







 文章介绍了DECASE挑战,包括低复杂度声学场景分类、无监督异常声音检测、声音事件定位与检测等任务,重点讨论了FoleySoundSynthesis任务,要求生成特定类别的仿真声音。此外,还提到了评估指标和基准系统。
文章介绍了DECASE挑战,包括低复杂度声学场景分类、无监督异常声音检测、声音事件定位与检测等任务,重点讨论了FoleySoundSynthesis任务,要求生成特定类别的仿真声音。此外,还提到了评估指标和基准系统。
文章目录
课程内容概述
-
要求实现一个有关语音和文字两种模态融合的程序,同时阅读相关论文,根据个人理解撰写课程论文,并以ppt的形式进行讲解。可选为以下的五个主题
- 语音增强
- 检测识别
- DOA声源定位
- 语音分离
- 语音合成
- 场景分类
-
这里参考DCASE(Challenge on Detection and Classification of Acoustic Scenes and Events),即声学场景和事件检测及分类竞赛,是世界范围内权威的声学比赛,从2013年至今已经成功举办了六届,随着越来越多的顶级高校组织、权威科研机构等参与到比赛中来,DCASE在一定程度上推动了计算机听觉的发展的快速发展。
DECASE官网介绍
Introduction
- 声音有很多信息,这些信息是关于周围环境和正在发生的事情。我们需要识别出声音的具体场景,比如说繁忙的街道、办公室等。而且我们还要能识别出个人声音源,比如说是汽车通过时发出的,脚步声等。开发出能够专门提取出这些信息的应用,十分有用,比如说基于音频信息搜索多媒体,做一个能够理解用户上下文的机器人,智能监控系统。但是,如果在很多人讲话的情况下,分离出人的声音和环境的声音,获取可靠的信息,还需要投入很多研究。
Challenge Status
- Task 1:Low-Complexity Acoustic Scene Classification 低复杂声学场景分类
- 这个任务的目标是在尽量少的内存和计算的情况下,发出声音的设备在什么地方。这个任务主要的限制就是模型不能太复杂,声音的数据会很多样,并且还有多个设备,这也是符合声音场景分类在实际生活中的应用。这个任务的核心在于训练出鲁棒性足够强的模型,并且这个模型不能太大还要能在嵌入式设备上使用。
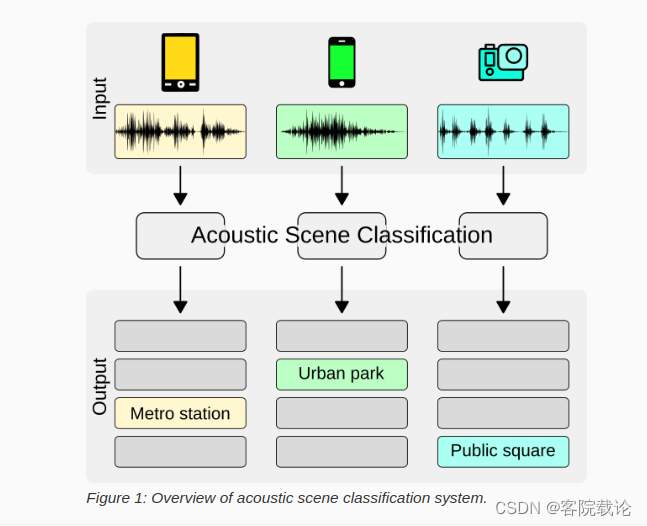
-
Task 2:First-Shot Unsupervised Anomalous Sound Detection for Machine Condition Monitoring 用于机器监督的无监督异常声音检测
