






爬取的是哔哩哔哩上所有纪录片的信息(名称,评分,描述,链接)、高分纪录片和低分纪录片的信息、以及高分纪录片的outline和点评文章。爬取深度为4,具体功能看下面描述。
一、系统功能描述
待爬种子url=“https://www.bilibili.com/”。
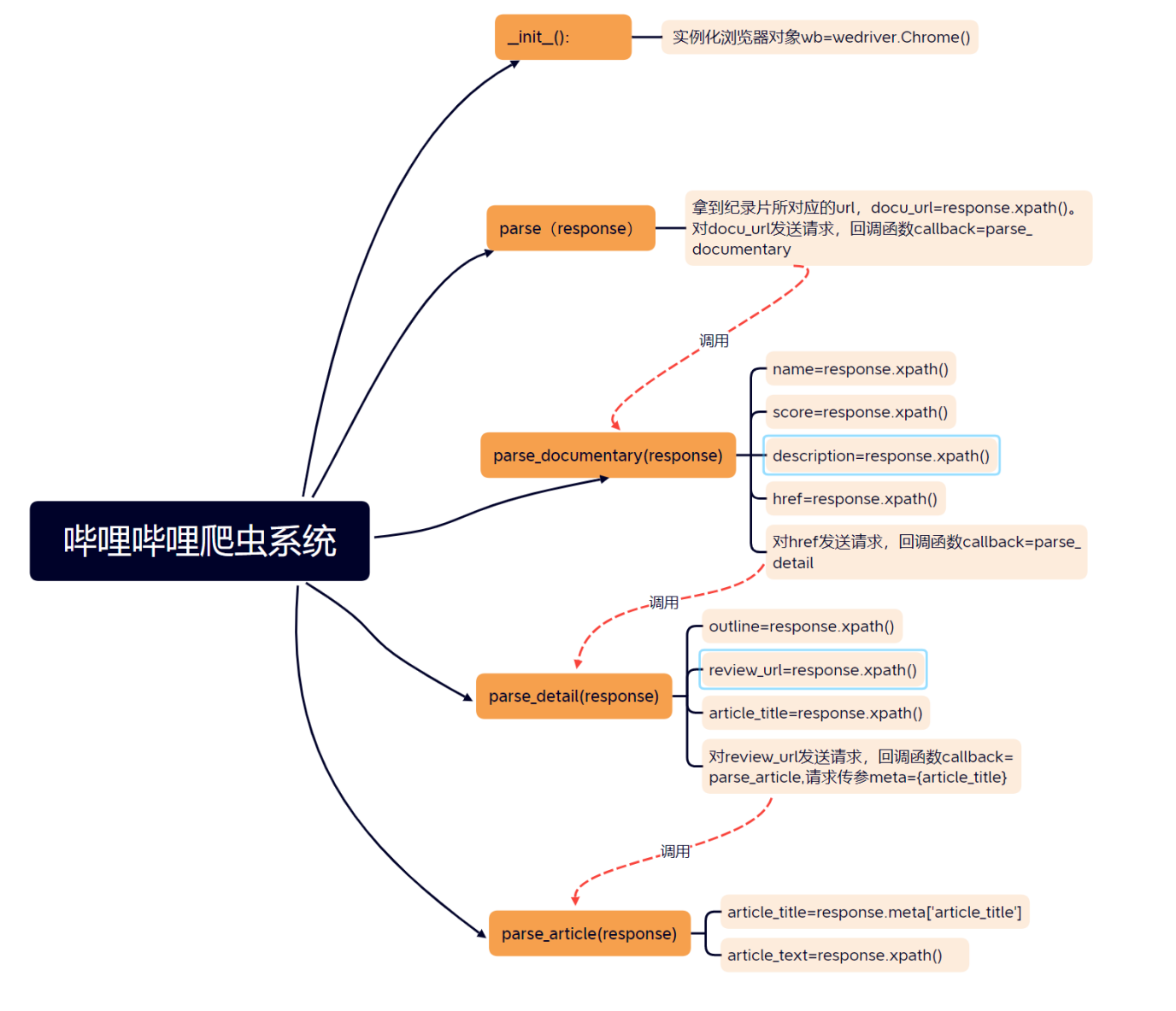
