







 本文深入解析Transformer模型,探讨其在行为序列建模中的应用。重点介绍注意力机制、多头注意力、自注意力和模型结构,包括Encoder-Decoder、Positional Encoding等关键概念,适合深度学习和自然语言处理领域的读者学习。
本文深入解析Transformer模型,探讨其在行为序列建模中的应用。重点介绍注意力机制、多头注意力、自注意力和模型结构,包括Encoder-Decoder、Positional Encoding等关键概念,适合深度学习和自然语言处理领域的读者学习。
前言
最近想研究序列推荐的内容,刚好看到行为序列建模的BST[1]序列模型运用了Transformer[2]结构,并且美团博客中也提到了“Transformer 在美团搜索排序中的实践”[3]。因此学习了Transformer模型内容,并记录了笔记。本篇文章并没有什么创新,因为基本参考了对Jay Alammar的博客[4],想要具体了解,可以查看原博客(点击原文链接)。但由于下一篇是想对Transformer中遇到的问题进行汇总与解答(Q&A),所以先将自己整理的内容堆上来,方便参考。
本文约2.7k字,预计阅读15分钟。
Transformer
Transformer,是一个sequence-to-sequence模型,2017年提出。与其他Seq2Seq模型不同的是,它抛弃了传统的RNN与CNN,完全依赖注意机制来构成整个网络的架构,广泛的应用于机器翻译、语音识别等领域,当然也有在序列推荐中有具体的应用。Transformer也是一个encoder-decoder的结构,由自注意力机制(self attention)和前馈神经网络(Feed Forward)堆叠而成。论文中整体的结构如下所示: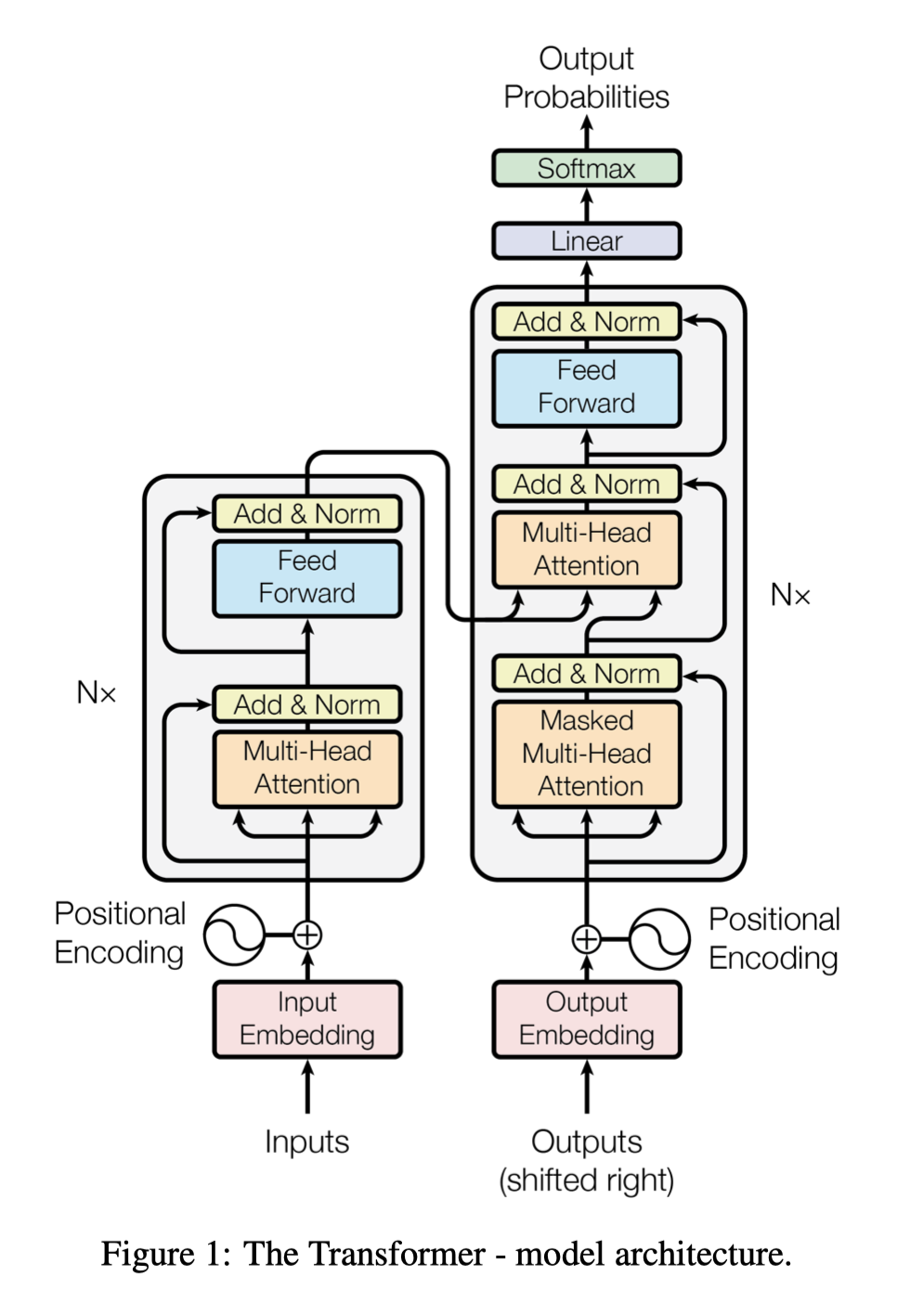
由于注意力机制是整个网络的核心,因此先由它展开。
注意力机制
注意力机制作为一种资源分配方案,将有限的计算资源用来处理更重要的信息,是解决信息超载问题的主要手段。
当神经网络来处理大量的输入信息时,也可以借助注意力机制,选择一些关键的信息输入进行处理,提高神经网络的效率。
用 表示 组输入信息,其中 维向量 表示一组输入的信息(向量)。注意力机制的计算可以分为两步:
在所有输入信息上计算「注意力分布」;
根据注意力分布来计算输入信息的加权平均;
「注意力分布:」
为了从 个输入向量 中选择出和某个特定任务相关的信息,需要引入一个和任务相关的表示,即「查询向量 」,通过一个打分函数来计算「每个输入向量和查询向量之间的相关性」。给定一个和任务相关的查询量量 ,用注意力变量 来表示被选择信息的索引位置,即 表示选择了第 个输入向量。首先计算在给定 和
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