- 这个任务的目标就是使用单纯的声音,监督一个机器是否正常。与去年不同的是,今年的数据集使用的是完全不同的数据集,并且训练集和测试集也完全是不同的,要求参与者能够调整系统能够处理完全不同的新的机器类型。
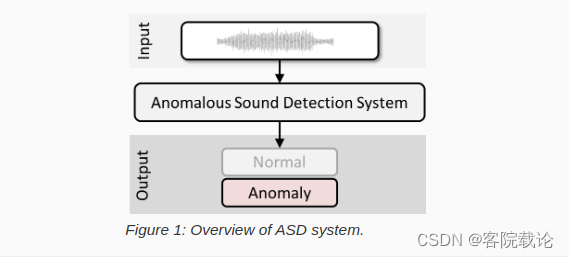
- 这个任务的目标就是使用单纯的声音,监督一个机器是否正常。与去年不同的是,今年的数据集使用的是完全不同的数据集,并且训练集和测试集也完全是不同的,要求参与者能够调整系统能够处理完全不同的新的机器类型。
-
Task 3:Sound Event Localization and Detection Evaluated in Real Spatial Sound Scenes 基于真实空间声音场景的声音事件定位与检测
- SELD是一个联合任务,一方面需要检测出目标的持续性或许偶那个,还要估计出相应的空间轨迹。。这个任务是去年SELD任务的继续,去年的任务是在局部标注的记录上进行的。今年需要在实际的数据集上进行测试,这个挑战性还是很大的。今年除了获得音频记录的数据,参与者还能获得360度的视频信息
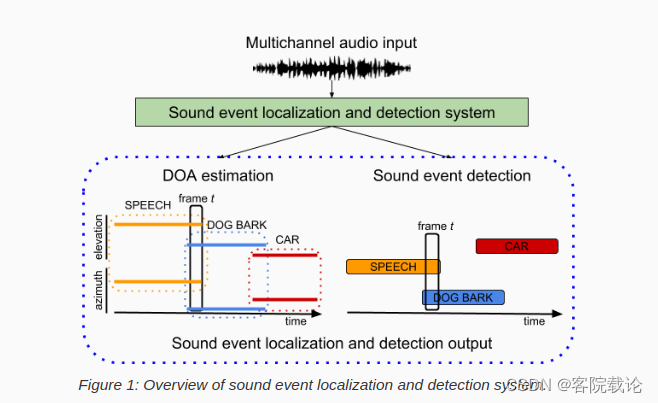
- Task 4:
- Sound Event Detection with Weak Labels and Synthetic Soundscapes 使用弱标记和同步的音景,检测声音发生时间
- Sound Event Detection with Soft Labels 使用软样本样本对声音进行检测
- 这一类任务的目标就是给你一段录音,你能识别出发出了哪些声音事件,并且标注出这些事件发生的时间段。这个任务是为了是模型在训练数据集上能够识别出不同的声音事件,在数据集中,这些标记是不同的,并且是随时发生变化的,主要是为了观察模型利用模型的过程。主要是因为完全标注好的数据集很难获得,并且在一定程度上还要受到标注者的偏差影响,所以在本次任务中,我们提出了使用两种数据集,分别是在第一个任务中使用的是弱监督的数据集,以及协同的声音场景。第二个任务使用的软标记的数据及。
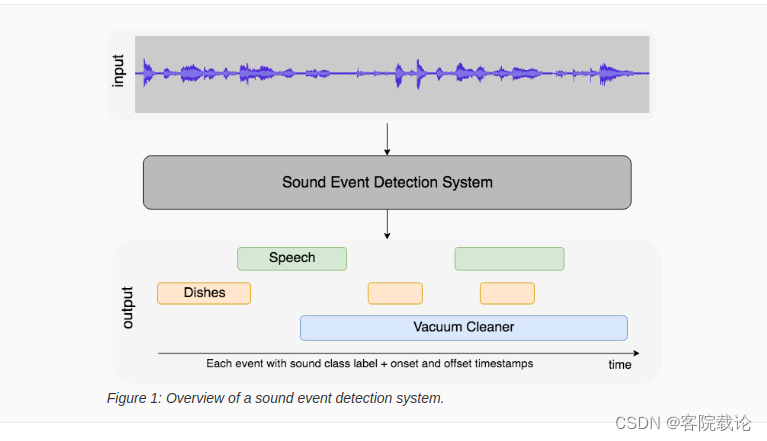
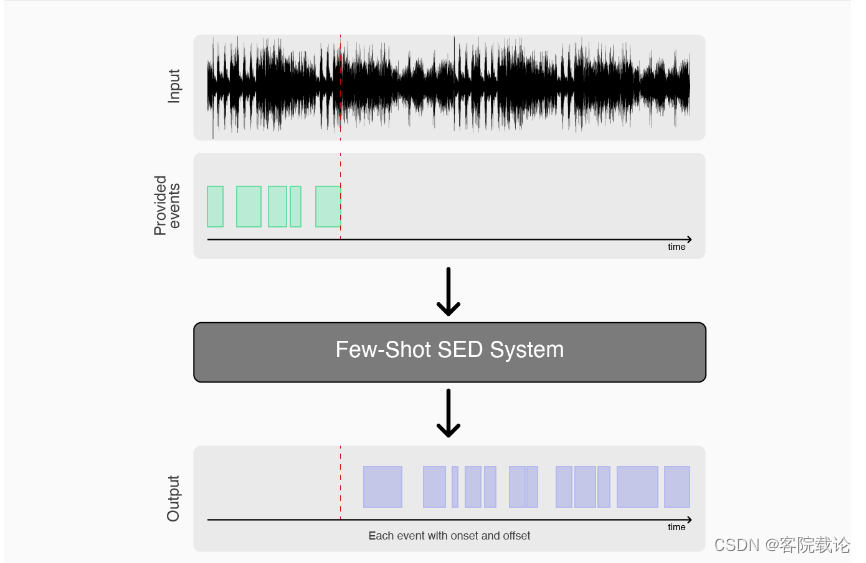
- Task 5 Few-shot Bioacoustic Event Detection 多次生物声音时间检测:
- 这个任务的就动物会发出多次叫声,你要能够检测出是什么类别的动物。每一个动物的声音样本是五次,然后参赛者要能开发出识别他是什么动物算法。
-
**Task 6 Automated Audio Captioning and Language-based Audio Retireval **:
- 根据声音信号,自动将之转为文字
- Automated Audio Captioning
- 自动音频标注AAC,使用自由文本对一般的音频文字进行标注。这是个模态内的转换任务,并不是语音转文字,系统会接受一段音频,并输出这段信号的文字描述。AAC能够对声音的特性(沉闷的声音),物理属性(大型汽车的声音)和环境进行描述。比如说生成的结果就是,人们在一个狭小并且空空的房子里谈话。甚至还能提炼出水品跟高的知识,比如说时钟响了三下。这玩意的应用很广泛,可以被应用在不同的场景,从智能自动内容描述到以内容为导向的机器之间的交流。
- 这个玩意还是挺厉害的
- Language-Based Audio Retrieval 基于语言的音频内容检索
- 这个子任务的目标是根据声音的文字描述来检索音频信号。这个目的就是能够根据无约束的文本描述检测出对应的不同的音频
- 蛮想做的,但是数据集,好像没有baseline

-
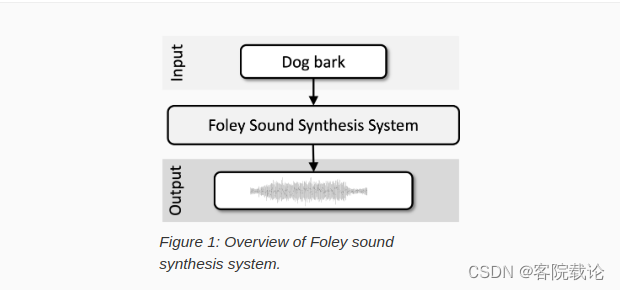
**Task 7 Foley Sound Synthesis 仿真声音合成 **:
- 这个任务的目标是合成可信的仿真声音,这个声音要能完全拟合到相应的类别中。仿真声音类别是由声音事件和环境声构成。这个任务主要有两部分,有外部生源的仿声,无外部生源的仿声。
- 这玩意用在电影里的配音比较多,比如说万马奔腾的声音等等,类似口技。
任务选择
-
我是从事多模态方面的研究,所以想选一个多模态的方面的项目进行复现,并且与我而言,只需要复现一个baseline就行。在分析一下
- 第一个任务是做场景分类,并且主打的是一个低运算和低内存
- 第二个任务根据声音判定机器是否运作正常,这个可以尝试一下,虽然不是多模态,但是我之前做过关于仪器故障检测项目,不过那个项目主要是通过震动频率等图像。
- 第三个任务是声音事件的定位和检测,主要是涉及两个任务,分别是对声音进行分类,并将这段声音在空间中进行定位。我觉得这个任务比较难,需要分别完成两个任务,然后将两个任务进行合并,算是一个多模态任务,而且我觉得光是定位就是一个多模态任务,我是倾向于选这个,而且内容比较多,比较好讲。但是需要看一下,这个baseline可以跑吗?
