







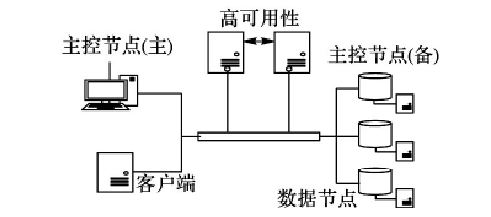
目前比较主流的分布式文件系统结构是主 /从( master/slave) 体系结构,如下图所示,通常包括主控节点 ( 或称元数据服务器,通常会配置一个活动节点和一个备用节点以实现高可用性) 、多个数据节点( 或称存储节点) 和各种大数据应用或者终端用户组成的客户端。分布式存储的目的是将大数据划分为小数据,均匀分布至多个数据节点上,将数据的规模降到单个节点可以处理的程度。
1 主控节点
主控节点主要负责管理文件系统名字空间( namespace)和管理客户端的访问。常见的命名空间结构有经典的目录树结构如Hadoop 分布式文件系统( Hadoop Distributed FileSystem,HDFS) 等,扁平化结构如【淘宝分布式文件系统( Taobao File System,TFS)等。为了维护命名空间,主控节点需要存储一些元数据( metadata) ,如文件的所有者和权限、文件到数据节点的映射关系等。除了管理命名空间,主控节点还要集中管理数据节点。除了管理命名空间,主控节点还要对数据节点轮询或接收来自数据节点的定期心跳( heartbeat)来集中管理数据节点。主控节点根据得到的消息可以验证文件系统的元数据;若发现数据节点有故障,主控节点将采取修复措施,重新复制在该节点丢失的数据块; 若有新的数据节点加入或某个数据节点负载过高,主控节点会根据情况执行负载均衡。
2 数据节点
数据节点负责数据在集群上的持久化储存。数据节点通常以机架的形式组织,机架通过交换机连接起来。数据节点响应来自客户端的读写请求,还响应来自主控节点的删除和复制命令。类似于磁盘的结构,在数据节点中也有块( block) 的概念,这是数据读写的最小单位,不过这里的块是一个很大的单元,在很多文件系统中通常为 64 MB,如 google 的 GFS、HDFS和 TFS 等。
对于小文件的储存,可以将多个文件储存在一个块中,并建立索引,提高空间利用率; 对于大文件的储存,则会将数据划分为多个数据块,并作为独立的单元进行储存。为了保证数据的安全性和容错性,分布式文件系统会存储多个数据副本在数据节点上。当数据不可用时,可调用存放在其他节点上的副本。在 HDFS 系统中,副本的基本存储策略是: 在任务运行的节点上存储第一个副本; 在任务所在机架内的其他节点中的某一节点存储第二个副本; 在集群的其他机架中的某一节点存储第三个副本。















 2880
2880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









