







 本文详细介绍了Python中的Requests库,包括库的入门、HTTP协议、主要方法解析,以及如何遵守Robots协议。通过五个实战例子展示了如何利用Requests库进行网络爬虫,涉及京东、亚马逊商品页面爬取、搜索引擎关键词提交、网络图片爬取和IP地址归属地查询等。
本文详细介绍了Python中的Requests库,包括库的入门、HTTP协议、主要方法解析,以及如何遵守Robots协议。通过五个实战例子展示了如何利用Requests库进行网络爬虫,涉及京东、亚马逊商品页面爬取、搜索引擎关键词提交、网络图片爬取和IP地址归属地查询等。
#requests库的学习与应用实例
导学
- Request:自动爬取HTML页面自动网络请求提交
- robots协议:网络爬虫排除标准
- Projects:实战项目
单元1:Requests库入门
Requests库安装:pip install requests
get() head()最常用

get()方法
import requests
r = requests.get("url")
#get->request:构造一个向服务器请求的资源的Requests对象
#response->r:返回一个包含服务器资源的的Response对象(包含爬虫返回的内容)
#requests.get(url,params=None,**kwargs)
#url:拟获取页面的url链接
#params:url中的额外参数,字典或字节流格数,可选
#**kwargs:12个控制访问的参数
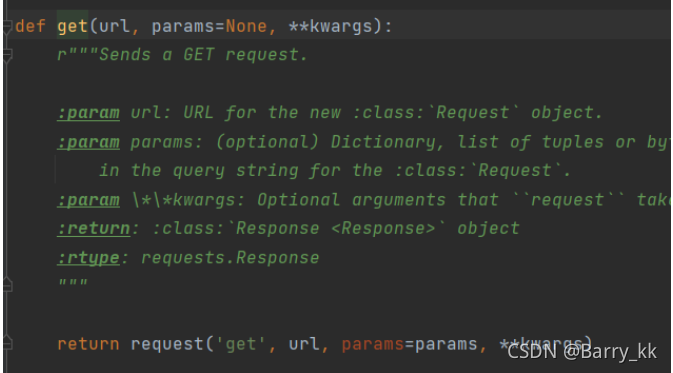
由此可见requests库只有一个request方法,其他方法都是调用request方法
#Requests库的两个重要对象 Response-Request
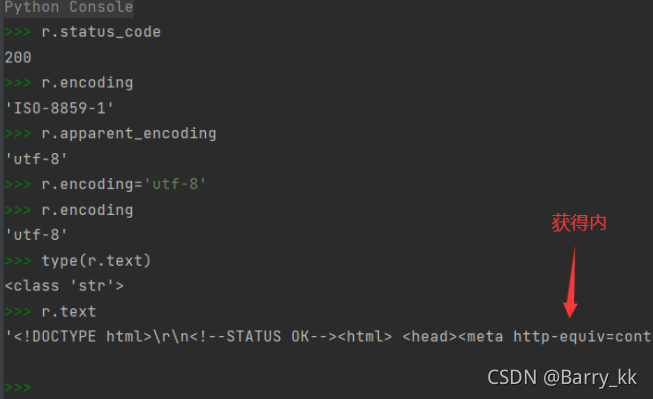
#Response的属性(包含爬虫返回的内容)
#404或其他:错误或异常
#200:可查看相应属性值

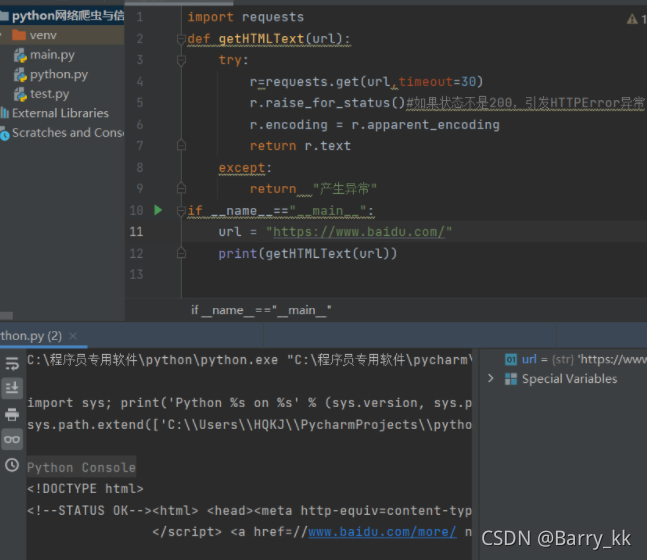
爬取网页的通用代码框架


#爬取网页的通用代码框架
#网络链接有风险,异常处理很重要
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__=="__main__":
url = "https://www.baidu.ccom/"
print(getHTMLText(url))
返回的正确结果
-
`` if _name_ == " _main_":
printf(“11”)语句的作用: ``
一个python的文件有两种使用的方法,第一是直接作为脚本执行,第二是import到其他的python脚本中被调用(模块重用)执行。因此if name == ‘main’: 的作用就是控制这两种情况执行代码的过程,在if name == ‘main’: 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而import到其他脚本中是不会被执行的。
HTTP协议及Requests库方法

HTTP协议:超文本传输协议。
http是一个基于“请求与响应”模式的,无状态的应用层协议。
http一般采用url作为定位网络资源的标识。
url格式 http://host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号,缺省端口为80
path:请求资源的路径
http://www.bit.edu.cn
HTTP URL的理解
url是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









