






最近参加一个比赛,由于数据集较少,需要自己手动爬取一些数据。首先发现原网页是局部刷新页面的,通过分析,拿到了请求json字符串的url,将url直接复制在浏览器中,可以拿到json字符串,接下来码代码爬取数据,主要代码如下:
response = requests.get(url)
if response.status_code == 200:
content = response.text
发现拿到的数据中中文全部变成了\u***之类的数据,首先想到的可能是编码问题,然后去网上搜,试了好多种办法,还是无法解决。
手动将输出的字符赋值为字符串,然后输出,发现竟然是中文
a = "\u5e73\u624b"
print(a)
print(type(a))
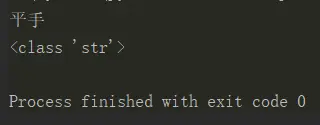
于是就怀疑可能是数据本身有问题,再次查看原网页数据:
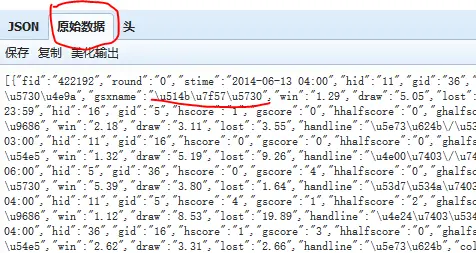
发现原始数据中中文确实是编码,当变为json数据时问题就解决了:
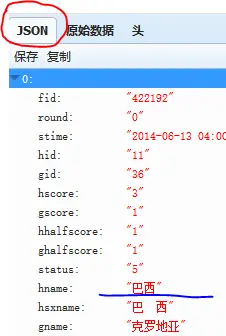
于是修改源代码:
response = requests.get(url)
if response.status_code == 200:
content = response.json()















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









