









引言
前面我们已经介绍了 Kubernetes 的各方面实现方案,但是网络这块比较复杂,所以我们这里单独用来进行介绍,网络部分主要分 5 个部分,即 Pod 网络,Service 网络,外网通讯、LoadBalance、Ingress,本文介绍其中的第一个部分 Pod 网络。更多相关文章和其他文章均收录于贝贝猫的文章目录。
网络原理
作为拓展,这里我们以 flannel 为例展开介绍一下 Kubernetes 内网络通讯的实现。在介绍之前,我们得先明确 Kubernetes 中的三种网络的概念:
- node network:承载 kubernetes 集群中各个“物理”Node(master 和 worker)通信的网络
- service network:由 kubernetes 集群中的 Services 所组成的“网络”,它的范围在启动集群的时候进行了配置
- flannel network:即 Pod 网络,集群中承载各个 Pod 相互通信的网络,它的范围在启动集群和启动网络插件的时候进行了配置
node network 自不必多说,node 间通过其局域网(无论是物理的还是虚拟的)通信。
Pod 网络
pod 网络即 flannel network 是我们要理解的重点,cluster 中各个 Pod 要实现相互通信,必须走这个网络,无论是在同一 node 上的 Pod 还是跨 node 的 Pod。这里以我的集群为例,介绍 flannel 的网络结构。
默认情况下,每个节点会从 PodSubnet 中注册一个掩码长度为 24 的子网,然后该节点的所有 pod ip 地址都会从该子网中分配。当 flannel 启动成功后,会在宿主机上生成一个描述子网环境的文件,该文件中记录了所有 pod 的子网范围(FLANNEL_NETWORK)以及本机 pod 的子网范围(FLANNEL_SUBNET):
cat /run/flannel/subnet.env
# 文件内容如下
#FLANNEL_NETWORK=192.168.128.0/18
#FLANNEL_SUBNET=192.168.132.1/24
#FLANNEL_MTU=1450
#FLANNEL_IPMASQ=true
当集群内的每个机器分配好属于自己的 pod subnet 域后,会在自己的网络设备中新增一个名为 flannel.1的类型为 vxlan 的网络设备:
ip -d link show
#eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
# link/ether fa:16:3f:56:85:66 brd ff:ff:ff:ff:ff:ff promiscuity 0 addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
#flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN mode DEFAULT group default
# link/ether 86:4f:51:1e:bb:38 brd ff:ff:ff:ff:ff:ff promiscuity 0
# vxlan id 1 local 10.231.209.117 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
#cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default qlen 1000
# link/ether 4e:a6:bb:c7:b9:d7 brd ff:ff:ff:ff:ff:ff promiscuity 0
# bridge forward_delay 1500 hello_time 200 max_age 2000 ageing_time 30000 stp_state 0 priority 32768 vlan_filtering 0 vlan_protocol 802.1Q bridge_id 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 root_port 0 root_path_cost 0 topology_change 0 topology_change_detected 0 hello_timer 0.00 tcn_timer 0.00 topology_change_timer 0.00 gc_timer 121.78 vlan_default_pvid 1 vlan_stats_enabled 0 group_fwd_mask 0 group_address 01:80:c2:00:00:00 mcast_snooping 1 mcast_router 1 mcast_query_use_ifaddr 0 mcast_querier 0 mcast_hash_elasticity 4 mcast_hash_max 512 mcast_last_member_count 2 mcast_startup_query_count 2 mcast_last_member_interval 100 mcast_membership_interval 26000 mcast_querier_interval 25500 mcast_query_interval 12500 mcast_query_response_interval 1000 mcast_startup_query_interval 3125 mcast_stats_enabled 0 mcast_igmp_version 2 mcast_mld_version 1 nf_call_iptables 0 nf_call_ip6tables 0 nf_call_arptables 0 addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
#veth65d142e7@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP mode DEFAULT group default
# link/ether 3e:86:a0:c8:f7:ca brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 1
# veth
# bridge_slave state forwarding priority 32 cost 2 hairpin on guard off root_block off fastleave off learning on flood on port_id 0x8001 port_no 0x1 designated_port 32769 designated_cost 0 designated_bridge 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 hold_timer 0.00 message_age_timer 0.00 forward_delay_timer 0.00 topology_change_ack 0 config_pending 0 proxy_arp off proxy_arp_wifi off mcast_router 1 mcast_fast_leave off mcast_flood on addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
从 flannel.1 的设备信息来看,它似乎与 eth0 存在着某种 bind 关系,而 eth0 则是宿主机上的原始网络。这是在其他 bridge、veth 设备描述信息中所没有的。此外我们还可以看出 veth 设备是 cni0 的 bridge_slave。然后我们着重看一下 Kubernetes 各个网卡的 ip。
ip -d addr show
#flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
# link/ether 86:4f:51:1e:bb:38 brd ff:ff:ff:ff:ff:ff promiscuity 0
# vxlan id 1 local 10.231.209.117 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
# inet 192.168.132.0/32 scope global flannel.1
# valid_lft forever preferred_lft forever
#cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default qlen 1000
# link/ether 4e:a6:bb:c7:b9:d7 brd ff:ff:ff:ff:ff:ff promiscuity 0
# bridge forward_delay 1500 hello_time 200 max_age 2000 ageing_time 30000 stp_state 0 priority 32768 vlan_filtering 0 vlan_protocol 802.1Q bridge_id 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 root_port 0 root_path_cost 0 topology_change 0 topology_change_detected 0 hello_timer 0.00 tcn_timer 0.00 topology_change_timer 0.00 gc_timer 226.02 vlan_default_pvid 1 vlan_stats_enabled 0 group_fwd_mask 0 group_address 01:80:c2:00:00:00 mcast_snooping 1 mcast_router 1 mcast_query_use_ifaddr 0 mcast_querier 0 mcast_hash_elasticity 4 mcast_hash_max 512 mcast_last_member_count 2 mcast_startup_query_count 2 mcast_last_member_interval 100 mcast_membership_interval 26000 mcast_querier_interval 25500 mcast_query_interval 12500 mcast_query_response_interval 1000 mcast_startup_query_interval 3125 mcast_stats_enabled 0 mcast_igmp_version 2 mcast_mld_version 1 nf_call_iptables 0 nf_call_ip6tables 0 nf_call_arptables 0 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
# inet 192.168.132.1/24 scope global cni0
# valid_lft forever preferred_lft forever
#veth65d142e7@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master cni0 state UP group default
