






目录
一、sort的基本用法
1.头文件:#include < algorithm>
2.使用标准库:using namespace std
3.函数参数:
#include <algorithm>
template< class RandomIt > void sort( RandomIt first, RandomIt last );
template< class RandomIt, class Compare > void sort( RandomIt first, RandomIt last, Compare comp );first和last分别是数组的起始位置和终止位置。
cmp属于扩展用法:你可以传入一个返回值为bool类型的函数,如果结果为true那么比较的两个数就不交换否则交换位置。
实例:
#include < algorithm>
int main()
{
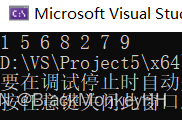
vector<int>vec = {5,1,6,8,2,7,9};
/* sort(vec.begin(), vec.end()); //基础用法
for (auto i : vec)
{
cout << i << " ";
}*/
sort(vec.begin(), vec.begin() + 3);
for (auto i : vec)
{
cout << i << " ";
}
}
扩展:
#include < algorithm>
bool decrease(int first, int second)
{
return first > second;
}
int main()
{
vector<int>vec = {5,1,6,8,2,7,9};
sort(vec.begin(), vec.end(),decrease);
for (auto i : vec)
{
cout << i << " ";
}
}

二、sort源码分析
2.1整体说明:
作者以前只知道使用,从没想过底层原理是什么,以前只认为sort底层就是快排,但是效率比自己写的要高,但实则不然。
首先找到sort:
template <class _RanIt, class _Pr>
_CONSTEXPR20 void sort(const _RanIt _First, const _RanIt _Last, _Pr _Pred) { // order [_First, _Last)
_Adl_verify_range(_First, _Last);
const auto _UFirst = _Get_unwrapped(_First);
const auto _ULast = _Get_unwrapped(_Last);
_Sort_unchecked(_UFirst, _ULast, _ULast - _UFirst, _Pass_fn(_Pred));
}
进入 _Sort_unchecked:
template <class _RanIt, class _Pr>
_CONSTEXPR20 void _Sort_unchecked(_RanIt _First, _RanIt _Last, _Iter_diff_t<_RanIt> _Ideal, _Pr _Pred) {
// order [_First, _Last)
for (;;) {
if (_Last - _First <= _ISORT_MAX) { // small
_Insertion_sort_unchecked(_First, _Last, _Pred);
return;
}
if (_Ideal <= 0) { // heap sort if too many divisions
_Make_heap_unchecked(_First, _Last, _Pred);
_Sort_heap_unchecked(_First, _Last, _Pred);
return;
}
// divide and conquer by quicksort
auto _Mid = _Partition_by_median_guess_unchecked(_First, _Last, _Pred);
_Ideal = (_Ideal >> 1) + (_Ideal >> 2); // allow 1.5 log2(N) divisions
if (_Mid.first - _First < _Last - _Mid.second) { // loop on second half
_Sort_unchecked(_First, _Mid.first, _Ideal, _Pred);
_First = _Mid.second;
} else { // loop on first half
_Sort_unchecked(_Mid.second, _Last, _Ideal, _Pred);
_Last = _Mid.first;
}
}
}
2.1.1分析:
首先可以看到,sort会先判断数组的长度是否够长(这里的_ISORT_MAX=32)
也就是说小于32直接调用插入排序(_Insertion_sort_unchecked)
