







Bloom Filter是HBASE用来优化读性能的手段,在讲解Hbase中Bloom Filter的应用前,我们先理解下Bloom Filter的原理。
我们经常会去判断一个元素是否在一个集合中,当数据量比较小的时候,我们可以用Java的HashSet,Java的HashSet是创建一个散列数组,把原来的元素以某种规则映射到散列数组中特定的位置。但如果我们需要判断的元素个数非常大,会导致散列数组非常大,这个时候Bloom Filter就可以发挥作用。问题引出来了,就是我们要用尽可能小的空间,在大数据场景下实现过滤。接下来我会从作用、算法原理、问题、公式推导、hbase应用来介绍Bloom Filter。
作用
Bloom Filter的作用就是过滤。Bloom Filter过滤掉的数据,一定不在集合中;未被过滤的数据可能在集合中,也可能不在。
算法流程
- 首先需要k个hash函数,每个函数可以把key散列成为1个整数
- 初始化一个长度为n比特的数组,每个比特位初始化为0
- 当某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位从0置为1,如果已经是1则不变。
- 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
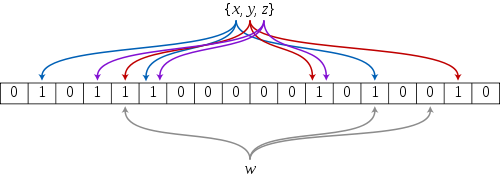
下图展示了Bloom Filter的原理
问题
bloom filter 存在两个问题:
1. Bloom Filter有一定概率False Positive发生,就是会把非集合内的元素误认为是集合内的元素。如果图中有个x1,对k个hash函数,有着和x完全一样的散列值,但是x1并不在集合{x,y,z}中,这时候bloom filter就会误判。
2. 该Bloom Filter无法删除元素。假设我要从集合中移去x这个元素,但是图中第6位的“1”,同时由x和z映射着,一旦删除,会对z造成影响。
接下来我们分析这两个问题,它们都是因为Bloom Filter节约空间导致的
1. False Positive是Bloom Filter的根本问题,因为hashSet会保存元素或者引用,如果hash碰撞了,我们直接比较元素来判断是否存在。而Bloom Filter并不保存元素或者引用,所以在原理上会出现False Positive的可能性。但是我们可以调节相关的参数来降低这种概率。
2. Bloom Filter基础版无法执行删除操作。在算法流程中,我们会把某个比特位置为1,但是可能该位已经置为1了,这样新的信息就没被保存。这是因为Bloom Filter用的位数组,每一位只有两种状态,“0”和“1”代表“出现过”和“没出现过”。如果我们能用一个int来表示出现的次数。添加元素的是,在特定位+1;在删除某个元素的时候,将特定位-1。
公式推导
假设bit数组大小为m、原始数集大小为n、哈希函数个数为k:
1.1个散列函数时,接收一个元素时,bit数组中某一位置为0的概率为: 1−1m 1 − 1 m
2.k个相互独立的散列函数,接收一个元素时,位数组中某一位置为0的概率为:
(1−1m)k
(
1
−
1
m
)
k
3.将n元素都输入布隆过滤器,此时某一位置仍为0的概率为: (1−1m)nk ( 1 − 1 m ) n k
4.某一位置为1的概率为: 1−(1−1m)nk 1 − ( 1 − 1 m ) n k
5.当我们判断某个元素是否在集合中,我们是根据k个标志位,如果全为1,则判断正确: [1−(1−1m)nk]k [ 1 − ( 1 − 1 m ) n k ] k
6.由极限定理
limn→∞(1+1n)n=e
lim
n
→
∞
(
1
+
1
n
)
n
=
e
,我们可以简化上面的公式
7.对k进行求导,当
k=mnln2
k
=
m
n
ln
2
,
ε
ε
取最小,最小值如下
这个值是理论上true positive和false positive和的最小值,因为是最小值,实际的值肯定要偏大一点。但是这里同时包含了两项,如果我们关注false positive的话,肯定又要小一点。
如果关注过滤掉的百分比,理论上就是 1−0.62mn 1 − 0.62 m n ,取m=10n, 1−0.6210=99.2 1 − 0.62 10 = 99.2 ,可以过滤掉99.2%的数据,只保留0.8%的数据进一步操作。
Bloom Filter在Hbase的作用
1.HBase主要利用BloomFilter来提高随机读(Get)的性能
2.对于顺序读(Scan)而言,只有设置了bloomfilter为ROWCOL且指定Scan的qualifer的才有优化;如果没指定qualifer,则没有优化。
BloomFilter在HBase中的性能
HBASE默认bloom filter级别为row,在实际使用时,如果需要过滤列,可以指定ROWCOL。一般能比不开启bloom filter快三四倍。
BloomFilter在HBase中的开销
BloomFilter是一个列族级别的配置属性,如果在表中设置了BloomFilter,那么HBase会在生成StoreFile时,包含一份BloomFilter 结构的数据,称其为MetaBlock(讲LRU的时候提到过);MetaBlock与DataBlock一起由LRUBlockCache维护,所以开启BloomFilter会有较小的的存储及内存cache开销。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









