






导言:
这是 Hopper 矩阵乘法文章,也是我们关于 GEMM(通用矩阵乘法)教程。我们从单个线程块的角度深入探讨了 GEMM 的实现细节,包括 WGMMA matmul 原语、流水线技术以及 warp 专业化等内容。而在本文中,我们将从整个网格的视角重新审视 GEMM,并重点讨论如何优化任务分配以充分利用 GPU 的计算能力。
在网格层面,GEMM 的优化主要分为两类:(1)通过线程块刷选(swizzling)和集群技术来提高 L2 缓存命中率;(2)优化任务分配策略,确保各线程块之间的负载均衡,从而最大化 GPU 的资源利用率。本文的核心将聚焦于第二类优化,尽管第一类优化也会在附录中有所提及。
具体而言,我们将介绍一种名为 **Stream-K** 的任务划分策略。这种策略旨在解决波量化(wave quantization)问题——当工作单元的数量无法被流处理多处理器(SM)的数量整除时,就会出现这种现象。此外,当采用传统的基于块的输出划分方式时,若矩阵的 M 和 N 较小而 K 很大,GPU 的计算资源往往无法被充分利用,而 Stream-K 在这种场景下表现出色。
本文的结构安排如下:首先,我们将解释波量化问题及其与持久内核(persistent kernel)的关系。接着,我们会对比多种在线程块间划分 GEMM 工作负载的策略,包括 Stream-K 及其前身 Split-K,分析它们如何应对波量化问题。随后,我们将指导内核开发者如何设计自己的 tile 调度器,并以本系列第二部分中的 GEMM 内核为基础,演示如何实现 Stream-K 策略.
Wave quantization
一块 NVIDIA GPU 包含多个流处理多处理器(SM),每个 SM 拥有独立的硬件资源,例如共享内存、寄存器文件和张量核心等,并且能够独立运行。理想情况下,计算任务应该被均匀分配到所有 SM 上,以确保它们在整个内核执行期间都能高效运转。然而,如果某些 SM 完成任务的速度快于其他 SM,这些 SM 就会进入空闲状态,等待其他 SM 完成任务,从而导致负载不均衡的问题。
假设某个计算任务可以被拆分为大小相等的工作单元,并且每个工作单元都可以由一个 SM 在相同的时间内完成。例如,在 GEMM 中,通常会将任务划分为多个工作单元,每个单元负责计算一个 bM x bN 的输出 tile。这些工作单元会被分配给线程块(CTA),而每个 CTA 会在可用的 SM 上执行其对应的任务。这种将工作单元分配给 SM 的过程被称为调度(scheduling)。
当工作单元的数量超过可用 SM 的数量时,这些工作单元会被分批处理,每一批次称为一个波(wave)。具体来说,每个可用 SM 同时处理一个工作单元,当所有 SM 完成各自的任务后,便构成一个波的完成。
波量化(wave quantization)问题出现在工作单元的数量不能被可用 SM 的数量整除时。例如,假设有 10 个工作单元和 4 个 SM,那么这些工作单元的执行时间轴如下所示:
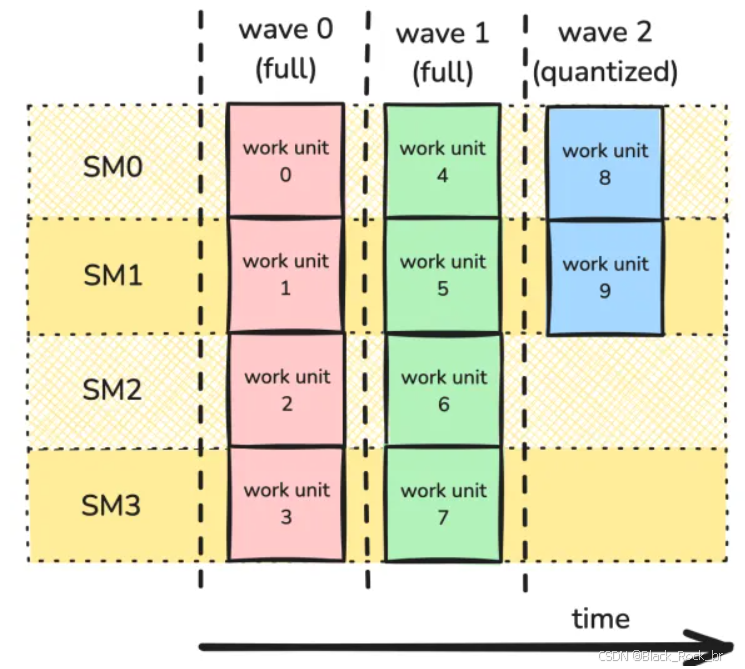
在这种情况下,前两波是完整的波,每个 SM 都得到了充分利用。然而,最后一波是一个部分波,仅占用了半个 SM。
当工作单元的数量相对于 SM 的数量较少时,波量化现象会严重降低性能。例如,在一块拥有 114 个 SM 的 H100 PCIe GPU 上,如果计算任务有 115 个工作单元,那么它需要 2 个波——这与拥有 228 个工作单元的计算任务所需的波数完全相同!换句话说,仅仅多出第 115 个工作单元,就会让设备利用率大约减半。另一方面,虽然拥有 114,001 个工作单元的计算任务也会受到同样的量化影响,但其带来的性能损失与整个内核的总开销相比可以忽略不计。你可以在 NVIDIA 深度学习性能指南中找到更多相关信息。
为了观察波量化的实际影响,我们可以采用本系列第二部分中实现的 GEMM 内核,并在不同波数下测量其性能。假设我们要计算一个 M×K 的矩阵 A 与 K×N 的矩阵 B 的乘积。令 bM 和 bN 分别为工作瓦片的尺寸,并假设它们能够整除 M 和 N。那么总波数为 ceil((M/bM × N/bN)/num_SMs)。为了研究量化效应,我们关注每个 SM 分到的瓦片数,即 (M/bM × N/bN)/num_SMs;其小数部分表示最后一波的填充程度。因此,我们将固定 M=1024、K=4096,并以 bN(对于我们来说是 192)为步长,逐步增加 N 的值。
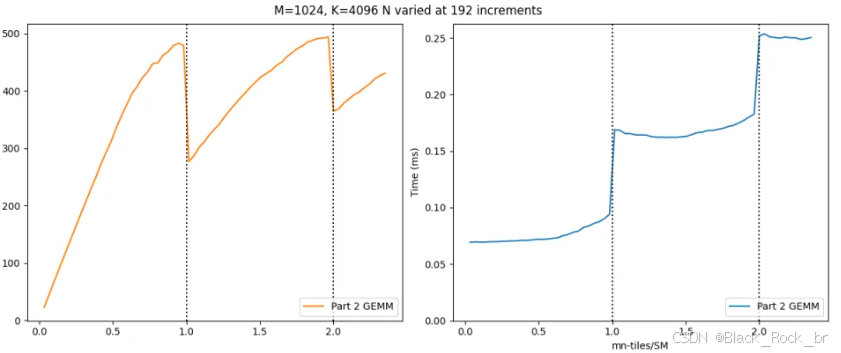
左侧图表展示了以 TFLOPs/s 为单位的性能,右侧图表则显示了执行时间。所有数据均在 H100 PCIe GPU 上进行了基准测试。图中的虚线表示波的分界线,即每个 SM 分配到的瓦片数跨越整数值的位置。左图清晰地展示了波量化效应——每当跨越波界时,性能会出现明显的下降。相应地,右图显示了耗时主要由总波数这个离散参数决定(具体来说,当 x ∈ (0,1] 时为 1 波,x ∈ (1,2] 时为 2 波,以此类推)。
需要注意的是,第二次量化带来的影响要小于第一次——随着波数的增加,波量化效应的影响会逐渐减弱。然而,增加波数并非易事,尤其是在 NVIDIA GPU 的 SM 数量随着新架构不断增加的情况下。因此,我们必须提出一些策略,在不对问题规模做假设的前提下,尽可能减轻波量化的影响。
Persistent kernels
为了解决波量化问题,我们需要设计更加高效的划分与调度策略。在本博客之前展示的内核实现中,网格(grid)的规模通常由问题的维度决定,每个 CTA 负责处理一个固定的工作单元。以 GEMM 为例,工作单元对应于 MxN 输出矩阵中的 bM×bN 子块(tile),其中 bM 和 bN 在编译阶段就已经确定。每个工作单元由一个 CTA 独立完成计算,这些 CTA 会分布在大小为 M/bM × N/bN 的网格中执行任务。因此,我们的 kernel 启动参数通常可以表示如下:
