







4 . take(n)试图最小化访问分区,此操作并不一定以期待的顺序返回数据。
5 . 当持久化一个RDD的时候,计算这个RDD的节点会保存它们的分区。如果缓存了数据的节点出错了,Spark会在需要的时候重新计算丢失的分区。只有遇到action的时候才会真正的执行持久化操作。默认的持久化操作是将数据存放在JVM中作为非序列化对象。如下面wordcount的例子:
val lines = sc.textFile("...",100)
val words = lines.flatMap(x=>x.split(" "))
\\持久化words的RDD,并且内存硬盘序列化存储
words.persist(StorageLevel.MEMORY_AND_DISK_SER)
val wordcount = words.map(x=>(x,1))
val result = wordcount.reduceBykey(_+_)如上面的wordcount,如果words的RDD中某一个丢失了,就只会对丢失的数据进行split操作,并不会全部计算。
关于persist的存储级别有5种,如图所示:
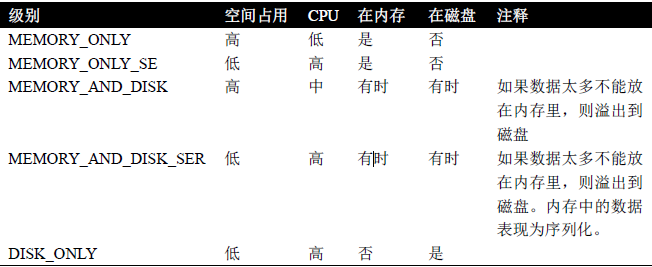
其中persist()和cache()相当于persist(StorageLevel.MEMORY_ONLY)。
后缀中带有 _SER 的表示序列化存储,使用序列化的方式来保存RDD数据,此时RDD中的每个分区都会序列化成一个大的字节数组,然后再持久化到内存或者磁盘中。序列化的方式可以减少持久化的数据对内存或磁盘的占用量,进而避免内存被持久化数据占用太多,从而发生频繁的GC。但是序列持久化会有序列化和反序列化的时间开销。















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









