







HEVC中在进行运动补偿时只考虑了平移运动,。而在现实世界中,有很多种运动,如放大/缩小、旋转、透视运动和其他不规则运动。在VVC中,采用了基于块的仿射变换运动补偿预测。如下图所示,块的仿射运动场由两个控制点(4参数)或三个控制点运动矢量(6参数)的运动信息来描述。

基于块的仿射运动补偿方式如下:
- 1.首先将块划分为4x4的亮度子块。
- 2.对每个亮度子块按下式由仿射向量计算其中心像素的运动向量,然后四舍五入到1/16精度。
对于4参数仿射运动模型,中心像素(x,y)处的运动矢量推导为:
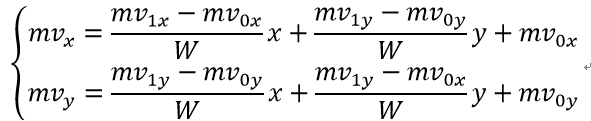
对于6参数仿射运动模型,中心像素(x,y)处的运动矢量导出为:
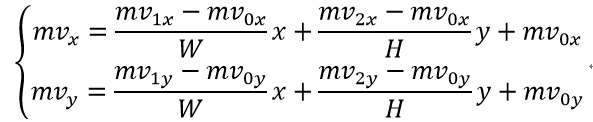
其中(mv0x,mv0y)是左上角控制点的运动矢量,(mv1x,mv1y)是右上角控制点的运动矢量,(mv2x,mv2y)是左下角控制点的运动矢量。
- 3.每个子块计算出运动向量后(如下图),根据运动向量进行运动补偿插值滤波得到每个子块的预测值。
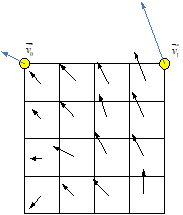
色度分量也划分为4x4的子块。 将4×4色度子块的MV计算为其相应的8x8亮度区域中左上和右下亮度子块的MV的平均值。
和对传统帧间预测所做的那样,有两种仿射运动帧间预测模式:Affine Merge模式和Affine AMVP模式。
Affine Merge预测
对于宽度和高度都大于或等于8的CUs,可以采用AF_MERGE模式。在AF_MERGE下,当前CU的CPMV(CPMV, control point motion vector)是基于空间相邻CU的运动信息生成的。最多可以有五个CPMVP候选,并用一个索引指示当前CU使用的索引。以下三种类型的CPVM候选者用于形成Affine Merge候选列表:
- 继承Affine Merge候选项:继承其相邻CU的CPMV候选项
- 构造Affine Merge候选项:使用相邻CU的平移运动的MVs构造CPMVPs候选项
- 零MVs
(1)继承Affine Merge候选项
在VVC中,最多有两个类型1的CPMV候选项加入候选列表,从左相邻CU最多继承1个,从上相邻CU最多继承1个。 候选块如下图所示。对于左相邻CU,扫描顺序为A0-> A1,而对于上相邻CU,扫描顺序为B0-> B1-> B2。 对于每一侧按照扫描顺序仅选择第一个有效的CU。 在两个继承的候选项之间不执行修剪prune检查。

当某一相邻CU被选定时,其控制点运动矢量被生成当前CU的仿射Merge列表中的CPMVP候选项。如下图所示,如果以左下A块为例,则获得包含块A的CU的左上角,右上角和左下角的运动矢量v2 , v3 和 v4。 当块A是4参数仿射模型时,将根据v2和v3计算当前CU的两个CPMV。 当块A是6参数仿射模型时,根据v2 , v3 和 v4计算当前CU的三个CPMV。

(2)构造Affine Merge候选项
对于类型2构造Affine候选,是指通过组合每个控制点的相邻平移运动信息来构造候选项。 控制点的运动信息是从下图中所示的指定空域相邻和时域相邻中获得的。CPMVk(k = 1、2、3、4)表示第k个控制点。 对于CPMV1,检查B2-> B3-> A2块,并使用第一个可用块的MV;对于CPMV2,检查B1-> B0块,使用第一个可用块的MV;对于CPMV3,检查A1-> A0块,使用第一个可用块的MV。 对于CPMV4,如果TMVP可用,则将它用作CPMV4。

在获得四个控制点的MV之后,基于这些运动信息构造Affine Merge候选项。
按以下CPMV的组合顺序构造Affine Merge候选项:
{CPMV1, CPMV2, CPMV3}, {CPMV1, CPMV2, CPMV4}, {CPMV1, CPMV3, CPMV4},
{CPMV2, CPMV3, CPMV4}, { CPMV1, CPMV2}, { CPMV1, CPMV3}
3个CPMV的组合构成一个6参数的Affine Merge候选项,而2个CPMV的组合构成4个参数的Affine Merge候选项。 为了避免运动缩放过程,如果控制点的参考帧索引不同,则丢弃CPMV的相关组合。
(3)零MV
在继承Affine Merge候选项和构造Affine Merge候选项之后,如果列表仍未满,则将零MV填充。
Affine AMVP预测
Affine AMVP模式可应用于宽度和高度均大于或等于16的CU。在比特流中发信号通知CU级别的Affine标志以指示是否使用Affine AMVP模式,然后发信号通知另一个标志以指示是4参数Affine或6参数Affine模型。
在Affine AMVP模式下,需要传输其预测CPMV在候选列表中的索引以及它和运动搜索得到的实际CPMV的残差。Affine AVMP候选列表大小为2,它是通过依次使用以下5种CPMV候选类型生成的:
- 继承AMVP候选项:继承其相邻CU的CPMV候选项
- 构造Affine AMVP候选项:使用相邻CU的平移运动的MVs构造CPMVPs候选项
- 直接使用相邻CU的平移MV
- 同位块的时域MV
- 零MV
对于继承AMVP候选项,其构建方法与Affine Merge继承AMVP候选项相同。 唯一的区别是,对于AVMP候选项,相邻CU的参考帧必须和当前帧一样。 将继承的AMVP候选项插入候选列表时,不应用修剪过程。
构造Affine候选项的产生和Affine Merge构造方法一样。 并且需要检查相邻块的参考图片索引,要选择扫描顺序中第一个帧间编码且和当前CU有相同参考图像的块。 当当前CU用4参数Affine模式编码时,mv0和mv1都可用时,才把它们加入Affine AMVP候选列表。 当当前CU用6参数Affine模式编码时,并且所有三个CPMV均可用时,才把它们加入Affine AMVP候选列表。 否则,将构造的AMVP候选项设置为不可用。
如果在插入类型1和类型2的AMVP候选项之后,Affine AMVP列表候选项仍小于2,则将按顺序将平移运动MV mv0, mv1 和 mv2 (第i个MV存在时,i=0,1,2)作为当前CU所有控制点的MV。
如果Affine AMVP列表仍小于2且开启时域MV预测,则使用同位块的时域MV作为当前所有控制点的MV。其时域MV的获取和常规Merge模式一致。
最后,如果Affine AMVP列表仍未满,则将使用零MV来填充Affine AMVP列表。
Affine motion information storage
在VVC中,Affine CU的CPMV存储在单独的缓冲区中。 存储的CPMV仅用于为最近编码的CU以Affine Merge模式和Affine AMVP模式生成继承的CPMVP候选项。 从CPMV派生的子块MV用于运动补偿,Merge /AMVP列表MV的推导以及去块。
