






Transferable Environment Poisoning: Training-time Attack on Rein-forcement Learning
计划把看过的针对DRL和RL对抗攻击的文献记录一下,方便后续回顾~今天先写一个
1.文章主要内容
这篇文章主要目的是构建一个双层马尔可夫过程,攻击者的策略基于一个马尔可夫链优化,每隔一段时间攻击者可以操纵受害者的环境动态。攻击者的目标:学习攻击策略在最小化环境动态变化的情况下成功进行策略中毒。双层马尔可夫过程表示如下:
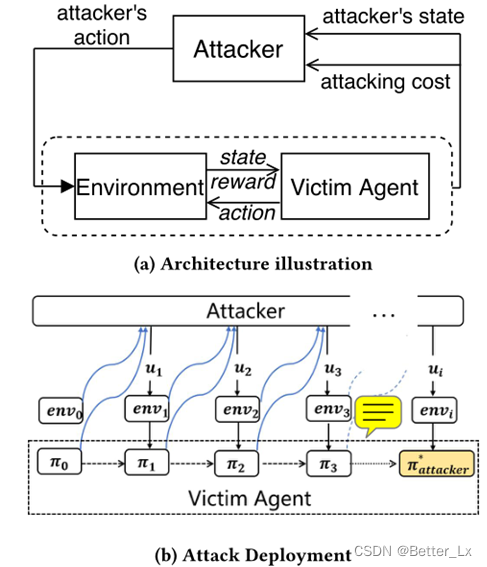
受害者的MDP组成:状态空间、初始状态分布、动作空间、折扣因子、奖励、环境参数影响下状态转移概率(Tu)
攻击者的MDP组成:攻击者的状态空间(受害者的策略参数集)、攻击者目标策略参数、行动空间(对受害者环境参数的调整)、环境转移概率函数、攻击成本函数。目标是最小化成本函数。
目标策略: s属于目标状态集(即目标参数集)时执行动作a’(进行环境参数调整),否则根据当前受害者策略执行相应动作。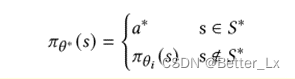
2.算法流程
 实验中的U是对环境中方块高度进行改变
实验中的U是对环境中方块高度进行改变
(感觉实验中直接对U进行改变有些简单,在复杂环境下这个环境参数应该如何选取?)
3.问题
(1).攻击者如何调整环境参数?环境参数是如何影响受害者的?
在每个攻击epoch中攻击者的环境转移参数固定的,第i个epoch为T(u1:i),受害者在给定的最大时间步与环境交互进行策略更新。攻击者识别到受害者的策略更新之后相应地调整环境超参数作为新的状态,并发起下一次攻击。可以理解为迭代更新。
(2).成本函数是怎么设置的?(创新点)
成本函数类似于奖励函数,每一个动作对应一个成本,该模型中成本要通过环境与受害者的整体交互来获取,创新性地引入散度率KLR来刻画受害者当前策略的状态动作转移概率与攻击者理想策略的状态动作转移概率的差异,这两者之间的差异越小越好,因此成本函数的优化朝着最小化方向进行。
(3).黑盒攻击中怎么实现双层闭环马尔可夫?
分为两种情况分别进行研究。
1)攻击者不知道智能体如何学习策略,但知道其策略模型,即瞬时策略
攻击者的挑战:在没有受害者学习算法信息的情况下设计攻击策略
解决方案:利用环境攻击的可转移性。攻击者在白盒智能体上学习其攻击策略(即攻击者知道学习算法),然后将该策略转移到攻击黑盒受害者智能体。
2)不知道学习算法和策略,只能观察智能体的行为轨迹
利用编码-解码器重构受害者策略网络,需收集受害者连续的状态动作对,从而推断受害者策略,编码器网络的输出代表受害者的策略功能,可用作攻击者的输入。
(4).攻击实施阶段是怎样的?
攻击策略训练好之后可以看作一个智能体,在给定状态环境下能产生一个输出,攻击是在整个训练阶段进行的。
4.总结
攻击者通过操纵受害者代理的环境动态,对其学习体验施加影响。攻击者的目标是秘密地迫使智能体学习目标策略,同时最小化环境变化。















 2024
2024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