# link/ether 3e:86:a0:c8:f7:ca brd ff:ff:ff:ff:ff:ff link-netnsid 0 promiscuity 1
# veth
# bridge_slave state forwarding priority 32 cost 2 hairpin on guard off root_block off fastleave off learning on flood on port_id 0x8001 port_no 0x1 designated_port 32769 designated_cost 0 designated_bridge 8000.4e:a6:bb:c7:b9:d7 designated_root 8000.4e:a6:bb:c7:b9:d7 hold_timer 0.00 message_age_timer 0.00 forward_delay_timer 0.00 topology_change_ack 0 config_pending 0 proxy_arp off proxy_arp_wifi off mcast_router 1 mcast_fast_leave off mcast_flood on numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
可以看到 flannel.1 和 cni0 的 ip 和该宿主机被分配的 FLANNEL_SUBNET 的 ip 范围一致。然后,我们再看一看该主机上的路由表:
ip route
#default via <local network gateway> dev eth0 metric 10
#<local subnet> dev eth0 proto kernel scope link src <local ip>
#192.168.128.0/24 via 192.168.128.0 dev flannel.1 onlink
#192.168.129.0/24 via 192.168.129.0 dev flannel.1 onlink
#192.168.130.0/24 via 192.168.130.0 dev flannel.1 onlink
#192.168.131.0/24 via 192.168.131.0 dev flannel.1 onlink
#192.168.132.0/24 dev cni0 proto kernel scope link src 192.168.132.1
#192.168.133.0/24 via 192.168.133.0 dev flannel.1 onlink
路由表显示,当要发送给自己的 pod 子网时(192.168.132.0/24),会通过 cni0 网卡,而当要发送其他宿主机的 pod 时,会通过 flannel.1 网卡。到这里,我们总结一下已经得到的情报,Kubernetes 目前通过 flannel.1 和 cni0 两个网卡来完成 pod 子网的通讯,flannel.1 负责本机 Pod 与其他宿主机 Pod 之间的通讯,cni0 负责本机内 Pod 间的通讯。那么还有两个疑问:1. cni0 又是怎么连通 docker 内容器的?2. flannel.1 是怎么连通其他宿主机的? 我们知道 Pod 内的进程都是跑在 Docker 容器里的,为了探究 cni0 的工作原理,我们就得深入调查一下 Docker 容器使用的网络结构。
# e1adc507e8bc 是 kubia 服务的容器
docker exec -it e1adc507e8bc ip route
#default via 192.168.132.1 dev eth0
#192.168.128.0/18 via 192.168.132.1 dev eth0
#192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.73
docker exec -it e1adc507e8bc ip -d link show
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 promiscuity 0
#3: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default
# link/ether 3e:43:3e:1f:48:a1 brd ff:ff:ff:ff:ff:ff promiscuity 0
# veth
docker exec -it e1adc507e8bc ip -d addr show
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# inet 127.0.0.1/8 scope host lo
# valid_lft forever preferred_lft forever
# inet6 ::1/128 scope host
# valid_lft forever preferred_lft forever
#3: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
# link/ether 3e:43:3e:1f:48:a1 brd ff:ff:ff:ff:ff:ff
# inet 192.168.132.73/24 scope global eth0
# valid_lft forever preferred_lft forever
# inet6 fe80::3c43:3eff:fe1f:48a1/64 scope link
# valid_lft forever preferred_lft forever
我们在 kubia 服务的 docker 容器中,可以看到 docker 内部的网络也已经是宿主机分配的 pod 子网 192.168.132.0/24,它的 ip 是 192.168.132.73,mac 地址是 3e:43:3e:1f:48:a1,而且所有 pod 网段的数据包都是通过 eth0 网卡发送的。那么 docker 容器内的 eth0 网卡的数据是怎么发送到宿主机的呢?我们不妨来看一下该 Pod 的 pause 容器配置,因为网络的设置都在 pause 中完成,其他 pod 内容器都是复用 pause 容器的网络。
# 12e3a9c720d7 是 kubia pod 的 pause 容器
docker inspect 12e3a9c720d7
# 从 NetworkSettings 中我们可以获得如下信息
#"NetworkID": "33fd5df9316947f37e388d49b121d47c589d7a2510b7bf055d6d55e0e57c75c8"
#"EndpointID": "106924f59a8d74db3f8045ac40feb9c9aa5b0ad0b320fadd344496eec39ff107"
然后我们再看一下 docker 中如何定义网络 33fd5df93。
docker network inspect 33fd5df93
很奇怪,在该网络的描述中并没有像 docker0 网桥那样显式地声明自己是网桥类型(“Driver”: “bridge”)。
[
{
"Name": "bridge",
"Id": "2cb95162f702d9f36620f95d61cba76055eeedc3791761209329eab37ef90235",
"Created": "2019-09-25T20:04:07.55834704+09:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Containers": {},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}
}
]
相反的,这里 Kubernetes 使用了null 驱动(“Driver”: “null”)。
[
{
"Name": "none",
"Id": "33fd5df9316947f37e388d49b121d47c589d7a2510b7bf055d6d55e0e57c75c8",
"Created": "2019-09-25T15:56:05.76660028+09:00",
"Scope": "local",
"Driver": "null",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": []
},
"Internal": false,
"Attachable": false,
"Containers": {
"12e3a9c720d72a41e829aeaa3e310436e1b9e33e1a7f8578b065506b64cb9b49": {
