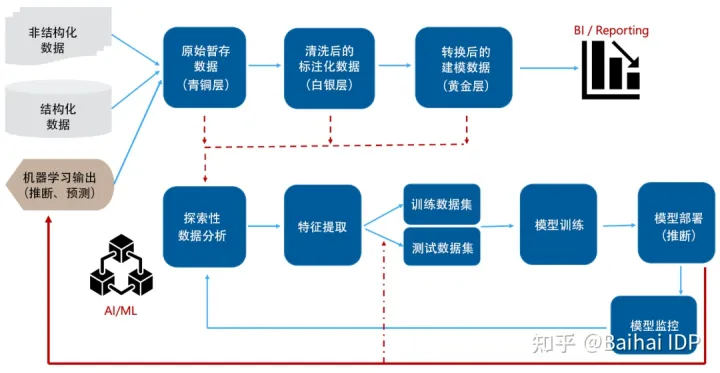
图 4. (已部署的) ML模型推理结果作为附加数据源(图片由作者提供)
END
本期互动:你如何看待MLOps和DataOps的关系呢?欢迎留言。
参考资料
- 以数据为中心的AI https://datacentricai.org/
- DataOps的重要性:为什么重要以及如何开始?https://www.wipro.com/analytics/the-importance-of-dataops-why-it-matters-and-how-to-get-started/
- D.Scully等 机器学习中隐藏的技术债务 https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
- 现场演示:使用Snowpark for Python构建数据科学的未来 https://www.snowflake.com/webinar/building-the-future-of-data-science-with-snowpark-for-python/
- 什么是BigQuery ML?https://cloud.google.com/bigquery-ml/docs/introduction
- 使用Amazon Redshift Data API https://docs.aws.amazon.com/redshift/latest/mgmt/data-api.html
- DataKitchen公司 为什有这么多*Ops术语?https://datakitchen.io/why-are-there-so-many-ops-terms/
- D. Biswas 组合式AI:企业AI的未来 https://towardsdatascience.com/


















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