为了避免用于额外CPMV的图片行缓冲区,对来自上方相邻CTU中的CU的Affine运动数据继承的处理与来自正常相邻CU的继承的处理不同。 如果用于Affine运动数据继承的候选CU在上相邻CTU的行中,则将行缓冲区中的左下和右下子块MV(而不是CPMV)用于Affine MVP推导。 这样,CPMV仅存储在本地缓冲区中。 如果候选CU是6参数Affine模型的,则Affine模型降为4参数模型。 如下图所示,在上方CTU边界,CU的左下和右下子块运动矢量用于下方CTU中的CU的 Affine继承。

Prediction refinement with optical flow for affine mode
与基于像素的Affine运动补偿相比,基于子块的Affine运动补偿可以节省内存并降低计算复杂度,但会降低预测精度。 为了获得更好的运动补偿精度,使用具有光流的预测细化(PROF)来细化基于子块的Affine运动补偿预测,而无需增加用于运动补偿的内存。 在VVC中,在基于子块的Affine运动补偿之后,通过添加由光流方程推导出的差来细化亮度预测样本。 PROF被描述为以下四个步骤:
(1)执行基于子块的仿射运动补偿以生成子块预测
(2)在每个像素位置使用3抽头滤波器[-1,0,1]计算子块预测的空间梯度和
。 梯度计算与BDOF中的梯度计算完全相同。
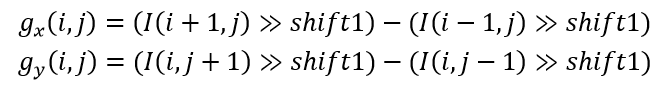
shift1用于控制梯度的精度。 子块(即4x4块)预测在每侧扩展一个像素以进行梯度计算。 为避免额外的内存和额外的插值计算,边界上的扩展像素是从参考帧中最接近的整数像素位置复制的。
(3)通过以下光流方程计算亮度预测细化

其中是像素位置(i,j)计算的像素级MV(以
表示)与像素(i,j)所属的子块的子块MV(以
表示)之差, 如下图所示。
以1/32亮度采样精度为单位进行量化。

由于Affine模型参数和相对于子块中心的像素位置在子块之间没有变化,因此可以为第一个子块计算出,并将其重用于同一CU中的其他子块。
假设和
是从像素位置(i,j)到子块中心
的水平和垂直偏移,则通过以下等式可以得出
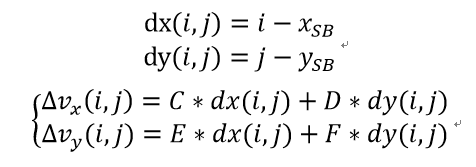
为了保持准确性,子块的输入计算为( ( WSB − 1 )/2, ( HSB − 1 ) / 2 ),其中WSB 和 HSB分别是子块宽度和高度。
对于四参数Affine模型

对于六参数Affine模型
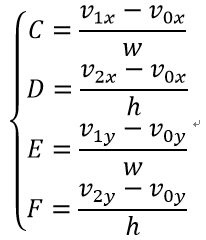
其中(v0x,v0y), (v1x,v1y), (v2x,v2y)是左上,右上和左下控制点运动矢量,w和h是CU的宽度和高度。
(4)最后,将亮度预测细化添加到子块预测
。 最终预测I'由以下等式生成
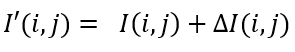
对于Affine编码的CU,在两种情况下不应用PROF:1)所有控制点MV都相同,这表明CU仅具有平移运动; 2)Affine运动参数大于指定的限制,因为基于子块的Affine MC降级为基于CU的MC,以避免对大内存访问带宽的需求。
在编码端应用快速算法来减少使用PROF进行Affine运动估计的编码复杂度。 在以下两种情况下,Affine运动估计阶段不应用PROF:
a)如果此CU不是根块,并且其父块未选择Affine模式作为其最佳模式,则不应用PROF,因为当前CU选择Affine模式为最佳模式的可能性较低;
b)如果四个仿射参数(C,D,E,F)的大小均小于预定义的阈值,并且当前图片不是低延迟图片,则不应用PROF,因为在这种情况下PROF的提升很小。 这样,可以加速使用PROF的Affine运动估计。
相关代码
Affine Merge候选列表构建的代码:(基于VTM10.0)
void PU::getAffineMergeCand( const PredictionUnit &pu, AffineMergeCtx& affMrgCtx, const int mrgCandIdx )
{
const CodingStructure &cs = *pu.cs;
const Slice &slice = *pu.cs->slice;
const uint32_t maxNumAffineMergeCand = slice.getPicHeader()->getMaxNumAffineMergeCand();//最大子块Merge候选数
const unsigned plevel = pu.cs->sps->getLog2ParallelMergeLevelMinus2() + 2;
//初始化Affine Merge候选列表
for ( int i = 0; i < maxNumAffineMergeCand; i++ )
{
for ( int mvNum = 0; mvNum < 3; mvNum++ )
{
affMrgCtx.mvFieldNeighbours[(i << 1) + 0][mvNum].setMvField( Mv(), -1 );
affMrgCtx.mvFieldNeighbours[(i << 1) + 1][mvNum].setMvField( Mv(), -1 );
}
affMrgCtx.interDirNeighbours[i] = 0;
affMrgCtx.affineType[i] = AFFINEMODEL_4PARAM;
affMrgCtx.mergeType[i] = MRG_TYPE_DEFAULT_N;
affMrgCtx.BcwIdx[i] = BCW_DEFAULT;
}
affMrgCtx.numValidMergeCand = 0;
affMrgCtx.maxNumMergeCand = maxNumAffineMergeCand;
bool sbTmvpEnableFlag = slice.getSPS()->getSbTMVPEnabledFlag()
&& !(slice.getPOC() == slice.getRefPic(REF_PIC_LIST_0, 0)->getPOC() && slice.isIRAP());
bool isAvailableSubPu = false;
if (sbTmvpEnableFlag && slice.getPicHeader()->getEnableTMVPFlag())
{
MergeCtx mrgCtx = *affMrgCtx.mrgCtx;
bool tmpLICFlag = false;
CHECK( mrgCtx.subPuMvpMiBuf.area() == 0 || !mrgCtx.subPuMvpMiBuf.buf, "Buffer not initialized" );
mrgCtx.subPuMvpMiBuf.fill( MotionInfo() );
int pos = 0;
// Get spatial MV
const Position posCurLB = pu.Y().bottomLeft();
MotionInfo miLeft;
//left
const PredictionUnit* puLeft = cs.getPURestricted( posCurLB.offset( -1, 0 ), pu, pu.chType );