![]()
这种方法的局限性在于,尽管我们能够通过一定方式控制线程块(CTA)如何分配到流处理多处理器(SM),但很难实现更加复杂的调度策略。为了解决这一问题,我们引入了一种新的设计思路:持久化内核(persistent kernels)。在持久化内核中,网格的大小被设定为一个固定值,通常等于可用 SM 的数量。这样设计的目的是让每个线程块独占一个 SM,从而更高效地利用硬件资源。我们可以通过以下 CUDA 代码获取用于确定网格维度(dimGrid)的 SM 数量:

每个 CTA 在分配到的 SM 上会持续运行,并不断处理多个工作单元,直到所有任务完成为止。这种设计上的调整赋予了程序员更大的调度灵活性,使其能够精确控制每个 CTA 如何访问和处理各个工作单元。通过这种灵活性,我们可以更有效地分配任务,从而显著减少波量化问题和负载不均衡现象。
在实际应用中,工作单元的分配通常由一个名为 tile 调度器(tile scheduler)的组件负责。从本质上讲,tile 调度器是一个功能增强的迭代器,用于指导每个 CTA 下一个需要处理的工作单元的位置,以及何时停止处理。尽管每个输出 tile 的总计算量保持不变,但通过切换不同的 tile 调度器,我们能够尝试更加复杂的任务分配策略,例如采用 Stream-K 方案,以进一步优化负载均衡并提升整体性能。
优化持久化内核以缓解波量化效应
为了更好地逐步理解 Stream-K,我们也有必要先回顾一些更简单但效率较低的波量化应对方法。Stream-K 相关论文对此进行了非常深入的讨论,强烈建议读者阅读。为了帮助读者更好地理解,这里我们将对论文中的讨论内容做一个简要总结。
为了使数据更易于理解,本节将以一块虚构的 GPU——Hipparchus H10(仅包含 4 个 SM)为例。
数据并行
我们先从最基础的版本开始:即在 M 和 N 方向上均匀划分 tile,并通过轮询(round-robin)的方式将这些 tile 分配给各个 CTA。需要注意的是,这种方式与非持久化、基于工作 tile 网格启动的内核实现几乎相同,唯一的区别在于分配顺序得到了明确保证。尽管如此,研究这种策略仍然具有价值,因为它能够帮助我们理解波量化问题在哪些情况下会显现出来。由于各个工作单元之间彼此独立且无依赖关系,这种调度方式通常被称为数据并行(data-parallel)工作调度.
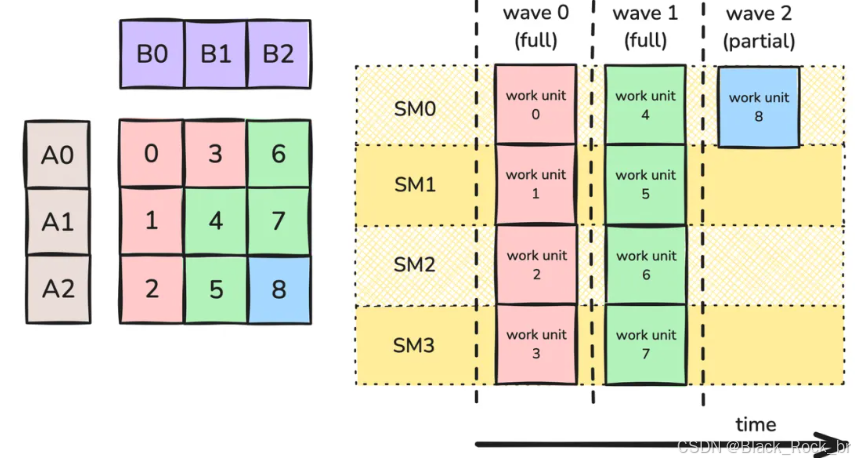
图 1 展示了一个划分示例。在这里,GEMM 工作负载被分成了 9 个工作单元。由于每个工作单元都是等价的,这些单元会以“波”的形式被处理。具体来说,这 9 个工作单元会在 H10 的 4 个 SM 上分 3 波执行:前两波为完整的波,最后一波是部分波,只占用了 4 个 SM 中的 1 个。如果每个工作单元在其 SM 上都能达到 100% 利用率,那么整个计算过程的平均利用率就是 2.25/3 = 75%。