"Name": "k8s_POD_kubia-24hmb_default_3586fce7-a27c-4955-9c74-8bd1bb2b9171_0",
"EndpointID": "106924f59a8d74db3f8045ac40feb9c9aa5b0ad0b320fadd344496eec39ff107",
"MacAddress": "",
"IPv4Address": "",
"IPv6Address": ""
},
"598b6a4eeba4ae11ecfb2f07603bda106ade78acfea6776bb1aad624edc2d850": {
"Name": "k8s_POD_kubia-rpr99_default_a628f355-75c4-4d4b-a637-a81e3b30a156_0",
"EndpointID": "dfe139b8af4391507ed411d813200adbe7a3d9f30ab78e4682025e24afa30fec",
"MacAddress": "",
"IPv4Address": "",
"IPv6Address": ""
},
"e7e15a5df3880d22a2ca4b254f959346d487c5b8869af0448989a73f518cb553": {
"Name": "k8s_POD_coredns-5644d7b6d9-v56sk_kube-system_53751e33-88d8-4ab0-a831-a4fdf04c3fae_0",
"EndpointID": "5232bea08ee84f86ed5b6489743061377766d495139ff9e42b7e21d110d23d65",
"MacAddress": "",
"IPv4Address": "",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]
bridge 驱动,默认模式,即 docker0 网桥模式。此驱动为 docker 的默认设置,使用这个驱动的时候,libnetwork 将创建出的 Docker 容器连接到 Docker 网桥上。作为最常规的模式,bridge 模式已经可以满足 Docker 容器最基本的使用需求了。然而其与外界通信使用 NAT,增加了通信的复杂性,在复杂场景下使用会有诸多限制。
null 驱动使用这种驱动的时候,Docker 容器拥有自己的 network namespace,但是并不需要 Docker 容器进行任何网络配置。也就是说,这个 Docker 容器除了 network namespace 自带的 loopback 网卡外,没有其他任何网卡、IP、路由等信息,需要用户为 Docker 容器添加网卡、配置 IP 等。这种模式如果不进行特定的配置是无法正常使用的,但是优点也非常明显,给了用户最大的自由度来自定义容器的网络环境。
这么看来,每个 pod 中的网络空间应该是独立的,Kubernetes 创建好容器后手动向 docker 容器的 network 命名空间中加网卡,进而连通到宿主机的 cni0 网桥的。
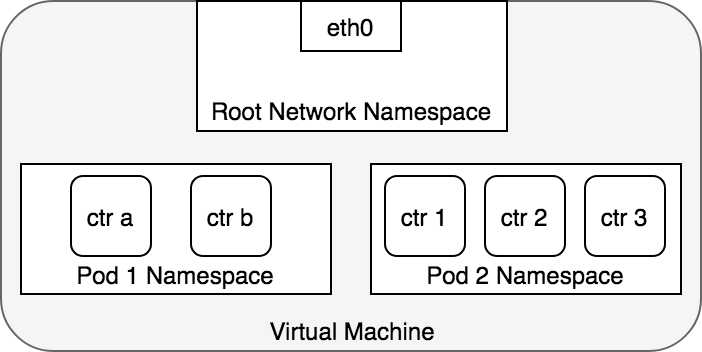
那么它又是怎么做到的呢?为了复现 Kubernetes 管理容器网络的方案,我创建了一个新的容器,并且同样使用前面用到的 kubia 镜像。同时,我们也使用 Kubernetes 的 null Driver 网络。
docker create --network 33fd5df931694 beikejiedeliulangmao/kubia
# 确认一下容器内的网卡情况,发现确实只有 loopback
docker exec -it 8ef9475b6d6e ip a
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# inet 127.0.0.1/8 scope host lo
# valid_lft forever preferred_lft forever
# inet6 ::1/128 scope host
# valid_lft forever preferred_lft forever
然后,我们使用 Kubernetes 的 cni0 网桥,连通容器和宿主机,具体怎么做呢?第一步,我们先将容器内的网络空间共享出来,让宿主机可以操作。
# 查看容器的 pid
docker inspect 8ef9475b6d6e|grep Pid
# "Pid": 68791
# 创建网络命名空间目录,后面操作网络空间时都会基于此目录存储的内容
mkdir /var/run/netns
# 根据 pid 得到容器的网络空间,然后通过软连接的方式共享到宿主机空间
ln -s /proc/68791/ns/net /var/run/netns/8ef9475b6d6e
# 确认网络空间是否出现
ip netns list
# 然后查看网络空间的内容
ip netns exec 8ef9475b6d6e ip a
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# inet 127.0.0.1/8 scope host lo
# valid_lft forever preferred_lft forever
# inet6 ::1/128 scope host
# valid_lft forever preferred_lft forever
到这为止,我们就可以在宿主机中,看到 docker 容器的网络空间内容了,接下来是第二步,基于 Kubernetes 的 cni0 网桥连通宿主机和新建的容器。
# 我们先看一下网桥的名字
brctl show
#bridge name bridge id STP enabled interfaces
#cni0 8000.4ea6bbc7b9d7 no veth0bcd3dfd
# veth65d142e7
# veth9e1cec0c
# 如果您想自己创建一个新的网桥的话可以通过如下命令:
#brctl addbr newBridge
#ip addr add x.x.x.x/x dev newBridge
#ip link set dev newBridge up
# 这里我们直接使用 Kubernetes 的 cni0 网桥,然后创建一个连接对端 peer
ip link add veth123 type veth peer name veth456
# 将 veth123 插到宿主机的 cni0 网桥上
brctl addif cni0 veth123
ip link set veth123 up
brctl show
#bridge name bridge id STP enabled interfaces
#cni0 8000.4ea6bbc7b9d7 no veth0bcd3dfd
# veth65d142e7
# veth9e1cec0c
# veth123
# 将 veth456 放入容器的网络空间后,容器中就能看到该网络设备,而宿主机中就看不到了
ip link set veth456 netns 8ef9475b6d6e
ip netns exec 8ef9475b6d6e ip a
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# inet 127.0.0.1/8 scope host lo
# valid_lft forever preferred_lft forever
# inet6 ::1/128 scope host
# valid_lft forever preferred_lft forever
#13: veth456@if14: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
# link/ether ae:17:f4:64:63:05 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 我们也将容器中的网卡重命名为 eth0,启动后再为其分配一个 ip 地址
ip netns exec 8ef9475b6d6e ip link set veth456 name eth0
ip netns exec 8ef9475b6d6e ip link set eth0 up
ip netns exec 8ef9475b6d6e ip addr add 192.168.132.150/24 dev eth0
ip netns exec 8ef9475b6d6e ip a
#1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# inet 127.0.0.1/8 scope host lo
# valid_lft forever preferred_lft forever
# inet6 ::1/128 scope host
# valid_lft forever preferred_lft forever
#13: eth0@if14: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
# link/ether ae:17:f4:64:63:05 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# inet 192.168.132.150/24 scope global eth0
# valid_lft forever preferred_lft forever
# inet6 fe80::ac17:f4ff:fe64:6305/64 scope link
# valid_lft forever preferred_lft forever
# 是不是网络设备的信息已经和 Kubernetes 的容器内网络信息一样了
ip netns exec 8ef9475b6d6e ip route
#192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.150
# 然后我们在宿主机 ping 一下该主机
ping 192.168.132.150
#PING 192.168.132.150 (192.168.132.150) 56(84) bytes of data.