const bool isAvailableA1 = puLeft && isDiffMER(pu.lumaPos(), posCurLB.offset(-1, 0), plevel) && pu.cu != puLeft->cu && CU::isInter( *puLeft->cu );
if ( isAvailableA1 )
{
miLeft = puLeft->getMotionInfo( posCurLB.offset( -1, 0 ) );
// get Inter Dir
mrgCtx.interDirNeighbours[pos] = miLeft.interDir;
// get Mv from Left
mrgCtx.mvFieldNeighbours[pos << 1].setMvField( miLeft.mv[0], miLeft.refIdx[0] );
if ( slice.isInterB() )
{
mrgCtx.mvFieldNeighbours[(pos << 1) + 1].setMvField( miLeft.mv[1], miLeft.refIdx[1] );
}
pos++;
}
mrgCtx.numValidMergeCand = pos;
isAvailableSubPu = getInterMergeSubPuMvpCand(pu, mrgCtx, tmpLICFlag, pos, 0);
if ( isAvailableSubPu )
{
for ( int mvNum = 0; mvNum < 3; mvNum++ )
{
affMrgCtx.mvFieldNeighbours[(affMrgCtx.numValidMergeCand << 1) + 0][mvNum].setMvField( mrgCtx.mvFieldNeighbours[(pos << 1) + 0].mv, mrgCtx.mvFieldNeighbours[(pos << 1) + 0].refIdx );
affMrgCtx.mvFieldNeighbours[(affMrgCtx.numValidMergeCand << 1) + 1][mvNum].setMvField( mrgCtx.mvFieldNeighbours[(pos << 1) + 1].mv, mrgCtx.mvFieldNeighbours[(pos << 1) + 1].refIdx );
}
affMrgCtx.interDirNeighbours[affMrgCtx.numValidMergeCand] = mrgCtx.interDirNeighbours[pos];
affMrgCtx.affineType[affMrgCtx.numValidMergeCand] = AFFINE_MODEL_NUM;
affMrgCtx.mergeType[affMrgCtx.numValidMergeCand] = MRG_TYPE_SUBPU_ATMVP;
if ( affMrgCtx.numValidMergeCand == mrgCandIdx )
{
return;
}
affMrgCtx.numValidMergeCand++;
// early termination
if ( affMrgCtx.numValidMergeCand == maxNumAffineMergeCand )
{
return;
}
}
}
if ( slice.getSPS()->getUseAffine() )
{
///> Start: inherited affine candidates 开始:继承的仿射候选
const PredictionUnit* npu[5];
int numAffNeighLeft = getAvailableAffineNeighboursForLeftPredictor( pu, npu ); //获得当前PU左侧可用块数,包括A0 A1
int numAffNeigh = getAvailableAffineNeighboursForAbovePredictor( pu, npu, numAffNeighLeft );//获得当前PU上侧可用块数,包括B0 B1 B2
// 遍历空域相邻可用块
for ( int idx = 0; idx < numAffNeigh; idx++ )
{
// derive Mv from Neigh affine PU 继承其相邻CU的CPMV候选项
Mv cMv[2][3];
const PredictionUnit* puNeigh = npu[idx];///相邻PU
pu.cu->affineType = puNeigh->cu->affineType;
if ( puNeigh->interDir != 2 )
{
xInheritedAffineMv( pu, puNeigh, REF_PIC_LIST_0, cMv[0] ); //继承Affine MV
}
if ( slice.isInterB() )
{
if ( puNeigh->interDir != 1 )
{
xInheritedAffineMv( pu, puNeigh, REF_PIC_LIST_1, cMv[1] );
}
}
for ( int mvNum = 0; mvNum < 3; mvNum++ )
{
affMrgCtx.mvFieldNeighbours[(affMrgCtx.numValidMergeCand << 1) + 0][mvNum].setMvField( cMv[0][mvNum], puNeigh->refIdx[0] );
affMrgCtx.mvFieldNeighbours[(affMrgCtx.numValidMergeCand << 1) + 1][mvNum].setMvField( cMv[1][mvNum], puNeigh->refIdx[1] );
}
affMrgCtx.interDirNeighbours[affMrgCtx.numValidMergeCand] = puNeigh->interDir;
affMrgCtx.affineType[affMrgCtx.numValidMergeCand] = (EAffineModel)(puNeigh->cu->affineType);
affMrgCtx.BcwIdx[affMrgCtx.numValidMergeCand] = puNeigh->cu->BcwIdx;
if ( affMrgCtx.numValidMergeCand == mrgCandIdx )
{
return;
}
// early termination 提前终止
affMrgCtx.numValidMergeCand++;
if ( affMrgCtx.numValidMergeCand == maxNumAffineMergeCand )
{
return;
}
}
///> End: inherited affine candidates
///> Start: Constructed affine candidates 使用相邻CU的平移运动的MVs构造CPMVPs候选项