然后看下面的_Ideal ,_Ideal = (_Ideal >> 1) + (_Ideal >> 2); // allow 1.5 log2(N) divisions
也就是说最多允许1.5 log2(N)的层次划分,所以快排层数如果超过了,也就是<=0的时候就会执行堆排序。
2.2快排基准值分析:
接着这个auto _Mid = _Partition_by_median_guess_unchecked(_First, _Last, _Pred);Pred是传入规则
快排需要选一个标杆,也就是基准值用于比较,这里并不是单纯的选择最左边的值或者最右边,因为那样选可能会造成On*n的情况,因此这里是一种优化选法;
template <class _RanIt, class _Pr>
_CONSTEXPR20 pair<_RanIt, _RanIt> _Partition_by_median_guess_unchecked(_RanIt _First, _RanIt _Last, _Pr _Pred) {
// partition [_First, _Last)
_RanIt _Mid = _First + ((_Last - _First) >> 1); // shift for codegen
_Guess_median_unchecked(_First, _Mid, _Prev_iter(_Last), _Pred);
_RanIt _Pfirst = _Mid;
_RanIt _Plast = _Next_iter(_Pfirst);
while (_First < _Pfirst && !_DEBUG_LT_PRED(_Pred, *_Prev_iter(_Pfirst), *_Pfirst)
&& !_Pred(*_Pfirst, *_Prev_iter(_Pfirst))) {
--_Pfirst;
}
while (_Plast < _Last && !_DEBUG_LT_PRED(_Pred, *_Plast, *_Pfirst) && !_Pred(*_Pfirst, *_Plast)) {
++_Plast;
}
_RanIt _Gfirst = _Plast;
_RanIt _Glast = _Pfirst;
for (;;) { // partition
for (; _Gfirst < _Last; ++_Gfirst) {
if (_DEBUG_LT_PRED(_Pred, *_Pfirst, *_Gfirst)) {
continue;
} else if (_Pred(*_Gfirst, *_Pfirst)) {
break;
} else if (_Plast != _Gfirst) {
_STD iter_swap(_Plast, _Gfirst);
++_Plast;
} else {
++_Plast;
}
}
for (; _First < _Glast; --_Glast) {
if (_DEBUG_LT_PRED(_Pred, *_Prev_iter(_Glast), *_Pfirst)) {
continue;
} else if (_Pred(*_Pfirst, *_Prev_iter(_Glast))) {
break;
} else if (--_Pfirst != _Prev_iter(_Glast)) {
_STD iter_swap(_Pfirst, _Prev_iter(_Glast));
}
}
if (_Glast == _First && _Gfirst == _Last) {
return pair<_RanIt, _RanIt>(_Pfirst, _Plast);
}
if (_Glast == _First) { // no room at bottom, rotate pivot upward
if (_Plast != _Gfirst) {
_STD iter_swap(_Pfirst, _Plast);
}
++_Plast;
_STD iter_swap(_Pfirst, _Gfirst);
++_Pfirst;
++_Gfirst;
} else if (_Gfirst == _Last) { // no room at top, rotate pivot downward
if (--_Glast != --_Pfirst) {
_STD iter_swap(_Glast, _Pfirst);
}
_STD iter_swap(_Pfirst, --_Plast);
} else {
_STD iter_swap(_Gfirst, --_Glast);
++_Gfirst;
}
}
}
这个Mid会返回两个值,[Mid.first,Midsecond]范围内是等于基准值的,具体选出基准值
2.3基准值选择的优化
在_Guess_median_unchecked(_First, _Mid, _Prev_iter(_Last), _Pred);这里
template <class _RanIt, class _Pr>
_CONSTEXPR20 void _Guess_median_unchecked(_RanIt _First, _RanIt _Mid, _RanIt _Last, _Pr _Pred) {
// sort median element to middle
