







代码创建进程
Windows操作系统下,创建进程一定要在main里面创建,因为Windows下创建进程是类似模块导入的方式(windows下诞生双胞胎的方式是以模块的形式导入一份同样的代码,往新的内存空间里面去放),会从上而下运行代码,如果不在main里面创建进程,每一次导入模块的时候,都会执行一次创建进程,结果就是没完没了的死循环了,所以放在main里面,只有第一次手动运行时,会执行创建进程的命令,第二次以模块导入的方式创建进程,不会运行main里面的代码
创建进程的本质:在内存中申请一块内存空间用于运行相应的程序代码
第一种方法
1、在mian下开启进程,
2、实例化一个对象,
3、开启进程
from multiprocessing import Process
import time
def task(name):
print('%s is running' % name)
time.sleep(3)
print('%s is over' % name)
if __name__ == '__main__':
p = Process(target=task, args=('jason',)) # 创建一个进程对象
p.start() # 告诉操作系统创建一个新的进程
print('主进程')
第二种方法,类的继承,
1、定义进程任务类(继承Process),重写run方法
2、在main下开启进程
3、实例化一个对象
4、开启进程
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, username):
self.username = username
super().__init__()
def run(self):
print('你好啊 小姐姐',self.username)
time.sleep(3)
print('get out!!!',self.username)
if __name__ == '__main__':
p = MyProcess('tony')
p.start()
print('主进程')
**总结:**创建进程就是在内存中申请一块独立的内存空间,将完整的代码丢进去,然后去执行进程任务。一个进程对应在内存中就是一块独立的内存空间,多个进程对应在内存中就是多块独立的内存空间,进程有各自的生命,运行完就自动结束。
join方法
join方法(干等方法),主进程等待各个子进程运行完后才开始运行
from multiprocessing import Process
import time
def task(name, n):
print(f'{name} is running')
time.sleep(n)
print(f'{name} is over')
if __name__ == '__main__':
p1 = Process(target=task, args=('jason', 1))
p2 = Process(target=task, args=('tony', 2))
p3 = Process(target=task, args=('kevin', 3))
start_time = time.time()
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
end_time = time.time() - start_time
print('主进程', f'总耗时:{end_time}') # 主进程 总耗时:3.015652894973755
# 如果是一个start一个join交替执行 那么总耗时就是各个任务耗时总和
如果是开一个进程等一个进程结束,在开第二个进程,则变成串行了,等待时间要累加起来。
结果:
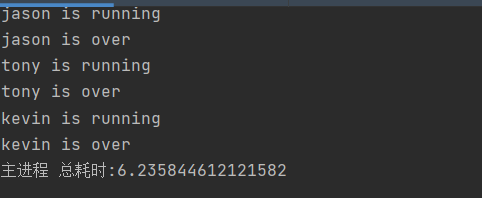
总结:进程先全开,则等待时间是所有进程中最长的那个进程的时间,如果进程开一个等一个结束,则等待时间是所有进程等待时间之和
进程间数据默认隔离
多个进程间互相独立,互不干扰,同时进行,是多个独立的个体。
from multiprocessing import Process
money = 999
def task():
global money # 局部修改全局不可变类型
money = 666
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join() # 确保子进程代码运行结束再打印money
print(money)
进程对象的属性和方法
- 查看进程好
进程号如何查看
windows: tasklist结果集中PID
mac: ps -ef
我的是Windows,所以1.1.current_process函数
from multiprocessing import Process, current_process
current_process().pid
1.2.os模块
os.getpid() # 获取当前进程的进程号
os.getppid() # 获取当前进程的父进程号
获取进程号的用处之一就是可以通过代码的方式管理进程
windows taskkill关键字
mac/linux kill关键字
- 杀死子进程
terminate()
- 判断子进程是否存活
is_alive()
僵尸进程与孤儿进程
僵尸进程
当进程exit()退出之后,他的父进程没有通过wait()系统调用回收他的进程描述符的信息,该进程会继续停留在系统的进程表中,占用内核资源,这样的进程就是僵尸进程。
孤儿进程
孤儿进程则是指当一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
守护进程
守护即死活全部参考守护的对象
对象死立刻死
def task(name):
print(f'大内总管:{name}正常活着')
time.sleep(3)
print(f'大内总管:{name}正常死了')
if __name__ == '__main__':
p = Process(target=task, args=('赵公公',))
# 必须写在start前面
p.daemon = True # 将子进程设置为守护进程:主进程结束 子进程立刻结束
p.start()
print('皇帝Jason寿终正寝')
互斥锁
一:互斥锁概念:
1.进程之间的数据不能共享,但是共享同一套文件系统,所以访问同一个文件,或者同一个打印终端,是没有问题的,而共享
带来的是竞争竞争带来是错乱
2.如何控制,就是加锁处理,而互斥锁就是互相排斥,假设把多个进程比喻成多个人,互斥锁的工作原理是多个人都要去争抢
同一个资源:比如抢票,谁先抢到票占为己有然后上个锁,然后在他占用的时间段内别人是要等他用完

import time
import json
from multiprocessing import Process, Lock
def func(n, loc):
dic = json.load(open('db.py'))
print("用户[%s]你好!目前剩余票数:" % n, dic['count'])
# with loc:
# dic = json.load(open('db.py'))
# time.sleep(0.1)
# if dic['count'] > 0:
# dic['count'] -= 1
# time.sleep(0.1)
# json.dump(dic, open('db.py', 'w'))
# print("恭喜您[%s]抢到票了." % n)
# else:
# print("非常抱歉[%s]抢票失败." % n)
loc.acquire()
dic = json.load(open('db.py'))
time.sleep(0.1)
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(0.1)
json.dump(dic, open('db.py', 'w'))
print("恭喜您[%s]抢到票了." % n)
else:
print("非常抱歉[%s]抢票失败." % n)
loc.release()
if __name__ == '__main__':
lock = Lock()
for i in range(10):
p = Process(target=func, args=(i, lock))
p.start()
二. 互斥锁与join
使用join可以将并发变成串行,互斥锁的原理也是将并发变成串行,那我们直接使用join就可以了啊,为何还要互斥锁
from multiprocessing import Process,Lock
import json
import time
def query_ticket(name):
time.sleep(1)
with open('db.txt','r',encoding="utf-8") as f:
d = json.load(f)
print('[%s] 查看到剩余票数 [%s]'% (name, d['count']))
def buy_ticket(name):
time.sleep(1)
with open('db.txt','r', encoding="utf-8") as f:
d = json.load(f)
if d.get('count') > 0 :
d['count'] -= 1
time.sleep(1)
json.dump(d, open('db.txt','w',encoding='utf-8'))
print('<%s> 购票成功' % name)
else:
print('没有多余的票,<%s> 购票失败' % name)
def task(name):
query_ticket(name)
buy_ticket(name)
if __name__ == '__main__':
print('开始抢票了……')
for i in range(5):
p = Process(target=task, args=('进程%s' % i,))
p.start()
p.join()
此时join与互斥锁的区别就显而易见了,join是将一个任务整体串行,而互斥锁的好处则是可以将一个任务中的某一段代码串行,比如只让task函数中的buy_ticket任务串行
加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行地修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。
虽然可以用文件共享数据实现进程间通信,但问题是:
1、效率低(共享数据基于文件,而文件是硬盘上的数据)
2、需要自己加锁处理
因此我们最好找寻一种解决方案能够兼顾:
1、效率高(多个进程共享一块内存的数据)
2、帮我们处理好锁问题。
这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。
队列和管道都是将数据存放于内存中,而队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来,因而队列才是进程间通信的最佳选择。














 6175
6175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