{
MotionInfo mi[4];
bool isAvailable[4] = { false };
int8_t neighBcw[2] = { BCW_DEFAULT, BCW_DEFAULT };
// control point: LT B2->B3->A2 CPMV1,检查B2->B3->A2块,使用第一个可用块的MV
const Position posLT[3] = { pu.Y().topLeft().offset( -1, -1 ), pu.Y().topLeft().offset( 0, -1 ), pu.Y().topLeft().offset( -1, 0 ) };
for ( int i = 0; i < 3; i++ )
{
const Position pos = posLT[i];
const PredictionUnit* puNeigh = cs.getPURestricted( pos, pu, pu.chType );
if (puNeigh && CU::isInter(*puNeigh->cu) && PU::isDiffMER(pu.lumaPos(), pos, plevel))
{
isAvailable[0] = true;
mi[0] = puNeigh->getMotionInfo( pos );
neighBcw[0] = puNeigh->cu->BcwIdx;
break;
}
}
// control point: RT B1->B0 CPMV2,检查B1->B0块
const Position posRT[2] = { pu.Y().topRight().offset( 0, -1 ), pu.Y().topRight().offset( 1, -1 ) };
for ( int i = 0; i < 2; i++ )
{
const Position pos = posRT[i];
const PredictionUnit* puNeigh = cs.getPURestricted( pos, pu, pu.chType );
if (puNeigh && CU::isInter(*puNeigh->cu) && PU::isDiffMER(pu.lumaPos(), pos, plevel))
{
isAvailable[1] = true;
mi[1] = puNeigh->getMotionInfo( pos );
neighBcw[1] = puNeigh->cu->BcwIdx;
break;
}
}
// control point: LB A1->A0 CPMV3,检查A1->A0块
const Position posLB[2] = { pu.Y().bottomLeft().offset( -1, 0 ), pu.Y().bottomLeft().offset( -1, 1 ) };
for ( int i = 0; i < 2; i++ )
{
const Position pos = posLB[i];
const PredictionUnit* puNeigh = cs.getPURestricted( pos, pu, pu.chType );
if (puNeigh && CU::isInter(*puNeigh->cu) && PU::isDiffMER(pu.lumaPos(), pos, plevel))
{
isAvailable[2] = true;
mi[2] = puNeigh->getMotionInfo( pos );
break;
}
}
// control point: RB CPMV4,如果TMVP可用
if ( slice.getPicHeader()->getEnableTMVPFlag() )
{
//>> MTK colocated-RightBottom
// offset the pos to be sure to "point" to the same position the uiAbsPartIdx would've pointed to
Position posRB = pu.Y().bottomRight().offset( -3, -3 );
const PreCalcValues& pcv = *cs.pcv;
Position posC0; //位置bottomRight().offset( 1, 1 );
bool C0Avail = false;
bool boundaryCond = ((posRB.x + pcv.minCUWidth) < pcv.lumaWidth) && ((posRB.y + pcv.minCUHeight) < pcv.lumaHeight);
const SubPic &curSubPic = pu.cs->slice->getPPS()->getSubPicFromPos(pu.lumaPos());
if (curSubPic.getTreatedAsPicFlag())
{
boundaryCond = ((posRB.x + pcv.minCUWidth) <= curSubPic.getSubPicRight() &&
(posRB.y + pcv.minCUHeight) <= curSubPic.getSubPicBottom());
}
if (boundaryCond)
{
int posYInCtu = posRB.y & pcv.maxCUHeightMask;
if (posYInCtu + 4 < pcv.maxCUHeight)
{
posC0 = posRB.offset(4, 4);
C0Avail = true;
}
}
Mv cColMv;
int refIdx = 0;
bool bExistMV = C0Avail && getColocatedMVP( pu, REF_PIC_LIST_0, posC0, cColMv, refIdx, false );
if ( bExistMV )
{
mi[3].mv[0] = cColMv;
mi[3].refIdx[0] = refIdx;
mi[3].interDir = 1;
isAvailable[3] = true;
}
if ( slice.isInterB() )
{
bExistMV = C0Avail && getColocatedMVP( pu, REF_PIC_LIST_1, posC0, cColMv, refIdx, false );
if ( bExistMV )
{
mi[3].mv[1] = cColMv;
mi[3].refIdx[1] = refIdx;
mi[3].interDir |= 2;
isAvailable[3] = true;
}
}
}
//------------------- insert model -------------------// //构造CPMV的组合
int order[6] = { 0, 1, 2, 3, 4, 5 };
int modelNum = 6;