using _Diff = _Iter_diff_t<_RanIt>;
const _Diff _Count = _Last - _First;
if (40 < _Count) { // Tukey's ninther
const _Diff _Step = (_Count + 1) >> 3; // +1 can't overflow because range was made inclusive in caller
const _Diff _Two_step = _Step << 1; // note: intentionally discards low-order bit
_Med3_unchecked(_First, _First + _Step, _First + _Two_step, _Pred);
_Med3_unchecked(_Mid - _Step, _Mid, _Mid + _Step, _Pred);
_Med3_unchecked(_Last - _Two_step, _Last - _Step, _Last, _Pred);
_Med3_unchecked(_First + _Step, _Mid, _Last - _Step, _Pred);
} else {
_Med3_unchecked(_First, _Mid, _Last, _Pred);
}
}
2.3.1分析:
先判断数量是否小于40个,如果大于那么跳到 _Med3_unchecked(_First, _Mid, _Last, _Pred);
这个函数实际上是一个冒泡排序(下面说),如果小于它定义了两个值 step和Two_step
分别是八分之一个位置,和四分之一个位置,然后分别从first,last,mid三个位置跟他俩组合形成9个位置的数,分别把这9个数进行调整,然后最中间的就是基准值,如下图:
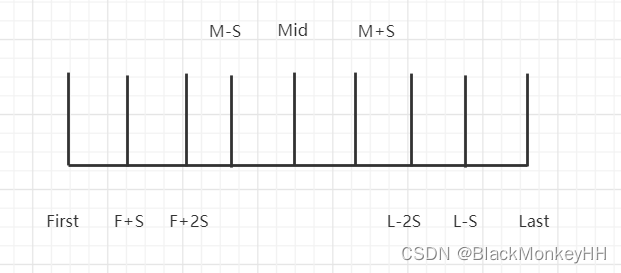
2.4 _Med3_unchecked(冒泡分析)
template <class _RanIt, class _Pr>
_CONSTEXPR20 void _Med3_unchecked(_RanIt _First, _RanIt _Mid, _RanIt _Last, _Pr _Pred) {
// sort median of three elements to middle
if (_DEBUG_LT_PRED(_Pred, *_Mid, *_First)) {
_STD iter_swap(_Mid, _First);
}
if (_DEBUG_LT_PRED(_Pred, *_Last, *_Mid)) { // swap middle and last, then test first again
_STD iter_swap(_Last, _Mid);
if (_DEBUG_LT_PRED(_Pred, *_Mid, *_First)) {
_STD iter_swap(_Mid, _First);
}
}
}
2.4.1分析:
函数前三个参数是比较的数字,最后那个是比较规则(Pred上面提到了,默认是less<>{})
第一个if比较mid是否小于first,如果小则交换,下面两个if也差不多,也就是选出大的,然后换到后面,所以是个冒泡。
2.5 快排分析
回头看上面的auto _Mid = _Partition_by_median_guess_unchecked(_First, _Last, _Pred);
现在mid的位置已经是基准值了,然后pfirst和plast的位置如下图:
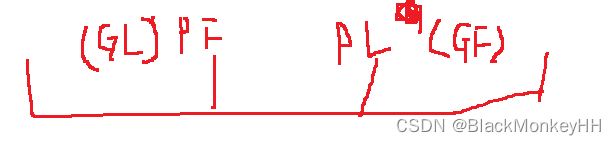
那两个while是用来选等于基准值的数,(那个Pred就是sort传进来的第三个参数,那个规则函数,默认是升序,而那两个while的意思是a不大于b,a也不小于b,那么就是a==b的时候去改变PF和PL的位置),最后PF处是等于基准值PL处不是,因为他一开始就不是。
下面的两个for循环就是分别是GF从PL出发向右走,GL从PF出发向左走,以GF为例子,如果遇到大于基准值那么continue,如果小于,那么break然后在下面和--GL交换,如果是相等那么和PL交换并更新
总结
sort函数首先从基本用法上,基础有两个参数,分别传数组的首尾指针,第三个可以传递比较器,可以是函数比较器,也可以是结构体比较器,返回值为bool类型,如果返回true则不交换,否则交换。
sort底层是根据传入数组的大小来判断使用哪种排序方式,如果长度小于40那么直接用插入排序,否则进入快排,但是如果快排的层数过多使用递归可能会造成栈溢出,因此sort限制递归的层数为1.5logn,当超过限制则会使用堆排序。
sort快排进行了优化,即对基准值做了优化,如果基准值恰好是最大或者最小值那么快排的复杂度会达到Ologn^2,因此需要选择一个适中的基准值。它将每一段排序的数组分成八段,九个位置,每三个进行一次冒泡排序,再对这三组的中间值进行一次冒泡,得到mid。
sort中的快排是一半进入递归另一半继续for循环,效率更高。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











