







文章目录
引言
-
这篇文章主要介绍使用resnetish和vggish对声音进行分类的代码,因为要通过分类模型的准确率来评价生成声音的质量,所以有必要好好实现一下这部分代码。需要实现如下的要求
- 不需要知道具体的代码逻辑结构,能跑就行
- 数据预处理部分
- 模型重新训练部分
- 模型测试部分汇总
-
继续弄吧,这部分是结果分析的最后一部分了,完成了这部分就可以完成整个实验的复现了。
-
这里是用了ml-sound-classifier项目,项目链接
正文
- 为了尽可能精简代码,这里将会对他给的完整项目代码进行精简,主要是围绕以下几个部分
- 数据预处理:用来加载音频
- 模型的定义:根据需要分类的音频重新调整模型结构
- 模型的训练:使用新的数据集重新训练
- 模型的测试:用来检测分类我的生成数据,作为评价标准
数据预处理
- 主要流程是
- 将所有的数据转变成log-mel频谱图进行保存
- 创建一个针对log-mel频谱图的dataset类,来加载数据
将wav转成log-mel频谱图进行保存
-
需要考虑几个问题
- 数据并不是等长的,短了需要补充,长了需要截断
-
这里使用的是torchaudio这个专门用来处理音频的库,然后进行处理音频,通过load函数读取音频,然后通过to_mel_spectrogram将数据转成mel频谱图,具体如下
'''将音频数据集转成对应的mel频谱图数据集并保存到指定路径'''''
def wav2mel_save(root_path,audio_dataset,yaml_file,mel_dataset):
'''
将数据集下方的所有音频文件转成对应的mel频谱图并保存到指定路径
:param root_path: 数据集所在文件的根目录
:param audio_dataset: 跟目录下方数据集的文件夹名称
:param yaml_file: 配置文件的路径
:param mel_dataset: 需要保存的mel频谱图数据集的根目录
:return:
'''
# 加载eav转成mel的实例对象
# 加载yaml文件,获取配置信息
with open(yaml_file) as conf:
cfg = EasyDict(yaml.safe_load(conf))
# 加载mel处理实例
to_mel_spectrogram = torchaudio.transforms.MelSpectrogram(
sample_rate=cfg.sample_rate, n_fft=cfg.n_fft, n_mels=cfg.n_mels,
hop_length=cfg.hop_length, f_min=cfg.f_min, f_max=cfg.f_max)
# 处理数据
audio_lengths = []
originRoot = Path(root_path) # 原始音频数据集根目录
targetPath = Path(mel_dataset) # mel频谱图数据集根目录
for folder in audio_dataset:
cur_folder = originRoot / folder
filenames = sorted(cur_folder.glob('*.wav'))
# 遍历所有wav文件
for filename in filenames:
# 加载wav文件
waveform, sr = torchaudio.load(filename)
# print('sample rate',sr)
assert sr == cfg.sample_rate
# 计算音频长度并且保存
num_samples = waveform.shape[-1] # Assuming shape is (num_channels, num_samples)
