







PLSA: Probabilistic Latent Semantic Analysis
在文本处理中,我们常常直接根据文本的内容,将document 和term直接关联分析,比如计算term frequency等。而在topic模型中,我们认为document是有主题topic的,topic才是直接和term关联的,但是topic又是不可观测的变量,所以它是一个隐含变量,则document 和term都可以看成是该隐含变量的分布。具体如图:
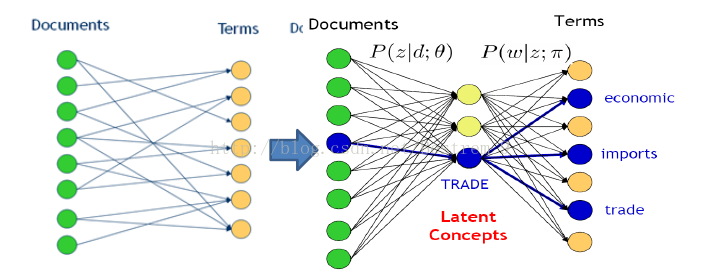
由于topic是隐含变量,那如何描述doc,topic,term之间的关系呢,这里假设每篇文档d都可以以概率p(z|d)属于某一个主题,并且在给定主题后,每个词都以一定的概率p(w|z)产生,这样文档和词一同出现的概率就可以通过概率来进行描述:
通过PLSA分析可以得到p(d|z), p(w|z)的概率。
利用图模型的PLSA的描述为:

那么改如何求解?我们都知道在p(d,w)含有隐含变量,如果直接利用最大似然函数的方法来求解的话, 就会遇到类似于GMM的问题,难以直接求解,那么同样可以采用EM算法来进行求解:
目标是doc和term的联合概率的似然函数最大:

其中E-step来估计概率:
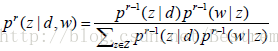
M-step:来更新参数:
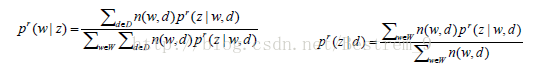
直至最后收敛。















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