#64 bytes from 192.168.132.150: icmp_seq=1 ttl=64 time=0.210 ms
#64 bytes from 192.168.132.150: icmp_seq=2 ttl=64 time=0.094 ms
现在,我们新建的容器已经能和宿主机连通了,但是还不能 ping 通其他网络设备,所以我们给其加一个默认路由,就像 Pod 容器中一样。
ip netns exec 8ef9475b6d6e ip route add default via 192.168.132.1
ip netns exec 8ef9475b6d6e ip route add 192.168.128.0/18 via 192.168.132.1
ip netns exec 8ef9475b6d6e ip route
#ip netns exec 8ef9475b6d6e ip route
#default via 192.168.132.1 dev eth0
#192.168.128.0/18 via 192.168.132.1 dev eth0
#192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.150
ip netns exec 8ef9475b6d6e ping 192.168.132.73
ip netns exec 8ef9475b6d6e curl 192.168.132.73:8080
ip netns exec 8ef9475b6d6e ping 172.17.0.2
ip netns exec 8ef9475b6d6e curl google.com
ip netns exec 8ef9475b6d6e ping google.com
现在我们的容器网络不光能连通 pod 的网络,还能连通其他段(172.17.0.1)的网络啦。这里大家可能会有一个疑问,为什么我能 curl 连通 google.com,但是 ping 却不行呢?因为在宿主机上对 tcp 做了 SNAT,而 ping 使用的 icmp 则没有做 SNAT,这就导致从我们建立的网络中发出去的 icmp 包有去无回。
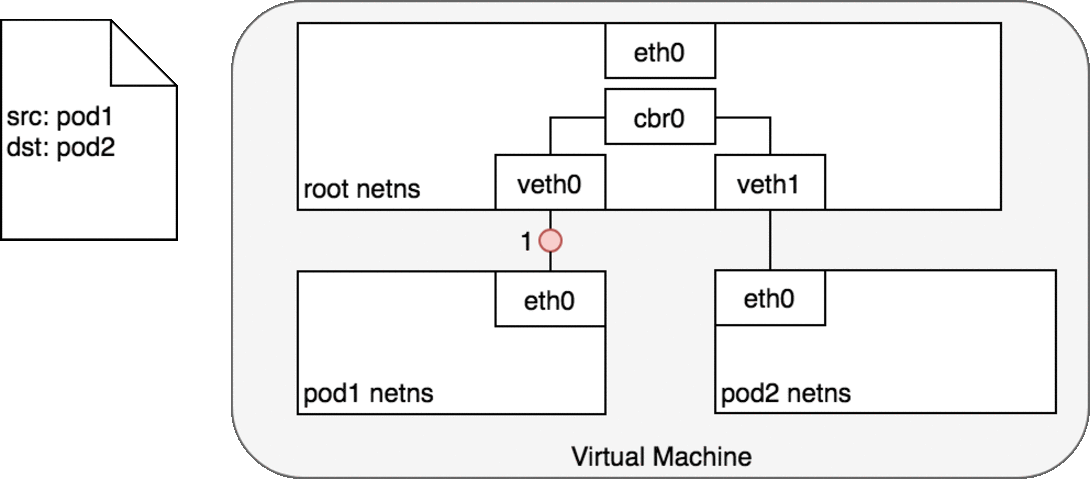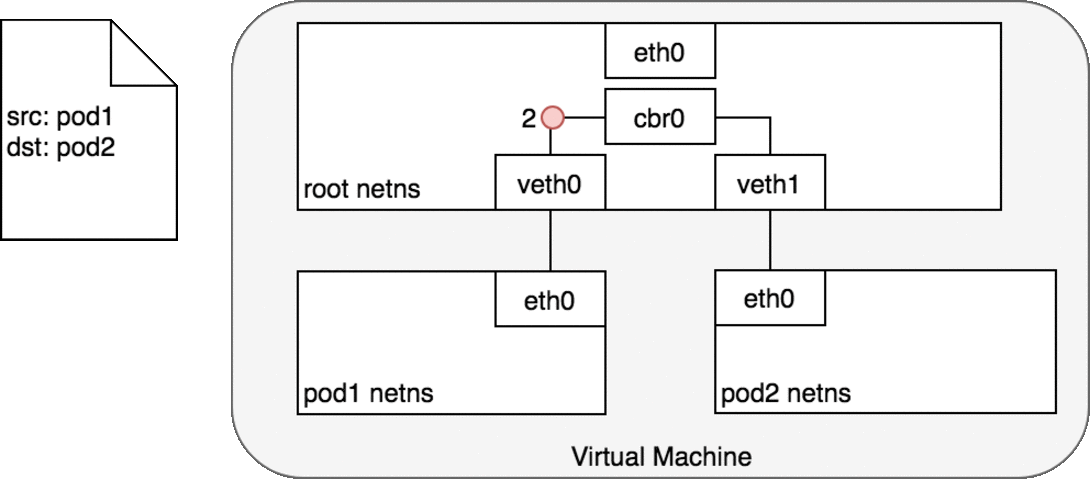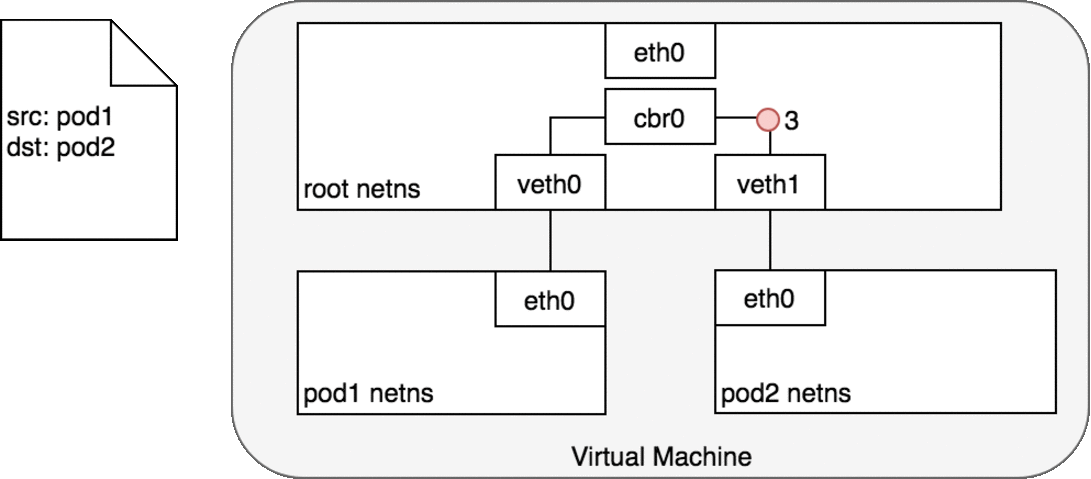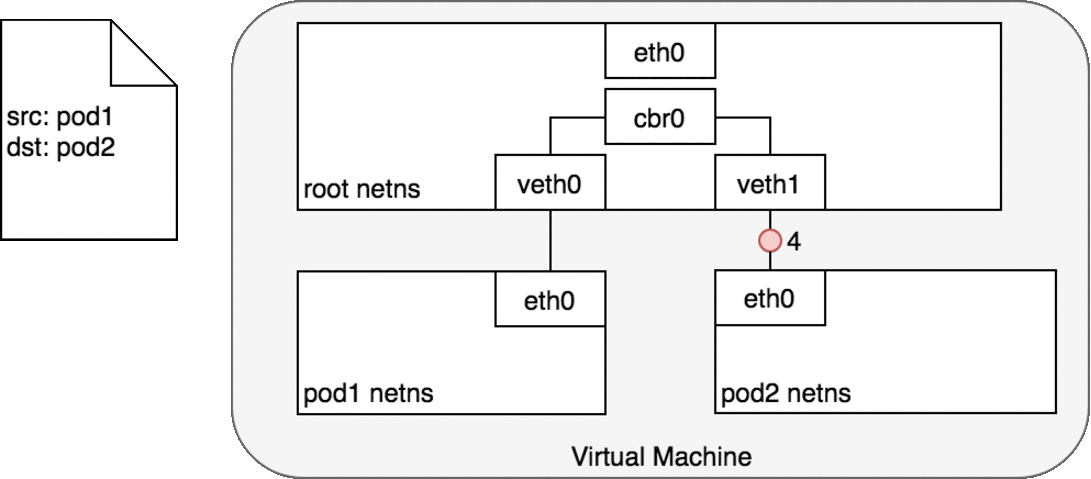
图中的 cbr0 实际上就是 cni0 网桥的别名。在 Kubernetes 的 cni 中默认将网络命名为 cbr0,您可以在