audio_length = num_samples / sr
audio_lengths.append(audio_length)
# 处理音频,确保长度和采样率一致
# waveform = process_audio(filename, max_length, target_sample_rate)
# waveform = torch.from_numpy(waveform)
# wav转成log-mel频谱图
# log_mel_spec = to_mel_spectrogram(waveform).log()
# print(log_mel_spec.shape)
# Write to work
# (targetPath / folder).mkdir(parents=True, exist_ok=True)
# np.save(targetPath / folder / filename.name.replace('.wav', '.npy'), log_mel_spec)
audio_lengths.sort()
index_20_percent = int(0.6 * len(audio_lengths))
min_length_80_percent = audio_lengths[index_20_percent]
return min_length_80_percent
创建dataset类保存数据
- 这里需要将数据进行统一处理,确保数据等长度,对音频数据进行补充或者截断。
- 这里继承了torch.utils.data.Dataset,主要重写三个方法,分别是__init__、len__和__getitem。就可以和dataloader类加载使用
# 制作数据集dataset类进行处理
class MelDataset(torch.utils.data.Dataset):
''' 对于数据处理类,要明确他的标签,文件名,以及数据的长度 '''
def __init__(self, filenames, labels, transforms=None):
assert len(filenames) == len(labels), f'Inconsistent length of filenames and labels.'
self.filenames = filenames
self.labels = labels
self.transforms = transforms
# 计算需要处理的音频的长度
self.sample_length = int((cfg.clip_length * cfg.sample_rate + cfg.hop_length - 1) // cfg.hop_length)
# print(self.sample_length)
# print(self[0][0].shape[-1])
# 测试第一个 wav 文件的长度
assert self[0][0].shape[-1] == self.sample_length, f'Check your files, failed to load {filenames[0]}'
# 展示基本信息
print(
f'Dataset will yield log-mel spectrogram {len(self)} data samples in shape [1, {cfg.n_mels}, {self[0][0].shape[-1]}]')
def __len__(self):
return len(self.filenames)
def __getitem__(self, index):