功能描述:通过对给定的url(哔哩哔哩首页网址)发送请求,解析出首页导航栏中“纪录片”所对应的url_2

对url_2发送请求,在url_2对应的网页中,爬取“纪录片热播榜(该网页上的前七个)”“厂牌推荐”“本周精选”“更多推荐”四大板块的纪录片的信息(名字,评分,描述,链接),保存该信息到本地文件中。
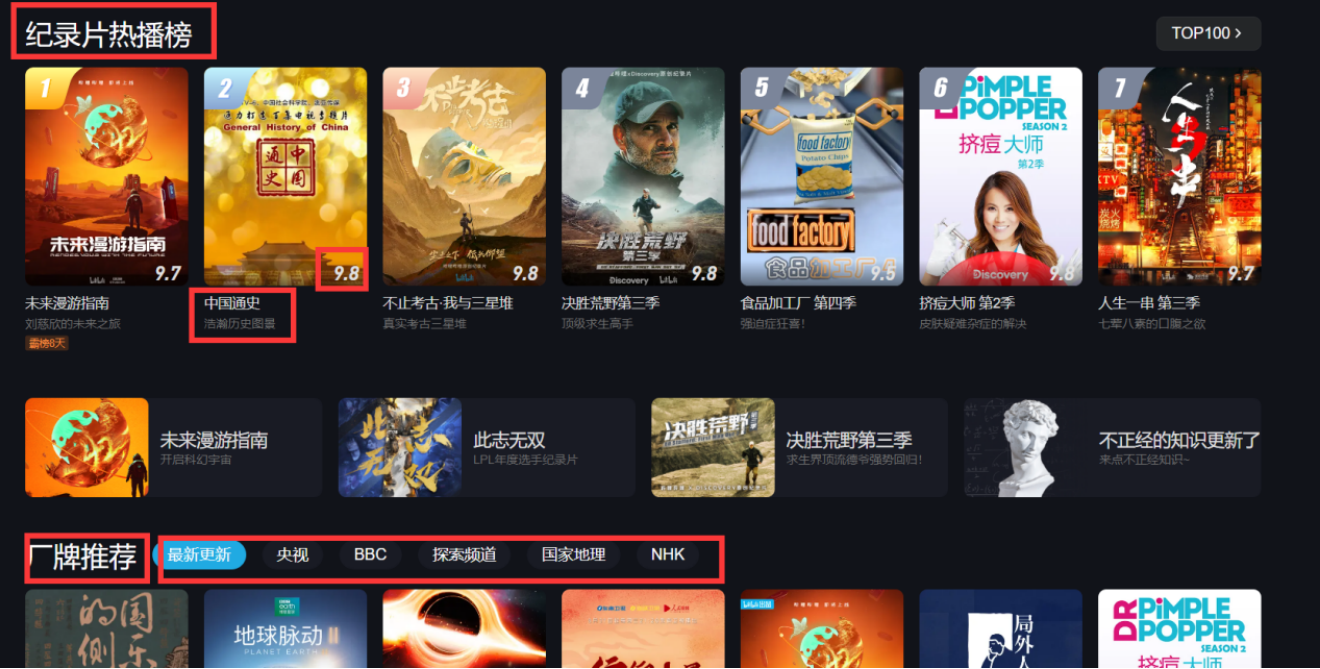
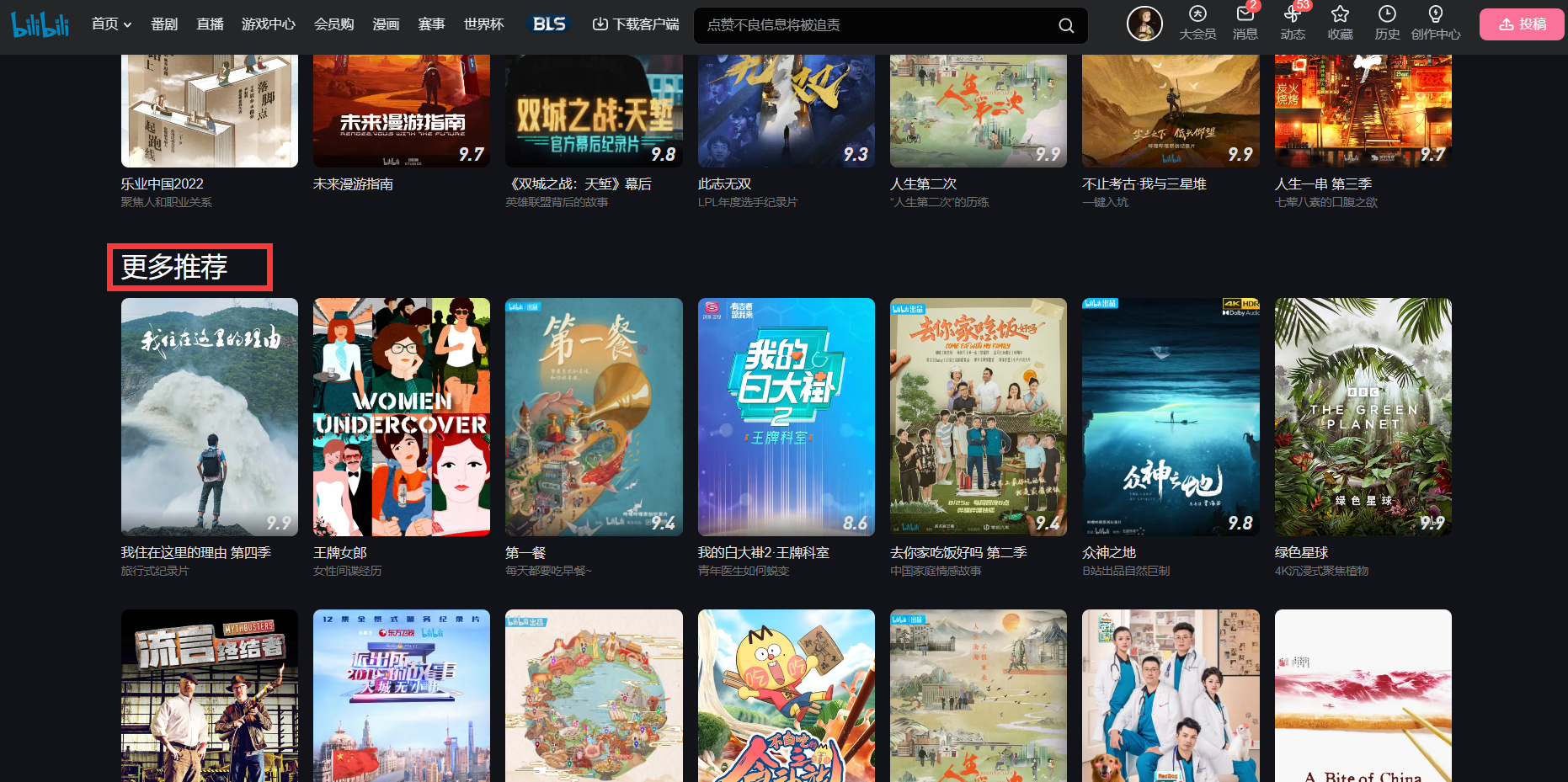
