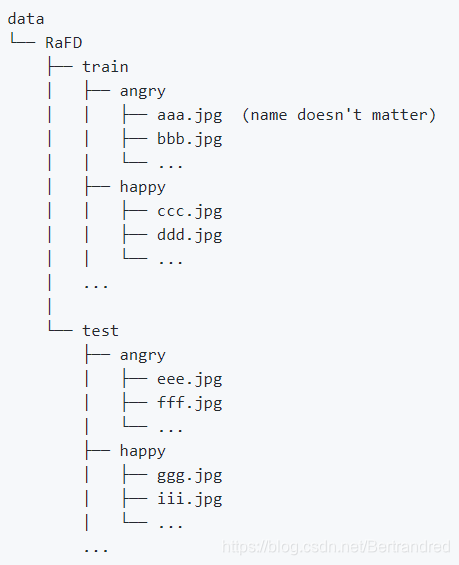
前情提要论文学习:link 参考的论文实现代码(Pytorch):link 环境 Python3.6 Pytorch1.0.0 (平台没有装Tensorflow的条件,所以砍掉了代码里的可视化部分) 数据集 RaFD申请:link 数据集处理:link 1.90%的训练集和10%的测试集 2.裁剪为人脸居中的256x256 3.存放的目录结构如下 训练 在RaFD上训练StarGAN # Train StarGAN using the RaFD dataset python main.py -








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1478
1478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






