







1.iForest(独立森林)算法
样本数据过大时推荐采用这种异常值检测方法
原理分析:iForest森林也由大量的树组成。iForest中的树叫isolation tree,简称iTree。iTree树和决策树不太一样,其构建过程也比决策树简单,因为其中就是一个完全随机的过程。具体实施过程如下:
第一、假设共有N条数据,构建一颗iTree时,从N条数据中均匀抽样(一般是无放回抽样)出ψ个样本出来,作为这颗树的训练样本。在样本中,随机选一个特征,并在这个特征的所有值范围内(最小值与最大值之间)随机选一个值,对样本进行二叉划分,将样本中小于该值的划分到节点的左边,大于等于该值的划分到节点的右边。这样得到了一个分裂条件和左、右两边的数据集,然后分别在左右两边的数据集上重复上面的过程,直接达到终止条件。终止条件有两个,一个是数据本身不可再分(只包括一个样本,或者全部样本相同),另外一个是树的高度达到log2(ψ)。不同于决策树,iTree在算法里面已经限制了树的高度。当然不限制也可以,只是算法为了效率考虑,只需要达到log2(ψ)深度即可。
第二、把所有的iTree树构建好了,就可以对测试数据进行预测了。预测的过程就是把测试数据在iTree树上沿对应的条件分支往下走,直到达到叶子节点,并记录这过程中经过的路径长度h(x),即从根节点,穿过中间的节点,最后到达叶子节点,所走过的边的数量(path length)。最后,将h(x)带入,计算每条待测数据的异常分数(Anomaly Score)如果分数越接近1,其是异常点的可能性越高;如果分数都比0.5要小,那么基本可以确定为正常数据;如果所有分数都在0.5附近,那么数据不包含明显的异常样本。
具体流程如下:
算法本身并不复杂,主要包括第一步训练构建随机森林对应的多颗决策树,这些决策树一般叫iTree,第二步计算需要检测的数据点x最终落在任意第t颗iTree的层数ht(x)。然后我们可以得出x在每棵树的高度平均值h(x)。第三步根据h(x)判断x是否是异常点。
对于第一步构建决策树的过程,方法和普通的随机森林不同。
首先采样决策树的训练样本时,普通的随机森林要采样的样本个数等于训练集个数。但是iForest不需要采样这么多,一般来说,采样个数要远远小于训练集个数。原因是我们的目的是异常点检测,只需要部分的样本我们一般就可以将异常点区别出来了。
另外就是在做决策树分裂决策时,由于我们没有标记输出,所以没法计算基尼系数或者和方差之类的划分标准。这里我们使用的是随机选择划分特征,然后在基于这个特征再随机选择划分阈值,进行决策树的分裂。直到树的深度达到限定阈值或者样本数只剩一个。
第二步计算要检测的样本点在每棵树的高度平均值h(x)
首先需要遍历每一颗iTree,得到检测的数据点x最终落在任意第t颗iTree的数层数ht(x)。这个ht(x)代表的是树的深度,也就是离根节点越近,则ht(x)越小,越靠近底层,则ht(x)越大,根节点的高度为0.
第三步是据h(x)判断x是否是异常点。我们一般用下面的公式计算x的异常概率分值:
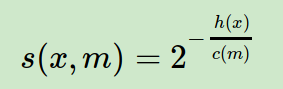
s(x,m)的取值范围是[0,1],取值越接近于1,则是异常点的概率也越大。其中m为样本个数。c(m)的表达式为:
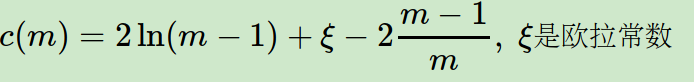
从s(x,m)表示式可以看出,如果高度h(x)→0, 则s(x,m)→1,即是异常点的概率是100%,如果高度h(x)→m−1, 则s(x,m)→0,即不可能是异常点。如果高度h(x)→c(m), 则s(x,m)→0.5,即是异常点的概率是50%,一般我们可以设置$s(x,m)的一个阈值然后去调参,这样大于阈值的才认为是异常点。
在sklearn中,我们可以用ensemble包里面的IsolationForest来做异常点检测。
在sklearn中的使用:
算法基本上不需要配置参数就可以直接使用,通常就以下几个(参数明显比随机森林简单):
n_estimators: 默认为100,配置iTree树的多少
max_samples: 默认为265,配置采样大小
max_features: 默认为全部特征,对高维数据,可以只选取部分特征
from sklearn.ensemble import IsolationForest
ilf=IsolationForest()
ilf.fit(X)
s=ilf.predict(X)
返回的是只包含-1和1元素的数组,-1代表可能为异常值的点
2.异常点检测常用算法OneClassSVM
在样本数据较少时建议采用这种异常值检测方法
它是无监督学习的方法,这里只讲解一种特别的思路SVDD, 对于SVDD来说,我们期望所有不是异常的样本都是正类别,同时它采用一个超球体而不是一个超平面来做划分,该算法在特征空间中获得数据周围的球形边界,期望最小化这个超球体的体积,从而最小化异常点数据的影响。可以判断新的数据点z是否在类内,如果z到中心的距离小于或者等于半径r,则不是异常点,如果在超球体以外,则是异常点。在sklearn中的用法
from sklearn.svm import OneClassSVM
classer=OneClassSVM()
classer.fit(X)
yHat=classer.predict(X)
print(yHat)
注意:由于其是非监督学习方法,所以不用传入类别列表。返回数据和iForest一样是只包含1,-1的列表,-1代表可能是异常点,X是训练样本。检测完后的数据筛选















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