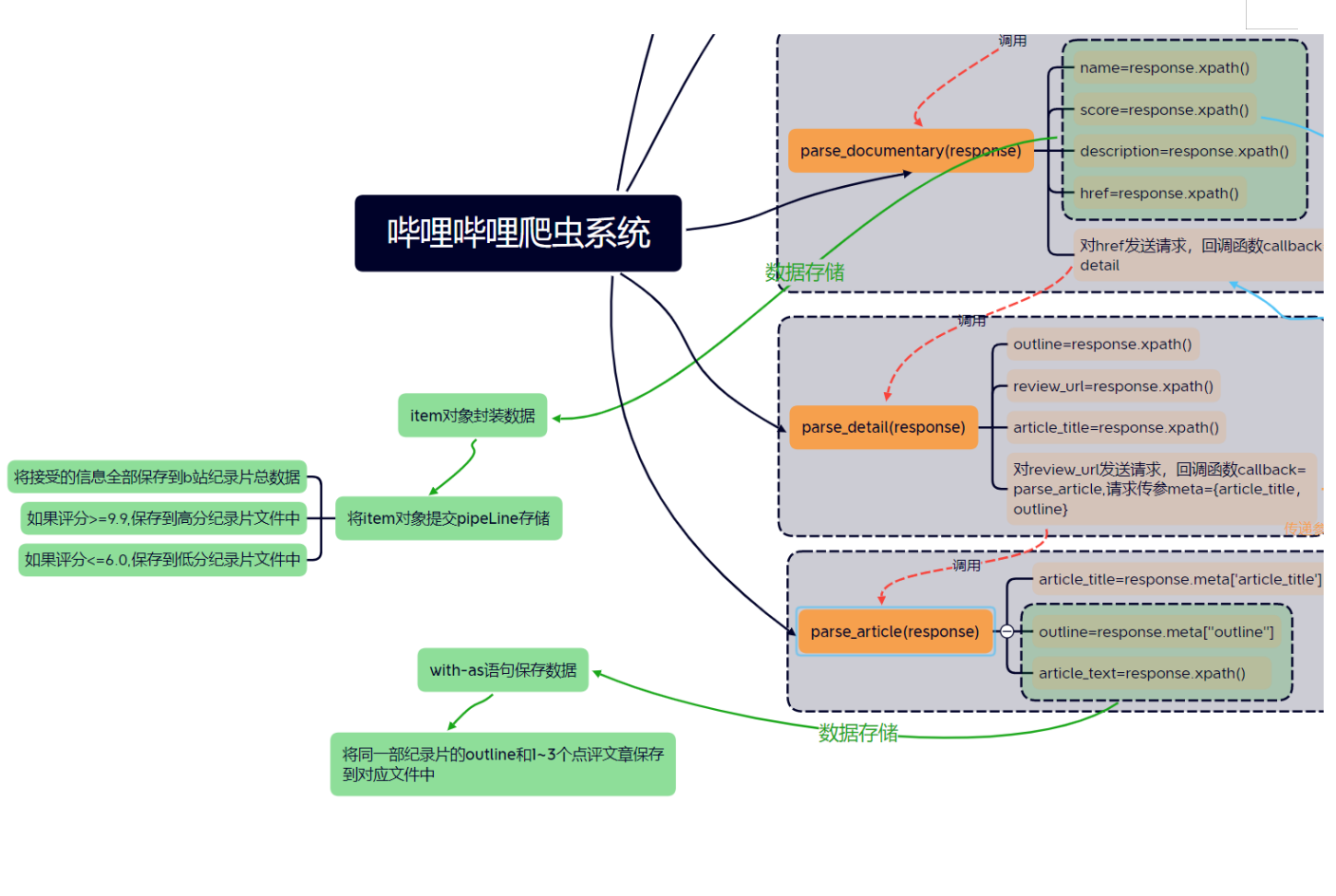
然后挑选出高分纪录片(评分>=9.9)和低分纪录片(平分<=6.0),将纪录片信息保存到本地。
获取所有高分纪录片的链接url_3s,对url_3s中的url_3一一发送请求,获取url_3网页的outline和点评所对应的链接url_4(点评分为:长评和短评,如果是长评文章,获取文章链接;如果是短评,不进行爬取)