最直接的应对方法是回到这样一个事实:如果工作单元数量增加,波量化问题的影响就会减小——而我们可以通过缩小每个工作单元的规模来增加工作单元的数量。
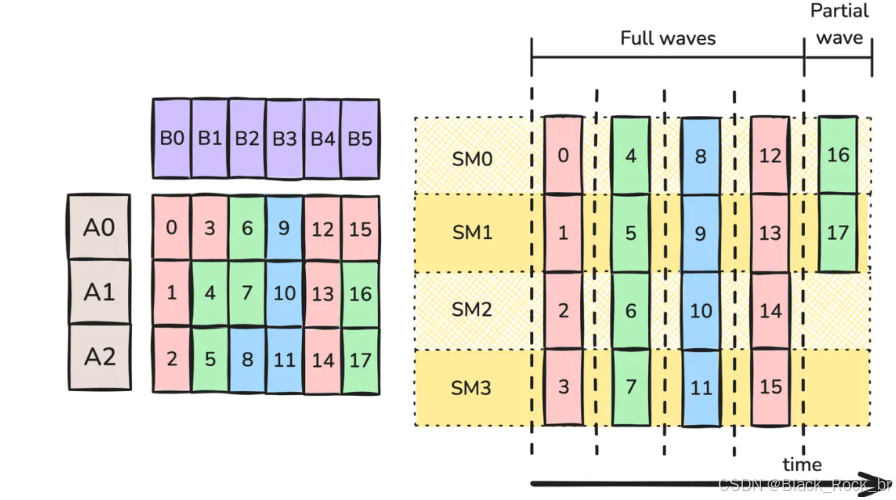
在图 2 中,我们将 bN 在 N 方向上缩减了一半。此时,总共有 18 个工作 tile,可以分为 5 个波执行:其中 4 个是完整的波,而第 5 个波仅部分占用(4 个 SM 中只有 2 个被使用)。假设每个工作 tile 都能以 100% 的计算利用率运行,那么整个计算过程的平均利用率则为 4.5/5 = 90%。此外,由于图 2 中每个工作 tile 所需的浮点运算次数(FLOPs)是图 1 的一半,粗略估计每个波的执行时间也应为图 1 的一半。因此,尽管图 2 需要 5 个波而图 1 只需 3 个波,图 2 的总用时仅为 (5*0.5)/3 ≈ 图 1 的 83%!这看起来似乎是一个改进,但问题真的如此简单吗?
遗憾的是,这里的分析基于过多的简化假设,无法准确反映 Hipparchus H10 的实际行为。核心问题在于,随着 tile 尺寸的缩小,每个工作 tile 的计算效率可能会下降。因此,假设 tile 尺寸减半就能让计算时间减半,或者保持单个 CTA 的利用率不变,通常是不现实的。
一个主要的问题是 **算术强度** 的降低。为了掩盖内存访问的高延迟,我们希望每次内存访问能够配合尽可能多的算术运算。对于 GEMM,一个 CTA 计算一个 bM × bN × bK 的 matmul tile 时,会执行 2·bM·bN·bK 次算术操作,并进行 (bM·bK + bN·bK + bM·bN) 次全局内存(GMEM)访问。可以看到,当 bN 减半时,算术操作的数量也随之减半,但内存访问量却没有按相同比例减少。例如,128 x 128 x 128 的 tile 每次 GMEM 传输可支持 85.3 次运算,而 128 x 64 x 128 的 tile 则只能支持 64 次运算/每次 GMEM 传输。
另一个问题是,如果 CTA 的大小保持不变,tile 尺寸减半会导致每个 CTA 内 warp 需要处理的指令数量也减半。这会削弱 warp 调度器的延迟隐藏能力,而延迟隐藏对于实现流水线化 GEMM 的高性能至关重要。
最后,tile 的尺寸还可能受到 MMA atom 的限制。例如,在 H10 上,可能需要使用 128 x 128 x 16 的 WGMMA atom 才能达到最大吞吐量。这种硬件约束对 tile 的最小尺寸提出了要求。
在这些因素之间找到平衡并非易事,针对特定问题选择合适的 tile 尺寸通常需要反复试验。为此,可以借助工具如 CUTLASS Profiler 来评估和优化性能.