int model[6][4] = {
{ 0, 1, 2 }, // 0: LT, RT, LB
{ 0, 1, 3 }, // 1: LT, RT, RB
{ 0, 2, 3 }, // 2: LT, LB, RB
{ 1, 2, 3 }, // 3: RT, LB, RB
{ 0, 1 }, // 4: LT, RT
{ 0, 2 }, // 5: LT, LB
};
int verNum[6] = { 3, 3, 3, 3, 2, 2 };
// 对于六参数模型,使用前四个3个的CPMV组合;对于四参数模型,使用后两个CPMV组合
int startIdx = pu.cs->sps->getUseAffineType() ? 0 : 4;
// 遍历相应的CPMV组合
for ( int idx = startIdx; idx < modelNum; idx++ )
{
int modelIdx = order[idx];
getAffineControlPointCand(pu, mi, isAvailable, model[modelIdx], ((modelIdx == 3) ? neighBcw[1] : neighBcw[0]), modelIdx, verNum[modelIdx], affMrgCtx);
if ( affMrgCtx.numValidMergeCand != 0 && affMrgCtx.numValidMergeCand - 1 == mrgCandIdx )
{
return;
}
// early termination 提前终止
if ( affMrgCtx.numValidMergeCand == maxNumAffineMergeCand )
{
return;
}
}
}
///> End: Constructed affine candidates
}
///> zero padding 填充零MV
int cnt = affMrgCtx.numValidMergeCand;
while ( cnt < maxNumAffineMergeCand )
{
for ( int mvNum = 0; mvNum < 3; mvNum++ )
{
affMrgCtx.mvFieldNeighbours[(cnt << 1) + 0][mvNum].setMvField( Mv( 0, 0 ), 0 );
}
affMrgCtx.interDirNeighbours[cnt] = 1;
if ( slice.isInterB() )
{
for ( int mvNum = 0; mvNum < 3; mvNum++ )
{
affMrgCtx.mvFieldNeighbours[(cnt << 1) + 1][mvNum].setMvField( Mv( 0, 0 ), 0 );
}
affMrgCtx.interDirNeighbours[cnt] = 3;
}
affMrgCtx.affineType[cnt] = AFFINEMODEL_4PARAM;
if ( cnt == mrgCandIdx )
{
return;
}
cnt++;
affMrgCtx.numValidMergeCand++;
}
}
其中xInheritedAffineMv函数作用是继承相邻块的CPMV
void PU::xInheritedAffineMv( const PredictionUnit &pu, const PredictionUnit* puNeighbour, RefPicList eRefPicList, Mv rcMv[3] )
{
int posNeiX = puNeighbour->Y().pos().x;
int posNeiY = puNeighbour->Y().pos().y;
int posCurX = pu.Y().pos().x;
int posCurY = pu.Y().pos().y;
int neiW = puNeighbour->Y().width;//相邻块的宽度
int curW = pu.Y().width;//当前块的宽度
int neiH = puNeighbour->Y().height;//相邻块的高度
int curH = pu.Y().height;//当前块的高度
Mv mvLT, mvRT, mvLB;
// 相邻块的Affine MV
mvLT = puNeighbour->mvAffi[eRefPicList][0];
mvRT = puNeighbour->mvAffi[eRefPicList][1];
mvLB = puNeighbour->mvAffi[eRefPicList][2];
bool isTopCtuBoundary = false;
// 是否是上方CTU的边界
if ( (posNeiY + neiH) % pu.cs->sps->getCTUSize() == 0 && (posNeiY + neiH) == posCurY )
{
// use bottom-left and bottom-right sub-block MVs for inheritance 使用左下角和右下角子块MVs进行继承
const Position posRB = puNeighbour->Y().bottomRight();
const Position posLB = puNeighbour->Y().bottomLeft();
mvLT = puNeighbour->getMotionInfo( posLB ).mv[eRefPicList];
mvRT = puNeighbour->getMotionInfo( posRB ).mv[eRefPicList];
posNeiY += neiH;
isTopCtuBoundary = true;
}
int shift = MAX_CU_DEPTH;
int iDMvHorX, iDMvHorY, iDMvVerX, iDMvVerY;
iDMvHorX = (mvRT - mvLT).getHor() << (shift - floorLog2(neiW));
iDMvHorY = (mvRT - mvLT).getVer() << (shift - floorLog2(neiW));
if ( puNeighbour->cu->affineType == AFFINEMODEL_6PARAM && !isTopCtuBoundary )
{
iDMvVerX = (mvLB - mvLT).getHor() << (shift - floorLog2(neiH));
iDMvVerY = (mvLB - mvLT).getVer() << (shift - floorLog2(neiH));
}
else
{
iDMvVerX = -iDMvHorY;
iDMvVerY = iDMvHorX;
}
int iMvScaleHor = mvLT.getHor() << shift;
int iMvScaleVer = mvLT.getVer() << shift;
int horTmp, verTmp;