/var/lib/cni/networks/cbr0中看到 Kubernetes 分配的所有地址,以及每个地址对应的容器 id(ip 地址作为文件名),而在/var/lib/cni/cache/results中存储了每个容器对应的网桥和插在网桥上的对端网络设备。
好了,我们终于解决了第一个问题:cni0 设备是如何连通 docker 容器,并让容器间的网络互通的。不同容器间的通讯是通过直联网络,实质上 cni0 在网络中的第二层(数据链路层)运转,这里以我们新建的容器和 pod 容器之间的通讯为例。当我们在新建的容器中 ping pod 容器,根据路由表,将匹配到 192.168.132.0/24 dev eth0 proto kernel scope link src 192.168.132.150,即无需 gateway 转发便可以直接将数据包送达。ARP 查询后(要么从 arp cache 中找到,要么在 cni0 这个二层交换机中泛洪查询)获得 192.168.132.73 的 mac 地址。ip 包的目的 ip 填写 192.168.132.73,二层数据帧封包将目的 mac 填写为刚刚查到的 mac 地址,通过 eth0(192.168.132.150)发送出去。eth0 实际上是一个 veth pair,另外一端“插”在 cni0 这个交换机上,因此这一过程就是一个标准的二层交换机的数据报文交换过程, cni0 相当于从交换机上的一个端口收到以太帧数据,并将数据从另外一个端口发出去。只有当在 pod 中访问 localhost,127.0.0.1,或者自己的 ip 时,数据帧只会和容器内的 eth0 交互。
泛洪查询:交换机根据收到数据帧中的源MAC地址建立该地址同交换机端口的映射,并将其写入 MAC 地址表中。交换机将数据帧中的目的 MAC 地址同已建立的 MAC 地址表进行比较,以决定由哪个端口进行转发。如数据帧中的目的 MAC 地址不在 MAC 地址表中,则向所有端口转发。当任意节点回应了该数据帧,就将该节点的 MAC 地址和上述 IP 绑定,存在 MAC 表中。
而如果我是在刚才的容器中 ping 了其他网段的地址 比如 docker的默认网桥 docker0 172.17.0.2。当 ping 执行后,根据容器路由表,没有匹配到直连网络,只能通过 default 路由将数据包发给Gateway: 192.168.132.1。虽然都是 cni0 接收数据,但这次更类似于“数据被直接发到 Bridge 上(因为桥的 ip 就是 192.168.132.1),而不是 Bridge 从一个端口接收转发给另一个端口”。二层的目的 mac 地址填写的是 gateway 192.168.132.1 自己的 mac 地址(cni0 Bridge的mac地址),此时的 cni0 更像是一块普通网卡的角色,工作在三层(网络层)。