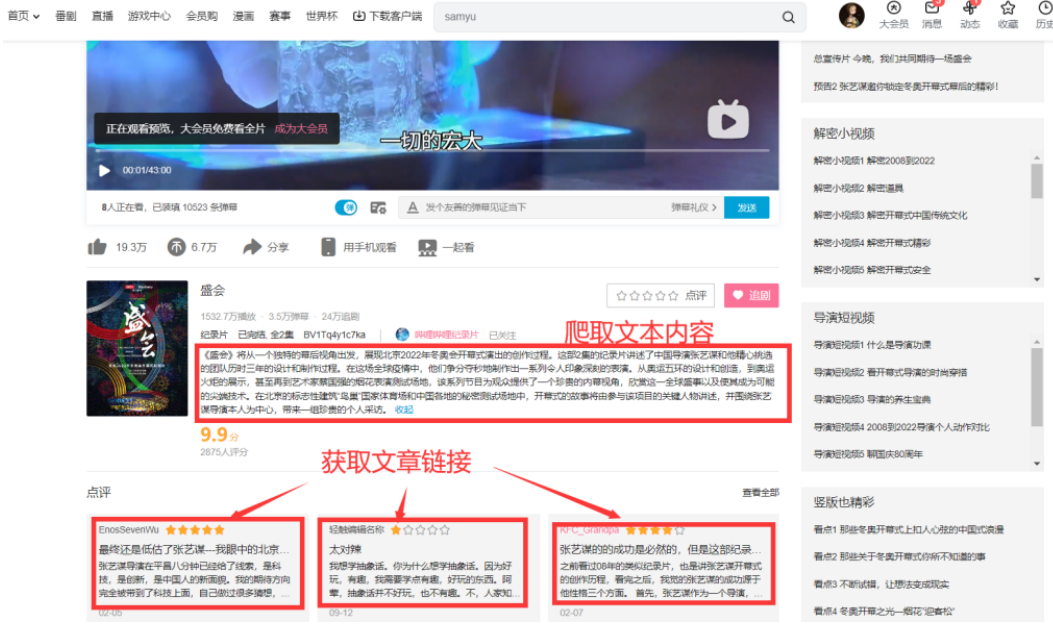
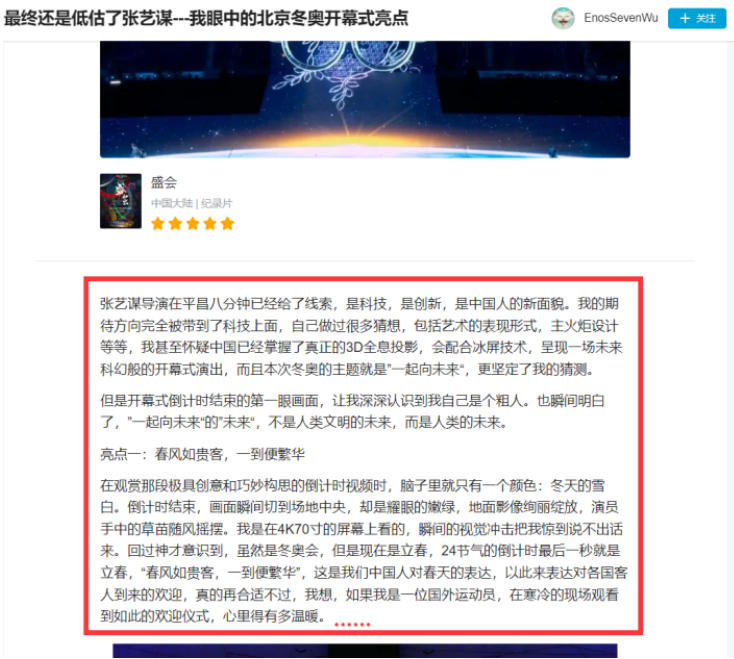
对url_4对应的点评文章进行爬取,将同一部纪录片的1~3篇长评文章和上一步操作中爬取的outline保存在一个文件中。
二、相关技术
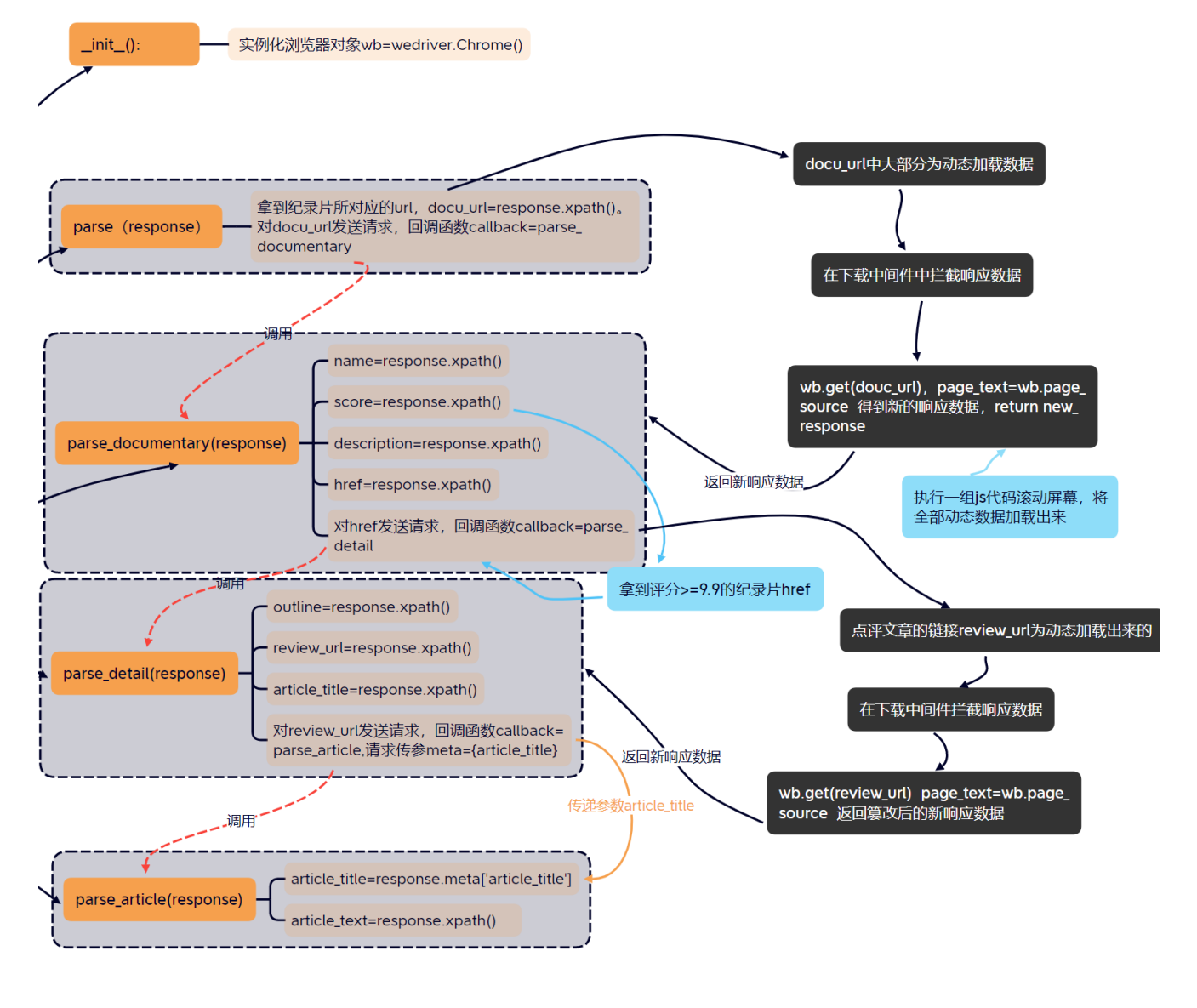