// v0
horTmp = iMvScaleHor + iDMvHorX * (posCurX - posNeiX) + iDMvVerX * (posCurY - posNeiY);
verTmp = iMvScaleVer + iDMvHorY * (posCurX - posNeiX) + iDMvVerY * (posCurY - posNeiY);
roundAffineMv( horTmp, verTmp, shift );
rcMv[0].hor = horTmp;
rcMv[0].ver = verTmp;
rcMv[0].clipToStorageBitDepth();
// v1
horTmp = iMvScaleHor + iDMvHorX * (posCurX + curW - posNeiX) + iDMvVerX * (posCurY - posNeiY);
verTmp = iMvScaleVer + iDMvHorY * (posCurX + curW - posNeiX) + iDMvVerY * (posCurY - posNeiY);
roundAffineMv( horTmp, verTmp, shift );
rcMv[1].hor = horTmp;
rcMv[1].ver = verTmp;
rcMv[1].clipToStorageBitDepth();
// v2
if ( pu.cu->affineType == AFFINEMODEL_6PARAM )
{
horTmp = iMvScaleHor + iDMvHorX * (posCurX - posNeiX) + iDMvVerX * (posCurY + curH - posNeiY);
verTmp = iMvScaleVer + iDMvHorY * (posCurX - posNeiX) + iDMvVerY * (posCurY + curH - posNeiY);
roundAffineMv( horTmp, verTmp, shift );
rcMv[2].hor = horTmp;
rcMv[2].ver = verTmp;
rcMv[2].clipToStorageBitDepth();
}
}Affine AMVP候选列表构建的代码:(基于VTM10.0)
void PU::fillAffineMvpCand(PredictionUnit &pu, const RefPicList &eRefPicList, const int &refIdx, AffineAMVPInfo &affiAMVPInfo)
{
affiAMVPInfo.numCand = 0;
if (refIdx < 0)
{
return;
}
//=========================1. 继承其相邻CU的CPMV候选项===========================
// insert inherited affine candidates
Mv outputAffineMv[3];
Position posLT = pu.Y().topLeft(); //PU左上
Position posRT = pu.Y().topRight(); //PU右上
Position posLB = pu.Y().bottomLeft(); //PU左下
// check left neighbor 先检查左下相邻CU是否可用,如果可用,则继承左下相邻CU的CPMV候选项;否则,检查左侧相邻CU是否可用
if ( !addAffineMVPCandUnscaled( pu, eRefPicList, refIdx, posLB, MD_BELOW_LEFT, affiAMVPInfo ) )
{
addAffineMVPCandUnscaled( pu, eRefPicList, refIdx, posLB, MD_LEFT, affiAMVPInfo );
}
// check above neighbor 按顺序检查右上、上侧和左上相邻CU是否可用
if ( !addAffineMVPCandUnscaled( pu, eRefPicList, refIdx, posRT, MD_ABOVE_RIGHT, affiAMVPInfo ) )
{
if ( !addAffineMVPCandUnscaled( pu, eRefPicList, refIdx, posRT, MD_ABOVE, affiAMVPInfo ) )
{
addAffineMVPCandUnscaled( pu, eRefPicList, refIdx, posLT, MD_ABOVE_LEFT, affiAMVPInfo );
}
}
if ( affiAMVPInfo.numCand >= AMVP_MAX_NUM_CANDS ) //如果Affine AMVP候选列表长度大于等于2,则退出
{
for (int i = 0; i < affiAMVPInfo.numCand; i++)
{
affiAMVPInfo.mvCandLT[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
affiAMVPInfo.mvCandRT[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
affiAMVPInfo.mvCandLB[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
}
return;
}
//=========================2. 构造Affine AMVP候选项===========================
// insert constructed affine candidates
// 相邻CU的平移运动MV构建CPMV
int cornerMVPattern = 0;
//------------------- V0 (START) -------------------//
AMVPInfo amvpInfo0;
amvpInfo0.numCand = 0;
// A->C: Above Left, Above, Left 检查MV0
addMVPCandUnscaled( pu, eRefPicList, refIdx, posLT, MD_ABOVE_LEFT, amvpInfo0 );
if ( amvpInfo0.numCand < 1 )
{
addMVPCandUnscaled( pu, eRefPicList, refIdx, posLT, MD_ABOVE, amvpInfo0 );
}
if ( amvpInfo0.numCand < 1 )
{
addMVPCandUnscaled( pu, eRefPicList, refIdx, posLT, MD_LEFT, amvpInfo0 );
}
cornerMVPattern = cornerMVPattern | amvpInfo0.numCand;
