







 这篇博客介绍了如何快速入门Pandas,包括导入依赖包、创建对象、查看数据、选择数据、处理缺失值、数据运算、数据合并、分组、时间序列分析以及数据的读写操作。通过实例展示了Pandas的基本操作,适合初学者学习。
这篇博客介绍了如何快速入门Pandas,包括导入依赖包、创建对象、查看数据、选择数据、处理缺失值、数据运算、数据合并、分组、时间序列分析以及数据的读写操作。通过实例展示了Pandas的基本操作,适合初学者学习。
通常这样导入依赖包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
创建对象
可以参考官方文档 http://pandas.pydata.org/pandas-docs/version/0.19.2/10min.html
通过传入一个列表建一个序列,默认索引为整数
>>> s = pd.Series([1, 2, 3, np.nan, 5, 6])
>>> s
0 1.0
1 2.0
2 3.0
3 NaN
4 5.0
5 6.0
dtype: float64
其中:NAN(NOt a Number) 表示不存在
- 通过numpy创建一个数组,并且用datetime作为索引和标记列名,创建一个DataFrame
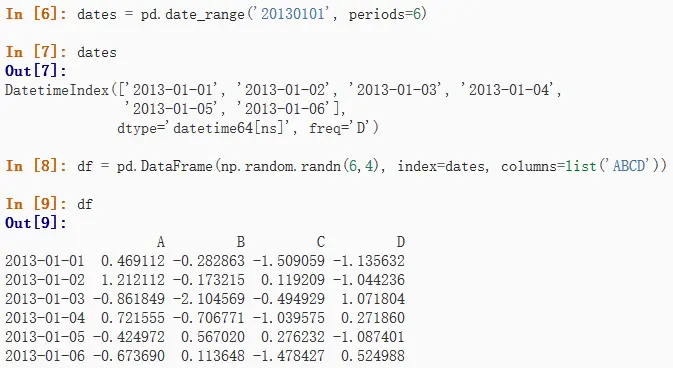
其中pd.date_range('20130101', periods=6)创建了一个时间序列,periods=6表示有6个值,freq='D'表时时间序列按天跨度,也可以指定为w(周)、M(月)等。df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))创建了一个DataFrame,第一个参数表示要填充的数据,第二个参数表示行索引,第三个参数表示列标签,它们的大小要匹配。
- 使用一个可以转换成类序列的字典对象创建一个DataFrame
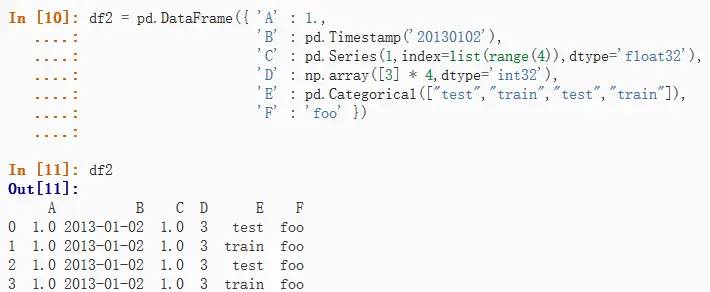
其中字典的每个key作为列标签,该key对应的value为该列的数据,行索引默认创建
查看数据
head()和tail()
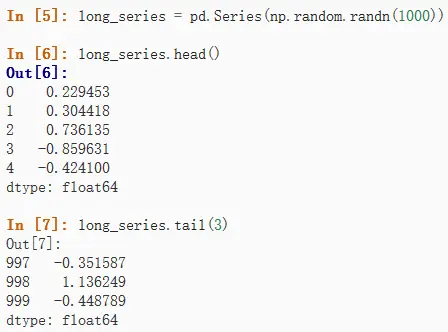
可以使用head()和tail()查看一个DataFrame和Series对象的数据,head()表示从头查起,tail()表示从尾部,默认只查看五项元素,可以自定义。
Series对象:
DataFrame对象:
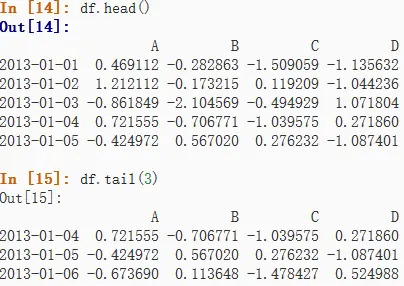
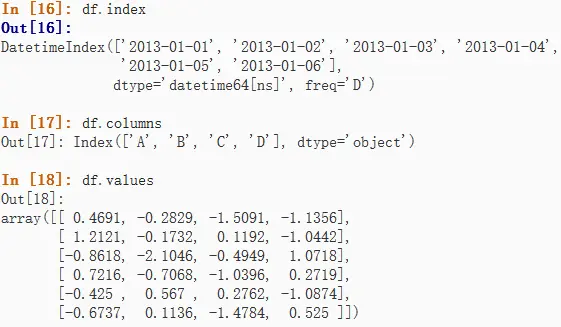
显示索引、行标和数据
分别使用index、columns和values属性访问
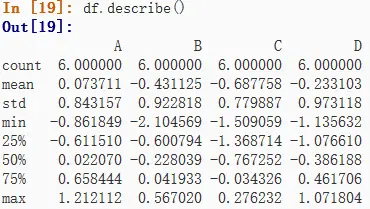
desctibe()
快速显示数据的汇总统计
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