Split-K
截至目前,我们仅在 M 和 N 方向上进行了划分,但实际上还有一个可以利用的维度:K 方向。当 K 值较大时,在 K 方向上进行划分(即 Split-K)会非常高效。然而,与之前类似,如果 bK 的值过小,同样会导致算术强度降低以及延迟隐藏能力的削弱。
Split-K 调度的核心思想是将一个 tile 沿 K 方向均匀分割为多个部分。例如,在图 3 中,我们便将 tile 在 K 方向上划分为 2 个工作单元.
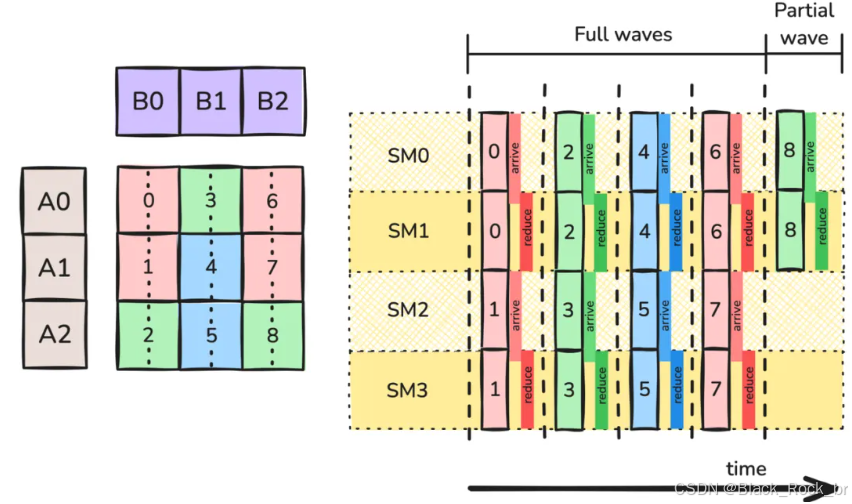
这种策略带来了一个新问题:每个 CTA 只为其 bM×bN 输出 tile 累加了一部分结果。为了完成计算,负责同一输出 tile 的多个 CTA 需要合并它们的结果。通常的做法是在辅助 GMEM 工作区进行“turnstile reduction”。每个协作计算同一 tile 的 CTA,会在前一个 K 索引的 CTA 达到同步屏障后,将自己的部分结果累加到工作区,然后自己也到达屏障。最后一个 CTA 则从工作区读取数据到自己的累加器,并计算收尾。不过,额外的 GMEM 访问和 barrier 同步会带来额外开销,如图 3 中的“arrive”和“reduce”模块。
Split-K 引入了一个新的超参数——分割数,这会带来一些权衡:
- 增加分割数可以减轻波量化的影响,可能提高 SM 利用率。
- 增加分割数会使 K 方向的 tile 尺寸变小,可能导致 GMEM 访问与计算的比值增加(内存带宽压力增大)。
- 增加分割数会减少每个 CTA 执行的指令数,降低隐藏延迟的能力。
- 我们还引入了同步和归约的额外开销,这是 Split-MN 所没有的。分割数越多,同步成本越高。
Stream-K
到目前为止,我们所讨论的这些策略虽然在一定程度上缓解了波量化问题,但并未彻底解决它。让我们回到最初的示例——将 9 个工作 tile 分配到 4 个 SM 上——理想情况下,每个 SM 应当能够运行 2.25 个波。而这正是 Stream-K 策略的核心动机。
Stream-K 策略为每个 SM 分配一个持久化的单一 CTA。每个 CTA 会被分配一个“分数”数量的工作 tile,其中被拆分的 tile 沿 K 方向进行划分。与 Split-K 策略类似,对于每个被拆分的工作 tile,协作的 CTA 可以通过 turnstile reduction 在 GMEM 工作区中合并它们的结果.