//------------------- V1 (START) -------------------//
AMVPInfo amvpInfo1;
amvpInfo1.numCand = 0;
// D->E: Above, Above Right 检查MV1
addMVPCandUnscaled( pu, eRefPicList, refIdx, posRT, MD_ABOVE, amvpInfo1 );
if ( amvpInfo1.numCand < 1 )
{
addMVPCandUnscaled( pu, eRefPicList, refIdx, posRT, MD_ABOVE_RIGHT, amvpInfo1 );
}
cornerMVPattern = cornerMVPattern | (amvpInfo1.numCand << 1);
//------------------- V2 (START) -------------------//
AMVPInfo amvpInfo2;
amvpInfo2.numCand = 0;
// F->G: Left, Below Left 检查MV2
addMVPCandUnscaled( pu, eRefPicList, refIdx, posLB, MD_LEFT, amvpInfo2 );
if ( amvpInfo2.numCand < 1 )
{
addMVPCandUnscaled( pu, eRefPicList, refIdx, posLB, MD_BELOW_LEFT, amvpInfo2 );
}
cornerMVPattern = cornerMVPattern | (amvpInfo2.numCand << 2);
outputAffineMv[0] = amvpInfo0.mvCand[0];
outputAffineMv[1] = amvpInfo1.mvCand[0];
outputAffineMv[2] = amvpInfo2.mvCand[0];
outputAffineMv[0].roundAffinePrecInternal2Amvr(pu.cu->imv);
outputAffineMv[1].roundAffinePrecInternal2Amvr(pu.cu->imv);
outputAffineMv[2].roundAffinePrecInternal2Amvr(pu.cu->imv);
// 对于四参数Affine模型,MV0和MV1均可用时才加入候选列表;对于六参数模型,当三个CPMV均可用时,才加入候选列表
if ( cornerMVPattern == 7 || (cornerMVPattern == 3 && pu.cu->affineType == AFFINEMODEL_4PARAM) )
{
affiAMVPInfo.mvCandLT[affiAMVPInfo.numCand] = outputAffineMv[0];
affiAMVPInfo.mvCandRT[affiAMVPInfo.numCand] = outputAffineMv[1];
affiAMVPInfo.mvCandLB[affiAMVPInfo.numCand] = outputAffineMv[2];
affiAMVPInfo.numCand++;
}
if ( affiAMVPInfo.numCand < 2 ) //如果Affine AMVP候选项数目小于2
{
// check corner MVs 直接使用相邻块的MV
for ( int i = 2; i >= 0 && affiAMVPInfo.numCand < AMVP_MAX_NUM_CANDS; i-- )
{
if ( cornerMVPattern & (1 << i) ) // MV i exist 第i个MV存在时,将第i个MV作为左上、右上和左下三点的MV候选项
{
affiAMVPInfo.mvCandLT[affiAMVPInfo.numCand] = outputAffineMv[i];
affiAMVPInfo.mvCandRT[affiAMVPInfo.numCand] = outputAffineMv[i];
affiAMVPInfo.mvCandLB[affiAMVPInfo.numCand] = outputAffineMv[i];
affiAMVPInfo.numCand++;
}
}
// Get Temporal Motion Predictor 获得同位块的时域MV
if ( affiAMVPInfo.numCand < 2 && pu.cs->picHeader->getEnableTMVPFlag() )
{
const int refIdxCol = refIdx;
Position posRB = pu.Y().bottomRight().offset( -3, -3 );
const PreCalcValues& pcv = *pu.cs->pcv;
Position posC0;
bool C0Avail = false;
Position posC1 = pu.Y().center();
Mv cColMv;
bool boundaryCond = ((posRB.x + pcv.minCUWidth) < pcv.lumaWidth) && ((posRB.y + pcv.minCUHeight) < pcv.lumaHeight);
const SubPic &curSubPic = pu.cs->slice->getPPS()->getSubPicFromPos(pu.lumaPos());
if (curSubPic.getTreatedAsPicFlag())
{
boundaryCond = ((posRB.x + pcv.minCUWidth) <= curSubPic.getSubPicRight() &&
(posRB.y + pcv.minCUHeight) <= curSubPic.getSubPicBottom());
}
if (boundaryCond)
{
int posYInCtu = posRB.y & pcv.maxCUHeightMask;
if (posYInCtu + 4 < pcv.maxCUHeight)
{
posC0 = posRB.offset(4, 4);
C0Avail = true;
}
}
if ( ( C0Avail && getColocatedMVP( pu, eRefPicList, posC0, cColMv, refIdxCol, false ) ) || getColocatedMVP( pu, eRefPicList, posC1, cColMv, refIdxCol, false ) )
{
cColMv.roundAffinePrecInternal2Amvr(pu.cu->imv);
affiAMVPInfo.mvCandLT[affiAMVPInfo.numCand] = cColMv;
affiAMVPInfo.mvCandRT[affiAMVPInfo.numCand] = cColMv;