cni0 收到数据包后,发现并非是发给自己的 ip 包,通过主机路由表找到直连链路路由,cni0 将数据包 Forward 到 docker0 上(封装的二层数据包的目的 MAC 地址为 docker0 的 mac 地址)。此时的 docker0 也是一种“网卡”的角色,由于目的 ip 依然不是 docker0 自身,因此 docker0 也会继续这一转发流程。通过 traceroute 可以印证这一过程:
ip netns exec 8ef9475b6d6e traceroute 172.17.0.2
#traceroute to 172.17.0.2 (172.17.0.2), 30 hops max, 60 byte packets
# 1 192.168.132.1 0.124 ms 0.053 ms 0.030 ms
# 2 172.17.0.1 3005.955 ms !H 3005.909 ms !H 3005.875 ms !H
现在,我们开始探索第二个问题,flannel.1 网络设备如何连通不同主机之间的 pod。通过前面的 docker0 例子中,我们知道 pod 中的数据帧如何通过宿主机的路由转发到其他网络设备,现在我们假设要发请求给另一个宿主机上的 pod(192.168.128.10),这时候会匹配到 192.168.128.0/24 via 192.168.128.0 dev flannel.1 onlink。因为本机 flannel.1 网络设备的 ip(192.168.132.0) 并不是目标地址(192.168.128.10),所以数据帧到达 flannel.1 之后也是要发出去。数据包沿着网络协议栈向下流动,在二层时需要封二层以太包,填写目的 mac 地址,这时一般应该发出 ARP:”who is 192.168.128.10″,但是要记住 flannel.1 是一个 vxlan 设备,因为该类设备的特殊性,他并不会真正的在第二层发送这个 ARP 包,而是由 linux kernel 引发一个 ”L2 MISS” 事件并将 ARP 请求发到用户空间的 flannel 程序。flannel 程序收到 ”L2 MISS” 内核事件以及 ARP 请求(who is 192.168.128.10)后,并不会向外网发送 ARP request,而是尝试从 etcd 查找该地址匹配的子网的 VtepMAC 信息,该信息目前存在 /registry/minions/<host_name>。
VxLan: 全称是 Virtual eXtensible Local Area Network,虚拟可扩展的局域网。它是一种 overlay 技术,通过三层的网络来搭建虚拟的二层网络, 只要是三层可达(能够通过 IP 互相通信)的网络就能部署 vxlan。接下来的实例中,您会清晰地了解到 VxLan 如何工作。