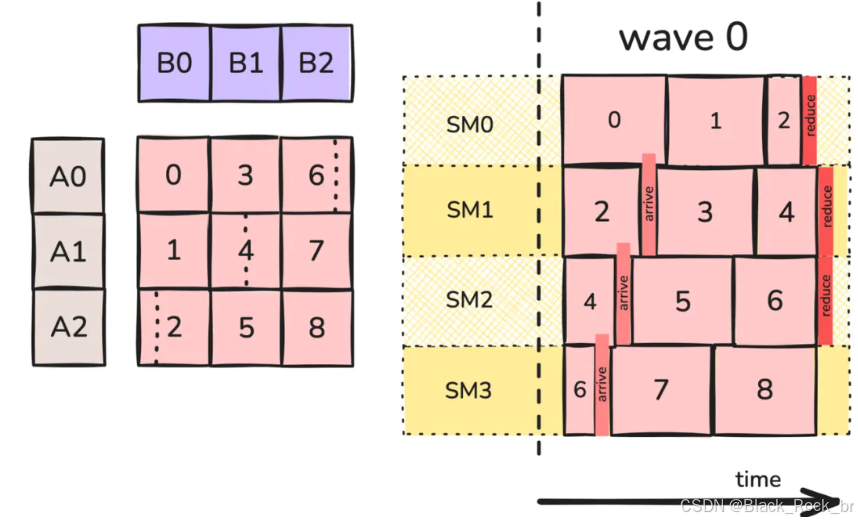
在图 4 中,SM0 上的持久化 CTA 计算了完整的 tile 0、完整的 tile 1 和 tile 2 的 1/4。SM1 上的持久化 CTA 计算了 tile 2 的剩余部分、完整的 tile 3 和 tile 4 的一半,以此类推。部分 tile 的调度方式是:确保每个 tile 的第一个部分比最后一个部分提前很多计算,从而尽量减少同步开销(不过,如果 tile 在 K 方向上很长,可能无法总是做到这一点)。
现在,我们来比较 Stream-K 和之前讨论的策略:
- Stream-K 通过消除“波”,解决了量化问题。每个 CTA 处理 2.25 个工作 tile。除了同步和归约所需的额外时间外,总体计算时间约为 2.25 个单位,而原始 kernel 需要 3 个单位。
- 许多原本 128×128×128 的工作 tile 仍然由单个 CTA 完全处理,因此保留了大 tile 的一些优势:高算术强度、较长的指令序列,以及能够使用大 WGMMA 指令。如果第一个 kernel 的每个 CTA 能达到 100% 利用率,那么这里也可以做到。
- 在很多情况下,输出 tile 的前几个部分可以比最后一个部分提前很多计算,这样负责 epilogue 的 CTA 实际上不需要长时间等待同步屏障。
- 但这个内核确实需要额外的 GMEM 传输,以便不同 CTA 之间共享部分 tile 的数据。
Hybrid Stream-K
我们还可以对内核进行最后一项优化,这与缓存性能有关。对于采用瓦片划分的 GEMM 内核而言,每个操作数的瓦片通常会被多个输出工作瓦片所共享。例如,在 split-MN 的情况下,B0 瓦片会被用于计算输出的瓦片 0、1 和 2。
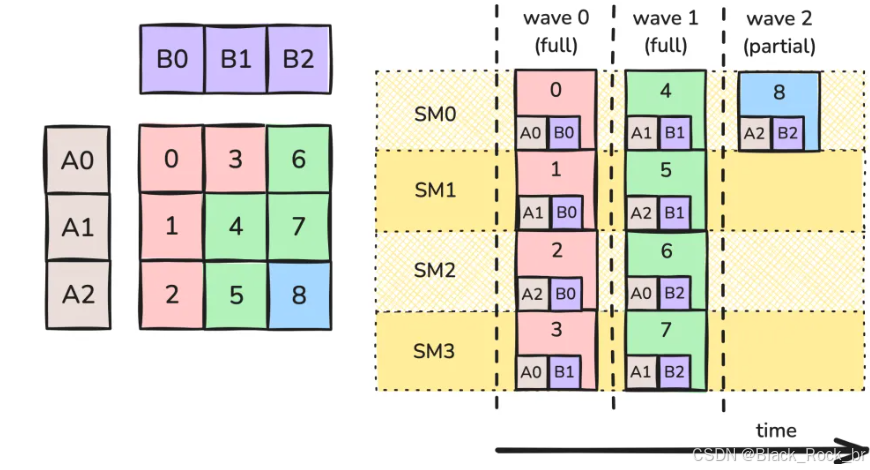
在计算过程中,输出 tile 0、1 和 2 是同时被处理的。当某个 CTA 从全局内存中加载 tile B0 时,这个数据会被存入 L2 缓存中。如果其他 CTA 也需要访问 tile B0,它们可以直接从缓存中获取数据,从而大幅提升加载速度。然而,由于缓存容量有限,旧的数据可能会被新数据驱逐。因此,为了最大化缓存利用率,这些数据请求需要在时间上尽可能接近。
更具体地讲,操作数 tile 也会在 K 方向上进行分块,每个 CTA 会在其操作数 tile 的 K 块上执行内层循环。例如,在第 0 波开始时,SM0、SM1 和 SM2 会同时请求 tile B0 的第 0 个 K 块,其中有两个请求能够命中缓存。在下一次循环迭代中,它们又会同时请求 tile B0 的第 1 个 K 块,依此类推。
