







原视频连接:https://www.bilibili.com/video/av39137333?p=18
sklearn.datasets.load_数据集名() 获取数据集
sklearn.datasets.fetch_数据集名() 获取大规模数据集

数据集的划分

x_train = 训练集的特征值 x_test = 测试集的特征值
y_train = 训练集的目标值 y_test = 测试集的目标值
特征工程处理流程:
原始数据–>数据处理–> 特征提取 --> 特征选择和特征降维 -->模型构建
1、特征抽取/特征提取
3类特征提取方式:
1.数值类型 -->直接使用
2.时间序列 --> 转成单独 年、月、日
3.分类数据 --> 用数值代替类别(One-hot编码)
2、特征预处理 把特征数据转换成更适合处理的形式
对分类型变量进行编码处理:
https://www.cnblogs.com/wyy1480/p/10295084.html
无量纲化:
1.归一化:
特征的单位不同,不同的数量级,把原始数据的值映射到默认[0,1]之间
缺点:受到异常值影响较大,因为是根据最大最小值得出,属于鲁棒性(稳定性)较差,适应于小数据情景。


import pandas as pd
from sklearn.preprocessing import MinMaxScaler
def minmax_demo():
"""
归一化
"""
data = pd.read_csv('dating.txt')
data = data.iloc[:,0:3]
print(data)
transfer = MinMaxScaler(feature_range=[2,3])
data_new = transfer.fit_transform(data)
print(data_new)
minmax_demo()
2.标准化
将原始数据变换到均值为0,标准差为1的范围内
标准化受异常点影响程度不大



已有足够多样本的情况下比较稳定,适合嘈杂的大数据情景
def stand_demo():
"""
标准化
"""
data = pd.read_csv('dating.txt')
data = data.iloc[:, 0:3]
print(data)
transfer = StandardScaler()
data_new = transfer.fit_transform(data)
print(data_new)
stand_demo()
3、特征降维
降低特征的个数(随机变量的个数)
效果:特征与特征间不相关,不重复

降
1.特征选择(去除冗余特征)
——Filter过滤式
————方差选择法:方差小,说明比较集中,要去除

def variance_domo():
"""
过滤方差
"""
data = pd.read_csv('dating.txt')
data = data.iloc[:, 1:-2]
print(data)
transfer = VarianceThreshold()
data_new = transfer.fit_transform(data)
print(data_new)
variance_domo()
————相关系数法:相关系数大,相关性强,要去除
相关系数–皮尔逊相关系数
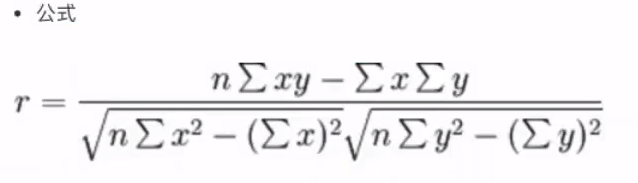

API:

from scipy.stats import pearsonr
r = pearsonr(data[''],data[''])
——Embedded嵌入式
————决策树
————正则化
————深度学习
2.主成分分析
PCA降维,将高维数据变为低维数据,尽可能的维数压缩,损失少量信息
API:
def PCA_demo():
"""
PCA降维
"""
data = [[2,8,4,5],[6,3,0,8],[5,4,9,1]]
transfer = PCA(n_components=0.9)
data_new = transfer.fit_transform(data)
print(data_new)















 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