affiAMVPInfo.mvCandLB[affiAMVPInfo.numCand] = cColMv;
affiAMVPInfo.numCand++;
}
}
if ( affiAMVPInfo.numCand < 2 ) //如果候选列表仍小于2,添加零MV
{
// add zero MV
for ( int i = affiAMVPInfo.numCand; i < AMVP_MAX_NUM_CANDS; i++ )
{
affiAMVPInfo.mvCandLT[affiAMVPInfo.numCand].setZero();
affiAMVPInfo.mvCandRT[affiAMVPInfo.numCand].setZero();
affiAMVPInfo.mvCandLB[affiAMVPInfo.numCand].setZero();
affiAMVPInfo.numCand++;
}
}
}
for (int i = 0; i < affiAMVPInfo.numCand; i++)
{
affiAMVPInfo.mvCandLT[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
affiAMVPInfo.mvCandRT[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
affiAMVPInfo.mvCandLB[i].roundAffinePrecInternal2Amvr(pu.cu->imv);
}
}
addAffineMVPCandUnscaled函数是用来判断相邻块的CPMV是否可用,如果可用,则继承相邻PU的CPMV
bool PU::addAffineMVPCandUnscaled( const PredictionUnit &pu, const RefPicList &refPicList, const int &refIdx, const Position &pos, const MvpDir &dir, AffineAMVPInfo &affiAMVPInfo )
{
CodingStructure &cs = *pu.cs;
const PredictionUnit *neibPU = NULL;
Position neibPos; //相邻块位置
switch ( dir )
{
case MD_LEFT:
neibPos = pos.offset( -1, 0 );
break;
case MD_ABOVE:
neibPos = pos.offset( 0, -1 );
break;
case MD_ABOVE_RIGHT:
neibPos = pos.offset( 1, -1 );
break;
case MD_BELOW_LEFT:
neibPos = pos.offset( -1, 1 );
break;
case MD_ABOVE_LEFT:
neibPos = pos.offset( -1, -1 );
break;
default:
break;
}
neibPU = cs.getPURestricted( neibPos, pu, pu.chType );//相邻PU
// 相邻PU不存在或者相邻PU帧内编码或者相邻PU不是Affine模式,则表示相邻PU不可用,返回FALSE
if (neibPU == NULL || !CU::isInter(*neibPU->cu) || !neibPU->cu->affine || neibPU->mergeType != MRG_TYPE_DEFAULT_N)
{
return false;
}
Mv outputAffineMv[3];
const MotionInfo& neibMi = neibPU->getMotionInfo( neibPos );//相邻PU的运动信息
const int currRefPOC = cs.slice->getRefPic( refPicList, refIdx )->getPOC();//当前块的参考帧索引
const RefPicList refPicList2nd = (refPicList == REF_PIC_LIST_0) ? REF_PIC_LIST_1 : REF_PIC_LIST_0;
// 检查指示的参考图片列表,如果不可用,则检查其他列表。
for ( int predictorSource = 0; predictorSource < 2; predictorSource++ ) // examine the indicated reference picture list, then if not available, examine the other list.
{
const RefPicList eRefPicListIndex = (predictorSource == 0) ? refPicList : refPicList2nd;//参考帧列表索引
const int neibRefIdx = neibMi.refIdx[eRefPicListIndex];//相邻PU的参考帧索引
if ( ((neibPU->interDir & (eRefPicListIndex + 1)) == 0) || pu.cu->slice->getRefPOC( eRefPicListIndex, neibRefIdx ) != currRefPOC )
{
continue; //相邻CU和当前CU的参考帧不一样,则不可用
}
xInheritedAffineMv( pu, neibPU, eRefPicListIndex, outputAffineMv );//继承Affine MV
outputAffineMv[0].roundAffinePrecInternal2Amvr(pu.cu->imv);
outputAffineMv[1].roundAffinePrecInternal2Amvr(pu.cu->imv);
// 添加左上和右上的CPMV候选项
affiAMVPInfo.mvCandLT[affiAMVPInfo.numCand] = outputAffineMv[0];
affiAMVPInfo.mvCandRT[affiAMVPInfo.numCand] = outputAffineMv[1];
if ( pu.cu->affineType == AFFINEMODEL_6PARAM )
{ //对于六参数模型,还需添加左下的CPMV候选项
outputAffineMv[2].roundAffinePrecInternal2Amvr(pu.cu->imv);
affiAMVPInfo.mvCandLB[affiAMVPInfo.numCand] = outputAffineMv[2];
}
affiAMVPInfo.numCand++;
return true;
}
return false;
}















 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