'''
返回索引index对应的数据和标签
:param index: 需要找到的数据的索引
:return:
'''
assert 0 <= index and index < len(self)
# 读取数据
log_mel_spec = np.load(self.filenames[index])
def sample_length(log_mel_spec):
return log_mel_spec.shape[-1]
# 填补数据到特定的长度
pad_size = self.sample_length - sample_length(log_mel_spec)
if pad_size > 0:
offset = pad_size // 2
log_mel_spec = np.pad(log_mel_spec, ((0, 0), (0, 0), (offset, pad_size - offset)), 'constant')
# 剪裁数据到特定的长度
crop_size = sample_length(log_mel_spec) - self.sample_length
if crop_size > 0:
start = np.random.randint(0, crop_size)
log_mel_spec = log_mel_spec[..., start:start + self.sample_length]
# 使用数据增强
if self.transforms is not None:
log_mel_spec = self.transforms(log_mel_spec)
# 处理 -inf 的值
if np.isneginf(log_mel_spec).any():
log_mel_spec[np.isneginf(log_mel_spec)] = 0 # 或者你想替换成的任何其他值
# 在第 0 维(最前面)添加一个新的维度,因为 PyTorch 的输入是一个 batch
return torch.Tensor(log_mel_spec), self.labels[index]
模型定义
- 这里是直接使用它定义的模型,有两个一个是AlexNet,用来练手,具体如下
import torch
import torch.nn as nn
import torch.nn.functional as F
# Mostly borrowed from https://github.com/pytorch/examples/blob/master/mnist/main.py
class Net(nn.Module):
def __init__(self, n_classes):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.conv3 = nn.Conv2d(64, 128, 3, 1)
self.conv4 = nn.Conv2d(128, 256, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.pooling = nn.AdaptiveAvgPool2d((8, 8)) # extended
self.fc1 = nn.Linear(16384, 128)
self.fc2 = nn.Linear(128, n_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = self.pooling(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
return x
- 另外一个是Resnetish,太长了就不放了,而且很常见爱你,在github上都有。