然而,Stream-K 内核引入了一种“错位”(skew)现象:由于每个 SM 初始分配的部分 tile 大小不同,它们往往会在同一时刻访问不同的 K 偏移量。以图 4 为例,尽管 SM0 和 SM2 都在第 0 波开始时使用 B0 的数据,但 SM0 请求的是第 0 个 K 块,而 SM2 请求的是更靠中间的 K 块。实际上,这种调度方式导致各 SM 的 K 偏移量无法对齐,从而显著降低了缓存命中的概率。总的来说,虽然消除了“波”的概念并实现了不同 SM 的异步调度,但这也带来了缓存性能下降的隐性代价。
为了解决这一问题,我们可以通过重新设计调度策略,将计算过程构建成持久化内核与普通数据并行内核的混合体。由于数据并行调度不会产生错位问题,因此应尽可能多地采用这种方式,仅在处理波量化残留的少量 tile 时使用 Stream-K 策略。为了确保 Stream-K 阶段 SM 之间的负载均衡,需要分配 1 个完整波以及剩余的部分波到该阶段。
这种调度方式如图 6 所示。在初始的 Stream-K 阶段,会处理 1 到 2 个完整波的计算任务。每个 SM 最多分配到 2 个部分工作 tile。通过这种设计,这些 tile 的总计算量与 CTA 无关,因此所有 CTA 预计会在同一时间完成该阶段的计算。一旦该阶段结束,剩下的便是完整的工作 tile,并且其数量能够被 SM 数整除。此时,这些 tile 可以通过非持久化、数据并行的策略来计算——这种方式不仅避免了波量化问题,还具有更好的缓存性能。如图 6 所示.
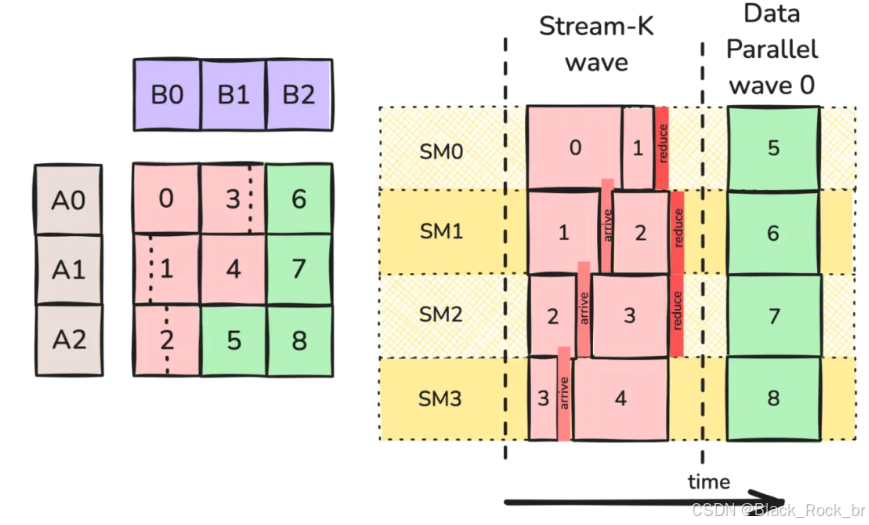
我们可以合理推测,工作瓦片 6、7 和 8 将几乎同时被计算,这使得在访问操作数瓦片 B2 时能够命中缓存。同理,工作瓦片 5 和 8 因为共享同一个 A 瓦片,也能利用缓存。在这个例子中,数据并行阶段仅包含 1 个波。但如果 GEMM 的规模更大、工作瓦片更多,数据并行阶段就会更长,缓存的利用率也会相应提高。
Tile 调度器抽象
由于工作划分和调度问题在很大程度上与每个 CTA 的内存及计算操作是独立的,像 CUTLASS 这样的 GEMM 实现通常会采用一种称为瓦片调度器(tile scheduler)的抽象来封装这些逻辑。(这种方式不仅适用于 GEMM——例如 FlashAttention-3 也支持基于瓦片调度器类的持久化内核。)在下一节中,我们会具体分析 CUTLASS 的实现,这里我们先概述一下瓦片调度器一般承担的职责。
首先,内核的 grid 形状取决于瓦片调度方式。因此,瓦片调度器负责决定内核的 grid 大小。对于非持久化内核,grid 大小与逻辑网格相同,取决于问题规模;而对于持久化内核,grid 大小通常是固定的,并且很可能等于 SM 的数量。我们会在启动内核前向瓦片调度器查询 grid 大小,并用它来配置内核启动参数。
