




 本文介绍了2018年SIGIR会议上的ESMM模型,该模型通过多任务学习解决CVR估计的样本选择偏差和数据稀疏问题。通过结合CTR和CTCVR预测,ESMM在曝光样本空间中估算CVR,同时分享CTR和CVR网络的嵌入,以缓解数据稀疏性。
本文介绍了2018年SIGIR会议上的ESMM模型,该模型通过多任务学习解决CVR估计的样本选择偏差和数据稀疏问题。通过结合CTR和CTCVR预测,ESMM在曝光样本空间中估算CVR,同时分享CTR和CVR网络的嵌入,以缓解数据稀疏性。

前言
接下来的知识输出可能会分为四个部分:基于图的推荐、多任务推荐、序列推荐以及pySpark学习。多任务推荐也叫多任务排序(因为主要应用的场景是排序),有两个或两个以上的目标函数,学习的模型在两个目标函数上都尽可能达到最优。我们从ESMM模型开始,探索多任务推荐的领域。
本文约1.6k字,预计阅读8分钟。
1. 概要
本篇文章是2018年发表在SIGIR会议上,题目为“Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate“,一篇非常经典的多任务推荐模型(应用在排序阶段)。当然文章的最终目的并不是为了完成多任务推荐,而是借助多任务学习作为辅助,对CVR(点击到购买的转化,CTR是曝光到点击)进行预测。
1.1 问题
这样做的原因是传统对CVR的估计存在两个问题:
「样本选择偏差问题(SSB)」:在训练阶段,采用的是用户点击过的样本进行模型训练,而在预测阶段,则使用的是整个曝光样本集(召回阶段给出的,点击的样本是中间产物,无法获取),如下图所示:
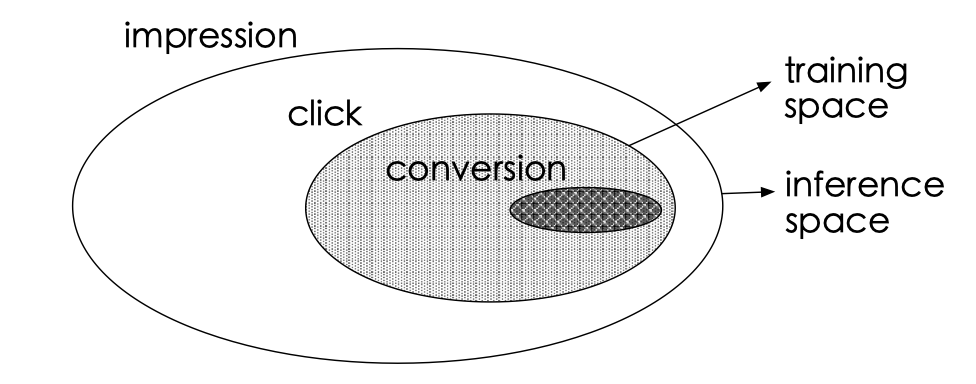
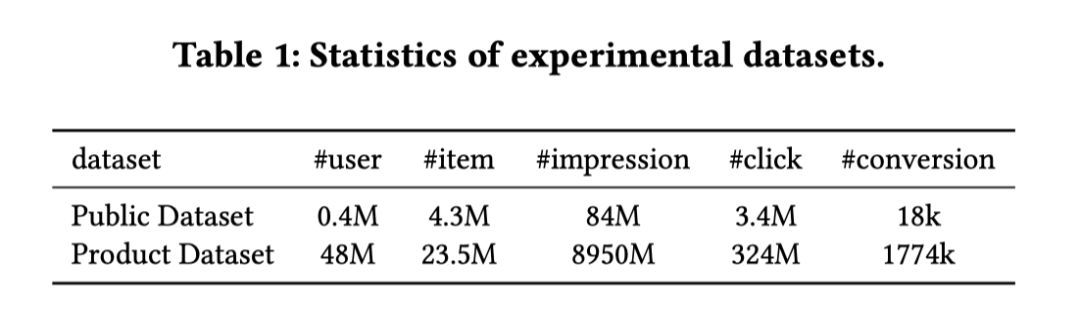
「数据稀疏问题(DS)」:在训练阶段,样本必须是用户点击过的,那么样本数量会远少于CTR预估任务,难以训练,论文给出的两个数据集中,CVR的样本数量只有CTR的4%:
1.2 一些解决方法
文章给出了之前的学者作出的一些改进,作为了解:
过采样(oversampling):对一些罕见的类样本(没有提及怎么去衡量)进行复制,这主要为了减缓数据的稀疏性,但对样本采样率非常敏感(在正负样本不平衡时,我们有时也会考虑过采样方法);
AMAN(all missing as negative):在训练阶段,随机采样曝光未点击的样本作为负样本,来消除样本选择偏差问题,但是这样CVR预测会被低估;
无偏方法(unbiased method)&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1763
1763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