模型训练过程
训练代码定义
- 这里使用pytorch-lightning进行训练,需要定义一个LightningModule模块,继承并实现这个模块,不需要在专门进行梯度清零,反向传播,这些在都会有模块自动执行。只需要关注模块进行训练过程中使用的一些关键变量就行。
class MyLearner(pl.LightningModule):
def __init__(self, model, learning_rate=3e-4, loss=nn.CrossEntropyLoss(),
classes=4, train_loader=None, valid_loader=None, test_loader=None):
super().__init__()
self.learning_rate = learning_rate
self.model = model
self.loss = loss
self.classes = classes
self.train_loader = train_loader
self.valid_loader = valid_loader
self.test_loader = test_loader # 注意拼写
def forward(self, x):
x = self.model(x)
# x = F.log_softmax(x, dim=1)
return x
def training_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = self.loss(logits, y)
# loss = F.nll_loss(logits, y)
avg_loss = loss.mean()
self.log('train_loss', avg_loss)
return {'loss': loss}
def validation_step(self, batch, batch_idx, split='val'):
x, y = batch
# print("Validation batch:", x, y) # 打印验证批次数据
logits = self(x)
loss = self.loss(logits, y)
# loss = F.nll_loss(logits, y)
# print("Validation loss:", loss) # 打印验证损失
preds = torch.argmax(logits, dim=1)
# print(preds)
acc = accuracy(preds, y, num_classes=self.classes, task="multiclass") # 注意使用 self.classes
avg_loss = loss.mean()
self.log(f'{split}_loss', avg_loss, prog_bar=True)
self.log(f'{split}_acc', acc, prog_bar=True)
return {'val_loss': loss, 'val_acc': acc}
def test_step(self, batch, batch_idx, split='val'):
x, y = batch
x = torch.where(torch.isfinite(x), x, torch.zeros_like(x))
# print("Validation batch:", x, y) # 打印验证批次数据
logits = self(x)
loss = self.loss(logits, y)
