









昨天的问题,的确在sql server上问题明显,可是同样的数据库、同样的表、同样的查询语句,它却可以在mysql上执行,对于sql server与mysql的区别我并不清楚,
下面写一下我对于这可问题的探索过程:
因为我是在github上照着别人练习的例子练习的,既然别人写的查询语句都贴上来了,肯定是运行成功了,于是我就想在mysql上试一试,还好我之前装了mysql。
下面是两个表manu 和 pro的查询结果(因为表名太长了,改短了):


在看一下相同查询语句下的结果:
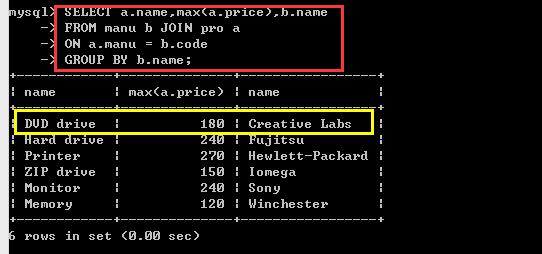
与昨天正确语句的查询结果对比一下:
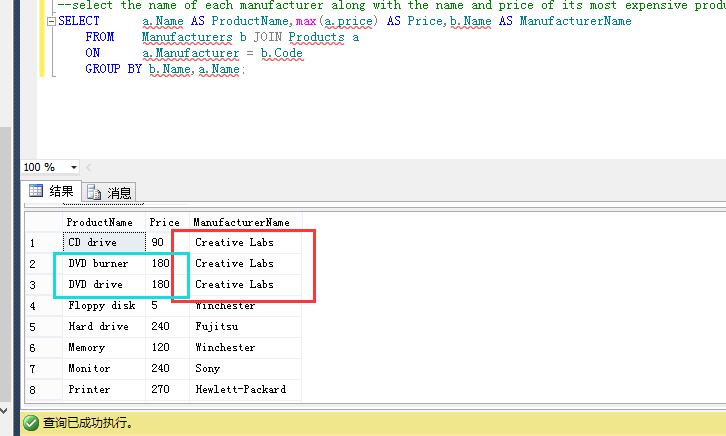
这结果出入很大,问题也很多。
mysql上的查询明显有问题,缺少了很多行。
那在mysql上试一试正确的语句如何?
结果如下:
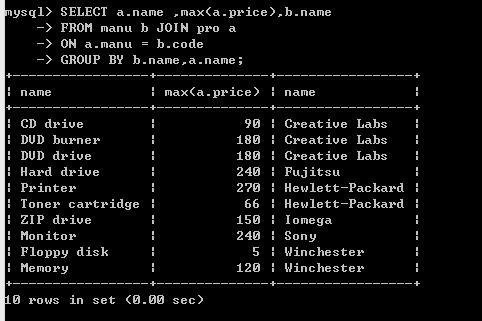
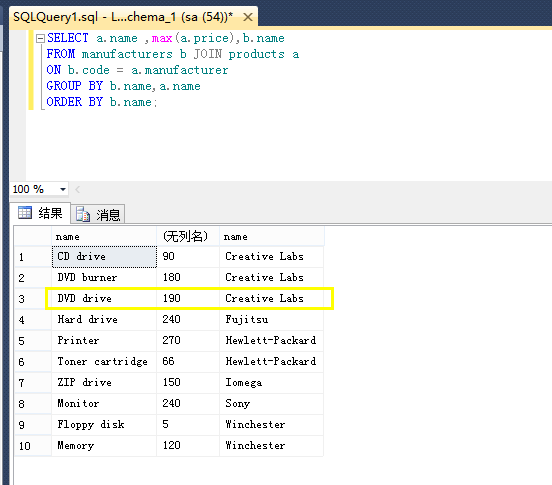
对比一下结果没有大的出入,除了那个price被我昨天改成190 以外。
那为什么相同的语句在sqlserver 和 mysql上使用得出的结果不同?
sqlserver上的报错与mysql上并不是我们所理想的结果,这是mysql的语法问题???















 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









