






徘徊、犹豫-之言:
在当今 AI 大模型技术蓬勃发展的浪潮中,挑选出一款契合自身需求的推理框架,已然成为开发者们亟待攻克的关键难题。对于企业级应用而言,高并发处理能力是其核心诉求;而个人开发者在本地进行实验时,又有着截然不同的考量标准。本文将全方位剖析 SGLang、VLLM、Ollama 这三大热门框架,从性能表现、易用程度、适用场景等多个关键维度,深入挖掘它们各自的优劣所在,助力你精准锁定最适合自己的“AI 开发利器”!不容错过!
1:SGLang:企业级推理的“性能霸主”,横扫高并发战场!
优点
1.1:吞吐量狂飙突进:
凭借零开销批处理调度器、缓存感知负载均衡器等前沿技术,SGLang 在吞吐量上一骑绝尘。就拿处理共享前缀的批量请求来说,它能轻松飙到 158,596 token/s 的惊人速度,同时缓存命中率稳稳站在 75% 的高位,简直就是为企业级高并发应用量身打造的“加速引擎”。
1.2:结构化输出极速狂飙:
基于 xgrammar 的 JSON 解码技术,犹如给解码速度装上了“火箭助推器”,比其他方案快上整整 10 倍。对于那些对输出格式有着严苛要求的场景,比如 API 接口开发,简直就是必备神器,能瞬间输出精准无误的结构化数据。
1.3:多 GPU 优化火力全开 :
完美支持分布式部署,搭配 DeepSeek 模型的数据并行注意力机制,解码吞吐量瞬间提升 1.9 倍,让多 GPU 资源得到充分利用,进一步释放性能潜力。
缺点
1.4:上手难度堪比“珠峰”:
需要开发者深入钻研其 API 和复杂的调度机制,更适合那些有着丰富经验的专业团队来驾驭,新手可能会在学习过程中“磕磕绊绊”。
1.5:系统与硬件“挑剔”:
虽说通过 docker 部署在一定程度上放宽了系统限制,但它本质上还是更偏爱 Linux 系统。而且,它对硬件配置要求极高,必须依赖高性能 GPU(像 A100/H100 这样的“性能怪兽”),否则难以发挥出最佳性能。
1.6:适用场景“专而精”:
主要适用于那些计算资源充裕的场景,比如企业级的高并发服务,或者是对结构化输出(如 JSON/XML 格式数据)有明确需求的业务领域,其他场景可能就无法充分展现其优势。
2: VLLM:大规模在线服务的“算力智控专家”
优点
2.1. 内存利用高效卓越 :
凭借 PagedAttention 技术,巧妙地将 KV 缓存进行分割管理,使得显存浪费率被严格控制在 4% 以内,从而能够同时处理更多的请求,极大地提升了资源利用效率。
2.2 动态批处理灵活高效:
Continuous Batching 技术的运用,打破了传统批处理的局限,允许新请求随时加入正在处理的批次,有效避免了等待延迟的问题,让吞吐量实现了质的飞跃,最高可提升 24 倍(相较于原生 Transformers),显著提高了处理速度和效率。
2.3. 多量化支持实用性强 :
广泛兼容 GPTQ、AWQ 等多种量化技术,通过这些技术能够显著降低显存占用,特别适合那些资源相对受限的在线服务场景,为在有限资源下实现高效推理提供了有力支持。
缺点
2.4配置过程较为繁琐 :
需要用户手动进行参数调整,对于新手来说不够友好,可能会在配置过程中遇到一些困难和挑战,需要一定的学习和摸索成本。
2.5显存占用相对较高 :
尽管在内存管理方面进行了优化,但整体显存需求仍然高于 Ollama,这意味着在硬件资源有限的情况下,可能会受到一定的限制,需要更强大的硬件支持来充分发挥其性能。
2.6系统与硬件兼容性有限 :
仅支持 Linux 系统,并且依赖于 NVIDIA GPU,这在一定程度上限制了其在不同系统和硬件环境下的适用范围,对于使用其他系统或硬件的用户来说,可能会带来不便。
适用场景:
主要适用于实时聊天机器人、大规模在线推理服务等对实时性和处理效率要求较高的场景,能够为这些场景提供强大的算力支持和高效的推理性能。
3:Ollama:个人开发者专属的“推理神器”
优点
3.1.一键式安装,畅快体验:
Ollama 提供了跨平台支持(Windows/macOS/Linux),安装过程宛如“丝滑巧克力”,轻松流畅,几分钟内即可完成部署,让开发者迅速进入开发状态。
3. 2. 海量模型库,创意无限 :
内置 1700+ 模型(如 Llama、Qwen),一键下载运行,轻松满足创意写作、学习辅助等多样化需求,为开发者提供了丰富的“创意弹药库”。
3. 3.高度可定制,灵活适配 :
通过 Modelfile 调整创造性参数或系统消息,灵活适配不同场景。比如,调高参数就能生成精彩故事,优化系统消息则可用于专业解答,满足各种个性化需求。
缺点
3.4.并发能力有限 :
在处理高并发请求时,需要手动调整参数,难以满足企业级场景的需求,更适合单机或小规模使用。
3.5.网络限制问题 :
由于服务器在国外,国内用户下载模型可能会遇到速度缓慢的问题,影响使用体验。
适用场景 :
主要适用于学生、个人开发者的本地实验,以及轻量级应用(如学习助手、创意写作工具),为个人开发者提供了便捷、高效的开发体验。
对比图:
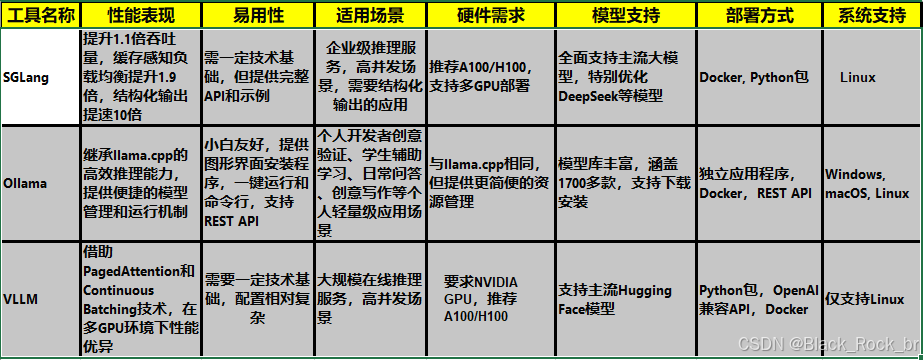
总结:
企业级服务,SGLang 是不二之选:凭借卓越的性能,其吞吐量和结构化输出能力堪称行业翘楚,为企业级应用筑牢根基。
在线高并发场景,VLLM 独占鳌头:凭借动态批处理和先进的内存管理技术,确保服务在高并发压力下依然稳定高效,保障业务流畅运行。
个人开发领域,Ollama 崭露头角:简单易用,跨平台支持搭配丰富的模型库,让创意灵感瞬间触手可及,助力个人开发者快速实现想法。
技术本身并无绝对优劣之分,关键在于是否契合应用场景。无论是对极致性能的不懈追求,还是对便捷体验的青睐有加,唯有精准选择与自身需求高度适配的框架,方能充分激发大模型的强大潜力,让技术真正赋能业务发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