# loss = F.nll_loss(logits, y)
# print("Validation loss:", loss) # 打印验证损失
preds = torch.argmax(logits, dim=1)
# print(preds)
acc = accuracy(preds, y, num_classes=self.classes, task="multiclass") # 注意使用 self.classes
avg_loss = loss.mean()
self.log(f'{split}_loss', avg_loss, prog_bar=True)
self.log(f'{split}_acc', acc, prog_bar=True)
return {'test_loss': loss, 'test_acc': acc}
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
scheduler = lr_scheduler.StepLR(optimizer, step_size=15, gamma=0.05)
# scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, 'max', factor=0.05, patience=10,min_lr=0.0002)
return {'optimizer': optimizer, 'lr_scheduler': scheduler, 'monitor': 'val_loss'}
def train_dataloader(self):
return self.train_loader
def val_dataloader(self):
return self.valid_loader
def test_dataloader(self):
return self.test_loader
loss为nan
- 出现loss是nan,说明存在数据是inf,是因为数据很小,取对数之后,出现了无穷小,然后下溢出。
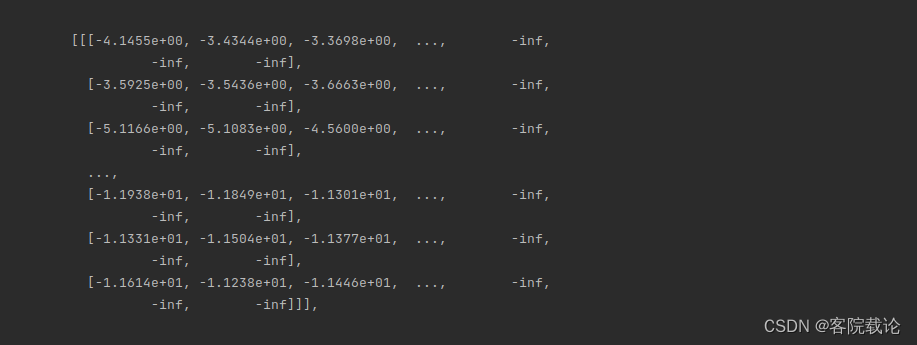
- 这里打印了处理之后的数据,具体如下,说明在数据预处理方面,自己并没有做好。
- 改进
- 在数据预处理部分,增加了对于溢出值的处理,具体如下
# 处理 -inf 的值
if np.isneginf(log_mel_spec).any():
log_mel_spec[np.isneginf(log_mel_spec)] = 0 # 或者你想替换成的任何其他值
总结
- 这里修改有一个问题,直接在模型的forward过程中,增加对于输入数据X的过滤,效果并不明显,这些问题应该在数据预处理部分就解决。
- 通过上述过程可以表明,实验数据越稳定,越紧凑,说明准确率提升的越快,结果越稳定。
从AlexNet到ResNet
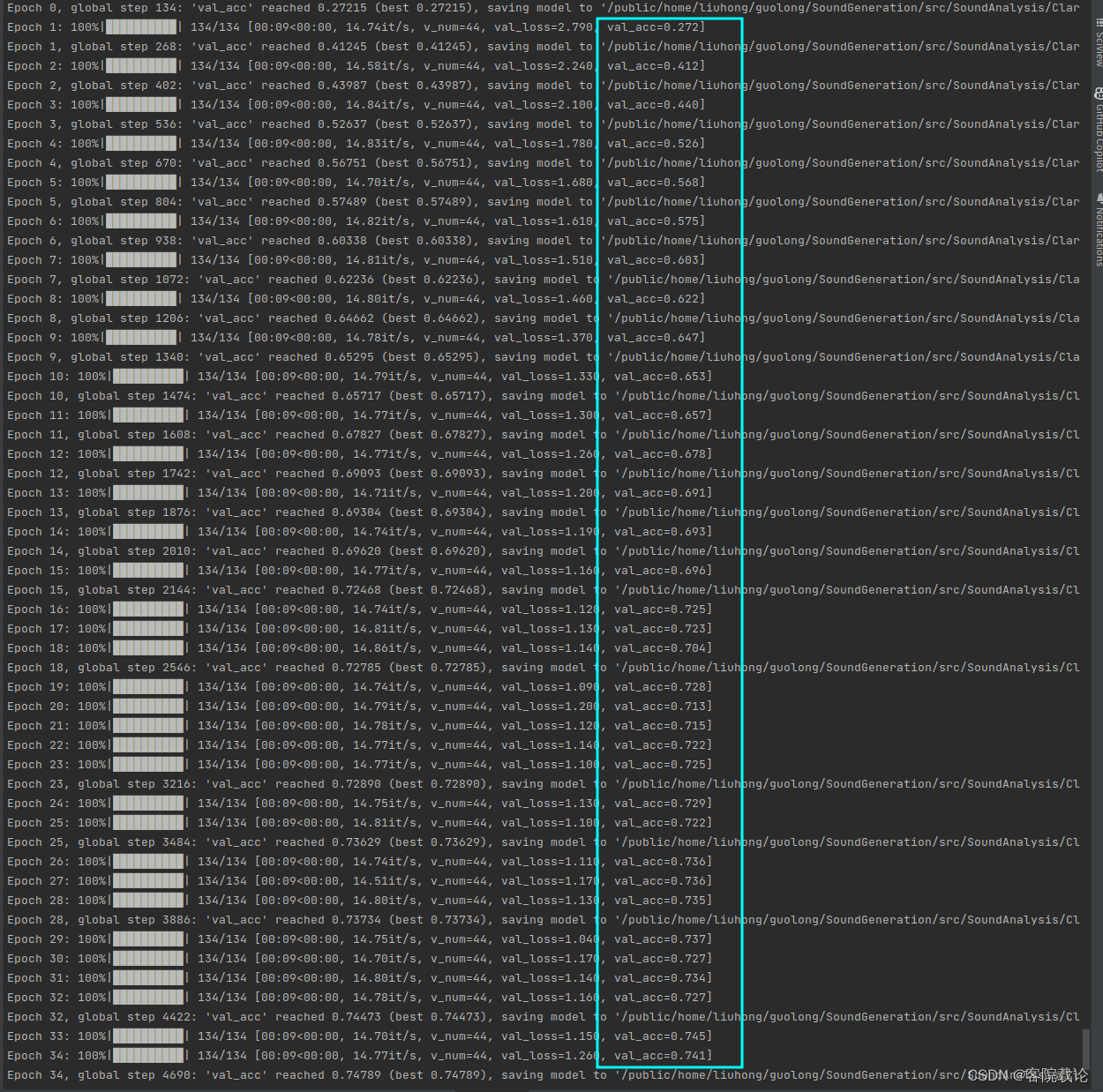
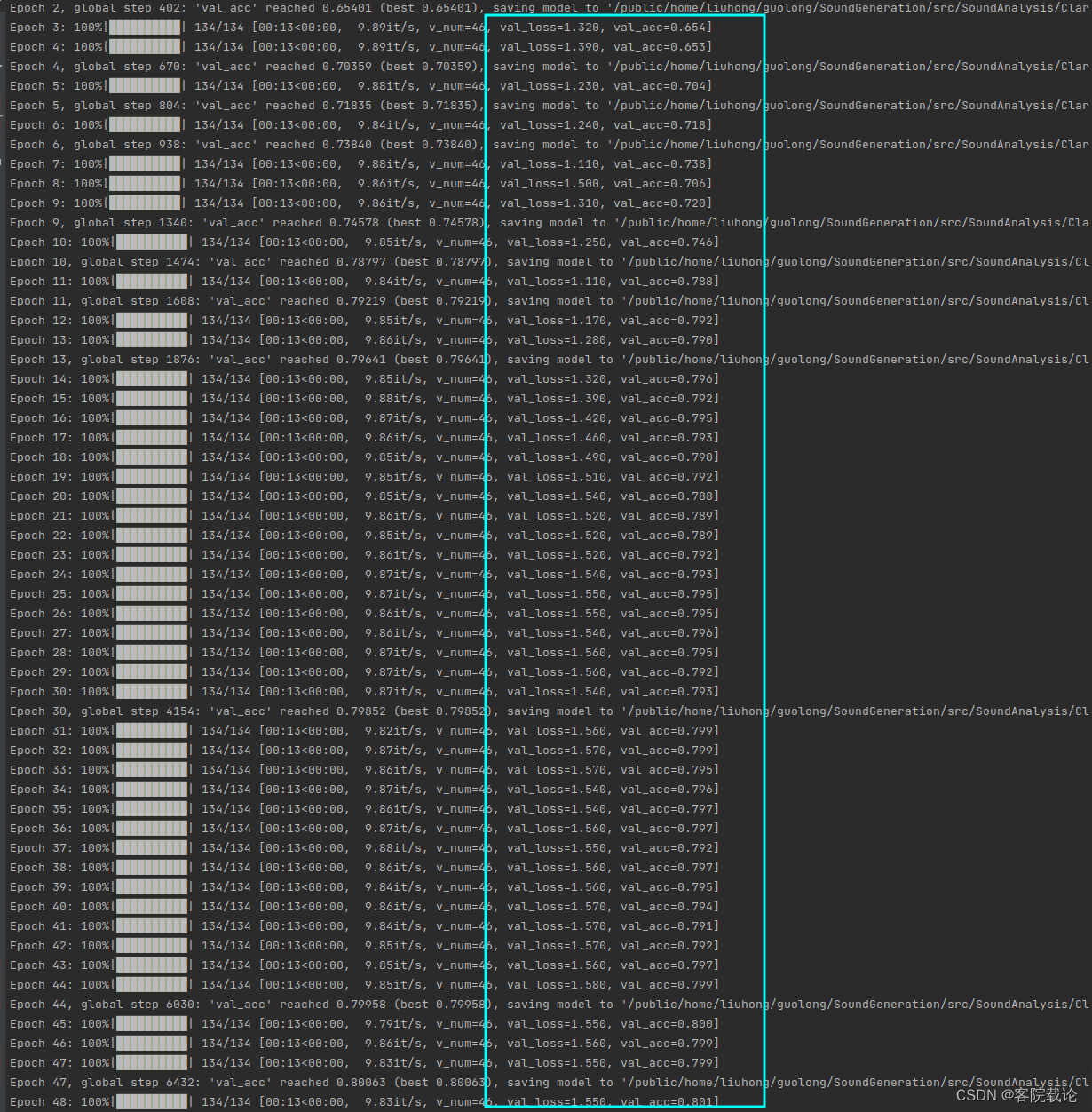
- 这里一开始使用了Mnist手写数据集常用的 AlexNet网络模型,50个epoch之后,他的准确度是73%(测试集),76%(验证集)。具体迭代过程如下,因为是在服务器上跑的,并不能进行可视化。
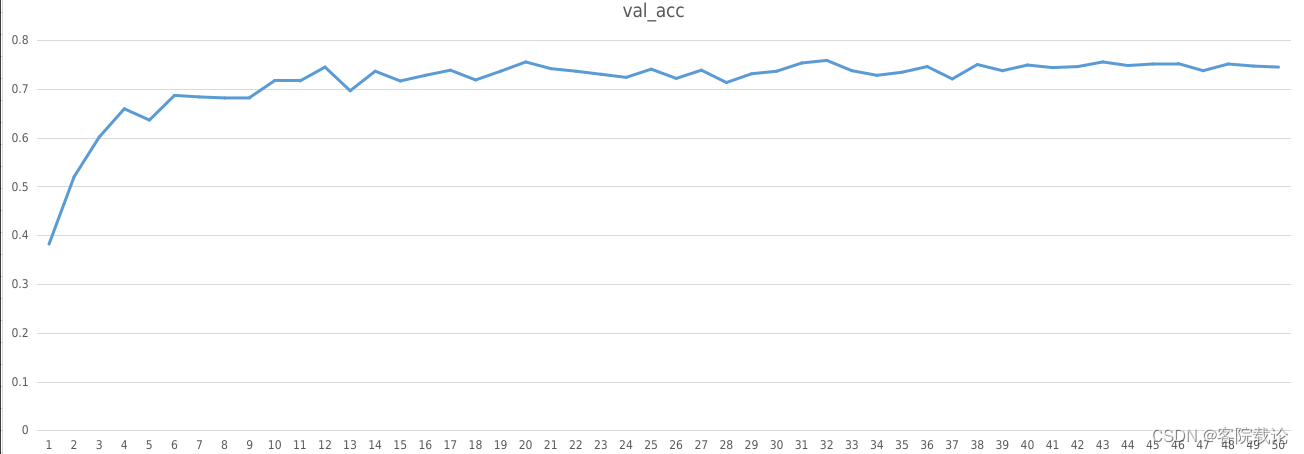
- 下述是使用resnetish 18进行实验的过程
总结
-
一个合适的网络结构,作用很大,主要体现在两个方面。
- 快速收敛:restnetish 18收敛速度快于AlexNet,AlextNet在第8个epoch准确率达到60%以上,但是resnetish在第3个epoch准确率就超过了60%。