整个项目整体使用scrapy框架,文件存储采用了基于管道的持久化存储操作和with-as语句写入内容两种方式;使用了基于selenium的自动化操作技术:用谷歌驱动程序实例化一个谷歌浏览器对象,将浏览器对象无可视化界面化,通过spider组件对相关url发送请求获取其页面源码,有些网页含有大量动态加载数据,在下载中间件DownloaderMiddleware中拦截响应数据进行篡改:使用selenium拿到动态加载数据,通过执行js代码来对网页进行多次滚动加载出全部动态数据,返回给Spider新的响应数据。在Spider组件中进行数据解析,将解析出的数据封装到item类型的对象中,然后将item类型的对象提交给管道进行持久化存储。在配置文件中进行UA伪装,关闭君子协议robots rules,开启下载中间件和管道配置。
三、运行结果
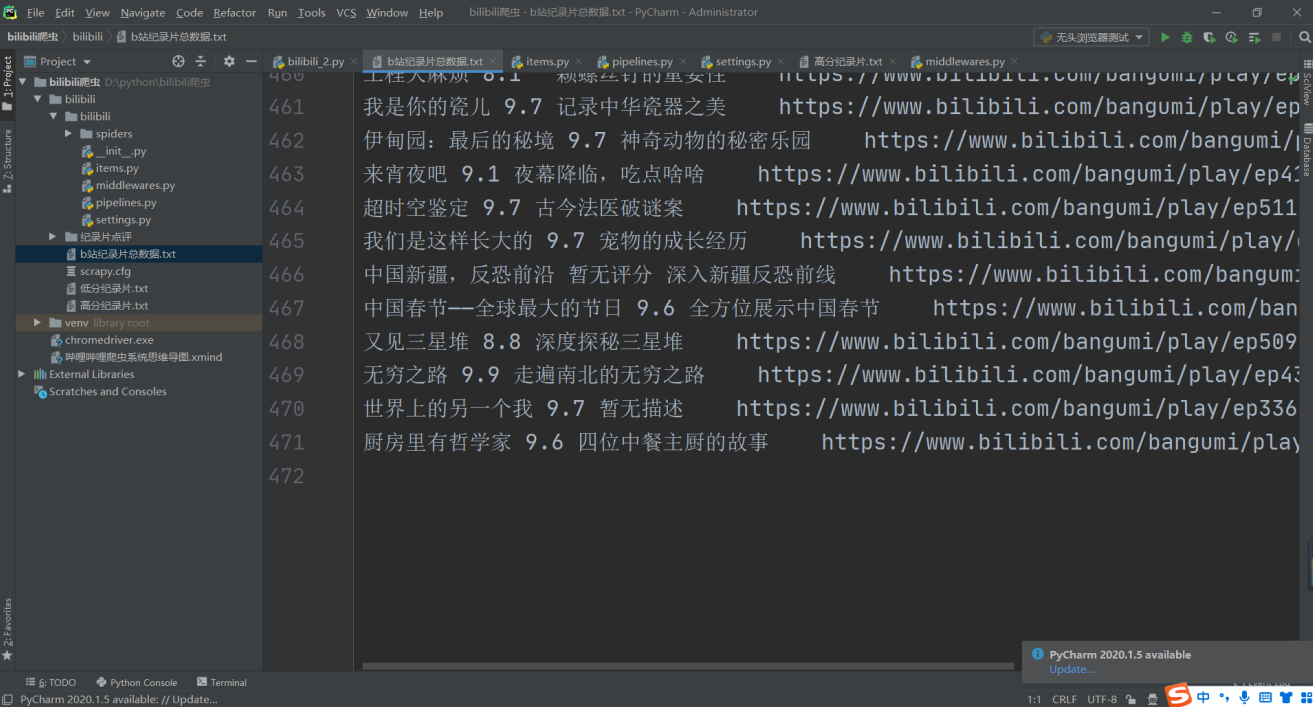