接下来,flannel 将查询到的信息放入宿主机的 ARP cache表中:
ip n |grep 192.168
#192.168.132.100 dev cni0 lladdr 7a:cf:98:ce:4b:cc STALE
#192.168.132.70 dev cni0 lladdr 12:4a:7a:31:5b:d7 REACHABLE
#192.168.132.150 dev cni0 lladdr ae:17:f4:64:63:05 STALE
#192.168.132.73 dev cni0 lladdr 3e:43:3e:1f:48:a1 STALE
#192.168.133.0 dev flannel.1 lladdr 02:4e:1e:94:98:20 PERMANENT
#192.168.132.69 dev cni0 lladdr ca:b7:e3:83:0d:3a STALE
#192.168.129.0 dev flannel.1 lladdr 7a:52:54:58:5f:4c PERMANENT
#192.168.128.0 dev flannel.1 lladdr 26:12:3f:ba:e9:f5 PERMANENT
#192.168.131.0 dev flannel.1 lladdr 62:6d:b4:f7:47:0b PERMANENT
#192.168.130.0 dev flannel.1 lladdr 56:d7:1a:70:7b:e0 PERMANENT
#192.168.132.72 dev cni0 lladdr f2:98:cd:7b:23:d9 STALE
flannel 完成这项工作后,linux kernel 就可以在 ARP table 中找到 192.168.128.10 对应的子网基ip(192.168.128.0)的 mac 地址并封装二层以太包了。
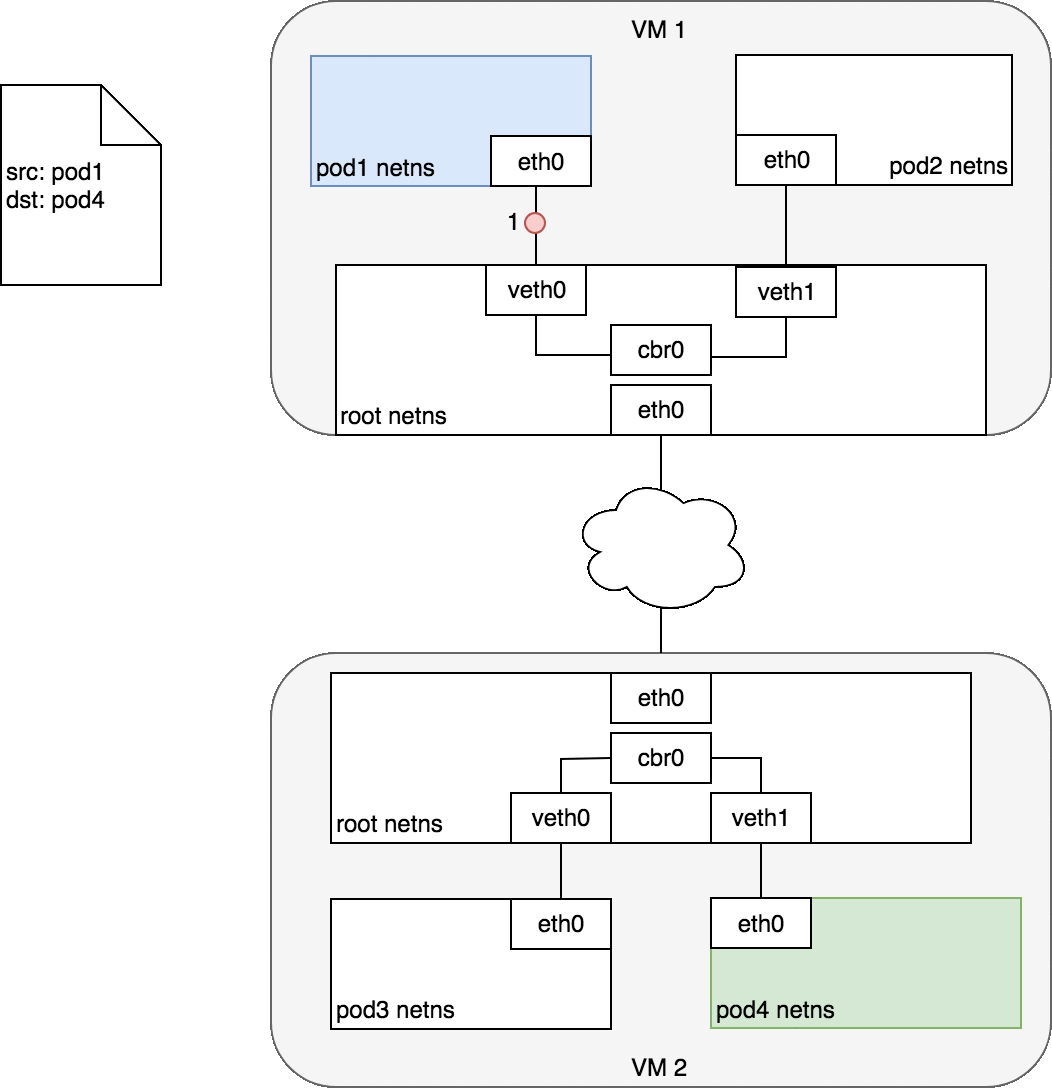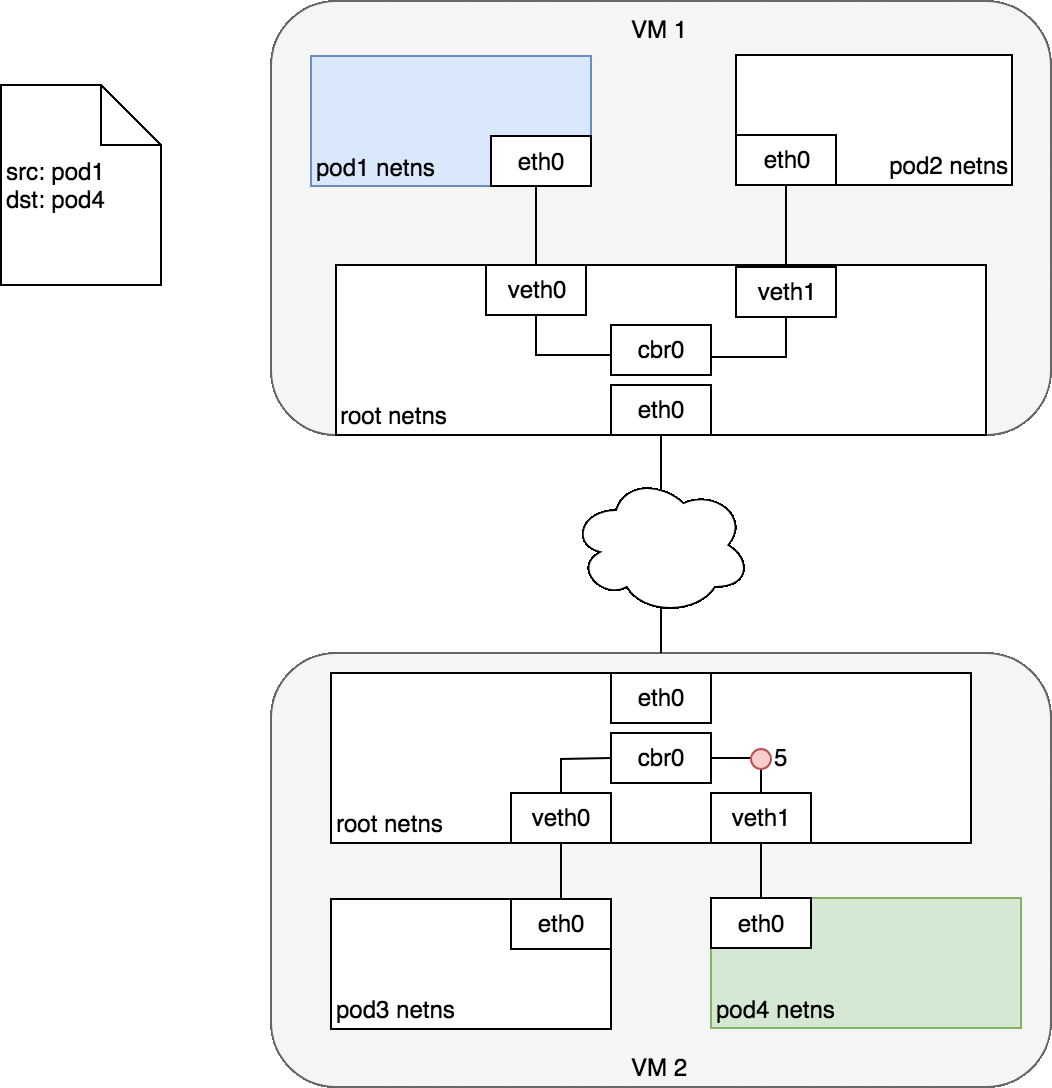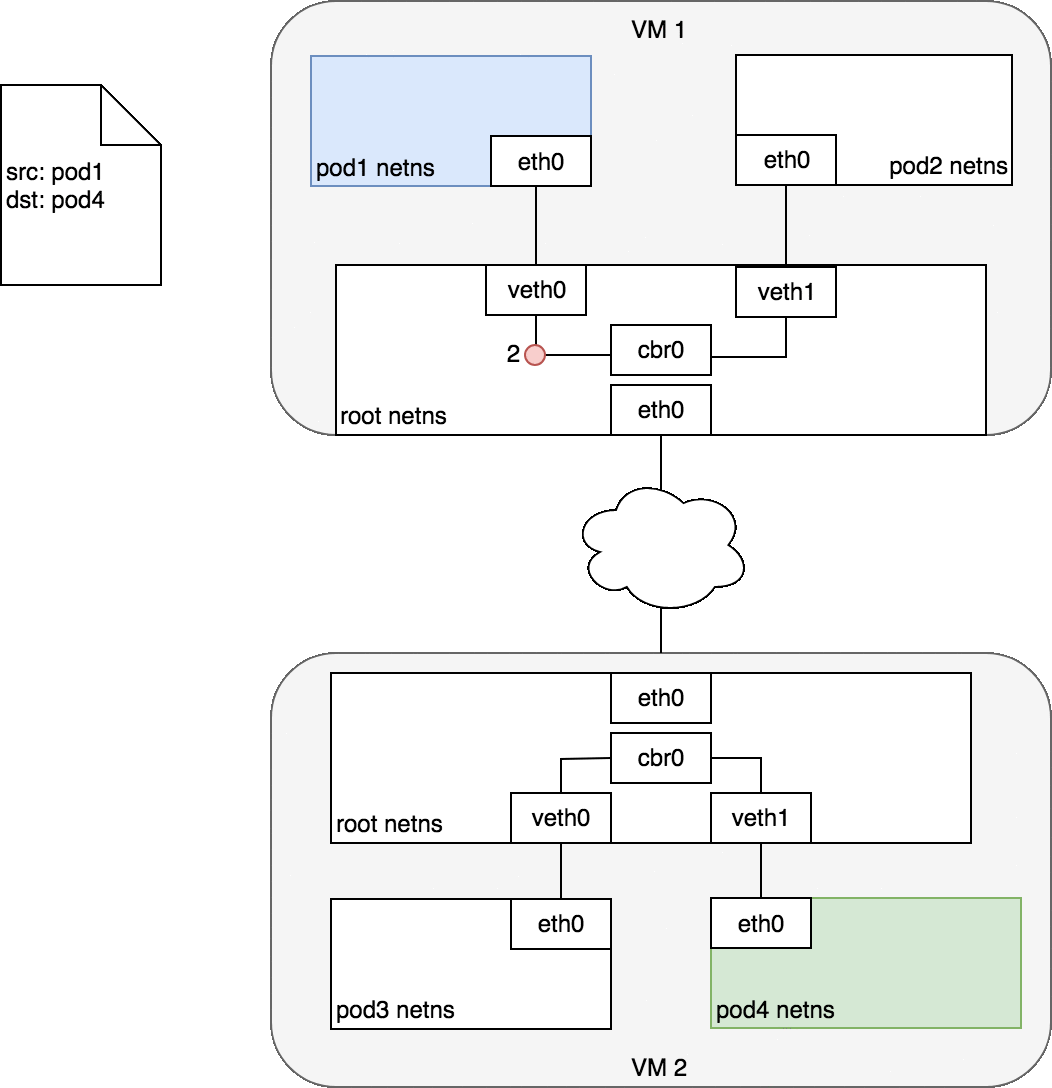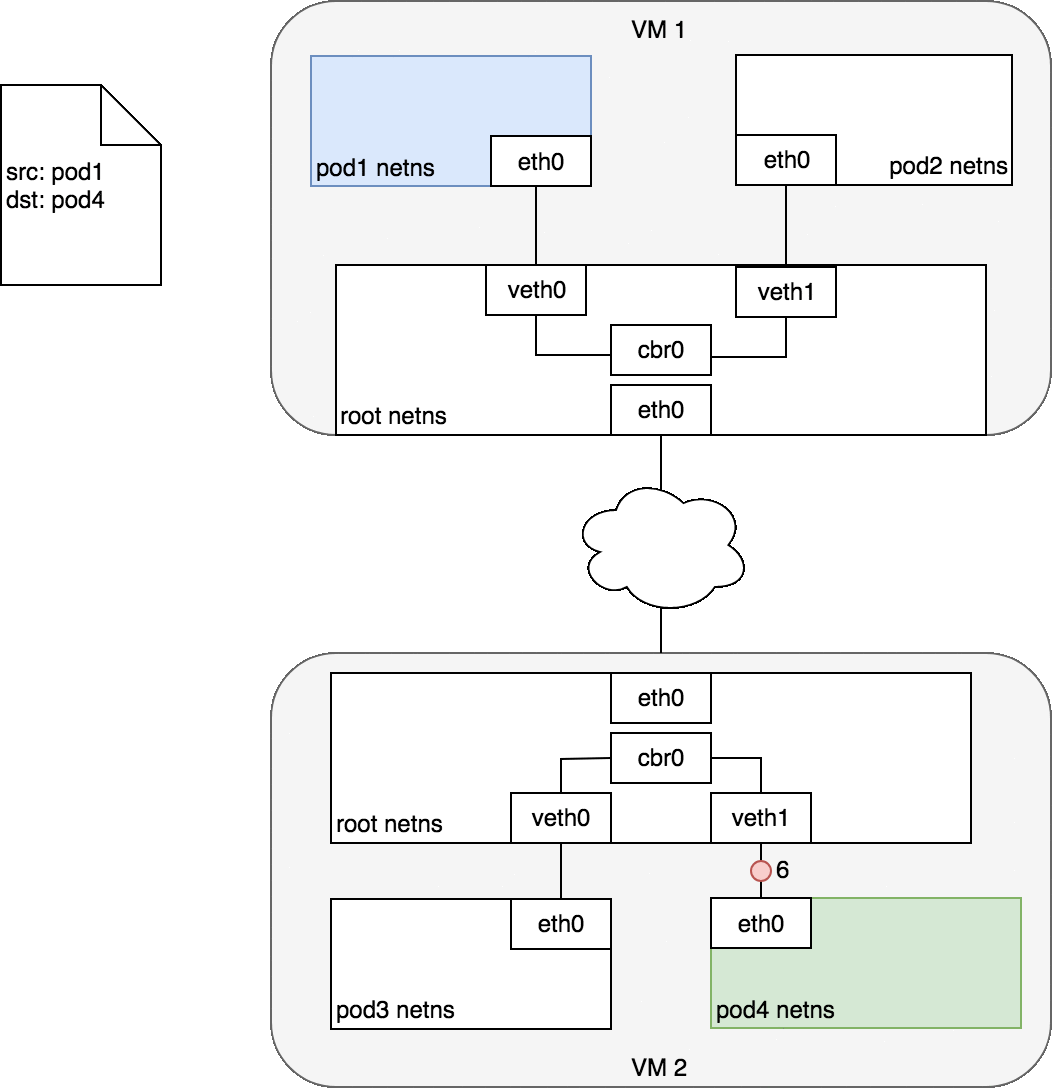
到目前为止,已经呈现在大家眼前的封包如下图:
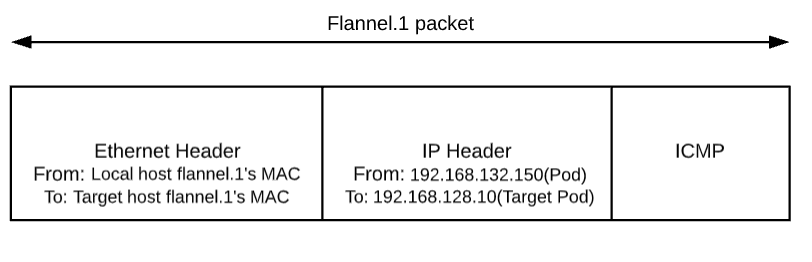
不过这个封包还不能在物理网络上传输,因为它实际上只是 vxlan tunnel 上的 packet。我们需要将上述的 packet 从本机传输到目标机器上,这就得再次封包。这个任务在 vxlan 的 flannel network 中由 linux kernel 来完成。