- 模型较为准确:在同时经历了50个epoch之后,resnetish 18的准确率要高于AlexNet。AlexNet的准确率是73%(测试集),76%(验证集),Resnetish 18的准确率是75%(测试集),76%(验证集)。
-
上面的实验过程是有点尴尬的,不过还是有提高的,虽然提高的不过,说明我的学习率是有问题的。下面就是讲我的学习率问题。
loss上下剧烈波动——使用学习率衰减策略
- 在对resnetish 18进行训练的过程中,第12epoch之后准确率就到了75%,但是下一个epoch之后,准确率迅速下降,在后续的epoch之后,又达到了73%,然后有下降 。
- 学习率设置的过高,使得模型在最低值附近来回变动,使得模型不能快速收敛。
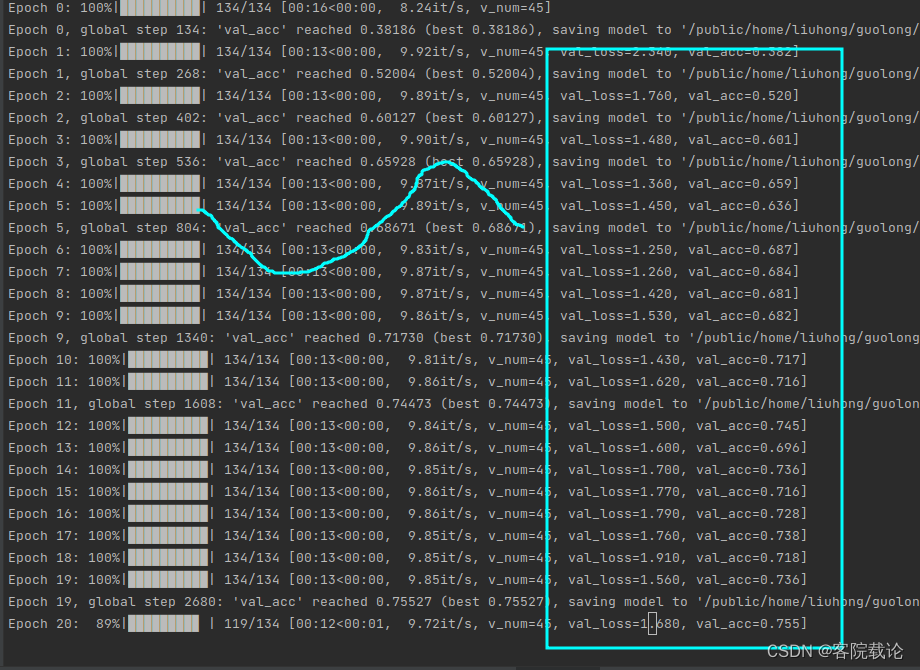
- 解决办法
- 使用衰减学习率,使用pytorch_lightning进行实现
from pytorch_lightning import LightningModule
class MyModel(LightningModule):
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=0.001)
scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
return {'optimizer': optimizer, 'lr_scheduler': scheduler, 'monitor': 'val_loss'}
- 具体训练过程如下
- 可以看到效果很棒,能够快速收敛,但是到了79以后,他的准确率就不变了,说明这个时候准确率太小了,应该还可以进行提高。
总结
- 一个合理的学习率调整策略确实能够实现模型准确率的快速提高,并且能够使得模型快速稳定。
小插曲
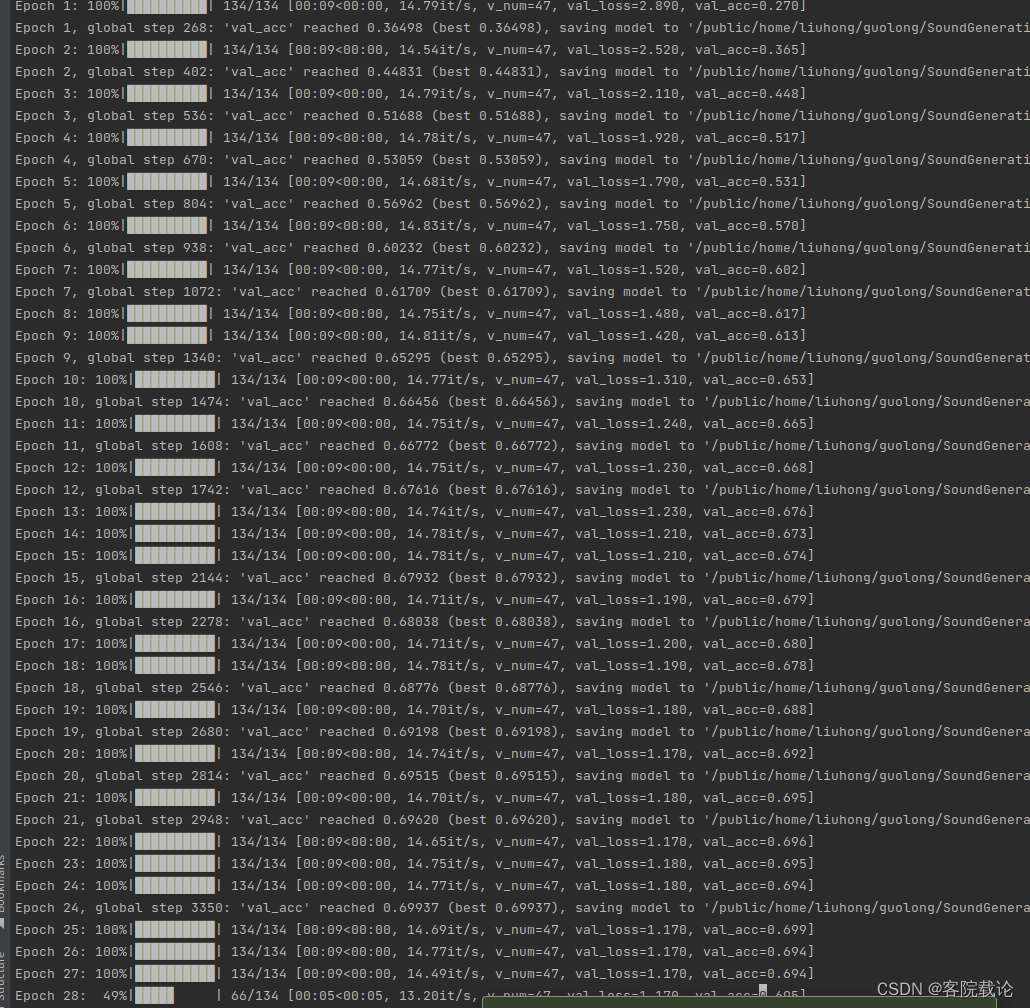
- 这里做了一个小尝试,用同样的学习率衰减策略,去训练AlexNet,发现会有如下的问题。他学习率并没有任何提高。说明,这个参数或者学习率还是需要调整的。
学习率调整——根据准确率来调整学习率
-
上面那个学习率调整方式,并不是很合理,因为是固定步长调整学习率,如果在前面学习率较大的情况下,还没有找到最有点,那么再后来学习率较小的情况下,移动会更加困难,优化的速率会更慢,所以这里选择使用根据准确率来调整学习率。
-
参数说明
- mode分为min和max
- min:监视验证集损失,损失没有变小,就降低学习率
- max:监视验证集准确率,准确率没有提高,就降低学习率
- mode分为min和max
-
具体代码如下
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
# scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.05)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, 'min', factor=0.1, patience=10)
return {'optimizer': optimizer, 'lr_scheduler': scheduler, 'monitor': 'val_loss'}
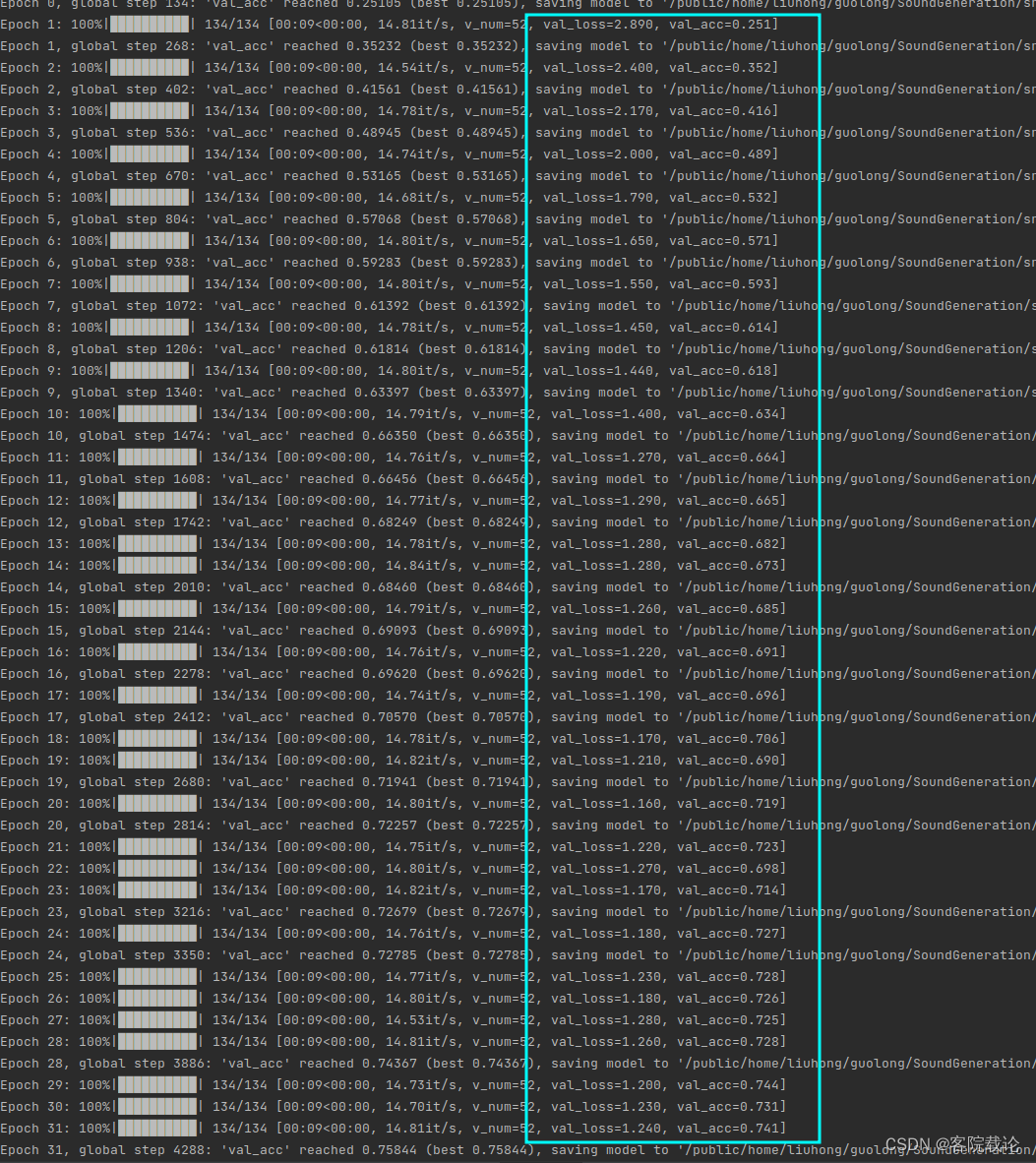
- 实验运行效果如下
- 下述使用AlexNet进行训练的,效果好了很多,精确率也有了显著的提高。
- 最终的精确度为77%测试集,76%验证集
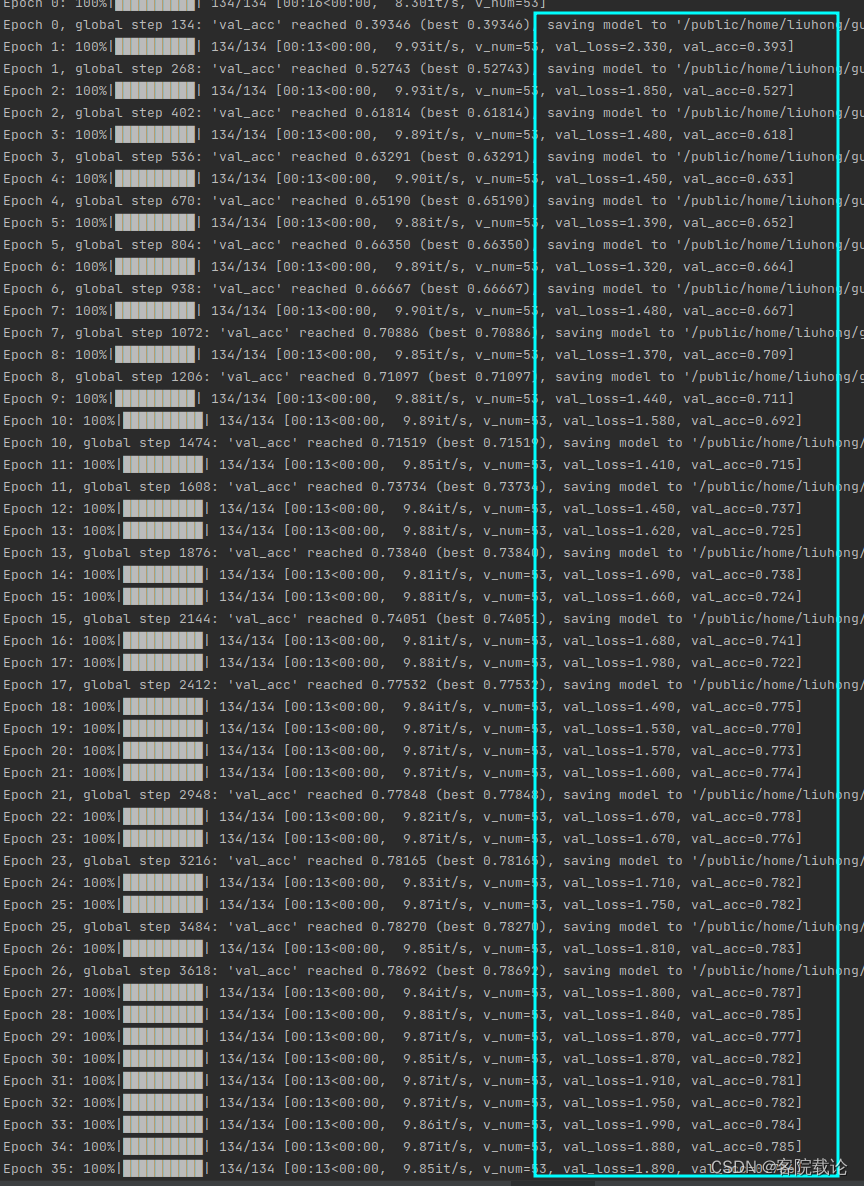
