







目录
一、简介
Spark 是一个快速(基于内存), 通用, 可扩展的集群计算引擎
并且 Spark 目前已经成为 Apache 最活跃的开源项目, 有超过 1000 个活跃的贡献者.
- Spark 是为了解决 MapReduce 等过去的计算系统无法在内存中保存中间结果的问题
- Spark 的核心是 RDDs, RDDs 不仅是一种计算框架, 也是一种数据结构
历史
-
2009 年,Spark 诞生于 UC Berkeley(加州大学伯克利分校, CAL) 的 AMP 实验室, 项目采用 Scala 编程语言编写.
-
2010 年, Spark 正式对外开源
-
2013 年 6 月, 进入 Apache 孵化器
-
2014 年, 成为 Apache 的顶级项目.
-
Spark 2.4.5发布 (2020年2月8日)
参考: http://spark.apache.org/history.html
二、特点
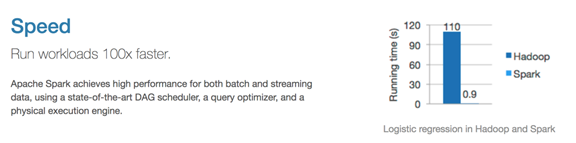
速度快
-
Spark 的在内存时的运行速度是 Hadoop MapReduce 的100倍
-
基于硬盘的运算速度大概是 Hadoop MapReduce 的10倍
-
Spark 实现了一种叫做 RDDs 的 DAG 执行引擎, 其数据缓存在内存中可以进行迭代处理
易用
df = spark.read.json("logs.json")
df.where("age > 21")
.select("name.first")
.show()
- Spark 支持 Java, Scala, Python, R, SQL 等多种语言的API.
- Spark 支持超过80个高级运算符使得用户非常轻易的构建并行计算程序
- Spark 可以使用基于 Scala, Python, R, SQL的 Shell 交互式查询.
通用
-
Spark 结合了SQL, Streaming和复杂分析.
-
Spark 提供了大量的类库, 包括 SQL 和 DataFrames, 机器学习(MLlib), 图计算(GraphicX), 实时流处理(Spark Streaming) .
-
可以把这些类库无缝的柔和在一个 App 中.
减少了开发和维护的人力成本以及部署平台的物力成本.

兼容
- Spark 可以运行在 Hadoop Yarn, Apache Mesos, Kubernets, Spark Standalone等集群中
- Spark 可以访问 HBase, HDFS, Hive, Cassandra 在内的多种数据库

三、Spark组件

Spark-Core 和 弹性分布式数据集(RDDs)
- Spark-Core 是整个 Spark 的基础, 提供了分布式任务调度和基本的 I/O 功能
- Spark 的基础的程序抽象是弹性分布式数据集(RDDs), 是一个可以并行操作, 有容错的数据集合
- RDDs 可以通过引用外部存储系统的数据集创建(如HDFS, HBase), 或者通过现有的 RDDs 转换得到
- RDDs 抽象提供了 Java, Scala, Python 等语言的API
- RDDs 简化了编程复杂性, 操作 RDDs 类似通过 Scala 或者 Java8 的 Streaming 操作本地数据集合
Spark SQL
- Spark SQL 在
spark-core基础之上带出了一个名为 DataSet 和 DataFrame 的数据抽象化的概念 - Spark SQL 提供了在 Dataset 和 DataFrame 之上执行 SQL 的能力
- Spark SQL 提供了 DSL, 可以通过 Scala, Java, Python 等语言操作 DataSet 和 DataFrame
- 它还支持使用 JDBC/ODBC 服务器操作 SQL 语言
Spark Streaming
- Spark Streaming 充分利用
spark-core的快速调度能力来运行流分析 - 它截取小批量的数据并可以对之运行 RDD Transformation
- 它提供了在同一个程序中同时使用流分析和批量分析的能力
MLlib
- MLlib 是 Spark 上分布式机器学习的框架. Spark分布式内存的架构 比 Hadoop磁盘式 的 Apache Mahout 快上 10 倍, 扩展性也非常优良
- MLlib 可以使用许多常见的机器学习和统计算法, 简化大规模机器学习
- 汇总统计, 相关性, 分层抽样, 假设检定, 随即数据生成
- 支持向量机, 回归, 线性回归, 逻辑回归, 决策树, 朴素贝叶斯
- 协同过滤, ALS
- K-means
- SVD奇异值分解, PCA主成分分析
- TF-IDF, Word2Vec, StandardScaler
- SGD随机梯度下降, L-BFGS
GraphX
GraphX 是分布式图计算框架, 提供了一组可以表达图计算的 API, GraphX 还对这种抽象化提供了优化运行
四、Spark和Hadoop的异同
| Hadoop | Spark | |
|---|---|---|
| 类型 | 基础平台, 包含计算, 存储, 调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算, 交互式计算, 流计算 |
| 延迟 | 大 | 小 |
| 易用性 | API 较为底层, 算法适应性差 | API 较为顶层, 方便使用 |
| 价格 | 对机器要求低, 便宜 | 对内存有要求, 相对较贵 |
五、Spark开发语言对比
 现在我们对每个语言的优缺点进行详细的分析:
现在我们对每个语言的优缺点进行详细的分析:
-
Scala 作为 Spark 的开发语言当然得到了原生支持,也非常成熟,它简洁的语法也能显著提高开发效率;
-
Java 也是 Spark 原生支持的开发语言,但是 Java 语法冗长且不支持函数式编程(1.8 以后支持),导致它的 API 设计得冗余且不合理,再加上需要编译执行,Java 开发效率无疑是最低的,但 Java 程序员基数特别大,Java API 对于这些用户来说无疑很友好;
-
Python 与 R 语言都是解释型脚本语言,不用编译直接运行,尤其是 Python 更以简洁著称,开发效率自不必说,此外 Python 与 R 语言本身也支持函数式编程,这两种语言在开发 Spark 作业时也是非常自然,但由于其执行原理是计算任务在每个节点安装的 Python 或 R 的环境中执行,结果通过管道输出给 Spark执行者,所以效率要比 Scala 与 Java 低;
-
SQL 是 Spark 原生支持的开发语言,从各个维度上来说都是最优的,所以一般情况下,用 Spark SQL 解决问题是最优选择。
如果你才刚开始学习 Spark,那么一开始最好选择一门自己最熟悉的语言,这样 Spark 的学习曲线会比较平缓。如果从零开始,建议在 Scala 与 Python 中间选择,Scala 作为 Spark 的原生开发语言,如果想要深入了解 Spark 有必要掌握。














 2102
2102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









