






分布式文件系统架构
- FS (File System)
- 文件系统是基于硬盘上的一个文件管理的工具
- 我们用户操作文件系统可以和硬盘解耦
- DFS (Distributed File System)
- 分布式文件系统
- 将数据存放到多台电脑上存储
- 分布式文件系统有很多
- HDFS(Hadoop Distributed File System)是Map Reduce计算的基础
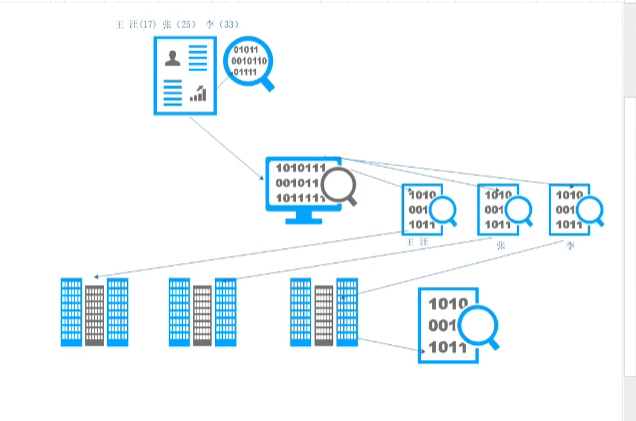
文件切分思想
- 文件存放在一个磁盘上效率低
- 读取效率低
- 如果文件特别大会超出单台机器的存储范围
- 字节数组
- 文件在磁盘真实存储文件的抽象概念
- 数组可以进行拆分和组装,源文件不会受到影响
- 切分数据
- 对字节数组进行切分
- 拼接数据
- 按照数组的偏移量将数据连接到一起,将字节数组连接到一起
- 偏移量
- 当前数据在数组中的相对位置,可以理解为下标
- 数组都有对应的索引(下标),可以快速地定位数据
- 数据存储的原理
- 不管文件的大小,所有的文件都是由字节数构成
- 如果要切分文件,就是将i个字节数组分成多份
- 只要将切分后的数据拼接到一起,数据就可以继续使用
- 拼接的时候需要参照的是每个数据的偏移量
Block拆分标准
-
拆分的数据块需要等大
- 数据计算的时候简化问题的复杂度
- 进行分布式算法设计的时候,数据不统一,算法很难设计
- 数据读取的时间相对一致
- 通过偏移量可以知道数据块的位置
- 相同文件,分成的数据块大小应该相等
- 数据计算的时候简化问题的复杂度
-
数据块Block
- 数据被切分后的一个整体成为数据块
- 在Hadoop1.0中默认大小为64M,在Hadoop2.0及其以后默认大小为128 M
- 在同一个文件中,每个数据块大小要一致,除了最后一个节点之外
- 不同文件中,块的大小可以不一致
- 文件大小不同可以设置不同的块的数量
- 真实情况下,会根据文件大小和集群节点的数量综合考虑块的大小
- 数据块的个数=ceil(文件大小/每个块的大小)
-
注意事项
- HDFS中一旦文件被存储,数据便不被允许被修改
- 修改会影响偏移量
- 修改会导致数据倾斜
- 修改数据会导致蝴蝶效应
- 可以被追加数据,但是不推荐
- 追加设置需要手动打开
- 一般HDFS存储的都是历史数据。所以将来Hadoop的Mapreduce都会被用来进行离线数据处理
- 一旦文件被上传之后,块的大小就不允许被修改,之后的可以适当缩小
- 块大小范围:128M-512M
- 如果数据文件的切割点128M正好是一个单词的中间部分,切分数据如何保证数据的完整性?
- 根据每个字符的偏移量,可以来为不同块的字符找到其原来的文件中的位置
- 参考文件拆分思想中的数据存储原理
- HDFS中一旦文件被存储,数据便不被允许被修改
Block数据安全
- 肯定是要对数据进行备份
- 备份的数据不能存放在一个节点上
- 存储的副本数据要尽可能的近,这样获取数据的速度会很快从而减少读取的代价
- 备份的数量小于等于节点数量
- 备份的数据节点越多的话,可能导致资源浪费严重
- 备份少的话,发生集体崩溃的可能性会增大
- 备份数量是通过数据的使用频率和数据的重要性来决定的
- 默认每个数据块会有3个副本,相同副本是不会存放在同一个节点上
- 副本的数量可以变更
- 如果数据近期被使用的可能性很大,那么可以多设置一些数据备份
- 后期数据很少被分析,可以减少副本数量
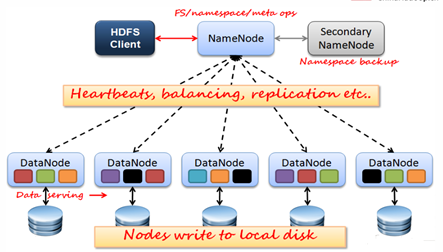
Block管理效率
- 需要专门给节点进行分工
- DataNode:存储数据,存储的数据块(data block)
- NameNode:记录数据。用来管理/分配所有访问对应DataNode的进程,监控对应DataNode的状态以及对应NameNode都做了什么,NameNode对DataNode进行记录
- SecondaryNameNode:数据日志
HDFS的特点
优点
-
高容错性
-
保存多个副本,并且提供容错机制
-
副本丢失或宕机后自动恢复。默认保存三个副本
-
-
可以运行在廉价的机器上
- 通过副本提高可靠性
- 提供容错机制和恢复机制
-
适合批处理
- 移动计算而非数据
- 数据位置暴露给计算框架,这样所有节点都可以进行数据访问
-
适合大数据的处理
- TB级数据处理,甚至是PB级数据的处理
- 百万规模以上的文件数量
- 10K+节点规模
-
流式数据访问
- 一次写入,多次读取,高吞吐量,所以可以同时处理大量数据
-
批处理和流处理
-
批处理:安按照一个定量不停的处理
-
流处理:源源不断,上流不停处理不停
-
缺点(不适合小量数据处理)
-
不擅长低延迟数据访问
- 比如毫秒级
-
不擅长小文件分区
- 占用NameNode大量内存,NameNode是管理datanode并记录block存储到了哪个datanode。所有每存储一个文件会生成一个1k或者几k的数据文件,如果小文件多的话,小文件累积最终也会达到一个比较大的规模
- 磁盘寻道时间超过读取时间
- 不擅长并发写入,文件随机修改
- 一个文件只能有一个写入者
- 仅支持append向尾部添加(有组件可以实现删除等功能)















 6153
6153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