- 第四个任务是对声音事件进行检测,判定他是什么类型,并且提取出该声音发生的时间段,这个任务比较简单,但是主要是针对数据集的变化
- 第五个任务是是识别声音的发出的对象,判别是哪一种动物,主要是应用比较新颖,原理的话应该也是原来的方法,所以如果想了解那些常用方法的原理,可以选这个
- 第六个任务是主要是音频注释和搜索,而且我觉得这个东西还是挺有意思的,挺高级,从语音角度获取更加高级的语音信息。
- 第七个任务是针对声音合成的,根据需要合成对应的声音,这个还是挺实用的,我也觉得很有意思,单纯从完成任务的角度,这可以选一下这个。
-
暂时决定选最后一个,进行语音合成,然后尽快做自己的项目。
Foley Sound Synthesis
Summary of Task
- 这个项目要求生成不同的声音,总共有7个类别,定义如下
- class index——>[model]——>100种声音(4-second / mono / 16-bit / 22,050 Hz)
- class:{“DogBark”: 0, “Footstep”: 1, “GunShot”: 2, “Keyboard”: 3, “MovingMotorVehicle”: 4, “Rain”: 5, “Sneeze_Cough”: 6}
- 在第一个任务中,参赛者可以使用外部的模型或者数据。但是在第二个任务,不允许实用任何外部的东西,可以提交一个或者两个都提交。
- 每一个项目主要由两部分构成
- yaml文件:包括了Colab 笔记本的链接
- pdf文件:技术报告
Description
- 伪声(Foley Sound)就是叙事作品中用来配乐的,类似我们中国的口技。这个东西一般是用来增加多媒体中的听觉体验的。这个任务要求系统能够生成表达某一类声音的原始声音的剪辑。
- 新生成的声音应该和特定类别的声音相拟合,而不应该是将训练集中提供的声音在复制一下。
Why is it an important task?
- 首先,如果要获得完美匹配的声音效果,耗费时间的后期制作是必不可少的。通过直接生成属于目标类的声音,这个伪声合成系统可以是工作站更加高效。随着越来越多的虚拟场景的出现,我们希望能够出现更加复杂的并且有创造力的声音环境。第二,可以把他用于数据集合成或者增强,这对很多DCASE任务都很有用,比如说SED,声音事件检测。
Task Setup
- 这个任务需要根据两个参数生成对应的声音,第一个参数是类的编号,第二个参数是需要生成的声音的数量。生成的声音要是4秒钟左右
- 这个任务主要有两个部分,第一个是使用外部的源进行模型的开发,第二个是不使用外部的源进行模型的开发。
Audio Dataset音频数据及
Development Set 训练集
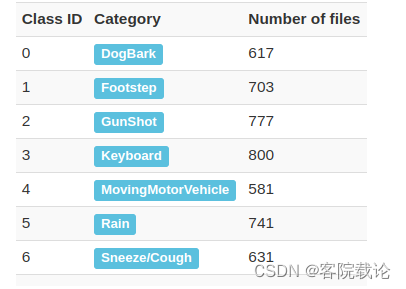
- 训练集是由三个音频数据集构成的,分别是UrbanSound8K, FSD50K, 和 BBC Sound Effects。数据集由4850个带标记的样本构成,共有7个类别。所有的音频都转为mono 16-bit 22,050 Hz的音频。除此之外,每一个数据都被精确分成4秒钟,具体类别编号如下
- mono是什么
- 表示声音是单声道
Evaluation Set测试集
- 测试集和训练集拥有同样的类别,采样频率、声道数量和音频的深度,和训练集中的音频相对应。每段音频是4秒钟,并且每个类别是100个样本。
Evaluation Metric 测试参数
- 一般使用FAD作为测试指标,这个指标是基于Frechat Inception Distance数据集的,并且广泛用于生成模型。因为这个参数主要是通过生成样例和实际样例的隐藏表示的共有集合计算的,所以即使在没有真实样本的情况下,也可以使用这个参数。FAD计算如下,首先,从训练集和生成的样本中,同时提取出音频表示特征。我们使用VGGish,这是一个在AudioSet上训练的分类模型。然后,将表示的每一个集合映射到多元高斯分布中。最后,生成样本的FAD分数是通过两个分布的Fercaht距离实现的,计算公式如下
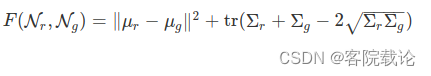
- N r ( μ r , σ r ) N_r(\mu_r,\sigma_r) Nr(μr,σr)和 N g ( μ g , σ g ) N_g(\mu_g,\sigma_g) Ng(μg,σg)是VGGish生成的特征的高斯多元值
- VGGish是啥
- 一个专门用来提取声音特征的网络模型,将声音表示成128维度的embedding。具体参考这个链接

















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









