







Temporal difference learning,暂时翻译成时间差学习,是一种基于动态规划(DP)和蒙特卡罗方法(Monte Carlo method)的强化学习方法。
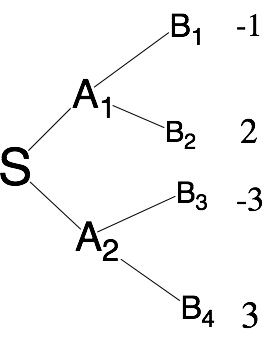
决策过程从S点出发,有一定概率到达A1或者A2,再次决策后才能获得收益。所以对于第一步决策,我们认为获得收益与这一步决策之间还隔了1次决策,因此我们规定这次决策的折扣速率(λ)为1。
- 在时间差学习中,决策被分为多步决策,但是收益过程是一次性的,所以前几步的决策的收益是未知的
因此需要发现状态转移方程以确定每一个状态的权值 - 比如说,根据样例模型,从S点开始决策,第一步可以转移到状态A1或者状态A2,但是此时收益是未知的,第二步可以从A1出发转移到B1或者B2,也可以从A2出发转移到B3或者B4
- B阶段的决策完成之后才能获得收益,但是在A阶段应该如何决策才能使得收益最优化呢?
运用动态规划的思想,根据后一步的收益来确定当前步的收益。将最终收益合理的分担给每一次决策。
为了方便,我们假装是等概率状态转移p(B1) = p(B2) = p(B3) = p(B4) = 1/2
- B1和B2的收益是已知的,我们可以设它们分别为 dp(B1) 、dp(B2),因此,我们可以得到A1的预期收益dp(A1) = dp(B1)*p(B1) + dp(B2)*p(B2)
- p(B1)是从A1出发进入B1的概率,p(B2)同理 同理可知,dp(A2)=dp(B3)*p(B3)+dp(B4)*p(B4)
- 可以得出dp(A1) = -1 * 0.5 + 1 * 0.5 = 0
同理可得dp(A2) = -2 * 0.5 + 4 * 0.5 = 1
这样我们就从局部最优解向前推进得到了大一点的局部最优解,最终得到了全局最优解。当然这只是最简化的不带概率的模型,真实的强化学习是涉及到概率的。
但是,如何得到最初的dp(B1) 、dp(B2)、dp(B3)、dp(B4)呢?
就需要用到蒙特卡罗模拟了
background:很久以前,有一个赌场在蒙特卡罗,然后赌场有许许多多的老虎机,赌徒需要花费最小的money找到老虎机的赔率。如果是为了寻找赔率,最暴力的方式是每台老虎机投币1000枚以找到每台老虎机的赔率,但是这样做花费的代价太高了。蒙特卡罗方法基于试验次数越大频率就越接近概率的原理,先对每台机器试探少数几次找出赔率最大的,再次试探赔率最大的,如果当前机器赔率下降就继续试探赔率最大的
ex:有一个不规则的平面S,要求他的面积。构造一大堆小球,随机撞击S,保证小球不会重叠,最后小球的个数就是S的面积,这也是蒙特卡罗方法
因此,用最少的试探次数确定某一最终状态收益的方法就是蒙特卡罗方法
参考
http://www.cnblogs.com/jerrylead/archive/2011/05/13/2045309.html
多机器人系统强化学习研究综述 马磊,张文旭,戴朝华















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