哔哩哔哩所有纪录片总数据(名字、评分、描述、链接):

高分纪录片(分数>=9.9的纪录片信息):
注:因为爬取的有热播榜、推荐榜、本周精选榜、更多推荐,前三个榜可能会推荐同一部纪录片,所以拿到的高分纪录片会有些重复数据,不过数量不多,因为大部分的纪录片信息是从“更多推荐”中爬取的,所以就不进行数据去重了。

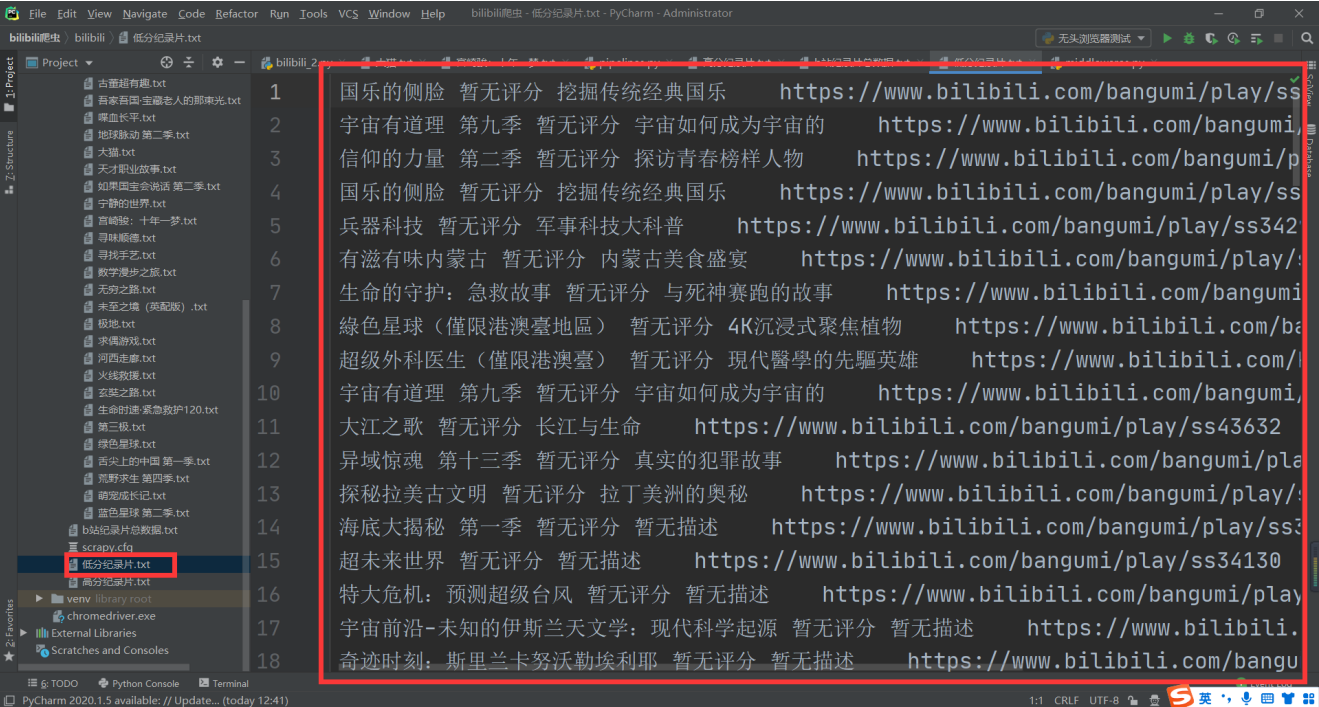
低分纪录片(有些纪录片没有评分,默认统计为低分纪录片):
