








今天LN现场售后人员反馈一台服务器上的业务办理出现问题,主要是运行缓慢,附带卡顿现象,没办法救急入救火就远程过去查查原因,本文用于记录排查过程并整理一些相关资料,希望对遇到类似问题的小伙伴们有帮助
排查过程:
第一步
先看看服务器情况,使用top命令可以监控linux的系统状况,主要用户查看显示系统中各个进程的资源占用情况,察看信息后发现CPU 占用高达100%+
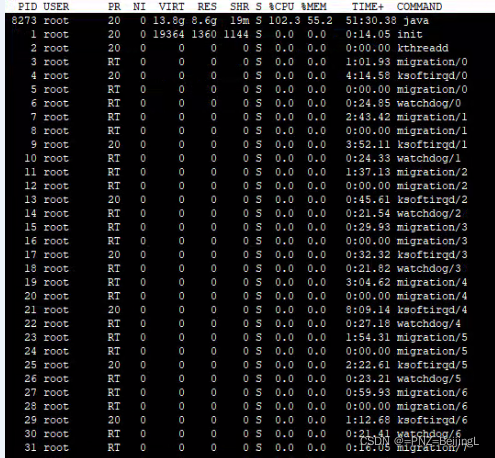
top命令格式
格式:top [-] [d delay] [q] [c] [S] [s] [i] [n] [b]
-
d : 改变显示的更新速度,
-
q : 没有任何延迟的显示速度
-
c : 切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称
-
S : 累积模式,会将己完成或消失的子进程 ( dead child process ) 的 CPU time 累积起来
-
s : 安全模式,将交谈式指令取消, 避免潜在的危机
-
i : 不显示任何闲置 (idle) 或无用 (zombie) 的进程
-
n : 更新的次数,完成后将会退出 top
-
b : 批次档模式,搭配 "n" 参数一起使用,可以用来将 top 的结果输出到档案内
top 列含义
| 列名 | 含义 |
| PID | 进程id |
| PR | 优先级 |
| NI | nice值。负值表示高优先级,正值表示低优先级 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| SHR | 共享内存大小,单位kb |
| S | 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| %MEM | 进程使用的物理内存百分比 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| COMMAND | Command Name/Line命令名/命令行。 |
第二步
CPU占比高,此问题多数是JVM 因堆内存不足频繁Full GC引起 。垃圾回收是根据可达性分析算法将不在GC Root根的引用链上的对象回收, 计算时会引发JVM 中的STW事件(stop the world),此事件使Java应用程序暂时停顿,被STW中断的应用程序线程会在完成GC之后恢复,这个停顿就让业务出现卡顿现象 ,
所以使用jstat命令查看 Jstat命令查看JVM 信息,出乎我的意料,从信息中发现没有出现频发FGC的情况出现。一般频繁full gc的时候, FGC的次数会很多,GCT的时间会很大, 但我查询信息中FGC的次数并不大,因此这次问题不是 Full GC引起的CPU高负载+卡顿现象

jstat 命令格式
jstat [-命令选项] [vmid] [间隔时间/毫秒] [查询次数]
jstat 列含义
| 列名 | 含义 |
| S0C | 第一个幸存区的大小 |
| S1C | 第二个幸存区的大小 |
| S0U | 第一个幸存区的使用大小 |
| S1U | 第二个幸存区的使用大小 |
| EC | 伊甸园区的大小 |
| EU | 伊甸园区的使用大小 |
| OC | 老年代大小 |
| OU | 老年代使用大小 |
| YGC | 年轻代垃圾回收次数 |
| YGCT | 年轻代垃圾回收消耗时间 |
| FGC | 老年代垃圾回收次数 |
| FGCT | 老年代垃圾回收消耗时间 |
| GCT | 垃圾回收消耗总时间 |
第三步
不是JVM问题那么就只能查看线程栈了 ,所以使用jstack 查询这个线程到底在干嘛,使用top -Hp 进程号命令找到 CPU 消耗最多的线程号,从中发现正在运行的线程十分可疑,其占用CUP很高,将其转换成16进制 再从jstatck栈日志中查看211e的信息,信息如下显示
printf "0%x\n" PID 此应用是一个老系统,老系统使用了ehcache当做缓存,从下发的栈信息发现,ehcache 正在执行OverflowDiskWriteTask任务,这个任务是ehcache超过最大缓存数后将缓存内容写入磁盘的操作,然后查看磁盘上的文件大小仍在增长,
所以本问题是由于ehcache在不停的做写操作占用CPU,让CPU飙升
"daoCache.data" daemon prio=10 tid=0x00007f199d281000 nid=0x211e runnable [0x00007f1a01942000]
java.lang.Thread.State: RUNNABLE
at java.io.ByteArrayOutputStream.<init>(ByteArrayOutputStream.java:77)
at net.sf.ehcache.util.MemoryEfficientByteArrayOutputStream.<init>(MemoryEfficientByteArrayOutputStream.java:50)
at net.sf.ehcache.util.MemoryEfficientByteArrayOutputStream.serialize(MemoryEfficientByteArrayOutputStream.java:89)
at net.sf.ehcache.store.compound.factories.DiskStorageFactory.serializeElement(DiskStorageFactory.java:300)
at net.sf.ehcache.store.compound.factories.DiskStorageFactory.write(DiskStorageFactory.java:280)
at net.sf.ehcache.store.compound.factories.DiskStorageFactory$DiskWriteTask.call(DiskStorageFactory.java:385)
at net.sf.ehcache.store.compound.factories.DiskOverflowStorageFactory$OverflowDiskWriteTask.call(DiskOverflowStorageFactory.java:246)
at net.sf.ehcache.store.compound.factories.DiskOverflowStorageFactory$OverflowDiskWriteTask.call(DiskOverflowStorageFactory.java:235)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744)jstack 格式
jstack [-l] pid
- -f 当’jstack [-l] pid’没有相应的时候强制打印栈信息
- -l 长列表. 打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表.
- -m 打印java和native c/c++框架的所有栈信息.
- -h 或者 -help 打印帮助信息
- pid 需要被打印配置信息的java进程id
解决方案:
问题是由于ehcache在不停的做写操作占用CPU,让CPU飙升,系统不能重启, 因此临时处理方案是从JBOSS控制台将其缓存清空,清空后问题解决
问题解决后看了下 ehcache.xml中的缓存配置, 配置中缓存的闲置时间timeToIdleSeconds时间为4小时,缓存个数是5W。从配置上分析怀疑是业务代码中存在问题,4小时内缓存了大量命中率低的数据,造成缓存数超过5W后ehcache开启将缓存写入磁盘的操作,所以暂时给售后以下建议
- 建议售后先将闲置时间timeToIdleSeconds修改为1小时, 此处也不敢直接修改的太小,有点儿担心不了系统造成系统其他问题,打算观察一段时间后再来决定设置的值
- 建议将overflowToDisk=true,修改成false禁止将缓存写入磁盘,毕竟缓存是用于提高读取速度。
其实 ehcache 已经很少被使用了,reidis作为缓存是当今主流, 考虑到迁移需要投入的人力成本,迁移问题暂时搁置吧,考虑成本无法把事情做到最好估计也是很多人心中的痛

















 9551
9551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