- 下面采用resnetish 18进行训练,查看训练效果。
- 可以看到resnetish 18的训练效果很好,精确度提高很快,但是后来变化就很慢,正常应该能到80%
- 最终的精确度为78%测试集,79%验证集
-
个人感觉是我的训练精度有问题,最低的精度设置的太低了,后续变化并不明显,自己私下里可以在试试看。
-
又试了一下,感觉这个效果更好,参数如下
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, 'max', factor=0.05, patience=10,min_lr=0.0002)
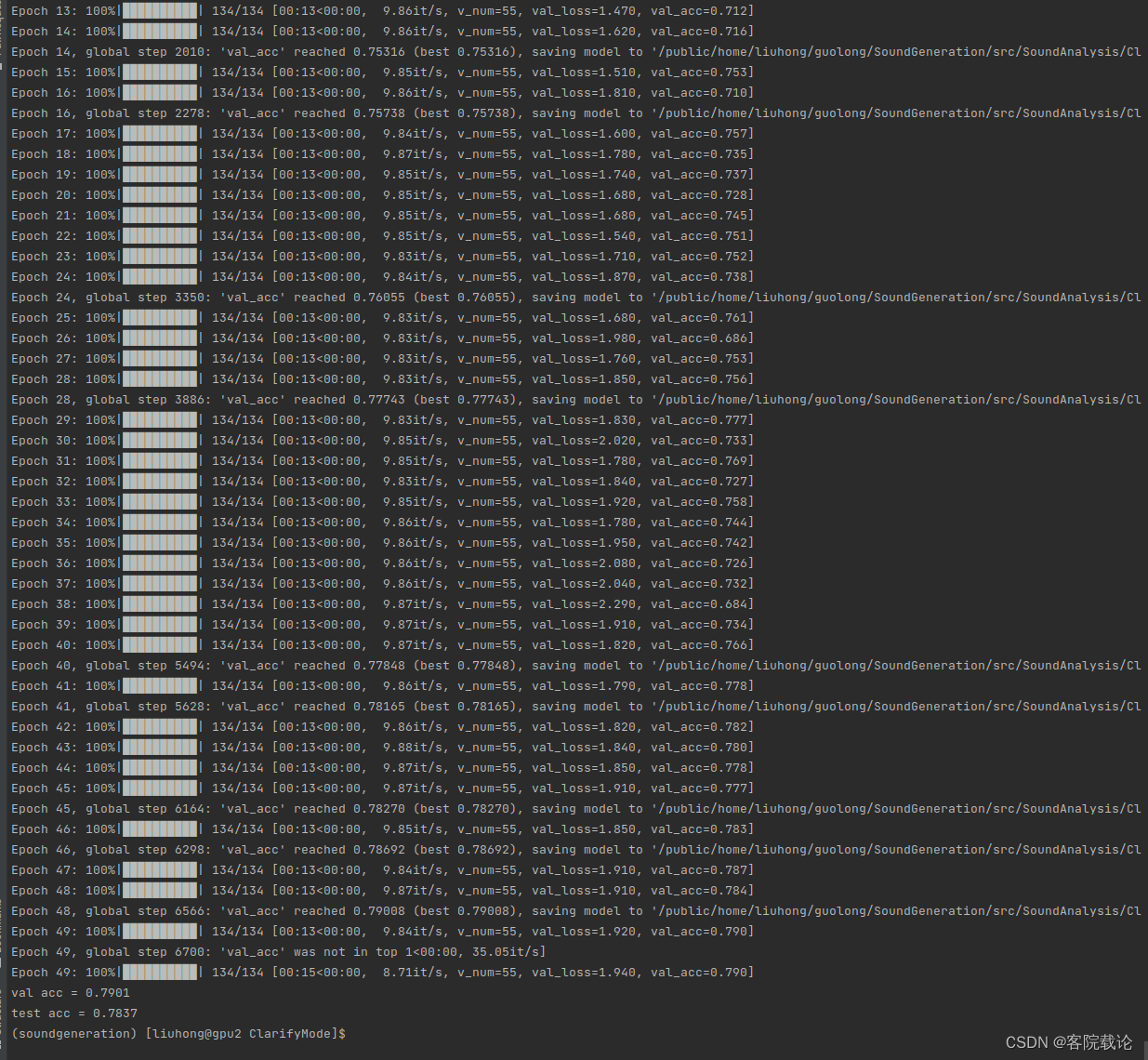
- 再来一个resnet34,看看效果
数据处理问题
-
无论怎么更改我的模型,发现模型的精确度并没有显著的提高,而且达不到我所参考的项目,这里就不得不再回到数据处理上,进行比较一下。
-
我所处理过之后数据,是[1,64,401]。而参考项目的所处理的数据,是[1,64,501],数据的采样点比我的数据多,我觉得参考的一句比我的多,所以我认为这是影响模型的一个重要的因素。
-
这里就需要具体看一下代码中给定的采样配置文件
# basic setting parameters
clip_length: 5.0 # [sec]
# preprocessing parameters
sample_rate: 44100
hop_length: 441
n_fft: 1024
n_mels: 64
f_min: 0
f_max: 22050
采样率sample_rate
-
通过torchaudio.load函数,读取音频,会自动返回波形图wave还有采样率sample rate。这个采样率是音频本身自己的采样率,所以在读取音频的时候,需要确保采样率和原始音频一致。
- 如果设置的采样率比原始的音频采样率大,那么就需要对原始的音频进行上采样。但是会引入更多的噪声
- 如果设置的采样率比原始的音频采样率小,那么就需要对原始的音频进行下采样,降低原始音频的音质。
clip_length截取长度
- 因为深度学习需要确保数据的长度一致,这里是对声音的长度的一个规范。
- 对于本身长度不足clip_length的,对数据进行padding,具体代码如下
- 这里是先计算需要填充的音频长度pad_size
- 然后除以2,获取offset,往音频两端同时添加同样长度的音频
- 是同时往音频两边补充常数0
pad_size = self.sample_length - sample_length(log_mel_spec)
if pad_size > 0:
offset = pad_size // 2
log_mel_spec = np.pad(log_mel_spec, ((0, 0), (0, 0), (offset, pad_size - offset)), 'constant')
- 对于本身长度超过了clip_length的,对数据进行随机剪裁,具体代码如下
- 计算出多的音频长度crop_size
- 然后随机在音频中找到截取的起点,进行选择。
# Random crop
crop_size = sample_length(log_mel_spec) - self.sample_length
if crop_size > 0:
start = np.random.randint(0, crop_size)
log_mel_spec = log_mel_spec[..., start:start + self.sample_length]
to_mel_spectrogram转成mel频谱图的相关参数