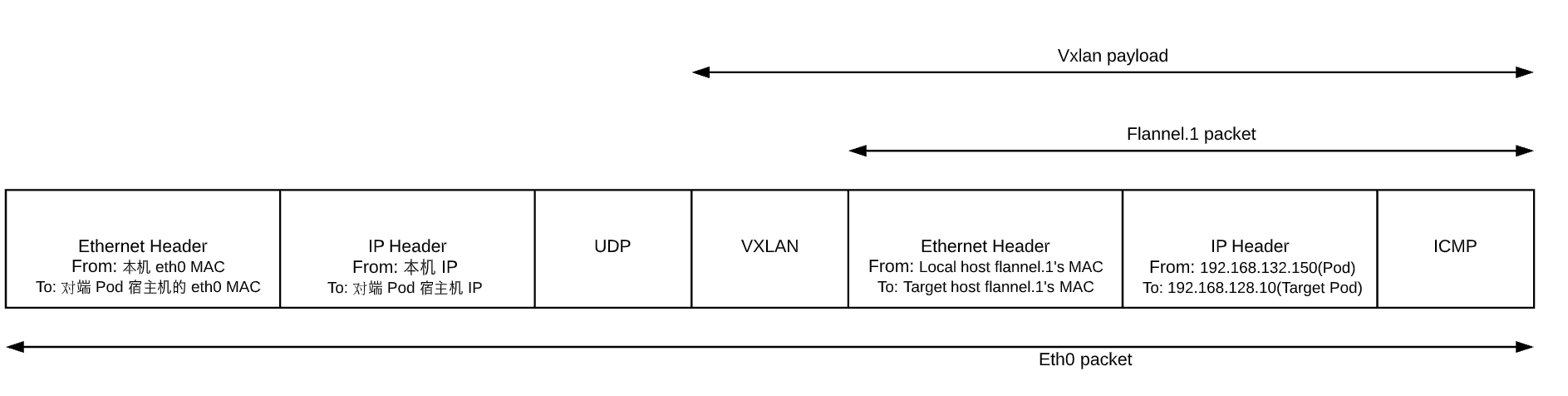
flannel.1 为 vxlan 设备,linux kernel 可以自动识别,并将上面的 packet 进行 vxlan 封包处理。在这个封包过程中,kernel 需要知道该数据包究竟发到哪个 node 上去。kernel 需要查看本机上的 fdb(forwarding database)以获得上面对端 vtep 设备(已经从 ARP table 中查到其mac地址:26:12:3f:ba:e9:f5)所在的 node 地址。如果 fdb 中没有这个信息,那么 kernel 会向用户空间的 flannel 程序发起”L3 MISS”事件。flannel 收到该事件后,会查询 etcd,获取该 vtep 设备对应的 node 的 IP,并将信息注册到 fdb 中。
这样 Kernel 就可以顺利查询到该信息并封包了:
bridge fdb show dev flannel.1|grep 26:12:3f:ba:e9:f5
#26:12:3f:ba:e9:f5 dst <target node ip> self permanent
由于目标 ip 是对端 pod 所处宿主机的 ip,查找路由表,包应该从本机的 eth0 发出,这样 src ip 和 src mac 地址也就确定了。封好的包示意图如下:
当对端宿主机 eth0 接收到该 vxlan 报文后,kernel 将识别出这是一个 vxlan 包,于是拆包后将 flannel.1 packet 转给自身的 vtep(flannel.1)。然后 flannel.1 再将这个数据包转到自己的的 cni0,继而由 cni0 传输到 Pod 的某个容器里。
参考内容
[1] kubernetes GitHub 仓库
[2] Kubernetes 官方主页
[3] Kubernetes 官方 Demo
[4] 《Kubernetes in Action》
[5] 理解Kubernetes网络之Flannel网络
[6] Kubernetes Handbook
[7] iptables概念介绍及相关操作
[8] iptables超全详解
[9] 理解Docker容器网络之Linux Network Namespace
[10] A Guide to the Kubernetes Networking Model
[11] Kubernetes with Flannel — Understanding the Networking
[12] 四层、七层负载均衡的区别
















 3170
3170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