在内核内部,每个线程会构造一个瓦片调度器的实例。主循环和 epilogue(收尾计算)现在会被包裹在一个由调度器提供的工作瓦片循环中,大致如下所示:
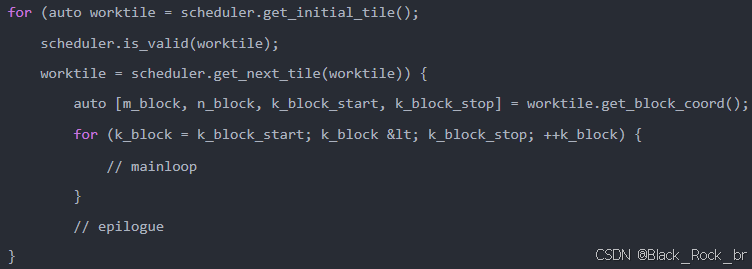
实现这些迭代器原语的一种简单方法是,让调度器维护一个线性的工作 tile 索引。在持久化内核中,每个 CTA 初始分配索引为 `blockIdx.x` 的工作 tile(即底层 SM 的编号),并通过递增 `gridDim.x`(SM 数量)跳转到下一个 tile。只要索引未超出总 tile 数量,则该 tile 有效。线性索引到实际 (M, N) 坐标的映射由 `worktile` 对象完成。
这种方法适用于持久化数据并行调度,但更复杂的策略(如 Stream-K)需要更多支持。例如,Stream-K 中的工作分配依赖 K 方向的 tile 尺寸,因此 `worktile` 需提供四个坐标。
对于 Stream-K 和 Split-K,部分 CTA 输出需要聚合部分结果,带来以下需求:
1. GMEM 工作区:需要额外空间存放部分结果和同步屏障对象,大小与问题规模相关,需动态分配。
2. 区分完整与部分结果:CTA 需知道当前 tile 是完整输出还是部分结果。
3. epilogue 分配:只有一个 CTA 执行 epilogue,从工作区累加结果并完成计算。
CUTLASS 的实现表明,可以通过优化调度顺序、切换模式(如 Stream-K 和数据并行)以及利用 Hopper 架构特性来提升性能。
我们提供了三种调度器示例:非持久化调度器、数据并行持久化调度器和 Stream-K 混合调度器。实践中发现,要实现高性能,需仔细调整 Stream-K 的工作分界以减少归约操作带来的性能损失。
下图展示了 Stream-K 的性能表现:初期优于数据并行,显著减轻波量化效应,但后期性能下降。采用 CUTLASS 的启发式策略(最后一波填满一半时切换回数据并行)效果显著.
结论:
我们探讨了波量化(wave quantization)及其对 GEMM 性能的影响。我们发现,在第二部分实现的 GEMM 中,波量化导致了显著的性能波动。为了解决这一问题,我们研究了多种应对波量化的策略,并重点介绍了 Stream-K 方法的优势与实现细节。最后,我们实现了一个 Stream-K tile 调度器版本,成功消除了波量化对我们 GEMM 实现的性能影响。至此,我们基于 CUTLASS/CuTe 抽象构建高性能 Hopper 架构 GEMM 的三部曲正式完结.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