- 将音频图转成mel频谱图的相关系数如下,使用的是如下的函数
to_mel_spectrogram = torchaudio.transforms.MelSpectrogram(
sample_rate=cfg.sample_rate, n_fft=cfg.n_fft, n_mels=cfg.n_mels,
hop_length=cfg.hop_length, f_min=cfg.f_min, f_max=cfg.f_max)
- 读取的yaml文件如下
hop_length: 441
n_fft: 1024
n_mels: 64
f_min: 0
f_max: 22050
- 参数说明
- sample_rate: 音频的采样率。这是每秒钟音频中样本点的数量。
- n_fft: FFT(Fast Fourier Transform,快速傅里叶变换)的窗口大小。这决定了进行频谱分析的窗口大小。
- n_mels: Mel 滤波器组的数量,也就是 Mel 频谱图的 Mel 带数。这决定了 Mel 频谱图的垂直分辨率。
- hop_length: 帧之间的跳跃长度。例如,如果 hop_length=512,则窗口每次移动 512 个样本点以生成下一个帧。
- f_min: Mel 滤波器组的最低频率。通常设置为 0。
- f_max: Mel 滤波器组的最高频率。通常设置为 sample_rate / 2,这是 Nyquist 频率,也就是能够表示的最高频率。
尽可能多的特征提取
-
如果要提取尽可能多的特征,这里需要考虑两个点
- 更多的 Mel 滤波器:确实,更多的 Mel 滤波器可能有助于捕获高频信息。
- 调整 Mel 滤波器的频率范围:您可以设置 Mel 滤波器的最大和最小频率(f_min 和 f_max)来专门捕获高频范围。
-
这里修改了数据的长度,由原来的4秒改成了5秒
# basic setting parameters
clip_length: 5.0 # [sec]
-
这里查看了80%的声音长度都是小于8秒,然后只有50的声音长度是小于5秒,所以这里还可以在增加声音的长度。
-
设置为10秒种,具体的试验效果如下
- 确实高了,效果还行,不错。
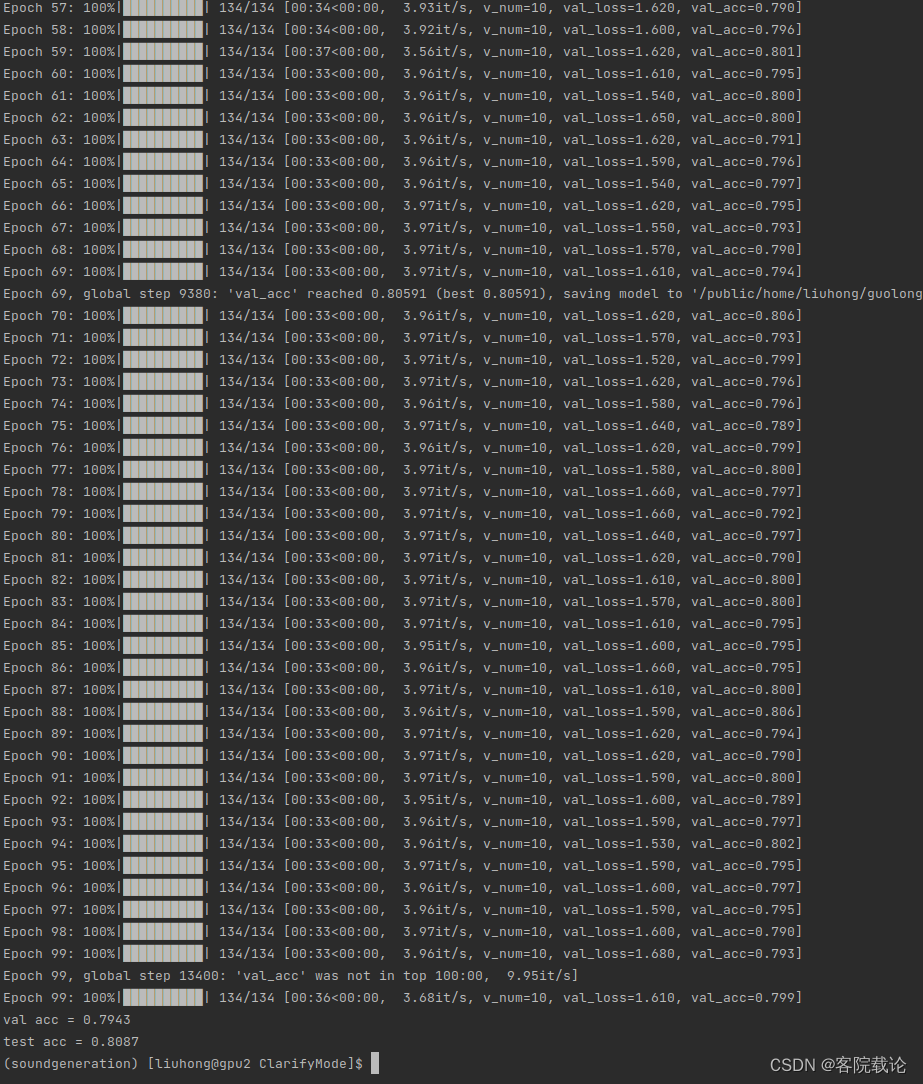
模型的测试
- 这里直接使用它定义的模型检测费方法,具体函数如下
def eval_acc(model, device, dataloader, debug_name=None):
model = model.to(device).eval()
count = correct = 0
for X, gt in dataloader:
logits = model(X.to(device))
preds = torch.argmax(logits, dim=1)
correct += sum(preds.cpu() == gt)
count += len(gt)
acc = correct/count
if debug_name:
print(f'{debug_name} acc = {acc:.4f}')
return acc
总结
- 这只是整个环节中,测试的一个小部分,就花了很多时间。不过学到了很多,模型的定义,模型的训练,模型的超参数调整,现在对这个分类模型有一个全面的认知了。但是并不准备花太多时间在模型参数的调整上,这个并不是我的主要任务,能够对数据进行分类就行了,我要的就是一个数据的准确率。
- 作为一个从零开始,什么都自己干的科研人,我心里的压力还是很大的,害怕自己不能毕业,不过又有什么关系,还是自己加油吧。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