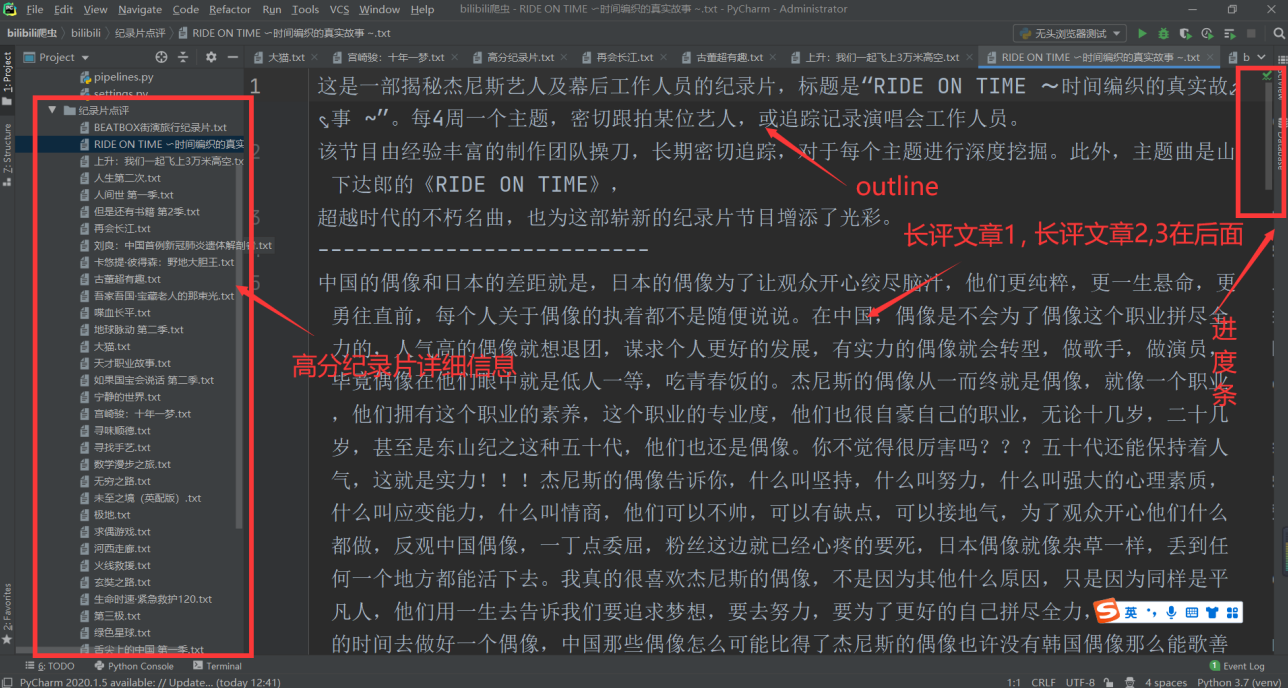
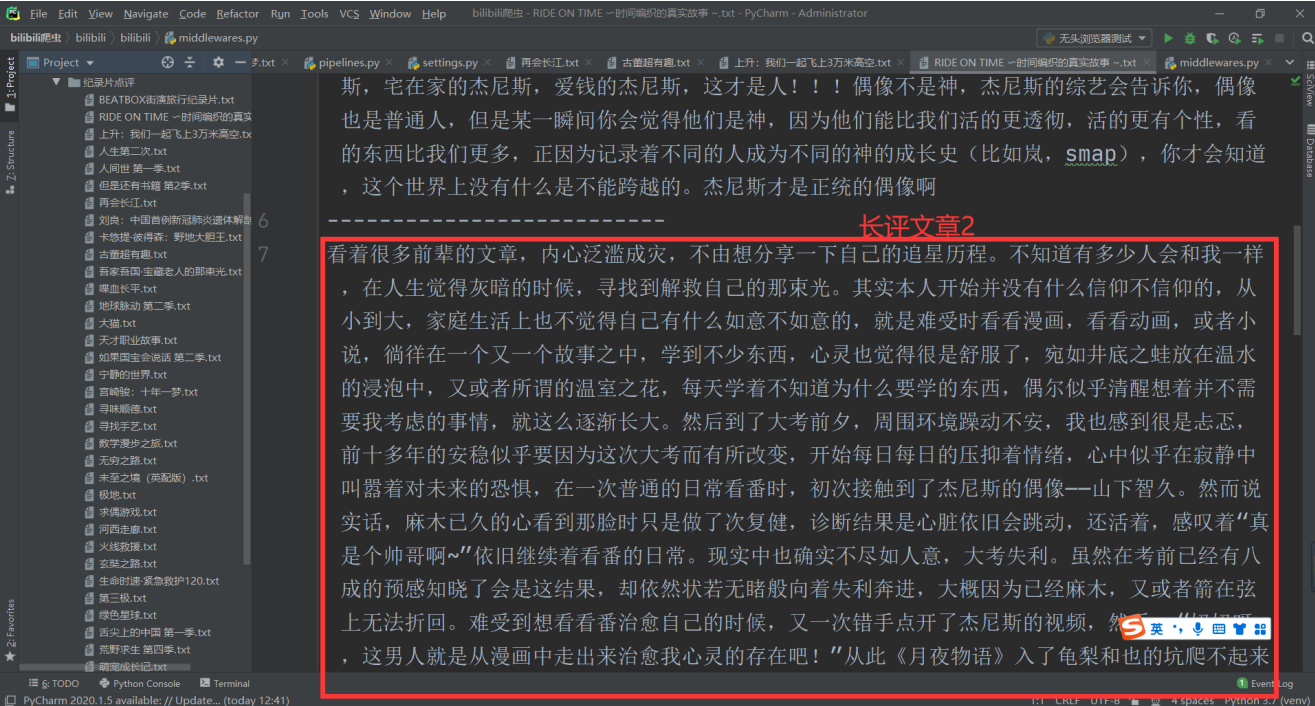
高分纪录片的详细信息(outline和长评文章):















 5763
5763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









