







要点:
- 多个scv格式数据的合并
(在这之前处理①“stkcd”② “year”③对“stkcd”和“year”进行排序 ④保存)
- 年份数据,只保留年报 (在csmar下载时可以添加条件)
- 报表类型,只保留合并报表A (在csmar下载时可以添加条件)
- 设置虚拟变量
一、详细数据合并及注意
1.merge命令:横向合并
在使用的时候至少需要一个共同的变量,通常是 stkcd year。可以排序一下
(1)一对一
merge 1:1 stkcd year using XXX ///stkcd year是匹配的依据,这样才能匹配正确。因为涉及的数据包括股票代码和年份
keep if _merge==3 ///是为了保留匹配成功的数据
drop _merge///是为了删除新生成的变量,不然之后没有办法匹配
(2)一对多
merge m:1 stkcd using XXX ///使用的文件using必须stkcd对应的数据是唯一的。多对一合并到主文件master中
keep if _merge==3 ///是为了保留匹配成功的数据
drop _merge///是为了删除新生成的变量,不然之后没有办法匹配| m:1 表示keyword在using文件中必须是唯一没有重复的的 |
2.append命令:纵向追加
append using xxx()文件名注意!!!append命令要求两份数据具有全部相同的变量,否则就会出现缺失值。
3.reclink命令:字符串模糊匹配
或者matchit
4.joinby命令:多对多匹配
5.nearmrg命令:相似之匹配
Stata:数据合并与匹配-merge-reclink (lianxh.cn)
二、基本合并命令
1.从数据库中下载相关数据scv格式,并解压
2.是从导入里,将数据导进stata中的(因为是文本形式的)
下载的数据中同一公司,同一年份中会对应 2组数据,是因为统计口径不一样,一般选择“年末在职人员”
命令:
![]()
 3.大部分数据使用的是“stkcd”而不是“symbol”,所以
3.大部分数据使用的是“stkcd”而不是“symbol”,所以
![]()
4.处理年份数据:
①将“xxxx-12-31”改为只有年份的数据
gen year =substr(enddate,1,4)
substr代表,提取字符“enddate”中,从第1个字符,向后提取4个字符(这里4表示间距)的数据为“year”
②如果数据中含有季报,半年报,年报,但是只要年报数据。需要先将年份,月份先提取出来再处理。(汉字是3个字符的,符号和数字都是一个字符)
gen year =substr(acc,1,4)
gen month = substr(acc,6,2)
destring year month,replace →进行数值型转换
keep if month==12 →只保留月份为12的
③将“year”进行数值型转换(因为此时“year”是字符型的数据)
destring year,replcae
destring的作用是转为数值,replace是替换掉原来的
5.保留合并报表数据A,删除母公司报表数据B。(因为字母无法直接转化为数值型的)
keep if typrep=="A" →加引号是为了告诉stata,保留的是非数值型的,typrep是报表类型的变量名
6.因为后续使用“stkcd”和“year”进行多个数据的合并,所以先将其排序
sort stkcd year
7.处理完后保存在文件夹,并采用以上方式处理其他scv格式文件里的“stkcd”和“year”之后再保存起来
8.合并处理
- 定义文件路径:是由于处理过的数据在同一个文件夹中,为了在合并的时候不再去输入完整的文件路径,只输入 文件名 即可。 用命令: cd 复制的文件路径
- 合并命令:merge stkcd year using 要合并的文件名
- 删除指示性变量: drop _m →合并后会自动生成一个变量_merge,表示指标原文件有没有之类的,需要删除不然没办法进行后续合并
- 排序:sort stkcd year
- 重复2-3步,合并其他的
从stata中保存之后的数据均为dta形式,所以再次打开不能从导入那里,否则会乱码
三、如何设置虚拟变量?
可以先使用 tabulate 命令,对该变量进行描述性统计
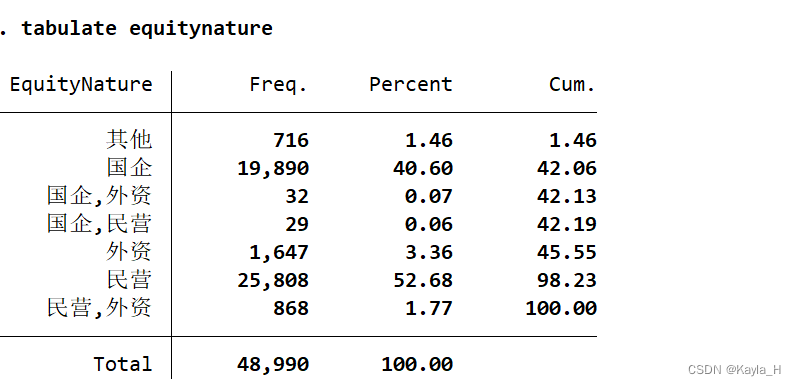
- 该变量本身有多个分类,但是只想分为两类,即引入一个虚拟变量的方法。例如,产权性质(国企、民营、外资等)只想分为 国企和非国企。→生成新变量并进行赋值
gen EN = 0 →生成一个新的变量,并赋值为0
replace EN = 1 if equitynature == "国企" →对新变量进行替换,输入条件,注意等号


















 2552
2552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









